
Занятие №14:
Метод исполнитель-критик (A2C)
Основные понятия
Ранее изученные методы
- Методы на основе значений (Q-обучение, Deep Q-Learning);
- Методы на основе политик (REINFORCE с градиентами политик).
Метод исполнитель-критик
- Критик, оценивающий эффективность предпринятых действий (на основе ценности);
- Исполнитель, который контролирует поведение нашего агента (на основе стратегии).
Наблюдения
Исполнитель
Критик
\pi(a|s)
V(s)
Метод исполнитель-критик

Выполнить действие
Получить награду
Наблюдение состояния
Ошибка
Критик
Исполнитель
Агент ОП
Q(s,a)
п(a,s)
p(a1,s), p(a2,s), p(a3,s)...
Проблема с градиентами политики
Отлично
Хорошо
Плохо
Хорошо
Хорошо
Хорошо
Хорошо
Хорошо
Хорошо
Хорошо
Метод исполнитель-критик
Старое обновление политики
\Delta\theta = \alpha * \triangledown_{\theta} * (log\pi(S_{t},A_{t},\theta)) * R(t)
\Delta\theta = \alpha * \triangledown_{\theta} * (log\pi(S_{t},A_{t},\theta)) * Q(S_{t}, A_{t})
Новое обновление политики
Метод исполнитель-критик
\pi(s,a,\theta)
q(s,a,w)
Исполнитель: функция стратегии контролирует действия нашего агента.
Критик: функция ценности измеряет насколько хороши эти действия.
Метод исполнитель-критик
- Критик вычисляет ценность выполнения данного действия в этом состоянии;
- Исполнитель обновляет свои параметры стратегии (веса), используя полученное q-значение.
Дискретная среда
Модель исполнителя
0.1
0.5
0.2
0.2
Входное состояние
Обучаемая сеть
Вероятности действий
Дискретная среда
Модель критика
Входное состояние
Обучаемая сеть
0.2
Значение состояния
Обновление весов
Для магистров
\Delta\theta = \alpha \triangledown_{\theta} (log\pi(s_{t},a_{t},\theta)) Q(s_{t}, a_{t})
\Delta\omega = \beta(R(s,a) + \gamma Q_{\omega}(s_{t+1}, a_{t+1}) - Q_{\omega}(s_{t}, a_{t})) \triangledown_{\omega} Q_{w}(s_{t}, a_{t})
Обновление весов исполнителя
Обновление весов критика
Функция преимущества (advantage)
A(s,a) = Q(s,a) - V(s)
q-значение для действия a в состоянии s
среднее значение этого состояния
A(s,a) = r + \gamma V(s{}') - V(s)
TD ошибка
Синхронная и асинхронная стратегии
- A2C или Advantage Actor Critic;
- A3C или Asynchronous Advantage Actor Critic.
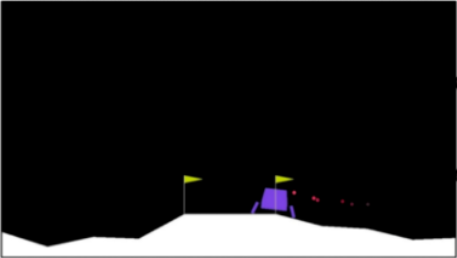
Среда LunarLander-v2
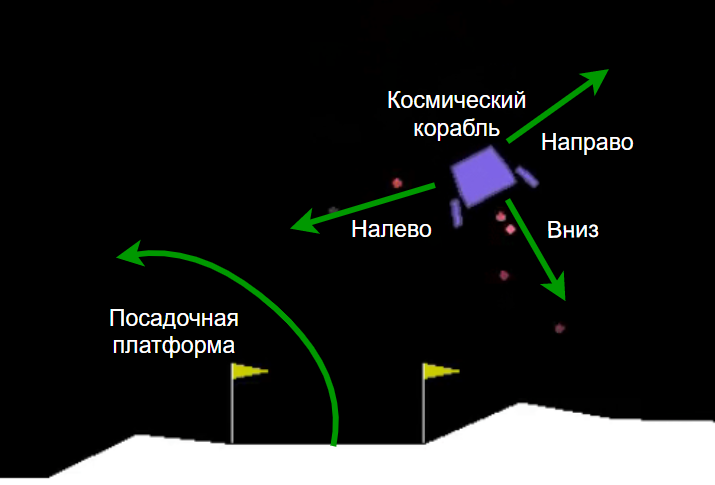
Код
import gym
import random
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda
from keras.models import Model, load_model
import numpy as np
from pyvirtualdisplay import Display
tf.keras.backend.set_floatx('float64')
env = gym.make("LunarLander-v2")
display = Display(visible=0, size=(400, 300))
display.start()Код
#Веса модели будут сохраняться в папку Models.
Save_Path = 'Models'
if not os.path.exists(Save_Path):
os.makedirs(Save_Path)
path = '{}_A2C'.format("Name")
Model_name = os.path.join(Save_Path, path)Код класса Actor
class Actor:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
self.model = self.create_model()
self.opt = tf.keras.optimizers.Adam(learning_rate=0.0005)
def create_model(self):
state_input = Input((self.state_dim,))
dense_1 = Dense(512, activation='relu')(state_input)
dense_2 = Dense(256, activation='relu')(dense_1)
dense_3 = Dense(64, activation='relu')(dense_2)
output = Dense(self.action_dim, activation="softmax")(dense_3)
return tf.keras.models.Model(state_input, output)Код класса Actor
def compute_loss(self, actions, logits, advantages):
ce_loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
policy_loss = ce_loss(tf.cast(actions, tf.int32), logits, sample_weight=tf.stop_gradient(advantages))
return policy_loss
def train(self, states, actions, advantages):
with tf.GradientTape() as tape:
logits = self.model(states, training=True)
loss = self.compute_loss(actions, logits, advantages)
grads = tape.gradient(loss, self.model.trainable_variables)
self.opt.apply_gradients(zip(grads, self.model.trainable_variables))
return loss
def load(self, Model_name):
self.model = load_model(Model_name + ".h5", compile=True)
def save(self, Model_name):
self.model.save(Model_name + ".h5")Код класса Critic
class Critic:
def __init__(self, state_dim):
self.state_dim = state_dim
self.model = self.create_model()
self.opt = tf.keras.optimizers.Adam(learning_rate=0.001)
def create_model(self):
state_input = Input((self.state_dim,))
dense_1 = Dense(512, activation='relu')(state_input)
dense_2 = Dense(256, activation='relu')(dense_1)
dense_3 = Dense(64, activation='relu')(dense_2)
output = Dense(1, activation="linear")(dense_3)
return tf.keras.models.Model(state_input, output)Код класса Critic
def compute_loss(self, v_pred, td_targets):
mse = tf.keras.losses.MeanSquaredError()
return mse(td_targets, v_pred)
def train(self, states, td_targets):
with tf.GradientTape() as tape:
v_pred = self.model(states, training=True)
loss = self.compute_loss(v_pred, tf.stop_gradient(td_targets))
grads = tape.gradient(loss, self.model.trainable_variables)
self.opt.apply_gradients(zip(grads, self.model.trainable_variables))
return loss
def load(self, Model_name):
self.model = load_model(Model_name + ".h5", compile=True)
def save(self, Model_name):
self.model.save(Model_name + ".h5")Код класса Agent
class Agent:
def __init__(self, env):
self.env = env
self.state_dim = self.env.observation_space.shape[0]
self.action_dim = self.env.action_space.n
self.actor = Actor(self.state_dim, self.action_dim)
self.critic = Critic(self.state_dim)
def td_target(self, reward, next_state, done):
if done:
return reward
v_value = self.critic.model.predict(np.reshape(next_state, [1, self.state_dim]))
return np.reshape(reward + gamma * v_value[0], [1, 1])Код класса Agent
def advantage(self, td_targets, baselines):
return td_targets - baselines
def list_to_batch(self, list):
batch = list[0]
for elem in list[1:]:
batch = np.append(batch, elem, axis=0)
return batch
def train(self, max_episodes=100):
if os.path.exists("Models/Name_A2C_Actor.h5") and os.path.exists("Models/Name_A2C_Critic.h5"):
self.actor.load("Models/Name_A2C_Actor")
self.critic.load("Models/Name_A2C_Critic")
print("Модели загружены")
for ep in range(max_episodes):
state_batch = []
action_batch = []
td_target_batch = []
advantage_batch = []
episode_reward = 0
done = FalseКод класса Agent
state = self.env.reset()
while not done:
probs = self.actor.model.predict(
np.reshape(state, [1, self.state_dim]))
action = np.random.choice(self.action_dim, p=probs[0])
next_state, reward, done, _ = self.env.step(action)
state = np.reshape(state, [1, self.state_dim])
action = np.reshape(action, [1, 1])
next_state = np.reshape(next_state, [1, self.state_dim])
reward = np.reshape(reward, [1, 1])
td_target = self.td_target(reward * 0.01, next_state, done)
advantage = self.advantage(
td_target, self.critic.model.predict(state))Код класса Agent
state_batch.append(state)
action_batch.append(action)
td_target_batch.append(td_target)
advantage_batch.append(advantage)
if len(state_batch) >= 5 or done:
states = self.list_to_batch(state_batch)
actions = self.list_to_batch(action_batch)
td_targets = self.list_to_batch(td_target_batch)
advantages = self.list_to_batch(advantage_batch)
actor_loss = self.actor.train(states, actions, advantages)
critic_loss = self.critic.train(states, td_targets)
state_batch = []
action_batch = []
td_target_batch = []
advantage_batch = []Код класса Agent
episode_reward += reward[0][0]
state = next_state[0]
print('Эпизод{}; Награда={}'.format(ep, episode_reward))
if ep % 5 == 0:
self.actor.save("Models/Name_A2C_Actor")
self.critic.save("Models/Name_A2C_Critic")
env = gym.make('LunarLander-v2')
env = gym.wrappers.Monitor(env,"recording",force=True)
agent = Agent(env)
agent.train()Результат
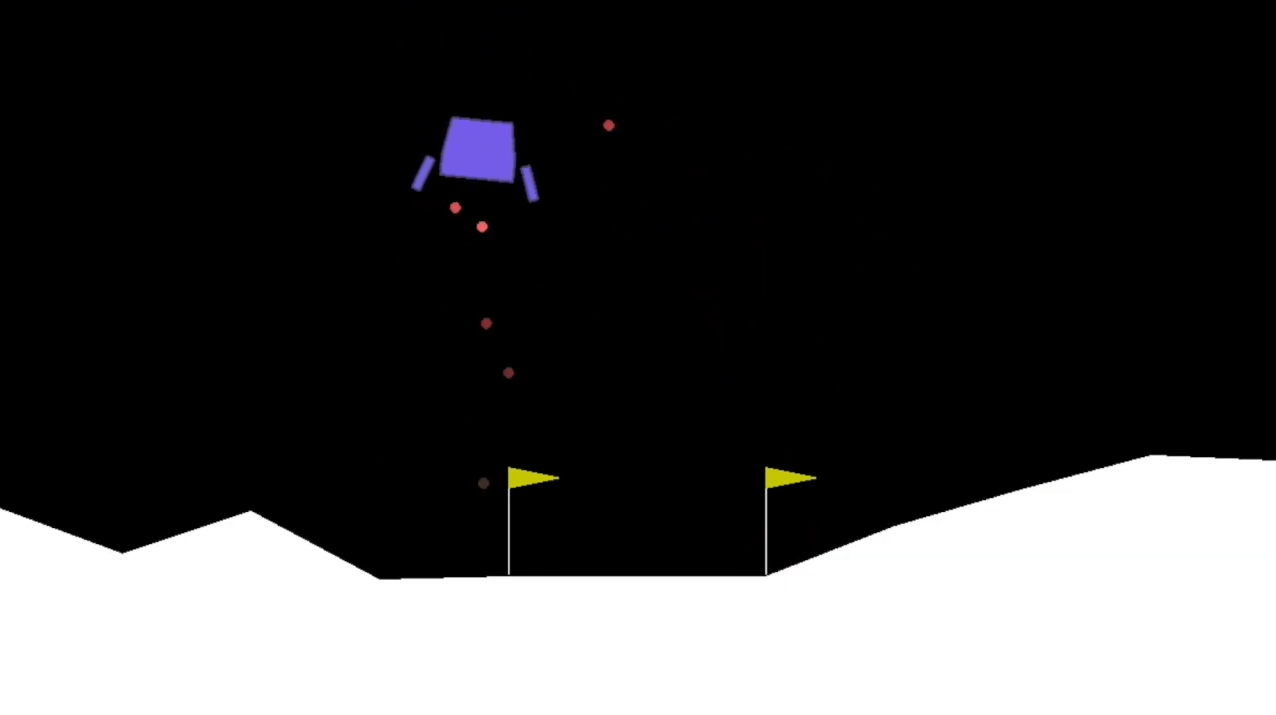
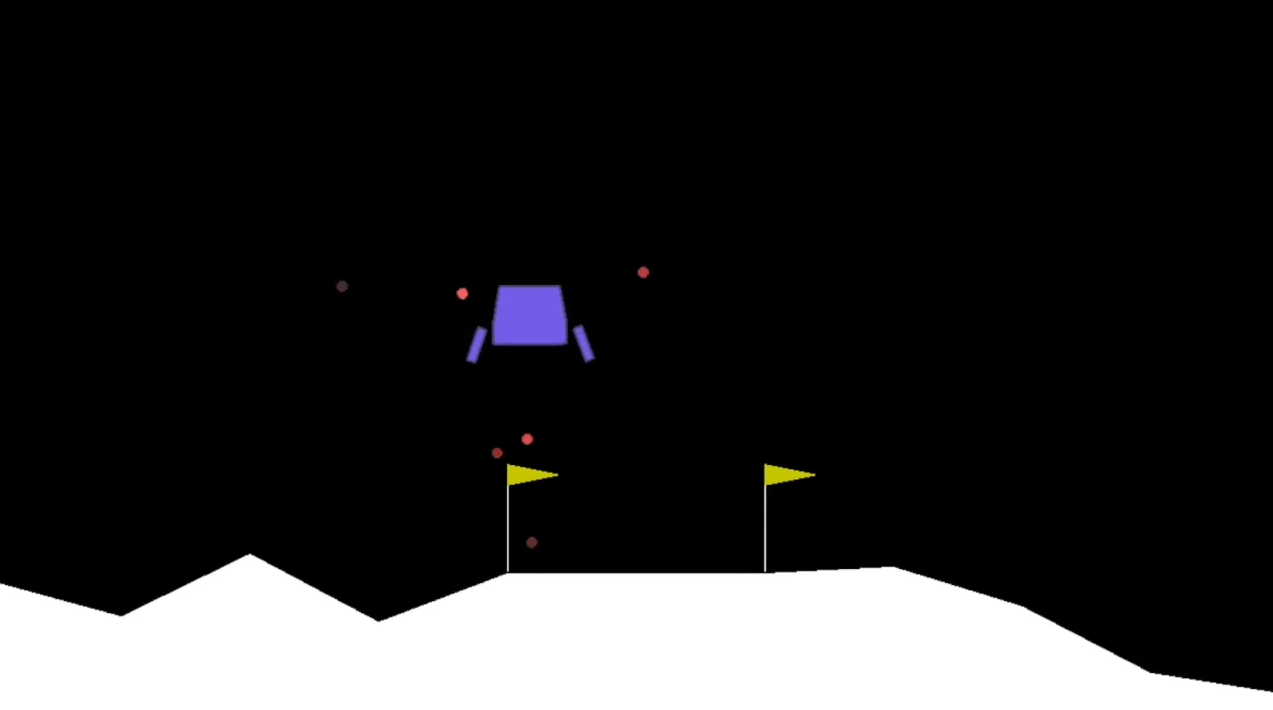
Непрерывная среда
Модель исполнителя

1
0.25
0
-0.32
0
0
-0.8
0.42
Значения действий
Обучаемая сеть
Входное состояние
Непрерывная среда
Модель критика
0.71
Значение состояния
Обучаемая сеть
Входное состояние
Непрерывная среда
Модель критика
0.71
Значение состояния
Обучаемая сеть
Входное состояние
from pyvirtualdisplay import Display
import random
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda
from keras.models import Model, load_model
import gym
import numpy as np
import pybullet_envsКод
#Веса модели будут сохраняться в папку Models.
Save_Path = 'Models'
if not os.path.exists(Save_Path):
os.makedirs(Save_Path)
path = '{}_A2C'.format("Name")
Model_name = os.path.join(Save_Path, path)Код
Непрерывная среда
#Изменения в программе для непрерывной среды
gamma = 0.99
class Actor:
def __init__(self, state_dim, action_dim, action_bound, std_bound):
self.state_dim = state_dim
self.action_dim = action_dim
# Ограничения на значения действий и
# среднеквадратическое отклонение
self.action_bound = action_bound
self.std_bound = std_bound
self.model = self.create_model()
self.opt = tf.keras.optimizers.Adam(learning_rate=0.001)Непрерывная среда
#Изменения в программе для непрерывной среды
def create_model(self):
'''
Смотрите задачу №3
'''
def get_action(self, state):
'''
Смотрите задачу №4
'''Непрерывная среда
#Изменения в программе для непрерывной среды
def log_pdf(self, mu, std, action):
std = tf.clip_by_value(std, self.std_bound[0], self.std_bound[1])
log_policy_pdf = -0.5 * (action - mu) ** 2 /
(std ** 2) - 0.5 * tf.math.log((std ** 2) * 2 * np.pi)
return tf.reduce_sum(log_policy_pdf, 1, keepdims=True)
def compute_loss(self, mu, std, actions, advantages):
log_policy_pdf = self.log_pdf(mu, std, actions)
loss_policy = log_policy_pdf * advantages
return tf.reduce_sum(-loss_policy)Непрерывная среда
#Изменения в программе для непрерывной среды
def train(self, states, actions, advantages):
with tf.GradientTape() as tape:
mu, std = self.model(states, training=True)
loss = self.compute_loss(mu, std, actions, advantages)
grads = tape.gradient(loss, self.model.trainable_variables)
self.opt.apply_gradients(zip(grads,
self.model.trainable_variables))
return loss
def load(self, Model_name):
self.model = load_model(Model_name + ".h5", compile=True)
def save(self, Model_name):
self.model.save(Model_name + ".h5")Непрерывная среда
#Изменения в программе для непрерывной среды
class Agent:
def __init__(self, env):
self.env = env
self.state_dim = self.env.observation_space.shape[0]
self.action_dim = self.env.action_space.shape[0]
self.action_bound = self.env.action_space.high[0]
self.std_bound = [1e-2, 1.0]
self.actor = Actor(self.state_dim, self.action_dim,
self.action_bound, self.std_bound)
self.critic = Critic(self.state_dim)Непрерывная среда
#Изменения в программе для непрерывной среды
class Agent:
'''
'''
def train(self, max_episodes=100):
'''
'''
while not done:
action = self.actor.get_action(state)
action = np.clip(action, -self.action_bound,
self.action_bound)
next_state, reward, done, _ = self.env.step(action)
state = np.reshape(state, [1, self.state_dim])
action = np.reshape(action, [1, self.action_dim])Непрерывная среда
#Изменения в программе для непрерывной среды
next_state = np.reshape(next_state, [1, self.state_dim])
reward = np.reshape(reward, [1, 1])
td_target = self.td_target((reward+8)/8, next_state, done)
'''
'''
env_name = 'MinitaurBulletEnv-v0'
env = gym.make(env_name)
env = gym.wrappers.Monitor(env,"recording",force=True)
agent = Agent(env)Результат

Спасибо за понимание!
Занятие 14. Метод исполнитель-критик (A2C)
By Astro Group



