LSTM & GRU
Revisão Rápida de algumas operações de Álgebra Linear
Produto Escalar
\vec{u} . \vec{v} = \left | \vec{u} \right | \left |\vec{v}\right| cos(\theta)
Produto Vetorial
\vec{a} \times \vec{b} = \begin{vmatrix}
\vec{i}& \vec{j}&\vec{k} \\
a_x& a_y & a_z\\
b_x& b_y &b_z
\end{vmatrix}
Produto de Hadamard
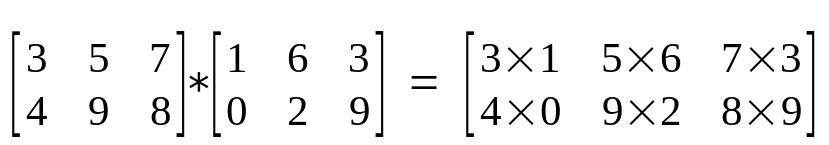
Como vimos na aula passada, Redes Neurais Recorrentes sofrem de vanishing gradient.
Vanishing Gradient
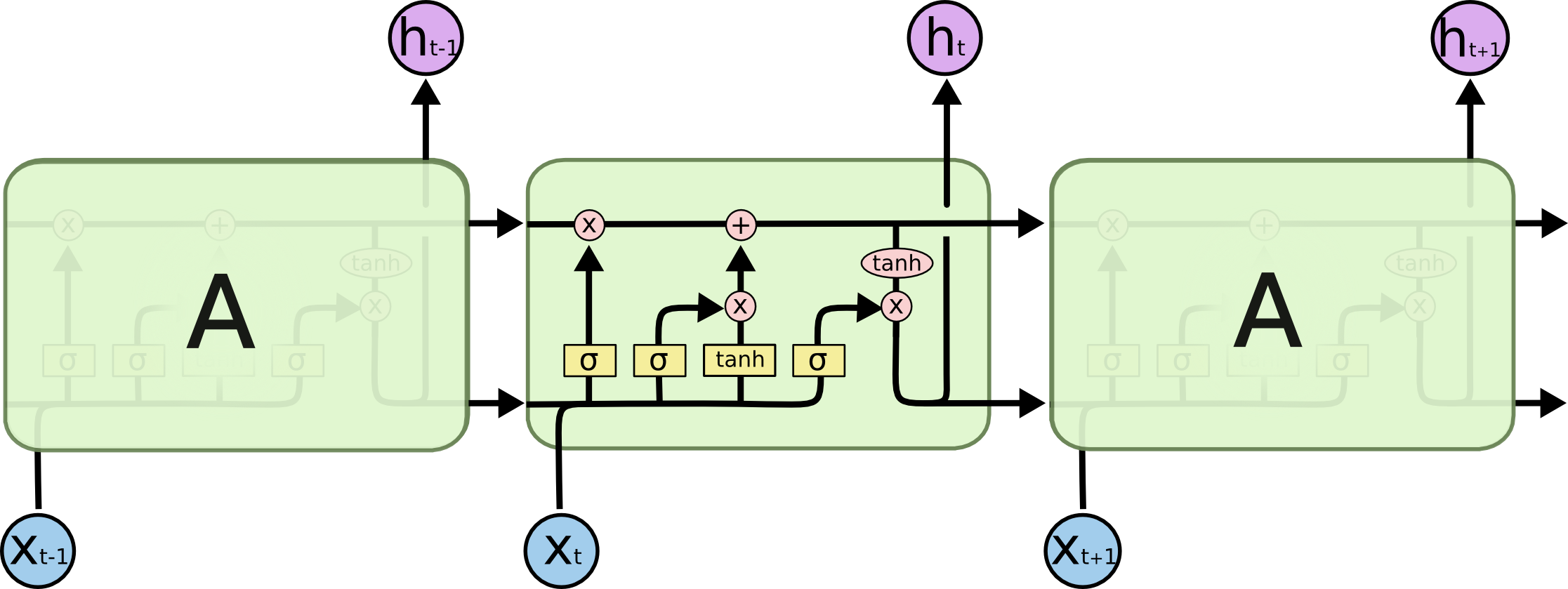
A LSTM combate isso ao criar um cell state onde informações podem fluir de um estado anterior ao próximo, gerando uma espécie de memória na rede.
A LSTM possui 3 gates principais:
-
Forget gate
-
Input gate
-
Output gate
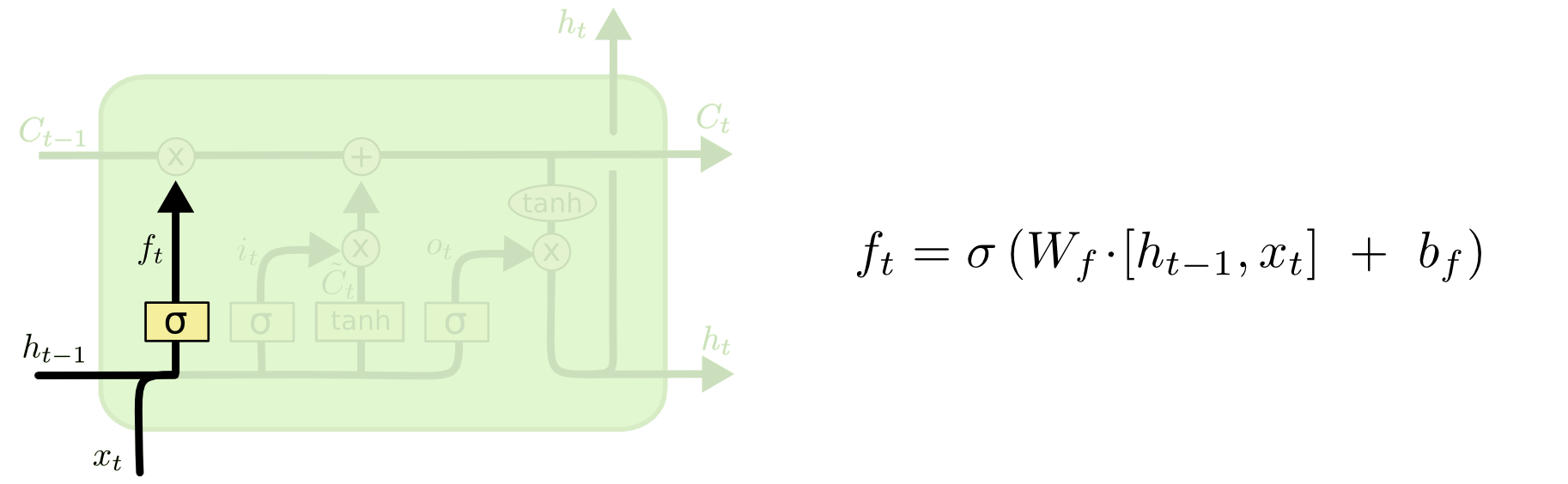
Forget Gate
O que deve ser esquecido?
Decide o que apagar do cell state, valores próximos de 1 serão mantidos e próximos de 0 serão descartados.
Input Gate
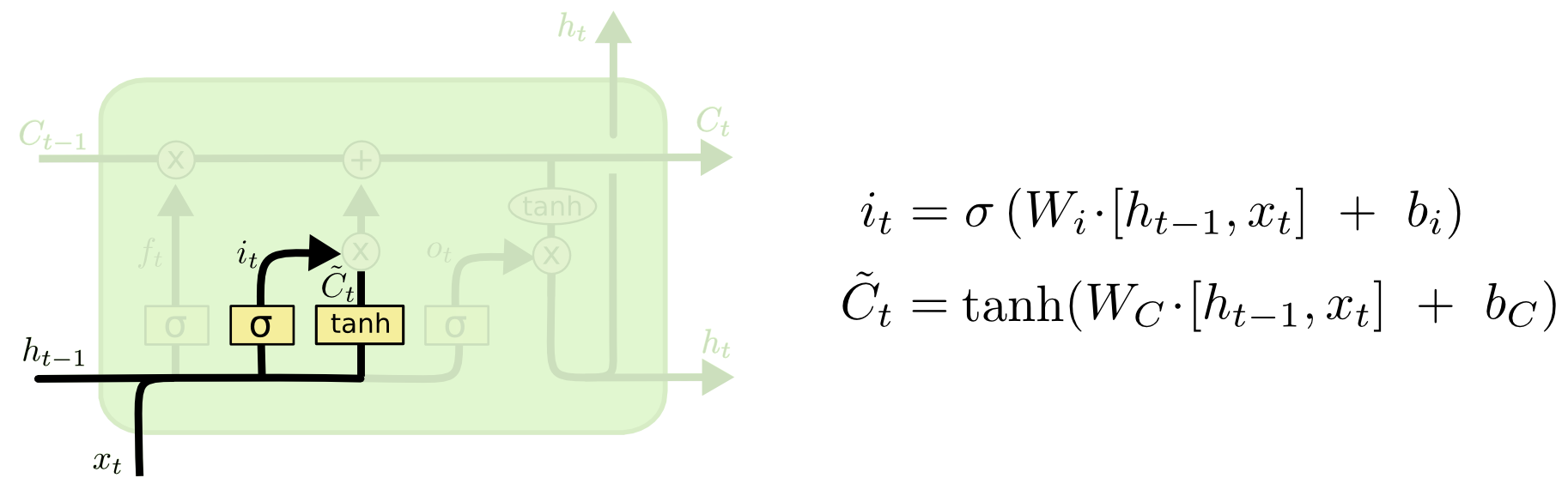
\(\tilde{C}_t\) calcula candidatos a serem armazenados no cell state
O input gate decide quais desses valores candidatos devem ser atualizados no cell state
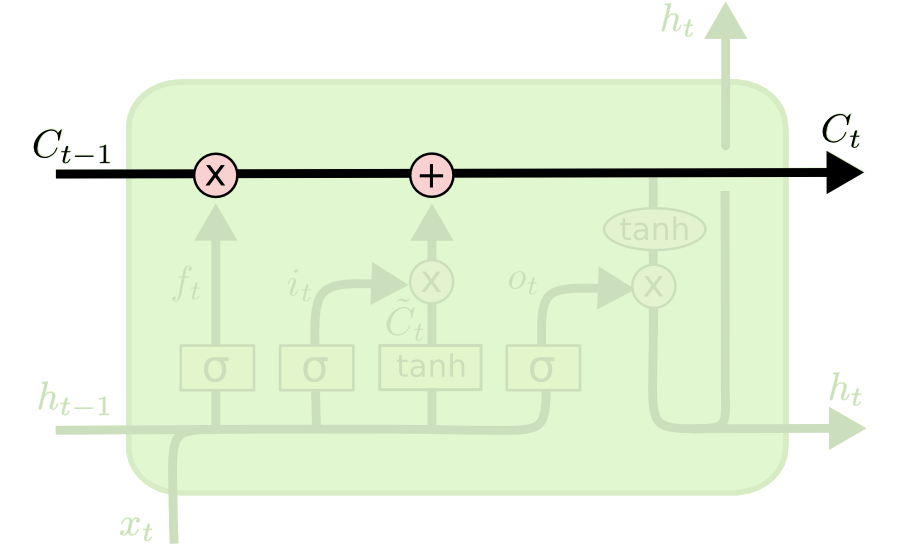
Cell State
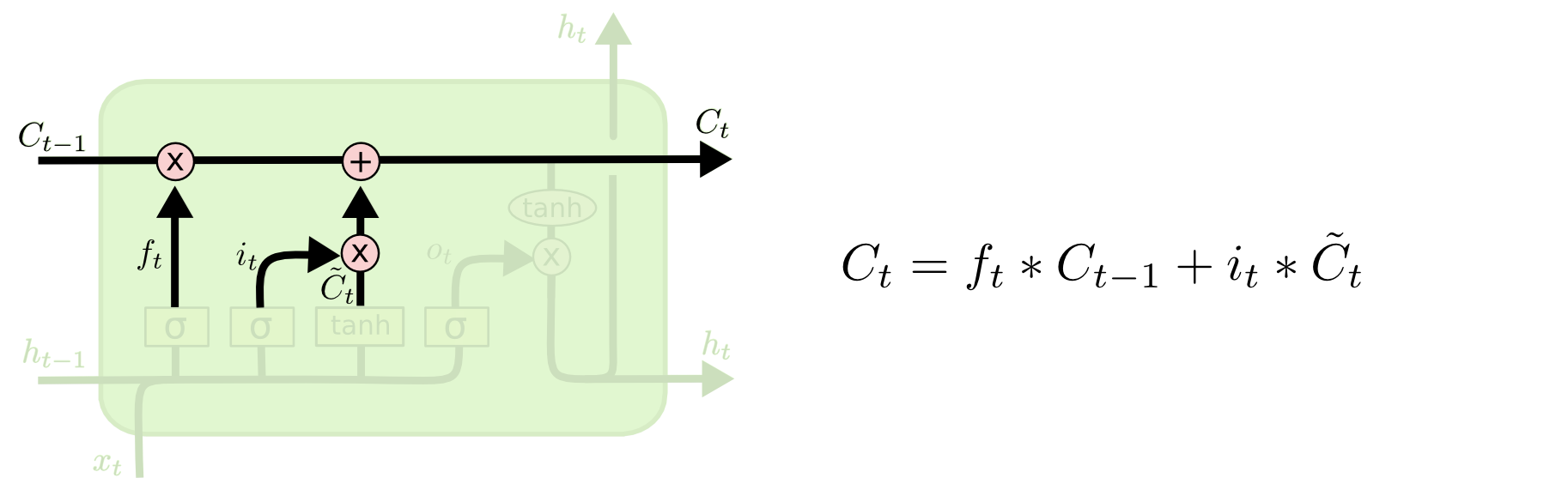
Os valores “selecionados” do cell state anterior e do candidato serão combinados para formar o novo cell state
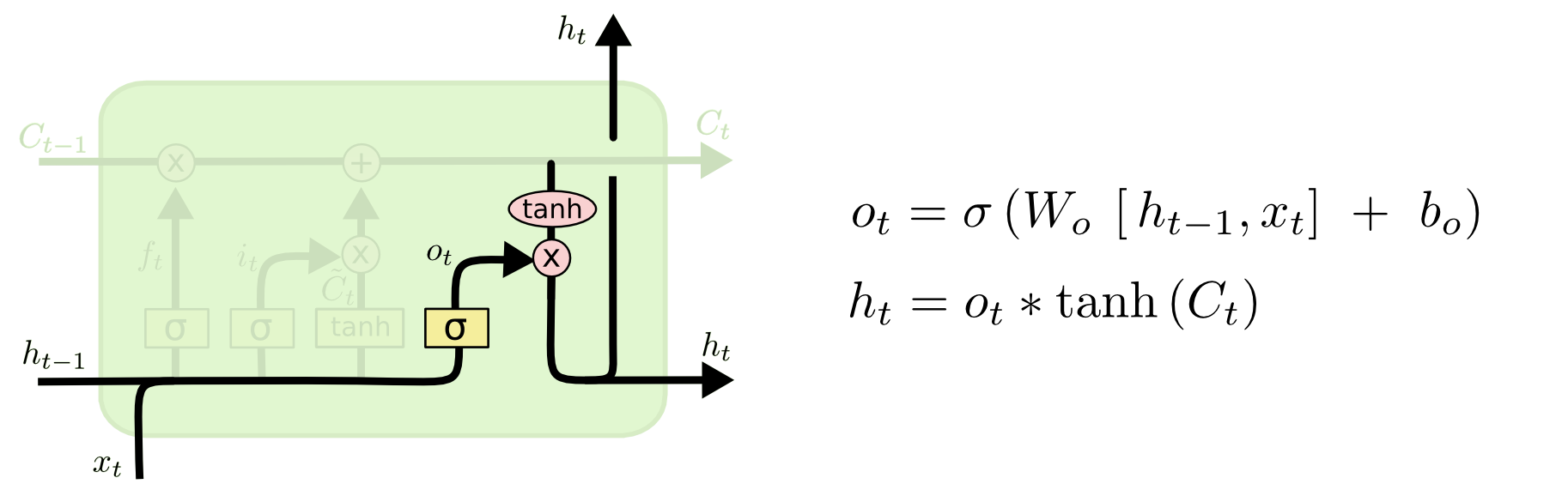
Output Gate
Novamente uma sigmoide, “seleciona” os elementos do cell state que serão utilizados como output.
Recapitulando LSTM
O forget gate decide o que manter das etapas anteriores, o input gate decide que informação manter da etapa atual e o output gate determina o próximo hidden state.
tf.keras.layers.LSTM(
units,
activation="tanh",
recurrent_activation="sigmoid",
use_bias=True,
kernel_initializer="glorot_uniform",
recurrent_initializer="orthogonal",
bias_initializer="zeros",
unit_forget_bias=True,
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
implementation=2,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
time_major=False,
unroll=False,
**kwargs
)
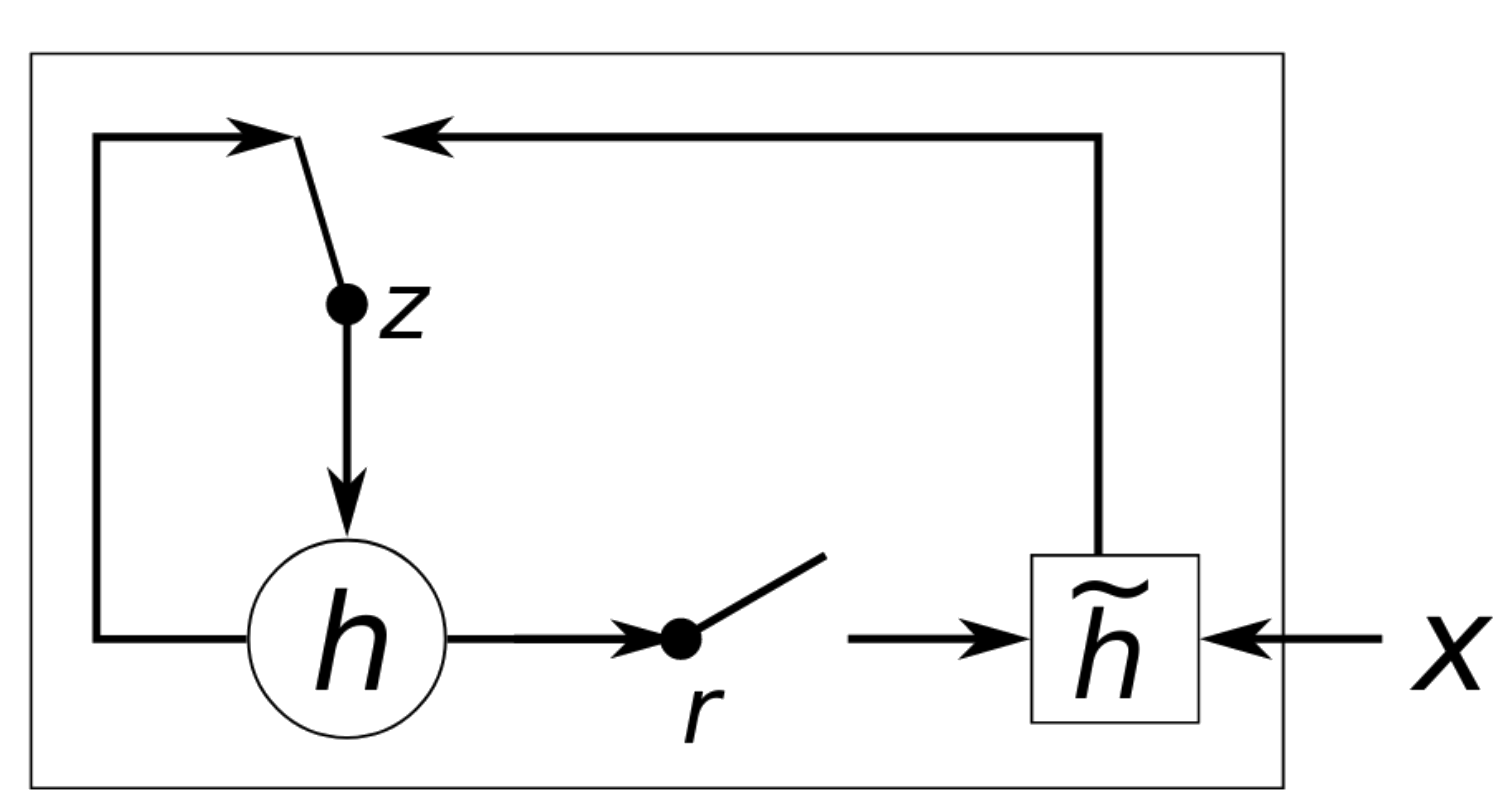
Forget e input gates são unidos em um unico update gate z
Cell state e hidden state passam a ser uma única entidade

GRU - Gated Recurrent Unit
-
Update Gate z controla se o estado h deve ser atualizado com \(\tilde{h}\)
- Reset Gate r controla se o estado h anterior deve ser ignorado
tf.keras.layers.GRU(
units,
activation="tanh",
recurrent_activation="sigmoid",
use_bias=True,
kernel_initializer="glorot_uniform",
recurrent_initializer="orthogonal",
bias_initializer="zeros",
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
implementation=2,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
time_major=False,
reset_after=True,
**kwargs
)
GRU Vs LSTM
LSTM é um pouco mais poderosa mas GRU é mais rápida
Quando usar cada uma?
Dificilmente você encontrará uma RNN pura sendo usada, mesmo para arquiteturas encoder decoder é mais comum usarmos LSTM, GRU, ou outras redes derivadas.
Redes Bi-direcionais
Mesma ideia, mas as 2 redes recebem as tokens em ordem contrária e seus hidden states no final são concatenados.
Isso permite incluir contexto de ambas as direções.
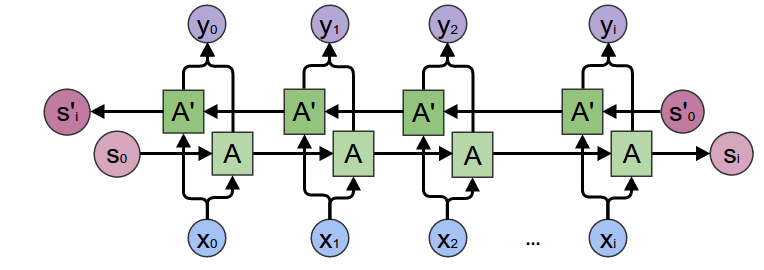
Redes Bi-direcionais
Adicionar probabilidades condicionais em ambas as direcoes aqui
tf.keras.layers.Bidirectional(
layer,
merge_mode="concat",
weights=None,
backward_layer=None,
**kwargs
)
06 - Lstm&gru
By barzilay



