New search engine on top of Elasticsearch
Agenda
- What is Elasticsearch
- Legacy search engine v.s. new search engine on top of ES
- The prototype
- Demo
What is Elasticsearch
Distributed search and analytics engine
Core of Elastic Stack
Overview
- Search and analytics engine
- Open source
- Works on multiple platforms: Windows, Linux, Mac.
- Powered by Apache Lucene
- Distributed -> Near-realtime response/Fault tolerance
- Functionalities available via REST APIs
- Extensions: X-pack
Key concepts - Logical
- Index
- Type (deprecated)
- Document
- Field
Relational DataBase Analogy
| Relational DB | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
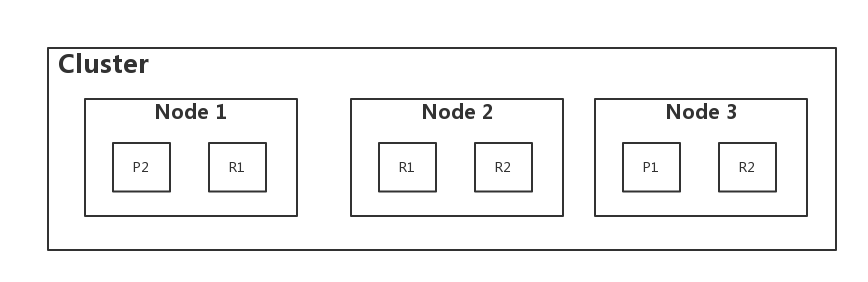
Key concepts - Physcal
- Cluster
- Node
- Master node
- Coordinating node
- Shards
- Primary shards
- Replica shards
Elasticsearch Cluster
Legacy search engine v.s. new search engine
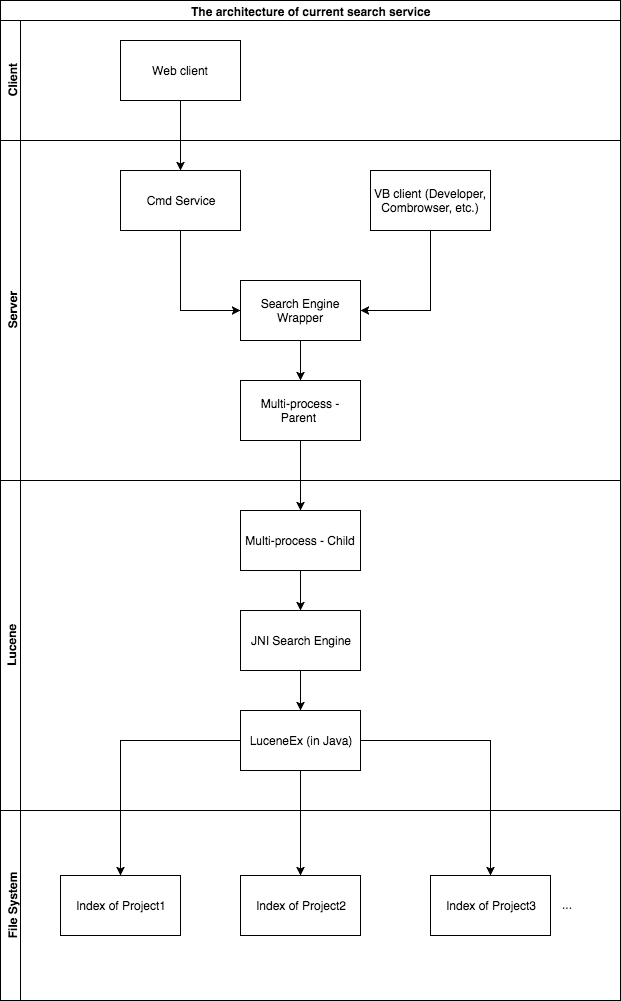
The architecture of legacy search engine
Share
Independent
Limitation: lock contention
Limitation:
1. Needs synchronization between nodes.
2. Difficult to support cross project search for asymmetric cluster
The architecture of the new search engine
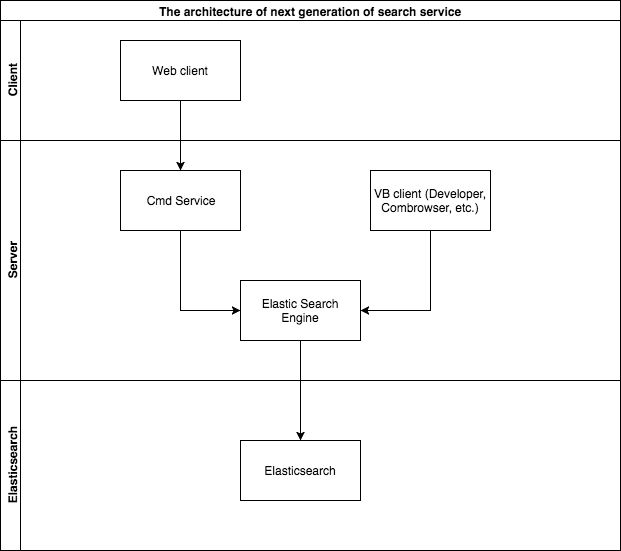
The prototype
What we have done so far
Configuration
- A new setting in server definition
- A JSON string looks like:
{
"network.host": "192.168.0.1",
"http.port": "9200"
}Feature flag
To control whether the server should instantiate the legacy search engine or the Elastic one

Get rid of the multi-process support
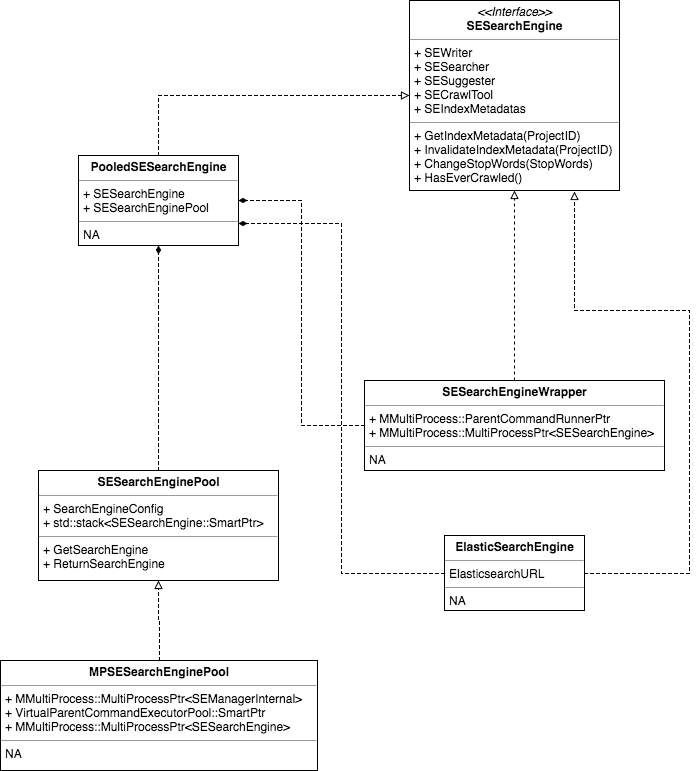
Stub out the skeleton of the Elasticsearch engine
class ElasticCrawTool : public SECrawlTool
{
public:
virtual Int32 Crawl(SEIndexMetadata& irMetadata) override;
virtual Int32 Pause(SEIndexMetadata& irMetadata) override;
virtual Int32 Resume(SEIndexMetadata& irMetadata) override;
virtual Int32 Complete(SEIndexMetadata& irMetadata) override;
virtual Int32 Destroy(SEIndexMetadata& irMetadata) override;
virtual Int32 Enable(SEIndexMetadata& irMetadata) override;
virtual Int32 SaveInitialCrawlProgress(SEIndexMetadata& irMetadata) override;
virtual Int32 SaveIncrementalCrawlProgress(SEIndexMetadata& irMetadata) override;
virtual Int32 StartIncrementalCrawl(SEIndexMetadata& irMetadata) override;
virtual Int32 StopIncrementalCrawl(SEIndexMetadata& irMetadata) override;
virtual Int32 Pend(SEIndexMetadata& irMetadata) override;
};
class ElasticWriter : public SEWriter
{
public:
virtual Int32 Update(UpdateCommand::SmartPtr iDocPtr) override;
virtual Int32 Update(std::vector<UpdateCommand::SmartPtr>& irDocs) override;
virtual Int32 UpdateImmediately(std::vector<UpdateCommand::SmartPtr>& irDocs, MBase::String& irProjectID) override;
};
class ElasticSearcher : public SESearcher
{
public:
virtual SearchResult::SmartPtr Search(SearchParameter::SmartPtr iParamPtr, UserInfo& irUser) override;
virtual MBase::String SearchJson(SearchParameter::SmartPtr iParamPtr, UserInfo& irUser) override;
virtual MBase::String SearchWithContext(ContextParameters::SmartPtr iParamPtr) override;
virtual Int32 NumDoc(MBase::String& irProjectID) override;
virtual MBase::String GetModifyTime(MBase::String& irProjectID, MBase::String& irObjectID) override;
};Porting over the java implementation
- Done
- Move the index state to Elasticsearch
- Full index
- Query
- Incremental index
- Destroy index
Demo
Questions
New search engine on top of Elasticsearch
By bawu



