數位人文概論
Lesson 3: 文本分析與視覺化
Last Updated: 2019/10/17
Outline
- 數位人文:借助數位科技工具的人文研究
- 文本收集與管理
- 高效筆記術 by Evernote
- 共筆系統:以Google文件為例
- 文本分析
- 斷詞、標記、統計
- 網路分析
- 視覺化
- 文字雲
- 網絡分析圖
- 時間線圖
文本收集馬偕數位典藏計畫(1/3)

文本收集
文本收集里德學院數位典藏(2/3)


文本收集
文本收集深化台灣核心文獻(3/3)
文本收集
文本分析
文本分析
"我和順仔早上5點登上「福建號」"
斷詞
原文
我 和 順仔 早上 5點 登上 福建號

文本資料來源
- 馬偕日記中譯本
- 30年、10141篇日記
- 內容分析Content Analysis
- 斷詞、詞性標記
- 人物、地點
- 解讀
- 詞頻統計、分群
- 斷詞、詞性標記
- 社會網路分析Social Network Analysis
- 詞與詞、群與群的關聯

http://www.tipi.com.tw/images/proimg/DoMCase-%E5%B0%8F-ss.jpg

http://ox.epage.au.edu.tw/ezfiles/278/1278/pictures/45/part_43922_9440244_30942.jpg
文本分析
文本分析斷詞與標記 (1/5)
"我和順仔早上5點登上「福建號」"
我和<person>順仔</person>早上5點登上「<ship>福建號</ship>」
斷詞
標記
原文
我 和 順仔 早上 5點 登上 福建號
專業術語
r c nr t t v nr
詞性
文本分析
文本分析斷詞與標記 (2/5)
拜訪 我 普林斯 頓 神學院 的 老同 學麥克 切斯 尼 先生 和 幾位 宣教 師 。 晚上 介紹 加拿大 , 哈巴 安德 醫師 翻譯
斷詞
困難: 斷詞錯誤 雜訊
"拜訪我普林斯頓(Princeton)神學院的老同學麥克切斯尼(McChesney)先生和幾位宣教師。晚上介紹加拿大,哈巴安德醫師翻譯。"
Icons made by Freepik from www.flaticon.com
Icons made by Eucalyp from www.flaticon.com

自訂辭典

停用字列表
普林斯頓
老同學
麥克切斯尼先生
哈巴安德醫師
宣教師
我
的
和
晚上
幾位
拜訪 普林斯頓 神學院 老同學 麥克切斯尼先生 宣教師 。 介紹 加拿大 , 哈巴安德醫師 翻譯
文本分析
文本分析斷詞與標記 (3/5)
困難: 錯別字、同義詞(不同稱呼/不同翻譯)
Icons made by Eucalyp from www.flaticon.com

拜訪南勢番(南方的原住民),在包干、李流(Li-lau),薄薄、斗蘭(Tau-lan)和七腳川拍了一些照片。

台灣堡圖
1904
我們拜訪流流、薄薄、里腦,又回到大社
問題:究竟是里腦,李流還是流流?
不同翻譯
回到五股坑,蔥仔在前往領事館費里德(A.Frater)先生那裡後和我們一起。
和偕師母及閏虔益一起到五股坑,然後去洲裡,在晚上回來。
同義詞
專家
修正與建議
里漏社
文本分析
文本分析
"""
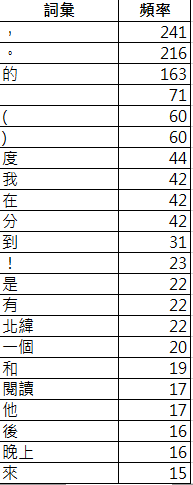
詞頻統計-不含詞性標記,使用jieba斷詞,載入自定義辭典,自訂停用字
"""
import jieba
import jieba.analyse
import csv
import collections
def readFile(fname):
my_dict = dict() # 建立空字典
with open(fname, encoding="UTF-8") as file:
rows = csv.reader(file) # 讀取所有內容產生串列
for r in rows: # 建立字典
my_dict[r[0]] = r[1]
return my_dict
# 步驟一:讀取日記,建立字典、停用字
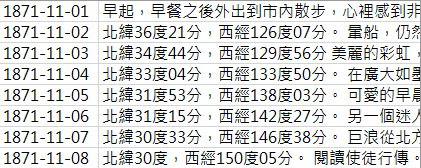
diary = readFile('Data/MackayFull.csv')
stop_word = []
# 從檔案讀取停用字
with open("Data/stopword.utf8.txt", encoding="UTF-8") as stop:
rows = stop.readlines()
for r in rows:
stop_word.append(r.strip())
jieba.load_userdict('Data/wordsMackay.utf8.txt') # 載入自定義辭典
# 步驟二:詞頻統計
word_count = dict() # 統計字典初值設定
for key, value in diary.items():
words = jieba.cut(value) # 對每一篇日記斷詞
for w in words: # 處理當天的斷詞結果
if (w in stop_word or w == ' ' or w == ' ' or w.isdigit()): # 移除停用字
continue
if (word_count.get(w) == None): # 詞不在字典裡
word_count[w] = 1 # 建立字典項目, 詞頻為1
else: # 詞在字典項目裡
word_count[w] += 1 # 詞頻加1
# 步驟三:重新排序:根據頻率高低
sorted_w = sorted(word_count.items(), key=lambda kv: kv[1], reverse=True)
# 步驟四:寫出檔案
with open('output_notag.csv', 'w', encoding="UTF-8", newline='') as csvfile:
writer = csv.writer(csvfile) # 建立 CSV 檔寫入器
writer.writerow(['詞彙', '頻率']) # 寫入標題列
# 寫入詞頻統計資料
for item in sorted_w:
writer.writerow([item[0], item[1]])Demo01:詞頻統計-不含詞性
需先安裝斷詞模組jieba
pip install jieba
- 使用Python程式對文章做詞頻統計
- 資料檔MackayDemo.csv,含自定義辭典、停用字列表
文本分析實作 (4/5)
文本分析

Python程式
停用字列表

自定義辭典
文本
Q: 有無改善空間?
輸出檔csv
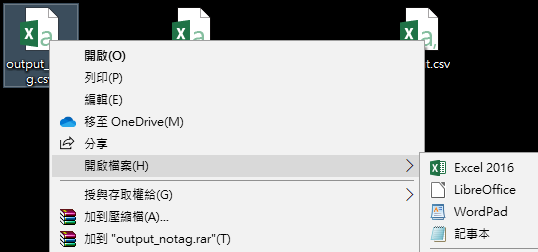
注意:輸出檔output_notag.csv(或output.csv)為utf8編碼
Excel直接開啟會顯示亂碼
❶先用記事本打開
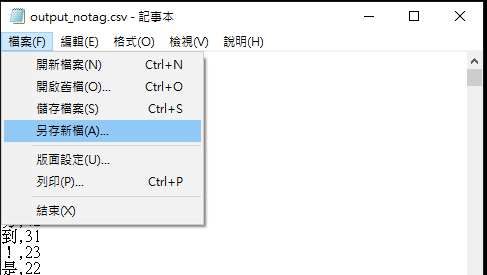
❷檔案/另存新檔
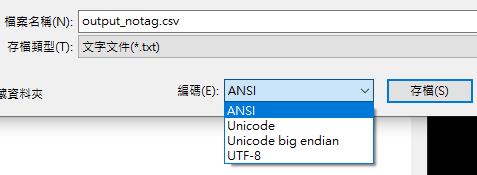
❸選取ANSI編碼後存檔
文本分析
### 使用外部模組jieba進行中文斷詞, jieba.posseg標記詞性
import jieba
import jieba.analyse
import jieba.posseg as posseg
import csv
import collections
def readFile(fname):
my_dict = dict() # 建立空字典
with open(fname, encoding="UTF-8") as file:
rows = csv.reader(file) # 讀取所有內容產生串列
for r in rows: # 建立字典
my_dict[r[0]] = r[1]
return my_dict
# 步驟一:讀取日記,建立字典
diary = readFile('Data/MackayDemo.csv')
stop_word = []
with open("Data/stopword.utf8.txt", encoding="UTF-8") as stop:
rows = stop.readlines()
for r in rows:
stop_word.append(r.strip())
jieba.load_userdict('Data/wordsMackay.utf8.txt')
# 欲省略的詞性列表
pos = {'u': '語助詞', 'r': '代名詞', 'd': '副詞', 'uj': '語助詞', 'c': '連接詞',
'm': '數詞', 'p': '介詞', 'j': '簡稱', 'y': '語氣詞'}
# 步驟二:詞頻統計
word_count = dict() # 詞頻統計字典
for key, value in diary.items():
words = posseg.cut(value) # 對每一篇日記斷詞,標記詞性
for w in words: # 處理每天的斷詞結果
word = w.word
if (word in stop_word or word == ' ' or word == ' ' or word.isdigit()): # 移除停用字
continue
if (w.flag in pos): # 忽略的詞性
continue
if (word_count.get(w) == None): # 詞不在字典裡
word_count[w] = 1 # 建立字典, 詞頻為1
else: # 詞在字典裡
word_count[w] += 1 # 詞頻加1
# 步驟三:重新排序(根據頻率高低)
sorted_w = sorted(word_count.items(), key=lambda kv: kv[1], reverse=True) # 排序
# 步驟四:輸出詞頻到檔案
with open('output.csv', 'w', encoding="UTF-8", newline='') as csvfile:
writer = csv.writer(csvfile) # 建立 CSV 檔寫入器
writer.writerow(['詞彙', '頻率', '詞性']) # 寫入標題列
for item in sorted_w: # 寫入統計資料列
writer.writerow([item[0].word, item[1], item[0].flag])Demo02:詞頻統計-含詞性
詞性標記jieba.posseg
- 使用Python程式對文章做詞頻統計與「詞性標記」
- 資料檔MackayDemo.csv
文本分析實作 (5/5)

q: 數量詞
v: 動詞
nr: 人名
n: 名詞
t: 時間詞
文本分析
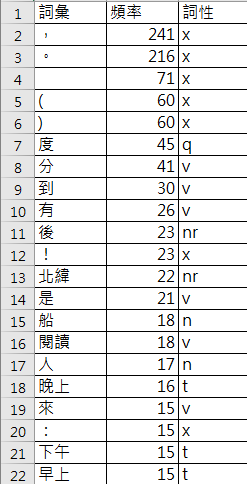
沒有詞性
刪除部份詞性
刪除更多詞性
Q: 有無改善空間?
哪些詞性應該刪除?
分組實作
- 程式:Demo02詞頻統計(含標記)
- 操作:請修改所使用的「資料檔檔名」
文本分析
| 檔名 | 日期 | 說明 |
|---|---|---|
| MackayFull.csv | 1871~1901 | 全部日記內容 |
| MackayFirst.csv | 1871~1879 | 第一階段 in 台灣 |
| MackayCan01.csv | 1880~1881/11/7 | 第一次返國 in 加拿大 |
| MackaySecond.csv | 1881/11/8~1893/8/18 | 第二階段 in台灣 |
| MackayCan02.csv | 1893/8/19~1895/10/13 | 第二次返國 in 加拿大 |
| MackayThird.csv | 1895/10/14~1901 | 第三階段 in 台灣 |
...
# 步驟一:讀取日記,設定停用字、自定義辭典
diary = readFile('Data/MackayFull.csv')
...資料視覺化 Part I
- 文字雲:詞彙與詞頻

視覺化
資料視覺化什麼是文字雲(1/8)
文字雲
- 關鍵字以視覺提示(如大小,顏色,形狀) 的方式呈現
- 能快速聚焦於文件主要內容(關鍵字, 趨勢, 概念)
視覺化
用途
- 寫作能力的提昇(例:將自己的文章製作為文字雲)
- 閱讀分析(例:將講稿製作為文字雲)
- 寫作提示(使用排名前10位的關鍵字寫一個故事)
資料視覺化什麼是文字雲(2/8)
關鍵字該是哪些?重要性?
- 次數越多的詞?
- 可根據詞性過濾?
- 詞性標記正確嗎?
- 重要性=詞頻?
- 學堂 vs 汽船

Answer: Case by case!
正規化(normalization)很重要
視覺化
資料視覺化文字雲工具(3/8)
註冊
視覺化
資料視覺化文字雲工具(4/8)
❶ 新增資料夾
❷ 點選資料夾
❸ 創建文字雲
視覺化
資料視覺化文字雲工具(5/8)
❶ 載入關鍵字
❷ 貼上「詞」、「頻率」
視覺化
❸ 匯入
資料視覺化文字雲工具(6/8)
視覺化
❹ 前往Google Noto Font網站下載免費中文字型
資料視覺化文字雲工具(7/8)
視覺化
❺ 載入中文字型
任選ㄧ.otf檔
資料視覺化文字雲工具(8/8)
視覺化
❻ 檢視文字雲
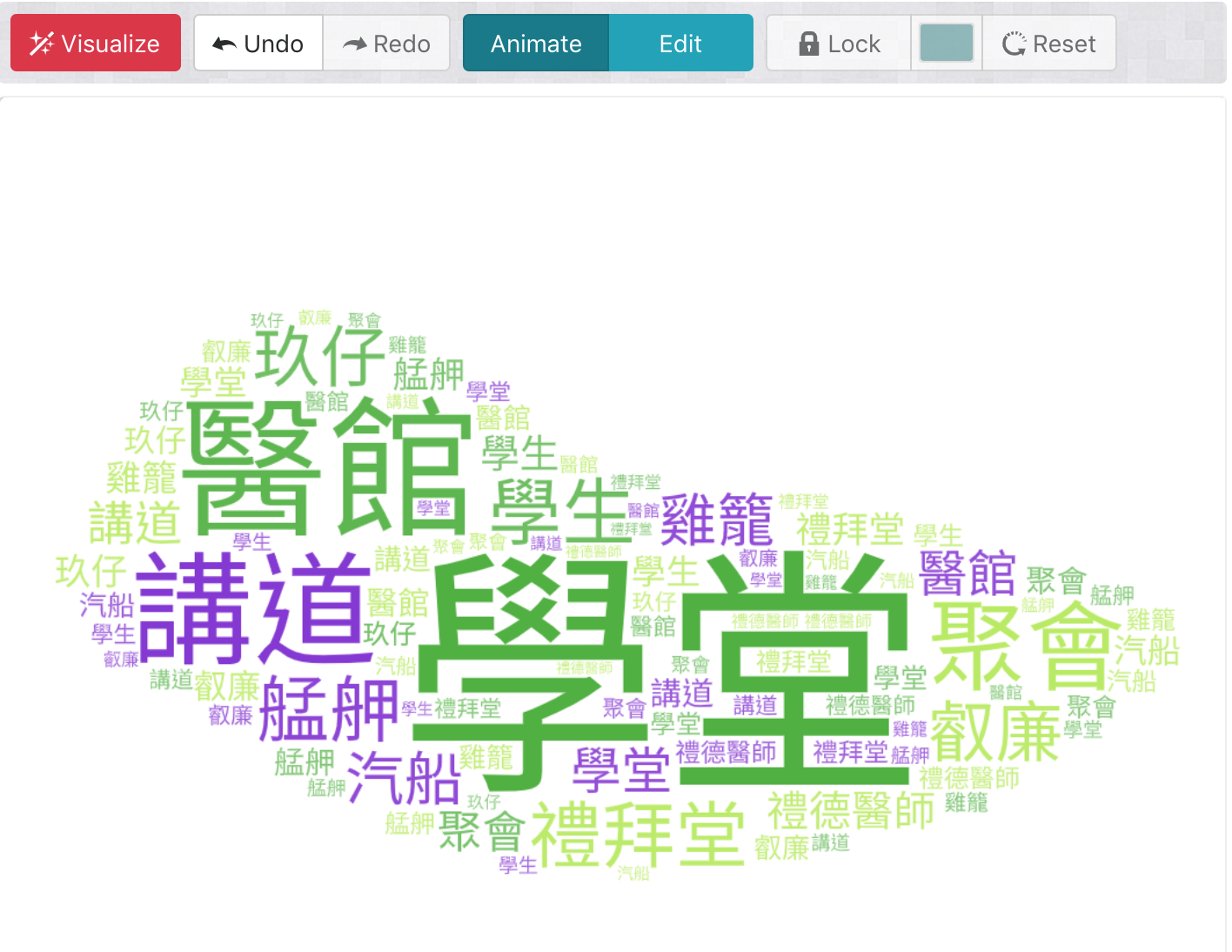
資料視覺化文字雲應用(1/4)
視覺化
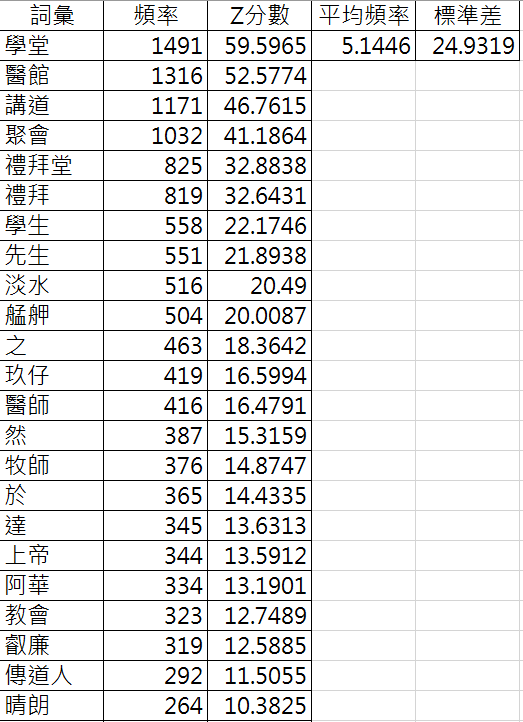
原始頻率

資料檔案:MackayFull.csv
處理方式:詞頻統計
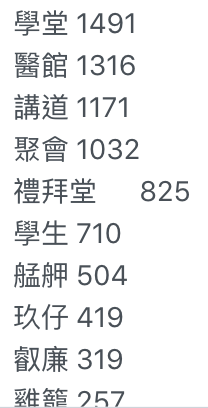
擷取頻率100次以上的字詞
- 學堂、醫館、禮拜堂: 工作地點
- 講道、聚會、禮拜: 馬偕博士的日常
- 艋舺、雞籠: 經常到訪的地點
- 玖仔、叡廉、禮德醫師、阿華: 互動的人物
觀察
Case 1: 高頻字詞
資料視覺化文字雲應用(2/4)
視覺化
正規化

正規化
=STANDARDIZE(頻率, 平均, 標準差)
=AVERAGE(所有頻率值)
=STDEV.P(所有頻率值)
移除字詞
Case 1-1: 高頻字詞
修正1-頻率正規化: 根據頻率計算Z分數
修正2-移除部分字詞
Z分數:Excel功能standardize(), average(), stdev.p()
中頻字詞浮現: 生病、教會、上帝
資料視覺化文字雲應用(3/4)
視覺化
Case 2: 含詞性字詞
資料檔案:MackayFirst.csv
處理方式:詞頻統計含詞性
頻率5次以上,不分詞性,共998個詞(共6197個詞)

地點: 五股坑、八里坌、大龍峒、洲裡、三重埔、滬尾、新港、竹塹、中壢
人名: 閏虔益、李庥
資料視覺化文字雲應用(4/4)
視覺化
Case 2-1: 含詞性(只有名詞)
資料檔案:MackayFirst.csv
處理方式:詞頻統計含詞性
頻率3次以上,名詞,共598個詞(名詞2582個詞)


字詞不重複, 大小由頻率決定
What's New?
社會網路分析Social Network Analysis
網路分析

Outline
- 基本概念:社會關係圖(sociogram)
- 社會網路分析實作
社會網路分析簡介
- 一種定量分析方法:使用數學工具如圖論等進行分析
- 目的:解析社會結構(如找出領導者、意見領袖、邊緣者、群組、不對稱或互惠關係...)
- 有時也稱為「社會關係圖」(sociograms)

社會網路
節點
關聯
網路分析

社會網路分析sociogram應用範例
小朋友的交友情況解析
連線:透過觀察或是直接詢問小朋友
Q: 誰比較邊緣?為什麼?
網路分析
主角分析 (冰與火之歌第三部:劍刃風暴)

連線:共同出現的次數
(兩個名字在15個字的距離內)
社會網路分析sociogram應用範例
(1) 107個角色, 353個邊
(2) 找出7個群組
(3) 使用6種「中心性」公式計算每
個角色的重要性
Q. 前三名主角是?
Tyrion, Jon, Sansa
網路分析
社會網路分析與日記內容分析有何關係?
網路分析
Q: 如果字詞是「節點」,字詞間的「共同出現」代表「關聯」?
「共同出現」:出現於同一句子、或同一文章)
我 和 順仔 早上 5點 登上 福建號
順仔
早上
福建號
社會網路
社會網路分析實作
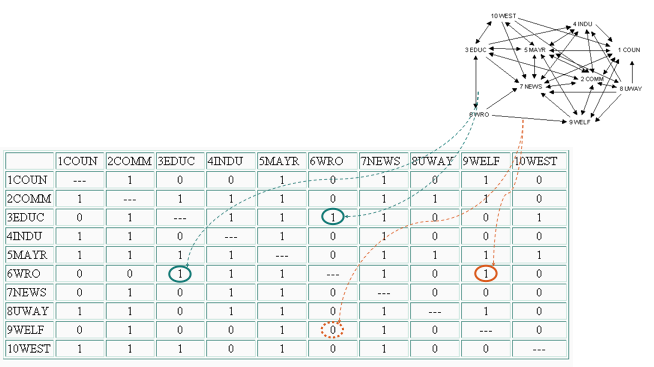
社會網路: 由圖 G=(V, E) 構成, 其中
- 節點V:actors(角色)
- 連線E:relations(關聯)
- 通常可用關聯矩陣表示
關聯矩陣
節點
關聯: 0 不相連, 1 相連
社會網路
節點
網路分析
社會網路分析實作
馬偕日記內容的
- 節點V:字詞(人名、地名...)
- 關聯E:出現於同一篇日記
網路分析
日記字詞: 可分為13類
社會網路: 單一類(例: 人名共同出現)
兩類字詞(例: 人名-地名)
網路分析
# 共同出現於同一天日記
import jieba
import jieba.analyse
import csv
import collections
def readFile(fname):
my_dict = dict() # 建立空字典
with open(fname, encoding="UTF-8") as file:
rows = csv.reader(file) # 讀取所有內容產生串列
for r in rows: # 建立字典
my_dict[r[0]] = r[1]
return my_dict
# 步驟一:讀取日記,建立字典
diary = readFile('Data/MackayDemo.csv')
stop_word = [] # 1-1 停用字
with open("Data/stopword.utf8.txt", encoding="UTF-8") as stop:
rows = stop.readlines()
for r in rows:
stop_word.append(r.strip())
jieba.load_userdict('Data/wordsMackay.utf8.txt') # 1-2 自定義辭典
# 步驟二:共同出現統計
word_count = dict() # 統計字典初值設定
co_occu = dict()
for key, value in diary.items():
words = jieba.cut(value) # 對每一篇日記斷詞
for w1 in words: # 處理當天的斷詞結果
if (w1 in stop_word or w1 == ' ' or w1 == ' ' or w1.isdigit()): # 移除停用字
continue
for w2 in words:
if (w2 in stop_word or w2 == ' ' or w2 == ' ' or w2.isdigit()): # 移除停用字
continue
if (w1 == w2):
continue
w = (w1 + ' ' + w2) if (w1 < w2) else (w2 + ' ' + w1)
if (word_count.get(w) == None): # 詞不在字典裡
word_count[w] = 1 # 建立字典項目, 詞頻為1
else: # 詞在字典項目裡
word_count[w] += 1 # 詞頻加1
# 步驟三重新排序:根據頻率高低
sorted_w = sorted(word_count.items(), key=lambda kv: kv[1], reverse=True)
# 步驟四:輸出
with open('output_co_occu.csv', 'w', encoding="UTF-8", newline='') as csvfile:
writer = csv.writer(csvfile) # 建立 CSV 檔寫入器
writer.writerow(['詞彙', '頻率']) # 寫入標題列
# 寫入詞頻統計資料
for item in sorted_w:
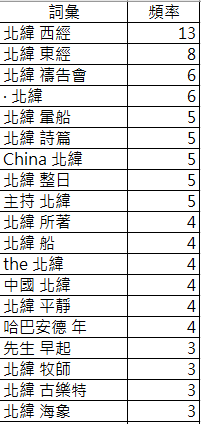
writer.writerow([item[0], item[1]])Demo03:共同出現-同一篇
社會網路分析結果
網路分析
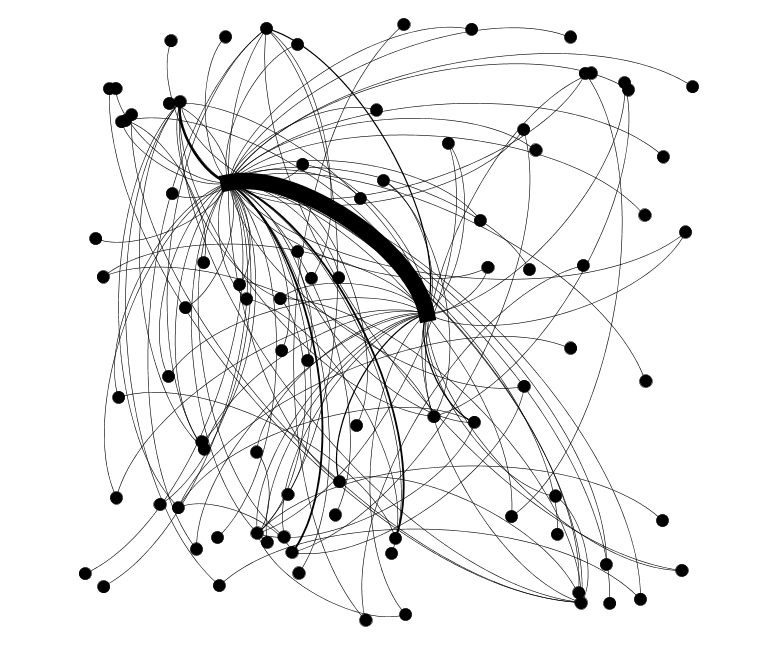
關於Gephi

資料視覺化軟體gephi
資料視覺化軟體gephi
- 匯入資料
- 視覺化設定:layout演算法
- 調整顏色與大小:ranking模組
- 計算重要性評量「指標」:statistics模組
- 文字標籤
- 群組偵測:statistics模組
- 設定過濾方式:過濾器(filter)
- 預覽
資料視覺化軟體匯入資料
支援格式:
- GEXF
- CSV
- GraphML
- GML
- ...

有無方向性
節點數量
邊的數量
layout演算法
大小、顏色(Ranking功能)
指標計算
(統計模組)

過濾功能
(Fiilter)
標籤、大小...
指標計算參考:淺談社會網路分析(中心性計算)
資料視覺化 Part III
- 時間線圖 (Timeline)
時間線圖
時間線圖介紹(1/9)
時間線圖

Q1:文字年表的問題?
Q2:資料如何自動產生?資訊擷取
時間線圖介紹(1/9)
時間線圖
資訊快速呈現的方法:時間線圖(Timeline)
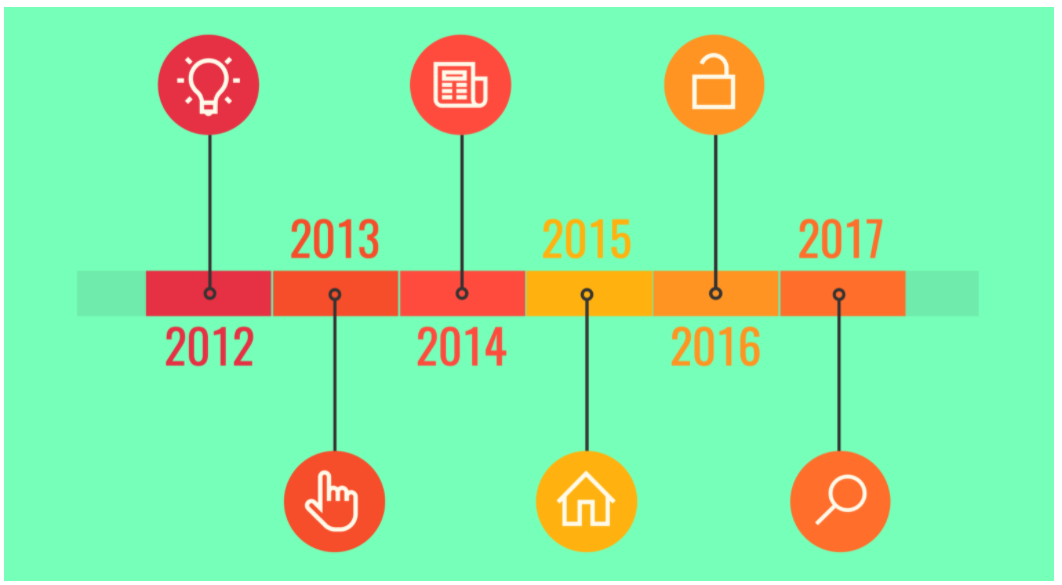
事件概述、議程/行程、突顯重要時間點、揭示重要訊息


時間線圖介紹(2/9)
時間線圖
時間線圖工具介紹(3/9)

西北大學Knight lab發展的Timeline JS工具
時間線圖
時間線圖建立Timeline(4/9)
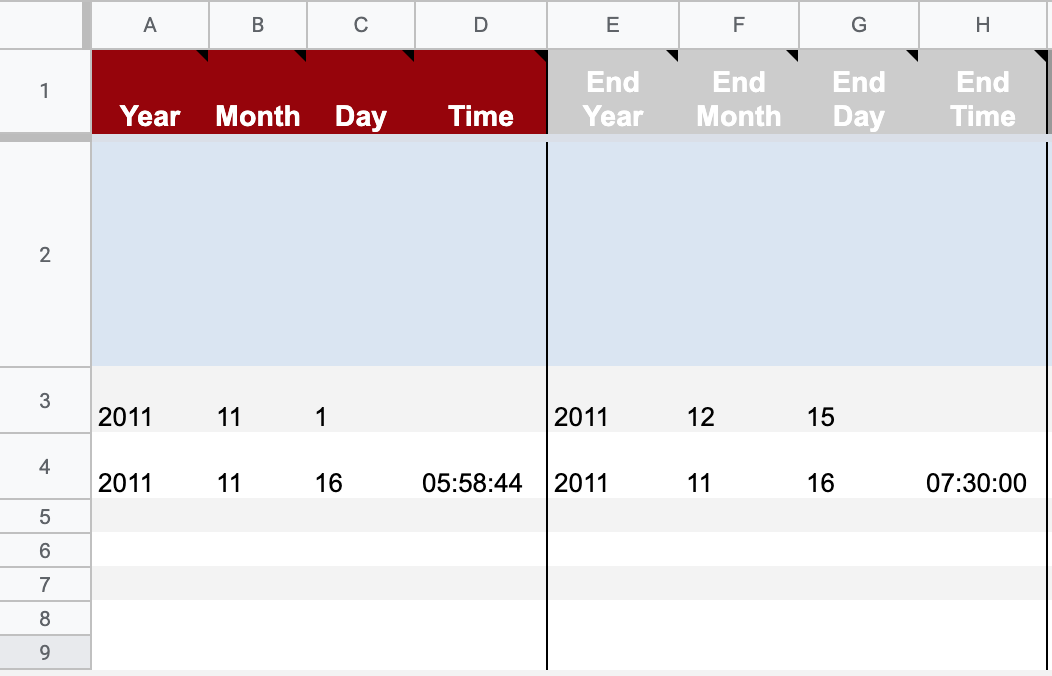
事件一
事件二
開始日期時間
結束日期時間
❷ 設定每個事件的時間
時間線圖
時間線圖建立Timeline(5/9)
事件標題
事件說明

媒體網址
標示來源
圖說
❸ 輸入每個事件的標題、說明、多媒體...
時間線圖
時間線圖建立Timeline(6/9)
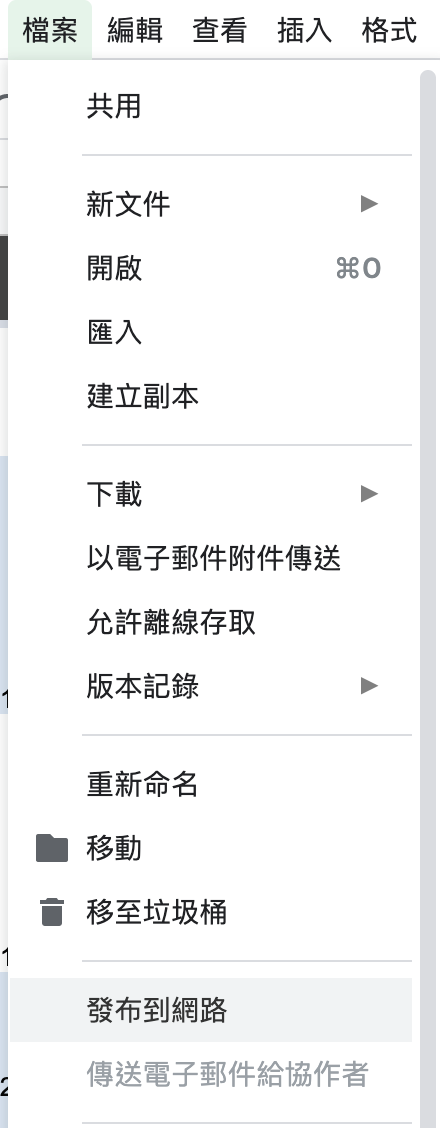
❹ 將Google試算表發布到網路
❺ 複製試算表網址
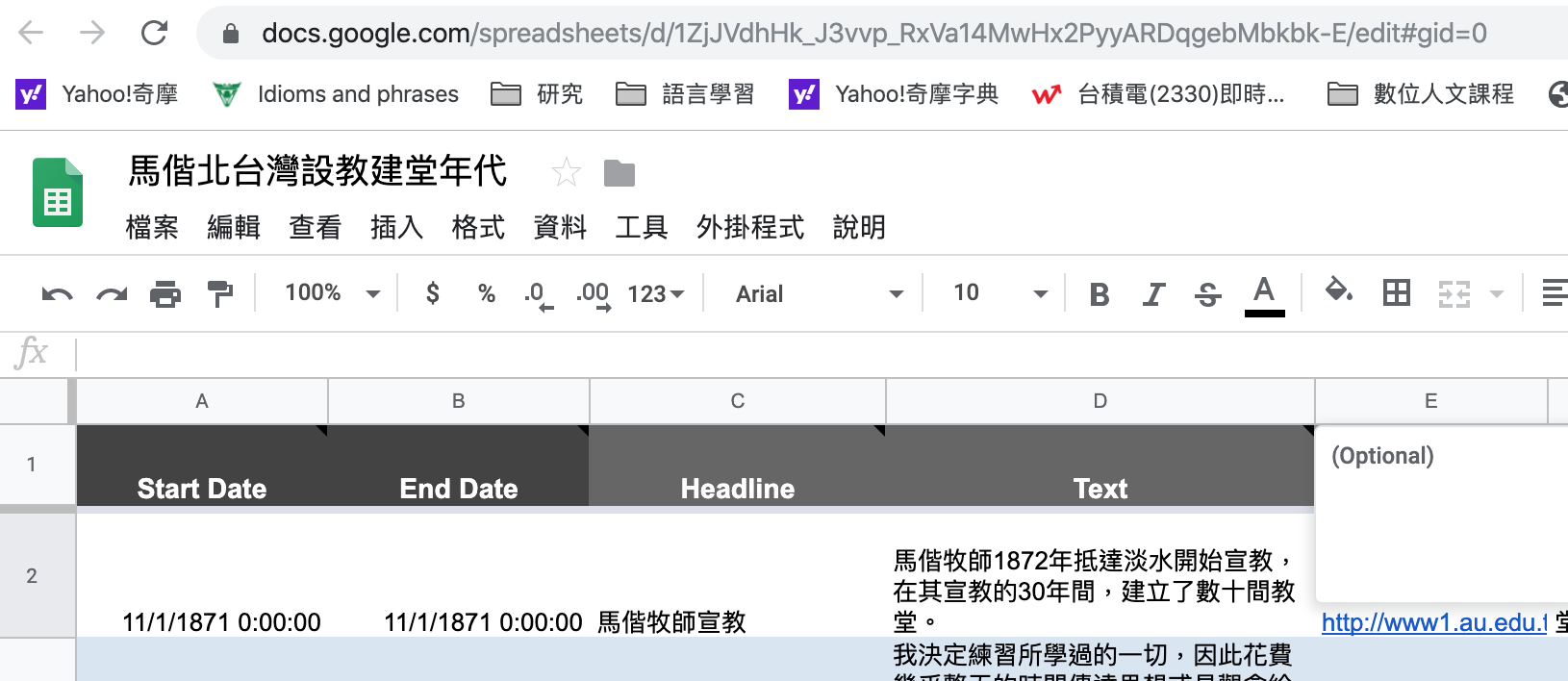
時間線圖
時間線圖建立Timeline(7/9)
❻ 試算表網址貼到Timeline官網
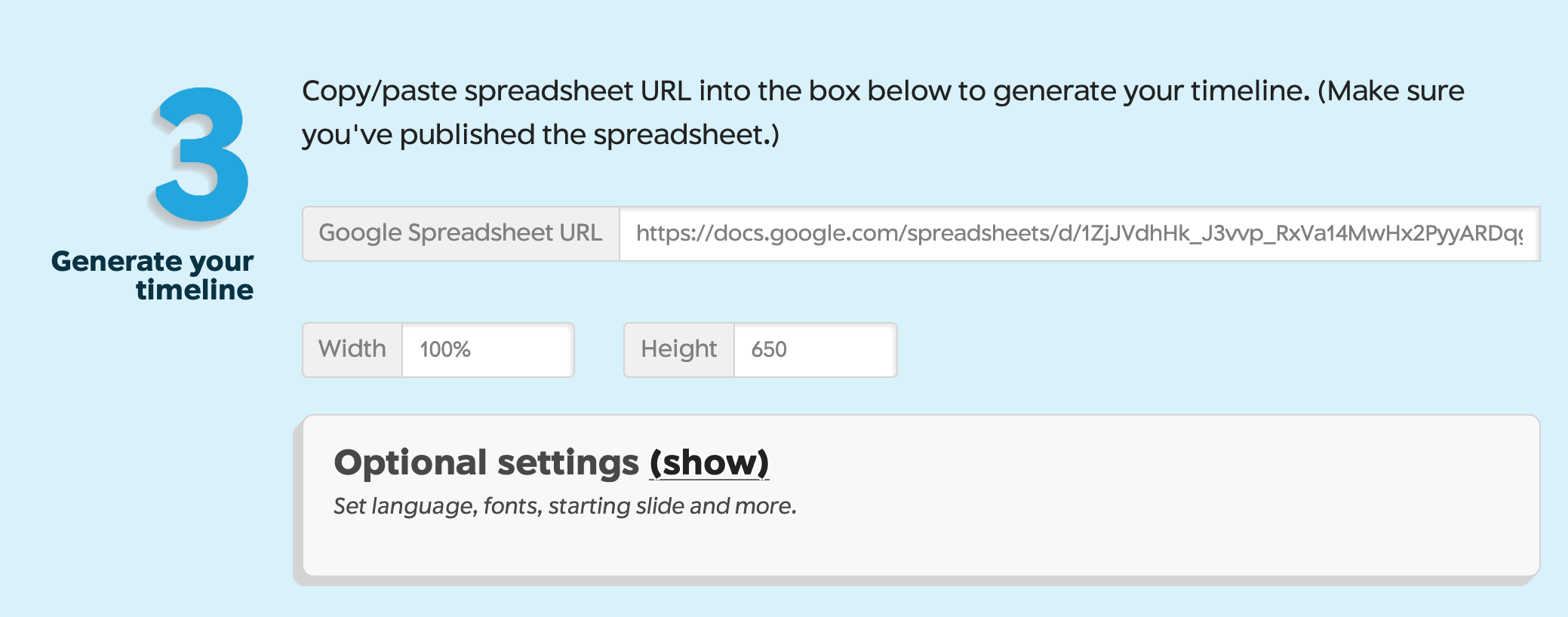
貼上試算表網址
有許多微調設定(可不設定)
時間線圖
時間線圖建立Timeline(8/9)
❼ 完成時間線圖(可分享、或內嵌到網頁)
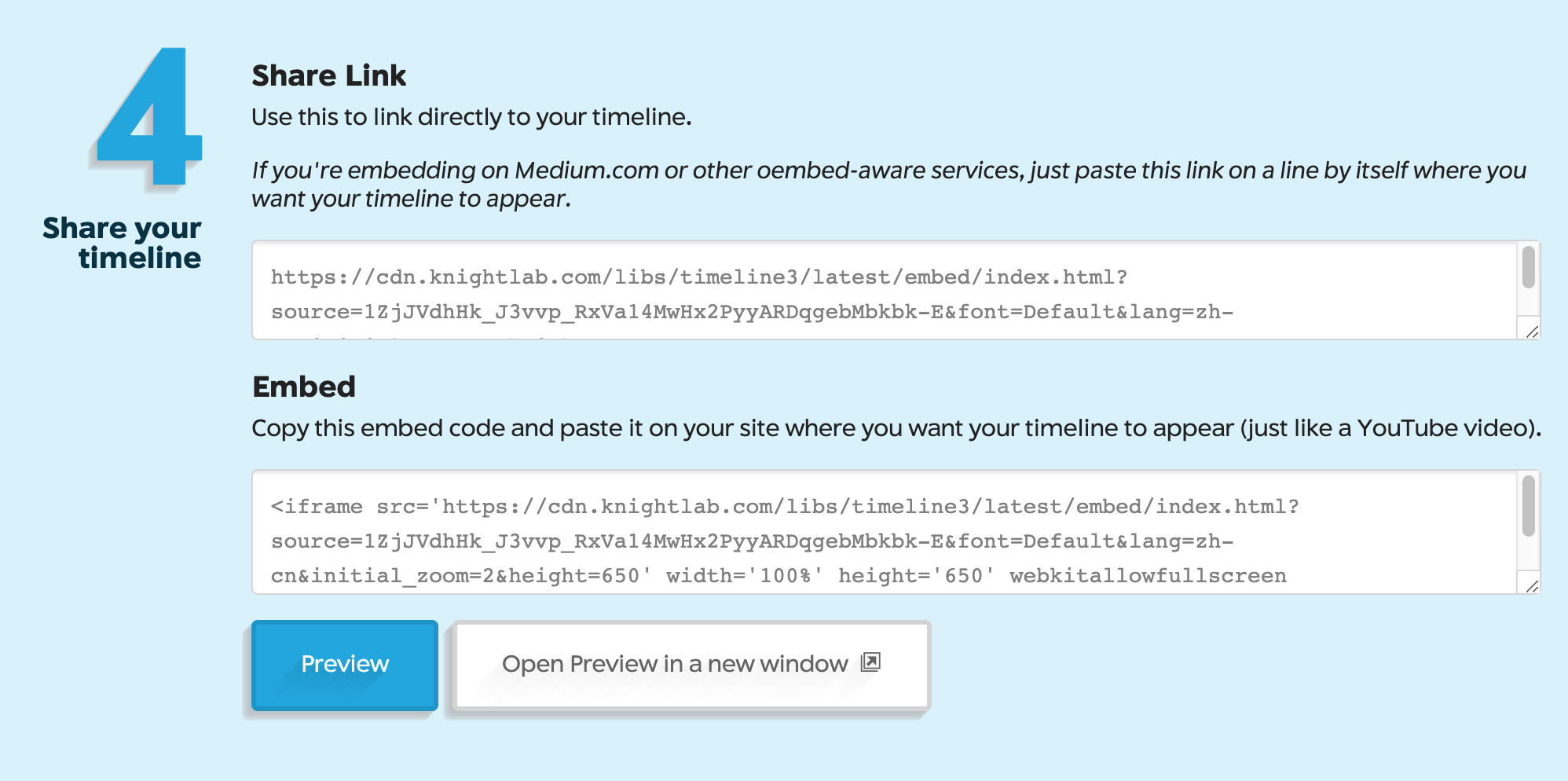
產生的試算表網址
產生的iframe標籤,可內嵌至網頁
預覽按鈕
時間線圖
時間線圖
- 下列建議僅包括馬偕史料,期末報告題目不在此限
- 從牛津學堂到真理大學(追本溯源)
- 設教建堂(宗教經營管理)
- 馬偕的書單(教育、學習管理)
- 馬偕與清法戰爭(決策)
- 出航
- 第一位環遊世界的台灣女性
- 宣教旅行(宗教經營管理)
- 宜蘭線
- 新竹-苗栗線
- 淡水河流域
時間線圖主題發想馬偕史料(9/9)
用資料說故事Storytelling
用資料說故事

明快的文字搭配清楚的圖片是講述故事的不二法門

你能用圖文並茂的方式講述你所挖掘的故事嗎

但是我故事講的不好,也只會PPT—還是用項目符號條列重點的那種

劇本結構 + 視覺技巧 = 好的視覺故事
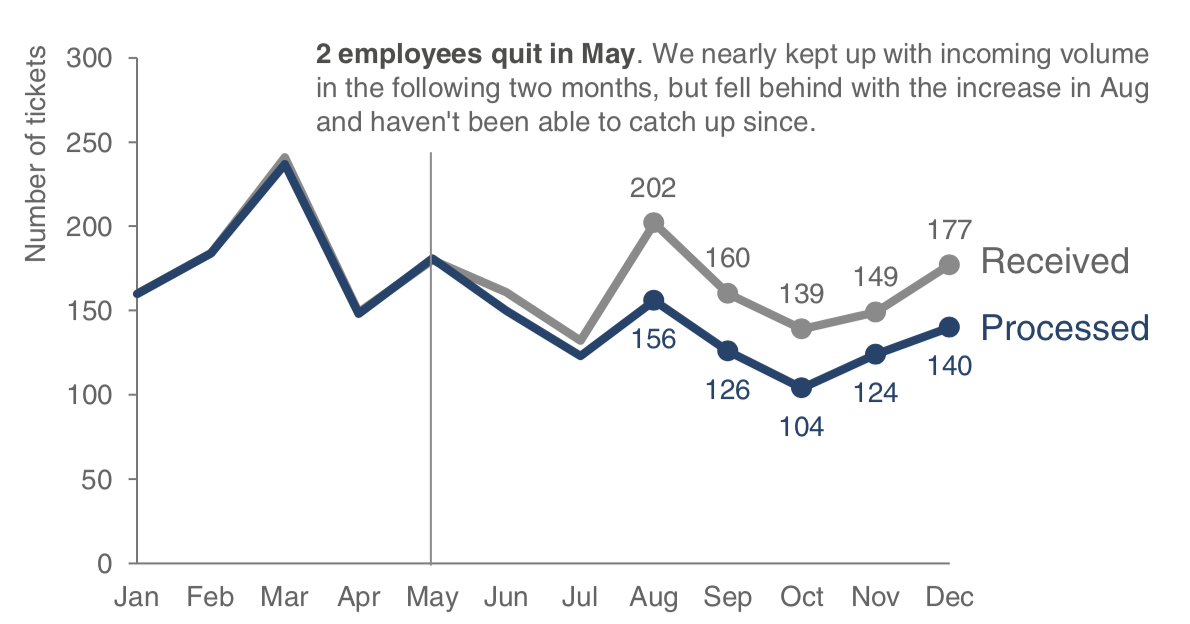
下單數量
處理數量
2位員工5月離職;6,7月勉強應付。但8月數量增加後便無法應付,之後再也趕不上進度
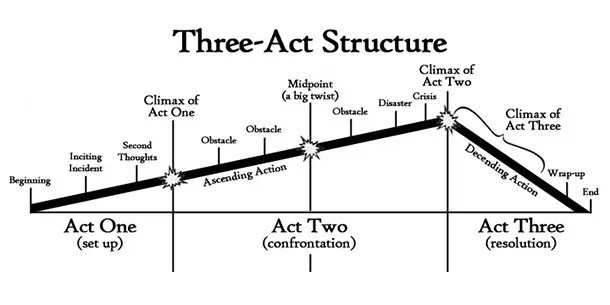
學會三個簡單步驟,你也可以是說故事高手

掌握情境
善用視覺
故事結構
步驟一:找出故事的情境
故事走向:砂礫中找珍珠 vs 展示珍珠項鍊
對象是誰
現況如何?反差何在?
如何弭平反差?
步驟二:用「三幕劇」手法說故事
佈局-衝突-結局
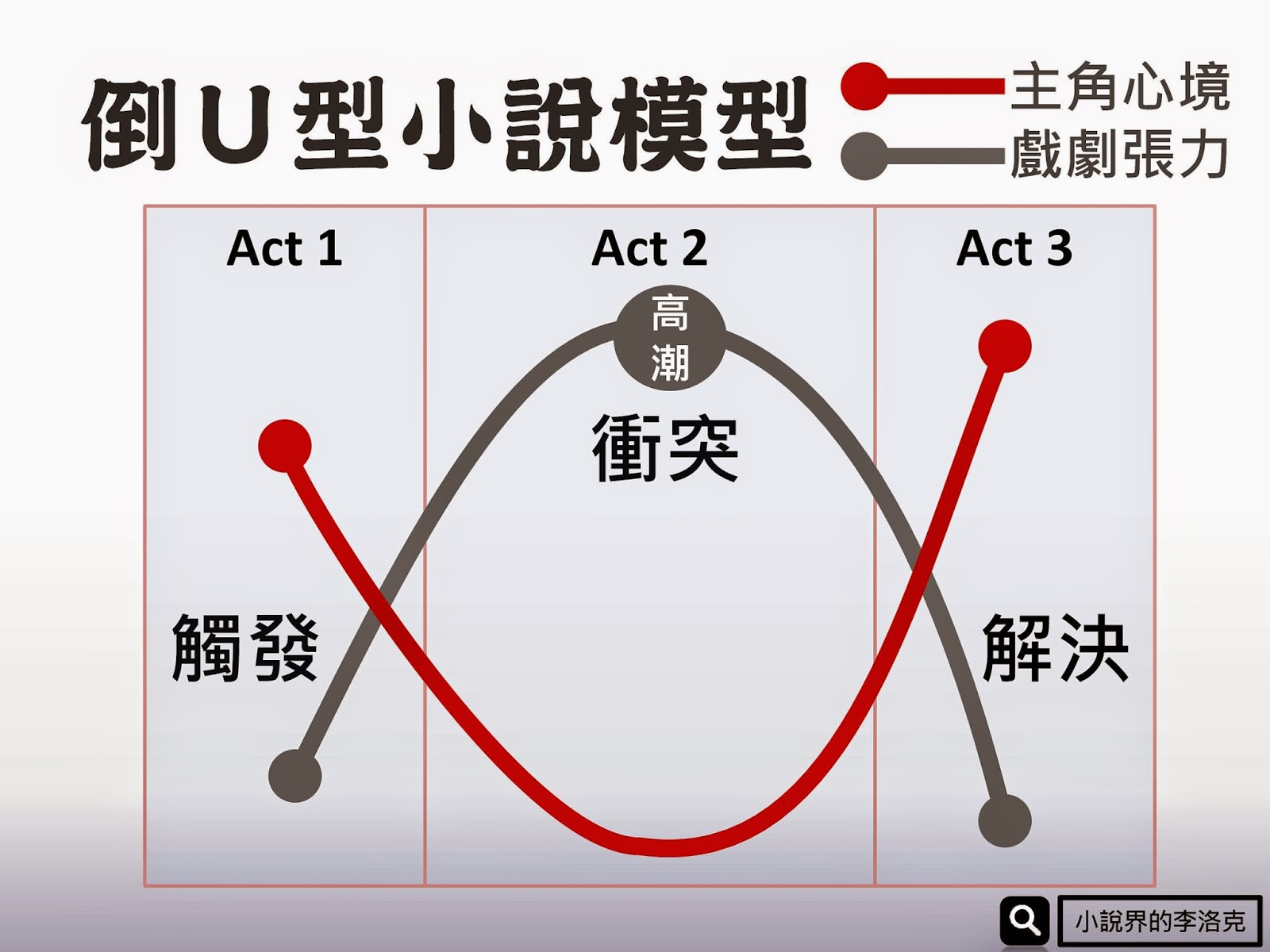
佈局
戲劇張力
主角心境
第一幕
第二幕
第三幕
數位人文概論
By au4163 王柳鋐
數位人文概論
Lesson 2: 文本分析與視覺化



