
質問記載場所
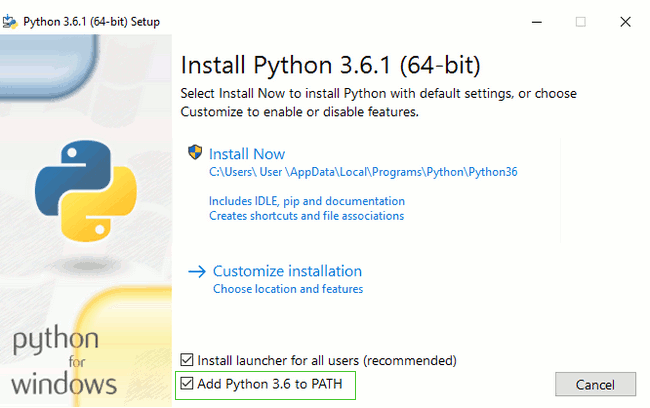
Windows
Mac
Atom *Atomはテキストエディタです





Notes Please check
スクレイピング クローリングとは? & 注意事項
HTMLとは、Hyper Text Markup Language
(ハイパーテキスト・マークアップ・ランゲージ)
の略で、Webページを作るための最も
基本的なマークアップ言語のひとつです。
WebページはHTMLというファイルだよ
普段、ChromeとかInternet Explorerとか
FireFoxなどのブラウザと呼ばれるアプリで見ているWebページは、HTMLやCSS、JavaScriptなどで書かれています。
インターネットの仕組み
HTMLなどのファイルが世界中にある、
どこかのサーバーに保存されています。
私たちは、普段ブラウザを通して、その情報を見ています。
例えば、このスライドのURL
https://slides.com/ayakomatsumoto/python_elv_2/
を入力すると、このファイルのデータが保存されて
いるサーバーへ情報を見にいきます。

画面上で右クリック
ページのソースを表示とすると
HTML(Webページ)のソースが表示されます。

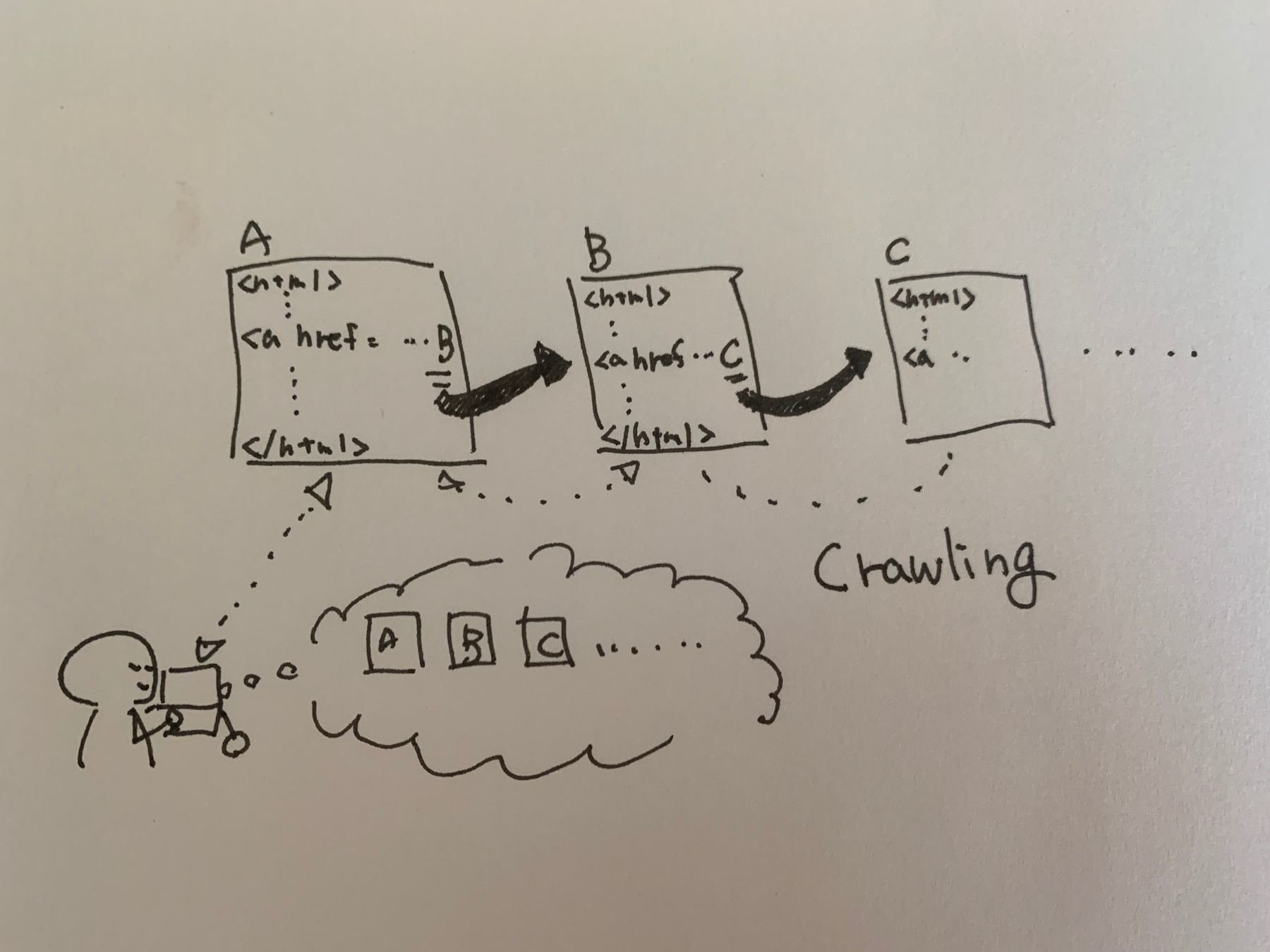
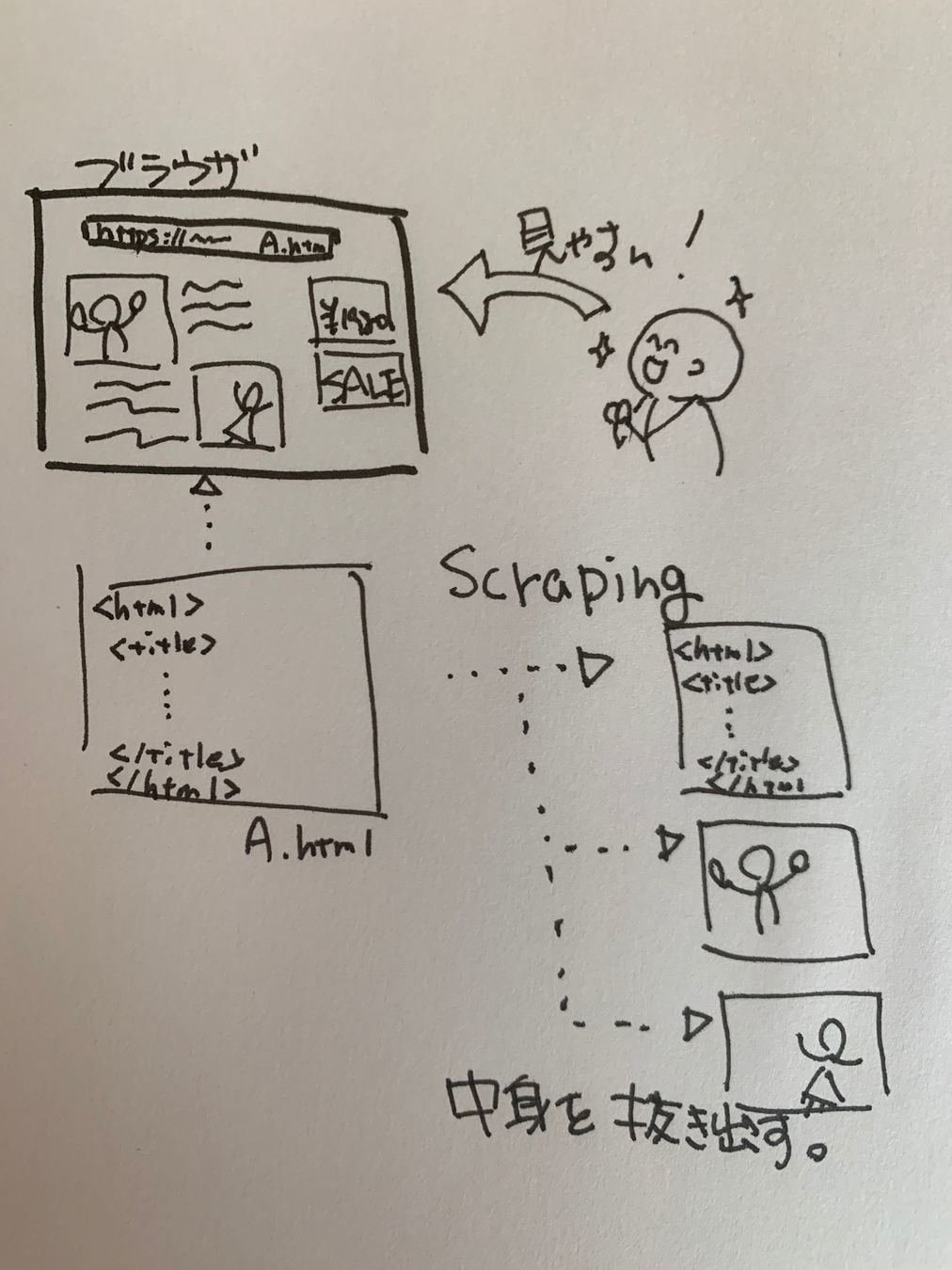
スクレイピング クローリングとは
Scraping
Webページから
必要な情報を抜き出す
Crawling
リンクを辿ってWebページを収集すること。
ScrapingとCrawling実施時の注意
- 著作権を侵害しないよう注意が必要
- Webページは基本的に著作物です
- 私的使用の範囲内の複製など、目的次第によって認められてもいるが、注意が必要
- Webサイトによっては、クローリングが禁止されている
- robots.txtやrobots metaタグで拒否されているページをクロールしないこと。
- Webサーバへの負担をかけないよう、配慮して作成すること。最低1秒以上は間隔をあけるようにしましょう。
robots.txtとrobots meta
| ディレクティブ | 説明 |
|---|---|
| User-Agent | 以降のディレクティブの対象となるクローラーを表す |
| Disallow | クロールを禁止するパスを表す |
| Allow | クロールを許可するパスを表す |
| Crawl-delay | クロール間隔を表す |
全ページのクロールを許可しない
User-Agent: *
Disallow: /全ページのクロールを許可する
User-Agent: *
Allow: /特定のクローラーを許可しない
User-Agent: *
Disallow: /old/
Disallow: /tmp/
User-Agnet:hogehoge-bot
Disallow: /User-Agnetヘッダーにhogehoge-bot という文字列を含む
クローラーは全てのクロールを禁止
他のクローラーは/old/ と/tmp/以下のみ禁止

ルールを守って利用しましょう。
この写真はフリー素材です。
step1 仮想環境を作ろう
仮想環境とは?
Python を使って開発や実験を行うときは、用途に応じて専用の実行環境を作成し、切り替えて使用するのが一般的です。こういった、一時的に作成する実行環境を、「仮想環境」 と言います。
コンピュータの中に擬似的に再現した環境とも言えます。
Python3 の標準ライブラリである venv を紹介します。
あなたのPC
ProjectA
Django
…
ProjectB
flask
…
ProjectB
Pyramid
…
Python
本日のディレクトリを作成
[スタート]→[Windowsシステムツール]→[コマンドプロンプト]を選択しましょうWindowsの古いバージョンの場合、[スタート] → [アクセサリ] → [コマンドプロンプト] です。
もしくは、「ウィンドウズキー + R」でファイル名を指定して実行を出して、
cmd と入力してエンター
Windows
[アプリケーション]→[ユーティリティ]→[ターミナル]を選択しましょう。
もしくは、「コマンド + シフト」で検索を出して
terminal と入力してエンター
Mac


本日のディレクトリを作成
$ mkdir elv_python
$ cd elv_pythonmkdir でその後に記載した名称でディレクトリ作成
cd でそのディレクトリの中に移動
仮想環境を作成
python -m venv myvenvWindows
Mac
python3 -m venv myvenv仮想環境を起動
myvenv¥Scripts¥ActivateWindows
Mac
source myvenv/bin/activate

myvenv は仮想環境の名前です。
これは自分で好きな名前をつける事もできます。
conda create -n myvenv pythonAnaconda
ライブラリのインストール
pip install requestsインストールしたライブラリの確認
pip freeze
requests 以外のものも入ってるけどOK
First time scraping
# インストールしたrequestsをインポートします
import requests
# 取得したいURLを書きます
url = "http://sandream.main.jp/elv_python/first"
# HTTPリクエストを送信してHTMLを取得します
response = requests.get(url)
'''
サーバから返されるエンコーディングが不明な場合に
コンテンツの中身をチェックした上で、適切な文字エンコーディングを
教えてくれます。
その上で、response.encodingにセットしてあげると極力文字化けなどが
おこらないようにしてくれます。
'''
response.encoding = response.apparent_encoding
# 取得したHTMLを表示します
print(response.text)
Webページの情報を取得しよう
テキストエディタを開いて、以下を写経します
作成したら、最初に作ったディレクトリにsc_1.pyの名称で保存してください。
作成したファイルの実行
python sc_1.pyWindows
Mac
python3 sc_1.py
Web上のCSV情報を読み取ろう
# インストールしたrequestsをインポートします
import requests
# 取得したいURLを書きます
url = "http://sandream.main.jp/elv_python/train.csv"
# HTTPリクエストを送信してHTMLを取得します
response = requests.get(url)
response.encoding = response.apparent_encoding
# 取得したHTMLを表示します
print(response.text)
作成したら、最初に作ったディレクトリにsc_2.pyの名称で保存してください。
作成したファイルの実行
python sc_2.pyWindows
Mac
python3 sc_2.py
Exercises1
複数のURLを連続で取得してみましょう
http://sandream.main.jp/elv_python/train.csv
http://sandream.main.jp/elv_python/first
上記2つの情報を1つのpythonファイルで取得してみましょう。
注意!
1つめと2つめの間には、
冒頭に import time
time.sleep(1)
と必ず入れるようにしましょう。(詳細は後ほど・・)
作成したら、最初に作ったディレクトリにsc_3.pyの名称で保存してください。
作成したファイルの実行
python sc_3.pyWindows
Mac
python3 sc_3.py
こうなったら正解!

頑張って!!
複数のURLを連続で取得(クローリング)
# 利用するライブラリをimportします
import time
import requests
# 取得したいURLをリストにしましょう
url_list = [
"http://sandream.main.jp/elv_python/train.csv",
"http://sandream.main.jp/elv_python/first",
]
# for文で順番に取り出しましょう
for url in url_list:
# HTMLの取得と表示
response = requests.get(url)
response.encoding = response.apparent_encoding
print(response.text)
# 1秒スリープ
time.sleep(1)
作成したら、最初に作ったディレクトリにsc_3.pyの名称で保存してください。

Parse HTML
HTMLを解析する
ライブラリのインストール
pip install beautifulsoup4インストールしたライブラリの確認
pip freeze
HTML情報
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>初めての解析</title>
</head>
<body>
<h1>初めての解析</h1>
<ul id="link-list">
<li>
<a href="http://sandream.main.jp/elv_python/1">どこにも行かない1</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/2">どこにも行かない2</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/3">どこにも行かない3</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/4">どこにも行かない4</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/5">どこにも行かない5</a>
</li>
<ul>
</body>
</html>このページから、リンク(aタグ)のテキストとリンク先を取得して表示してみよう。
HTML情報の解析
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/second"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのテキストを取得
text = a_tag.text
# aタグのhref属性を取得
link_url = a_tag['href']
# 表示します
print('%s: %s'%(text, link_url))
作成したら、最初に作ったディレクトリにsc_4.pyの名称で保存してください。
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/second"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのテキストを取得
text = a_tag.text
# aタグのhref属性を取得
link_url = a_tag['href']
# 表示します
print('%s: %s'%(text, link_url))
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>初めての解析</title>
</head>
<body>
<h1>初めての解析</h1>
<ul id="link-list">
<li>
<a href="http://sandream.main.jp/elv_python/1">どこにも行かない1</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/2">どこにも行かない2</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/3">どこにも行かない3</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/4">どこにも行かない4</a>
</li>
<li>
<a href="http://sandream.main.jp/elv_python/5">どこにも行かない5</a>
</li>
<ul>
</body>
</html>BeautifulSoupのインスタンス
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/second"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのテキストを取得
text = a_tag.text
# aタグのhref属性を取得
link_url = a_tag['href']
# 表示します
print('%s: %s'%(text, link_url))
bs = BeautifulSoup(response.text, 'html.parser')
とすることで、取得したHTMLの
情報に対し、BeautifulSoup内にあるメソッドを使えるインスタンスを作成しています。
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/second"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのテキストを取得
text = a_tag.text
# aタグのhref属性を取得
link_url = a_tag['href']
# 表示します
print('%s: %s'%(text, link_url))
ulタグ内だけを抽出

<ul id="link_list">
〜〜
</ul>
までの情報に絞り込みます。
ul_tag.find_all('a')
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/second"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのテキストを取得
text = a_tag.text
# aタグのhref属性を取得
link_url = a_tag['href']
# 表示します
print('%s: %s'%(text, link_url))
ul_tag.find_all('a')
ulタグの中で、aタグ(リンクタグ)の部分だけを取り出します。
find_allは引数に指定したタグの
情報をリスト形式で返します。

リストなので、for文を使って
1つずつ要素を取出していきます。
各情報を取り出す
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/second"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのテキストを取得
text = a_tag.text
# aタグのhref属性を取得
link_url = a_tag['href']
# 表示します
print('%s: %s'%(text, link_url))
取り出した要素の中から、
テキスト情報を取り出すには
a_tag.text(a_tagは取り出した要素名)
リンクURLを取り出すには
a_tag['href'](a_tagは取り出した要素名)
とします。
Exercises2

頑張ってぇ〜〜

これが出たら正解!
by スティーブ・ジョブズ
import time
import requests
from bs4 import BeautifulSoup
# URLからHTMLを取得します
url = "http://sandream.main.jp/elv_python/exercises"
response = requests.get(url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
# ulタグで囲まれた部分を抽出します
ul_tag = bs.find('ul')
# ulタグの中のaタグを抽出します
for a_tag in ul_tag.find_all('a'):
# aタグのhref属性を取得
link_url = a_tag['href']
# HTTPリクエストを送信してHTMLを取得します
detail_response = requests.get(link_url)
detail_response.encoding = detail_response.apparent_encoding
detail_bs = BeautifulSoup(detail_response.text, 'html.parser')
# pタグの取得
detail_ul_tag = detail_bs.find('p')
# pタグのテキストを表示
print(detail_ul_tag.text)
# 1秒スリープ
time.sleep(1)Summary
HTMLは世界中のどこかにある
サーバーの中のhtmlファイルの
情報をみにいってるよ
Scraping
Crawling
ルールを守って利用しましょう。
あなたのPC
ProjectA
Python
ProjectB
ProjectC
仮想環境
import requestsfrom bs4 import BeautifulSoupまとめ

今日はこれで終わりです!
ありがとうございました〜〜
python_elv_2
By Ayako Matsumoto




