Transformers
Overview
- Transformer
- Self Attention
- Multi Headed
- Encoder
- Decoder
- Mascaras
- Positional Encoding
- Transformer XL
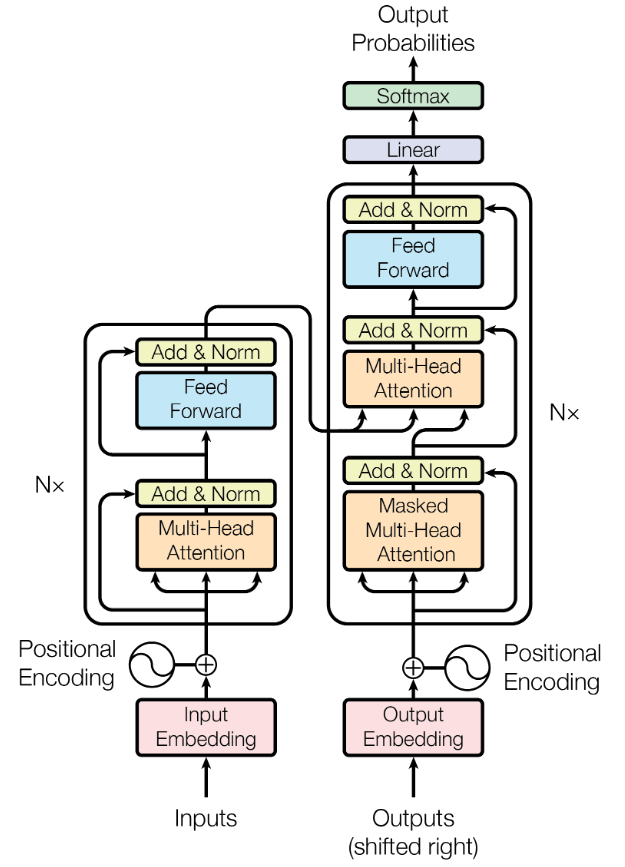

Note que:
Não há recorrência!
A(s) sentença(s) é(são) processada(s) de uma vez
Attention is all you need
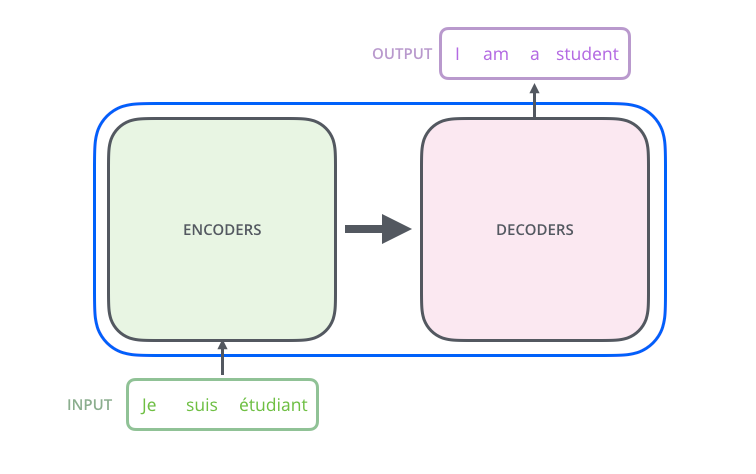
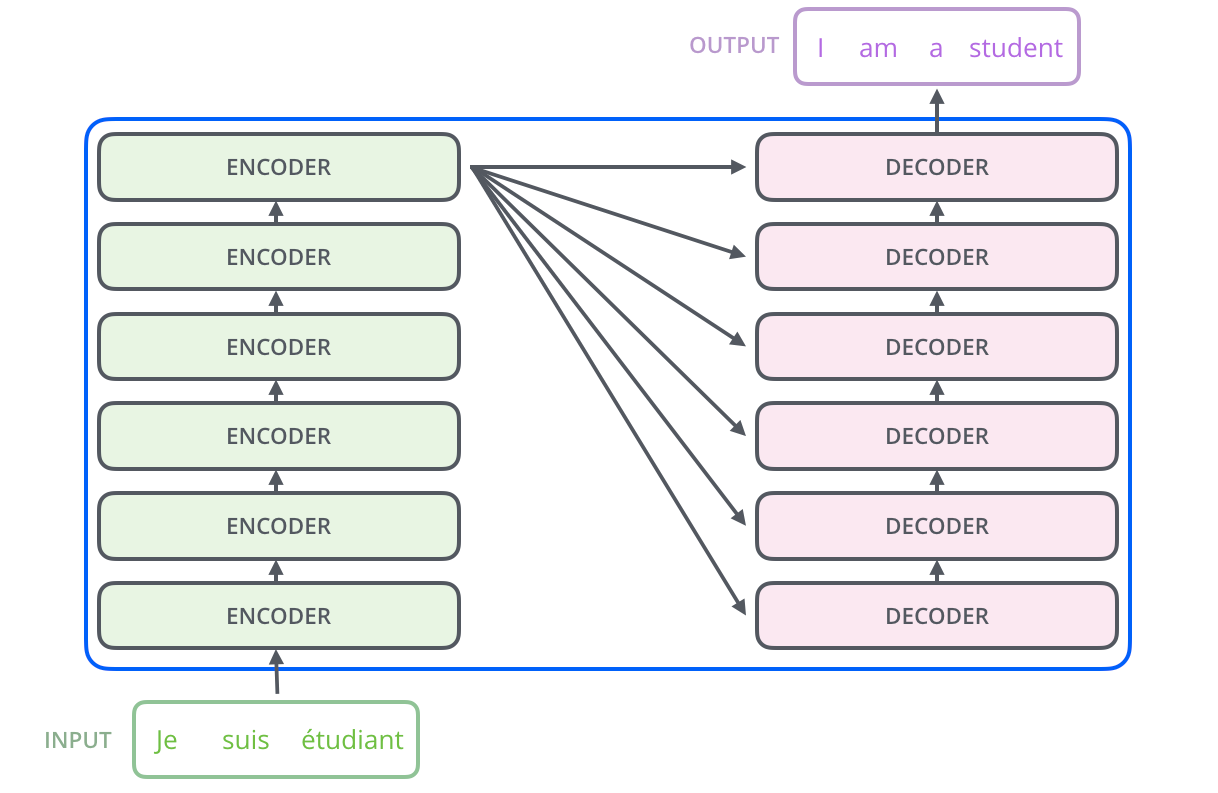
Auto-Atenção (Self-Attention)
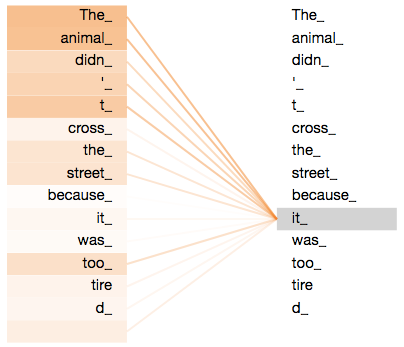
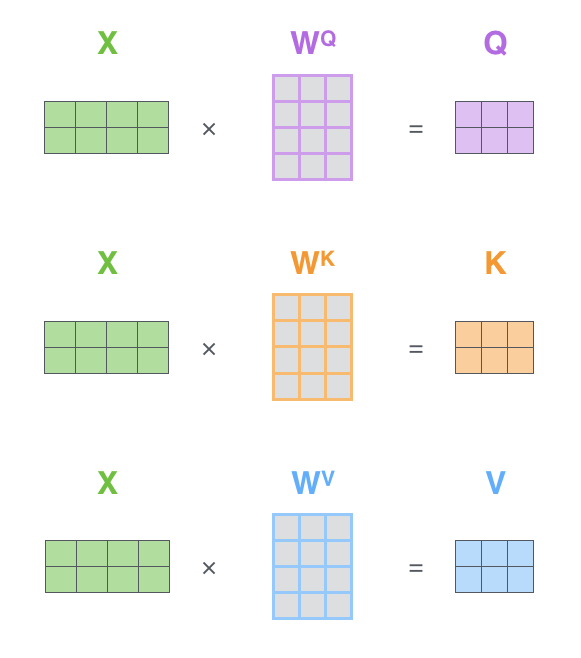
Key, Query, Value
A partir de um mesmo embedding geramos representações distintas para cada palavra: um key, uma query e um value
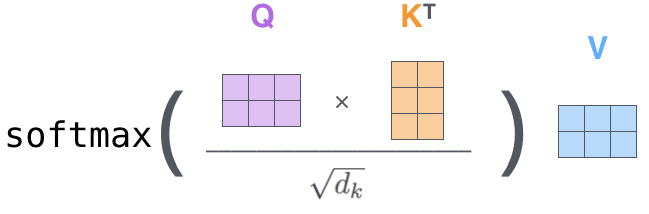
Auto-Atenção
- Produto escalar é a função score
- \( d_k \) é a dimensão de key
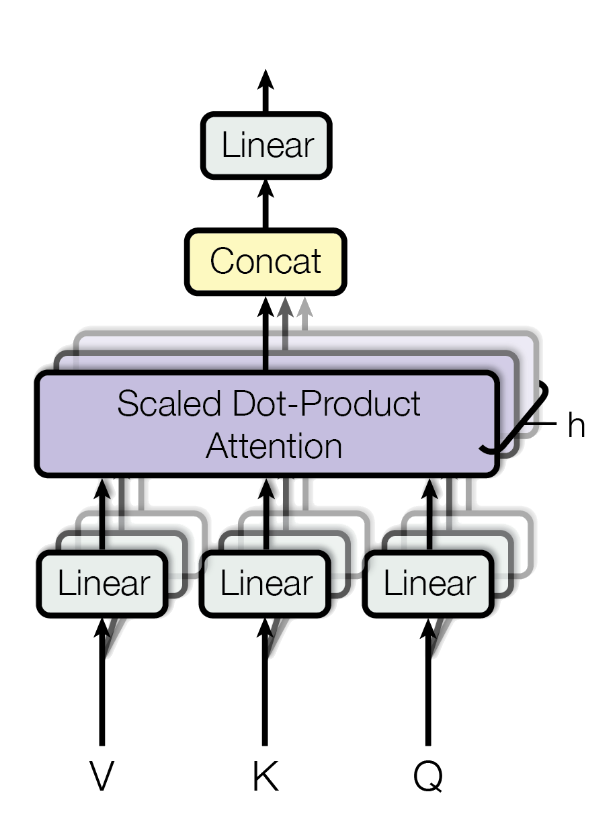
Multi-Headed Attention
Como funcionam as múltiplas cabeças?
- \(Q,W,V\): \(nWords \times embedDim\)
- As colunas são de $Q,W,V$ são particionadas em $$projDim = embedDim/nHeads$$
- Cada cabeça pode aprender um padrão diferente
- Mas como? Todas cabeças não são "iguais"?
Como as cabeças se especializam?
- \(Q = \)\(W^Q\) \(\cdot X, K=\)\(W^K\) \(\cdot X \), \(V =\) \(W^V\) \(\cdot X\)
- Devem ser aprendidas \(W^Q, W^K, W^V\)
- É conveniente que \(W^Q, W^K, W^V\) sejam inicializadas diferentemente
- Estas matrizes são responsáveis por aprender a especialização de cada cabeça
Utilizando diversas "cabeças" de atenção nós podemos capturar múltiplas relações

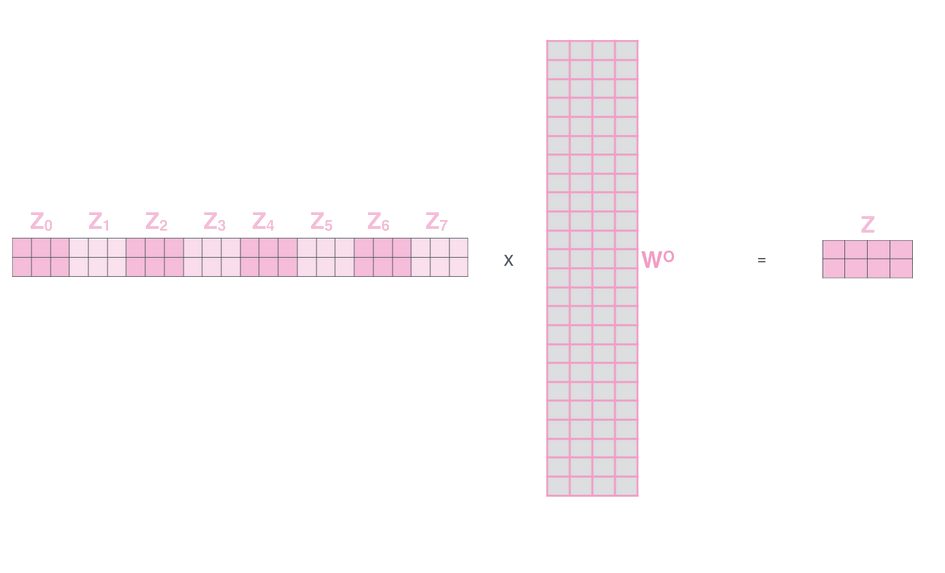
Concatenar o output de cada cabeça e passa-las por uma camada linear
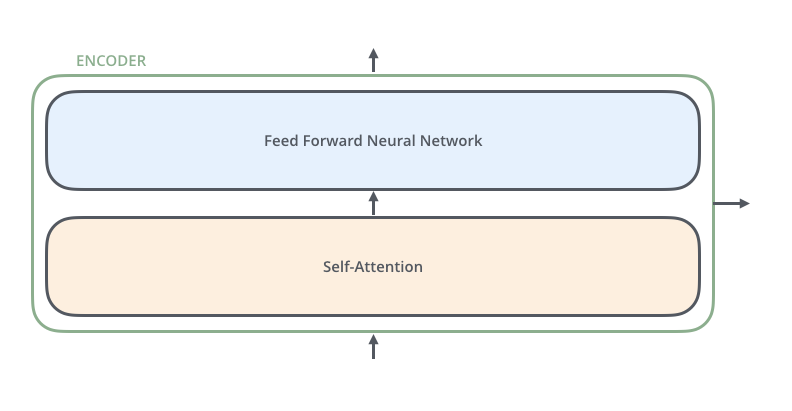
De volta ao Encoder
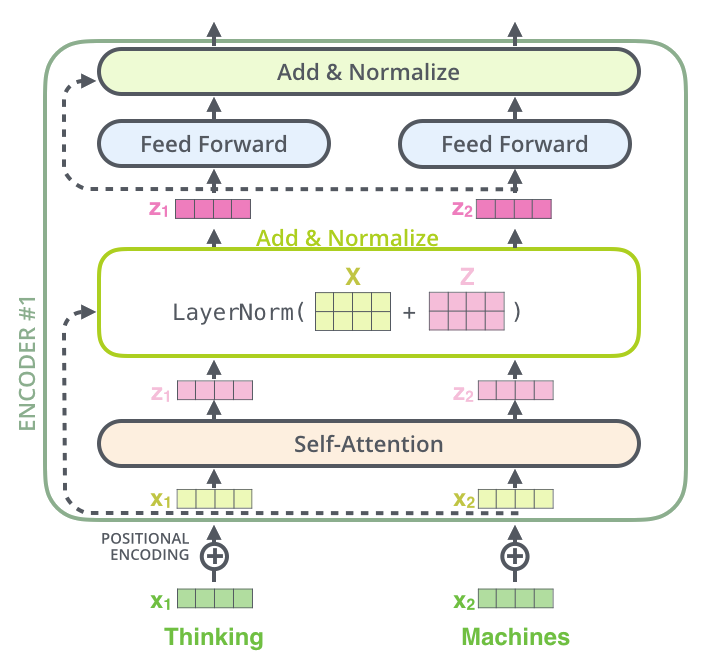
Conexão residual e normalização após cada etapa de auto-atenção
Conexões Residuais
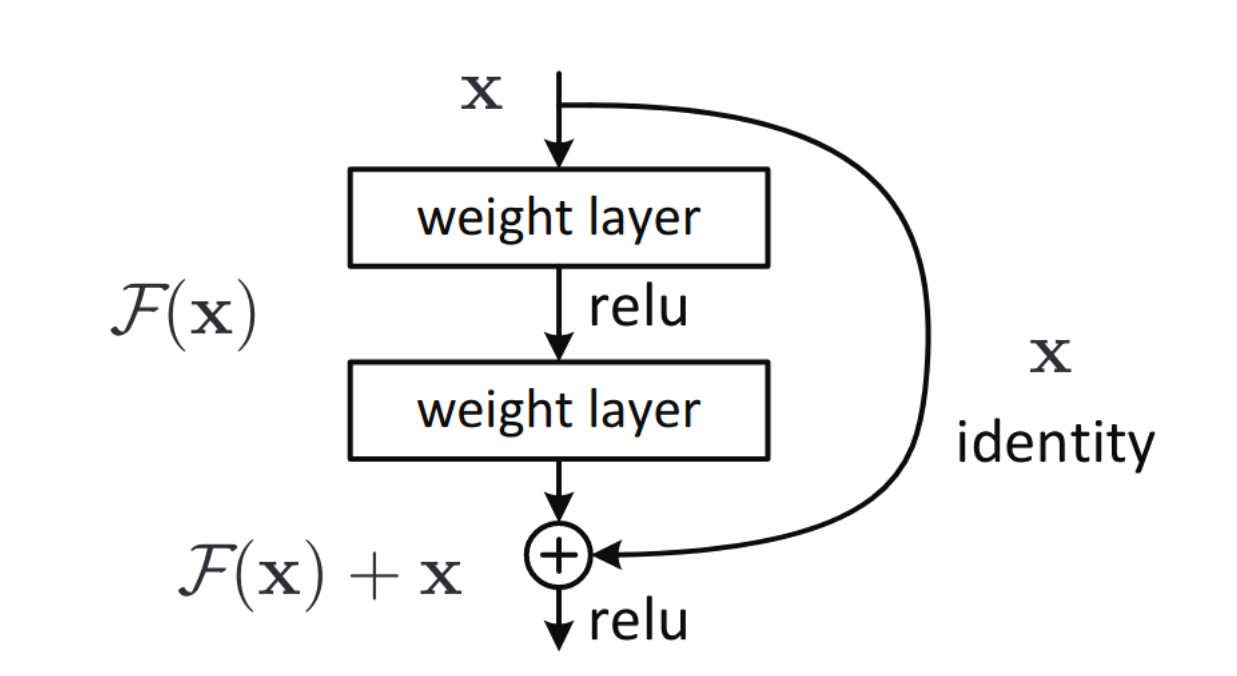
Também conhecidas como Skip-Connections
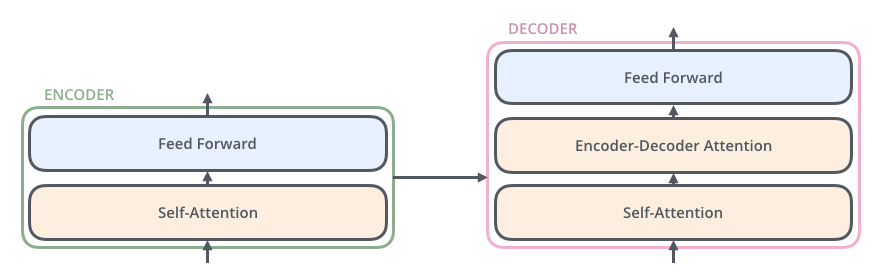
Decoder
Encoder Decoder Attention
Após uma camada de auto-atenção no decoder, temos uma etapa de atenção entre o encoder e o decoder.
Os outputs do encoder são utilizados como Keys e Values enquanto os outputs da etapa de auto-atenção do decoder são usados como querys.
Encoder Decoder Attention
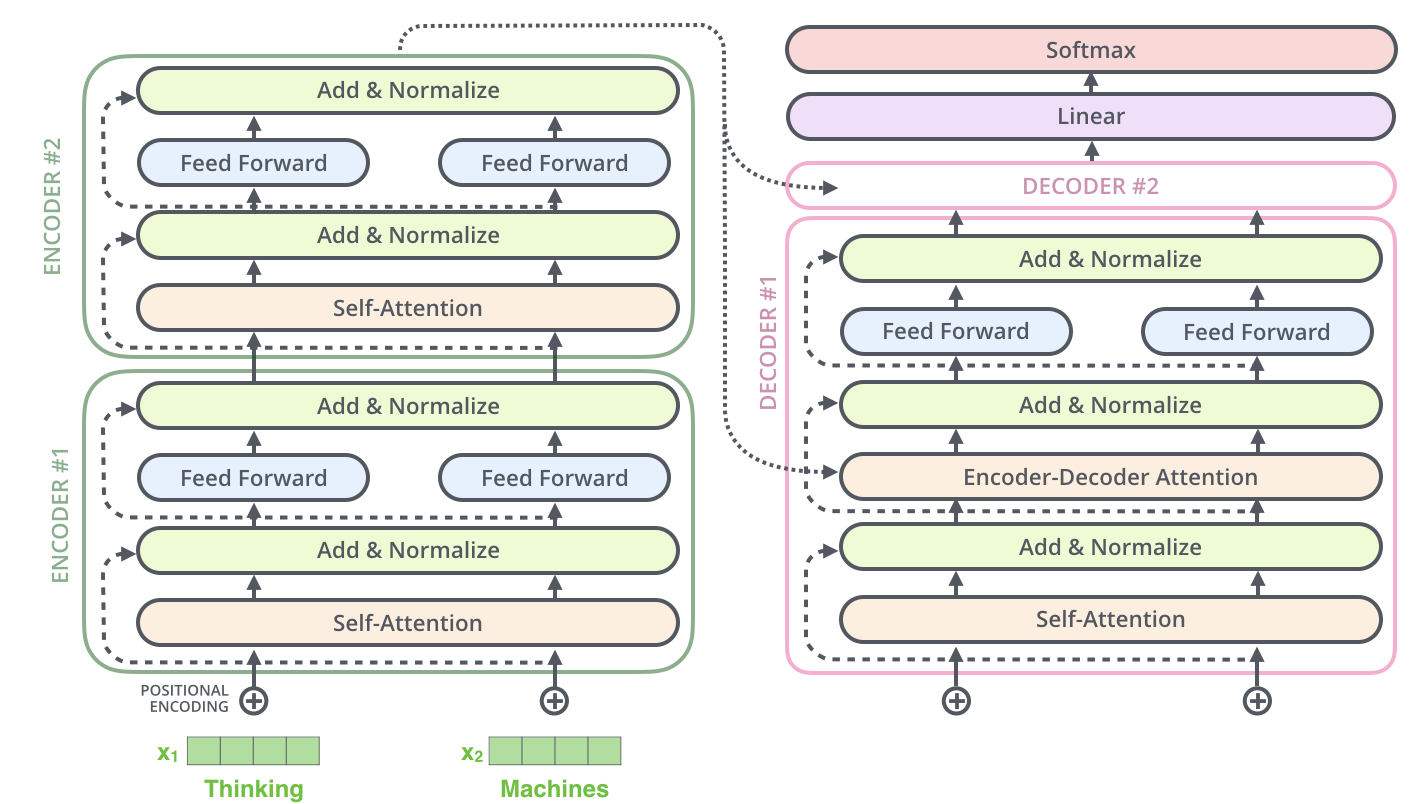
Assim como no Encoder, o Decoder possui conexões residuais
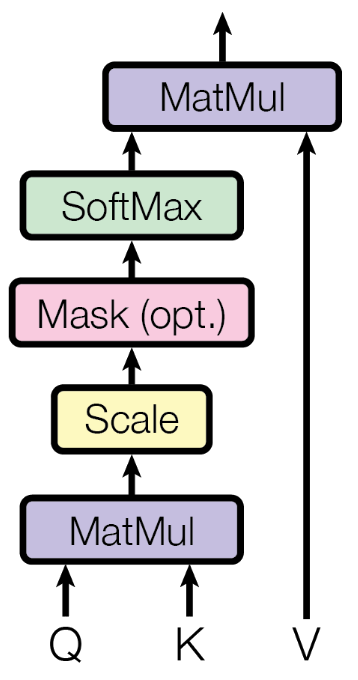
Masking no decoder
Mas como fazer para o decoder não "olhar o futuro" durante o treinamento?
Nós usamos Máscaras
Masking no decoder

Masking no decoder
Em amarelo temos as tokens visíveis para o decoder, em roxo temos a mascara.
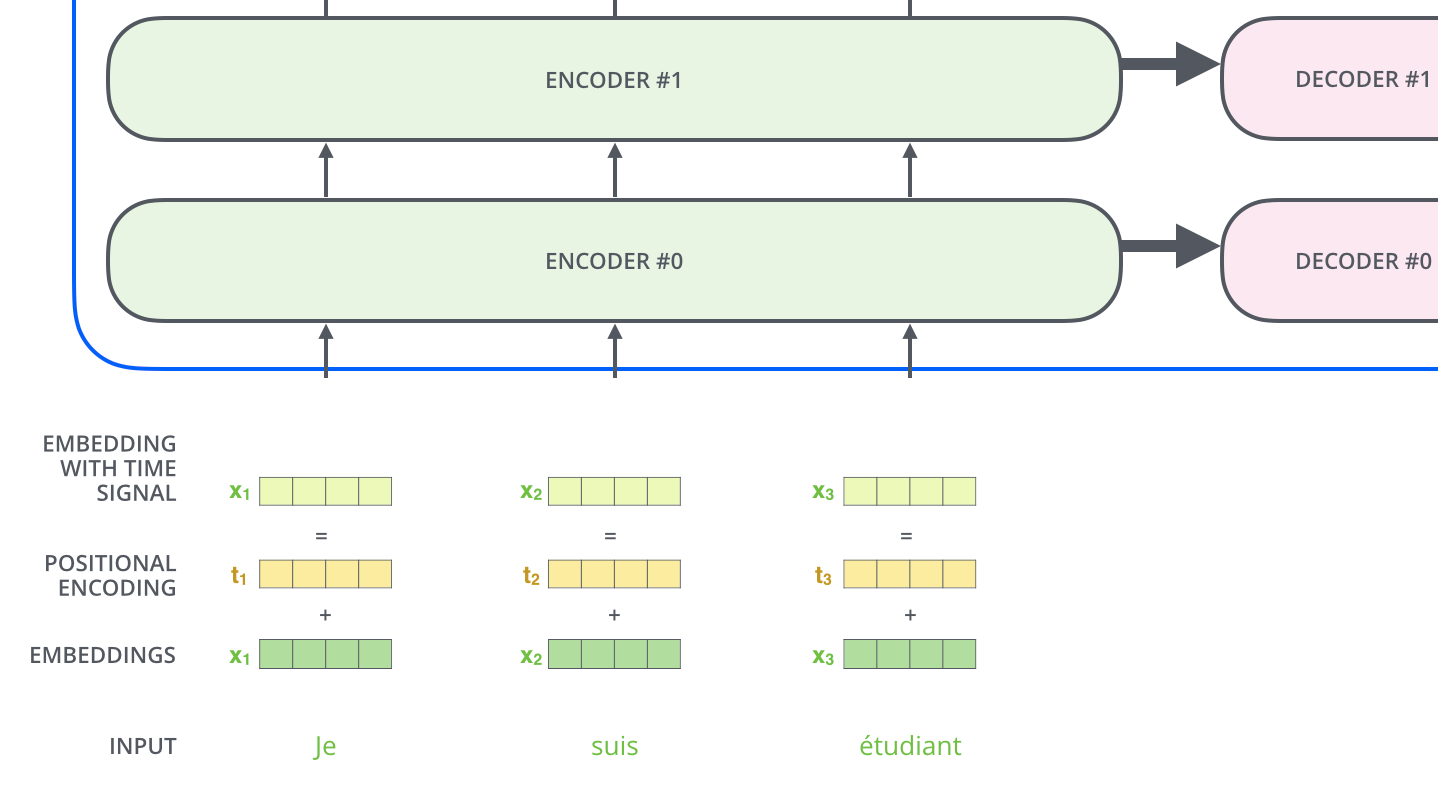
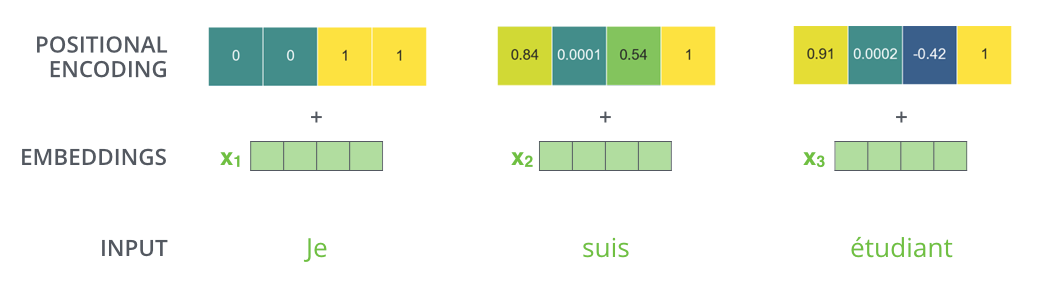
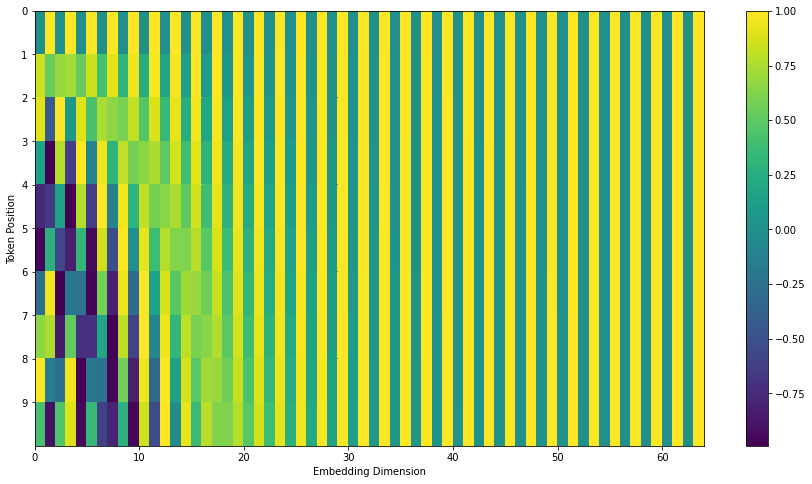
Positional Encoding
Como todos tokens são processados de maneira independente, não há mais uma noção de sequencia ou ordem no nosso input.
Como remediar isso?
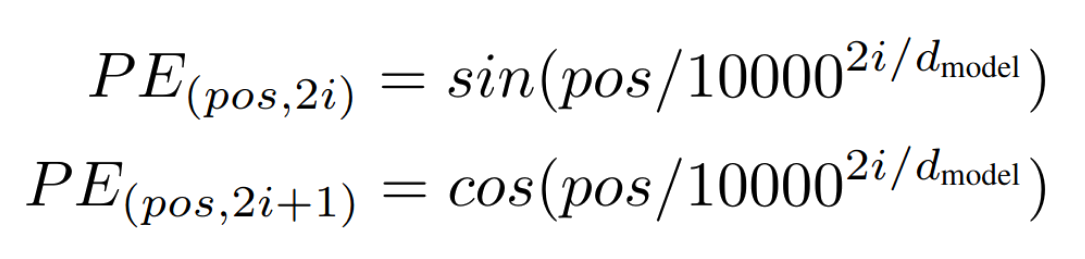
O paper "Attention is all you need" mudou drasticamente a área de NLP. Desde sua publicação diversos modelos surgiram inspirados pelo modelo transformer.
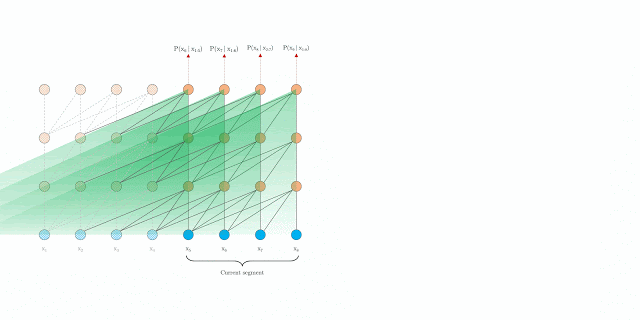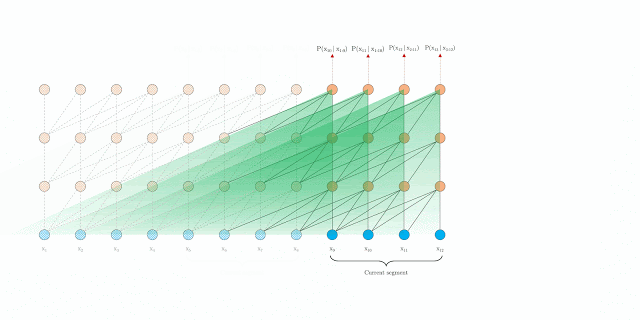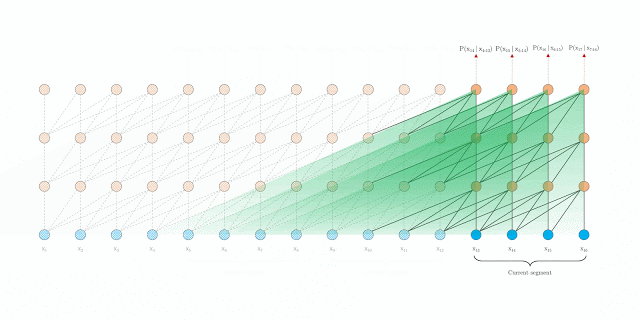
Um deles foi o transformer XL que se propoem a estender de maneira eficiente o contexto de um modelo transformer.
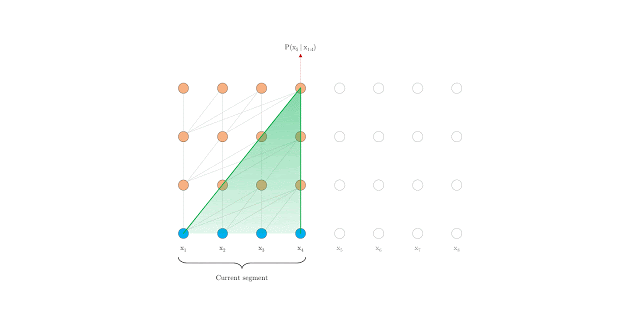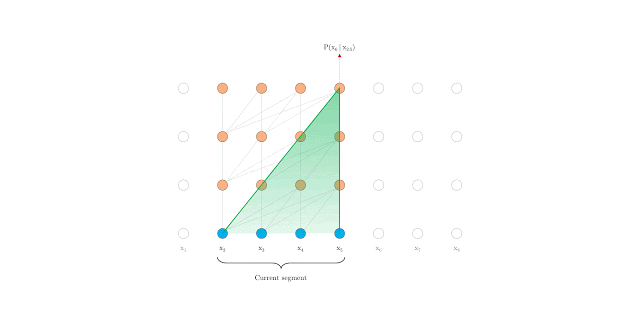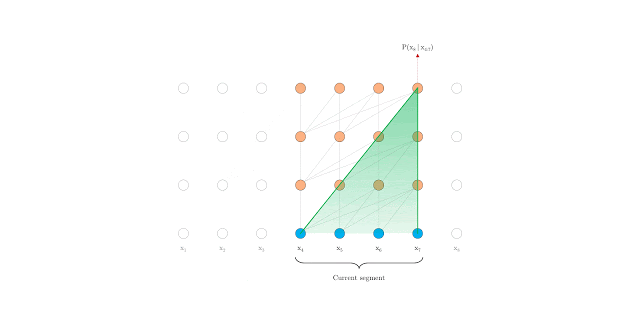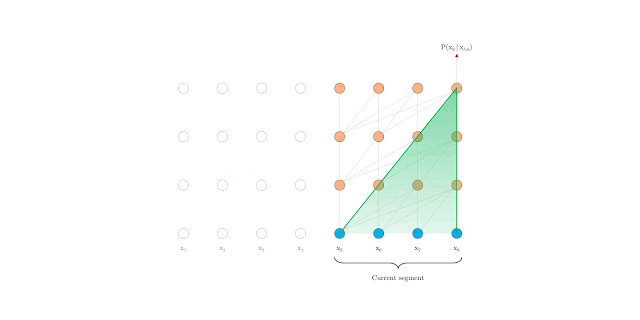
Transformer
Transformer XL
Transformers de Sucesso
- Bert
- XL-Net, RoBERTa, AlBERT, DistilBERT, CamenBERT
- GPT, GPT-2, GPT-3
- T5 (tradução)
Usam pré-treinamento + refinamento: transfer learning
não-supervisionado supervisionado
Nas próximas aulas!
09 - Transformers
By barzilay



