Health Data Science Meetup
September 26, 2016
Introduction
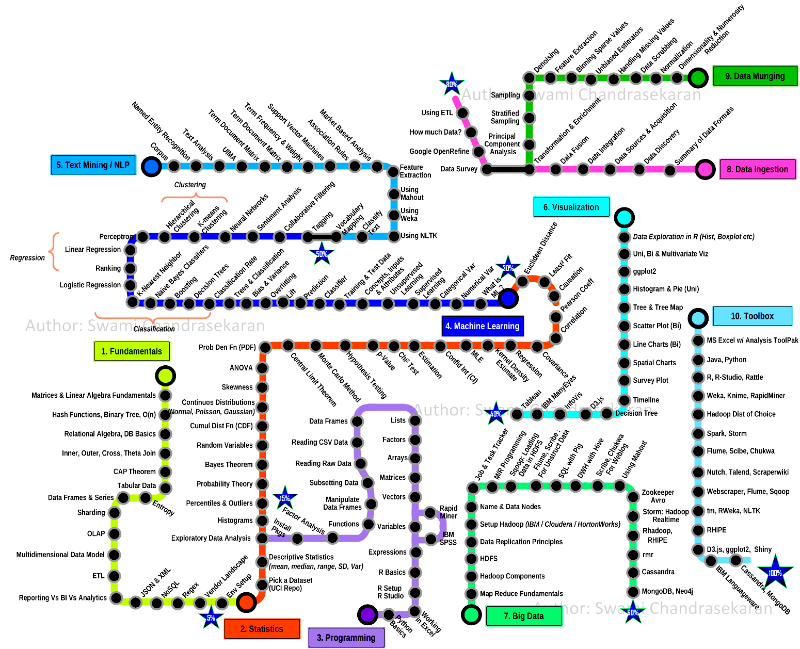
Overview of Data Science Pipeline
Python Crash Course and Common Packages
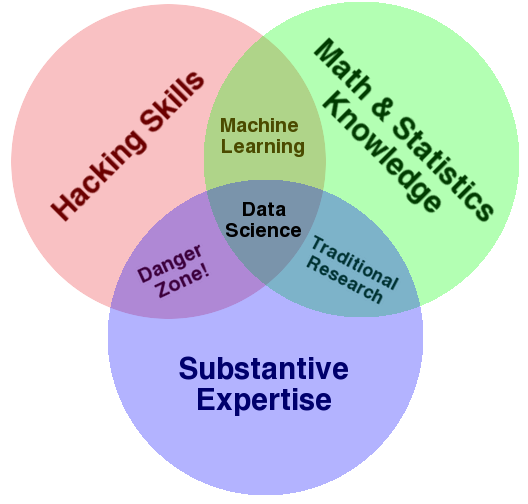
A place where we can
-
share tips and codes
-
explore new areas of the health data science landscape
-
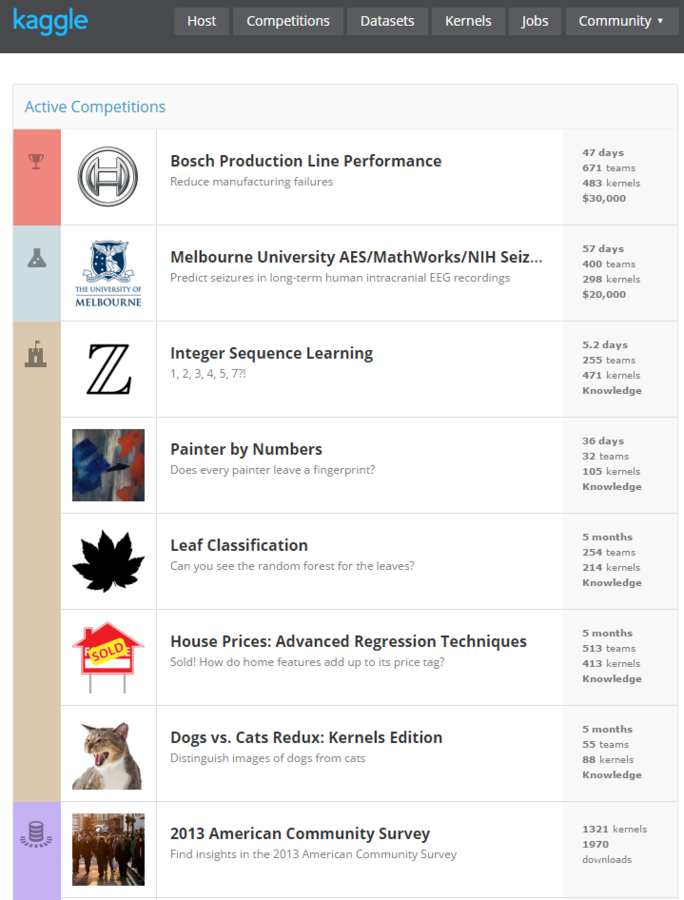
take challenges on online competitions such as Kaggle and Dream challenges





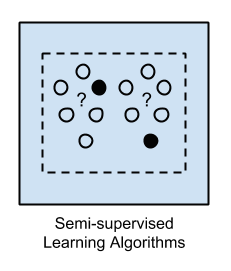
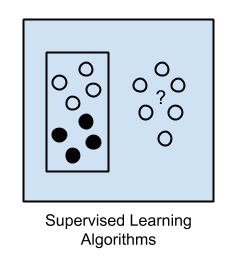
What to expect from the meetup?
- Time: 9/26 9:00-11:00 AM; Topic: Data Science Pipeline, Python crash course, common packages
- Time: 10/10 9:00-11:00 AM; Topic: Shrinkage and Regularization: Lasso, Ridge, Elastic Net
- Time: 10/24 9:00-11:00 AM: Topic: Tree-based Methods: CART, Random Forests, GBDT & Ensembles: Voting, Bagging, Boosting
- Time: 11/7 9:00-11:00 AM; Topic: Support Vector Machines
- Time: 11/21 9:00-11:00 AM; Topic: Neural Network: MLP, CNN
- Time: 12/5 9:00-11:00 AM: Topic: Neural Network: RNN
Raw Data
Data Wrangling
Explore
Model Selection
Feature Engineering
Train Model
Evaluate Performance
Data Product
Data Science Pipeline
Inferential Model
vs
Predictive Model
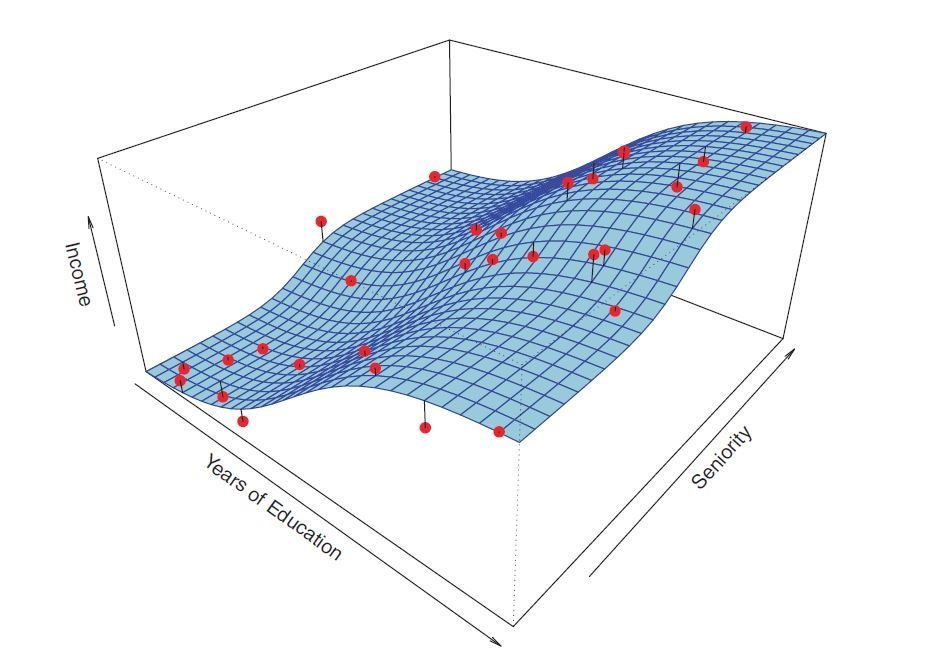
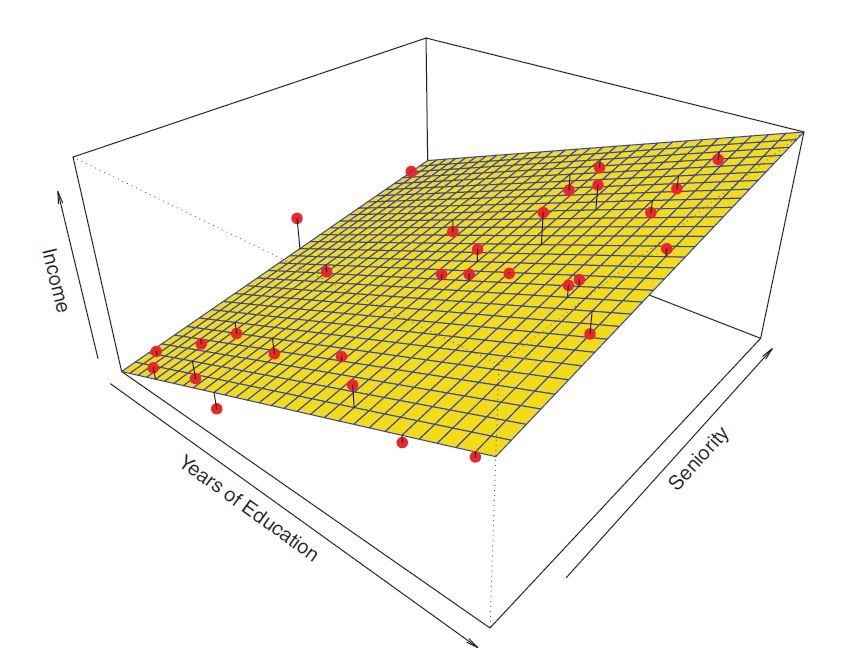
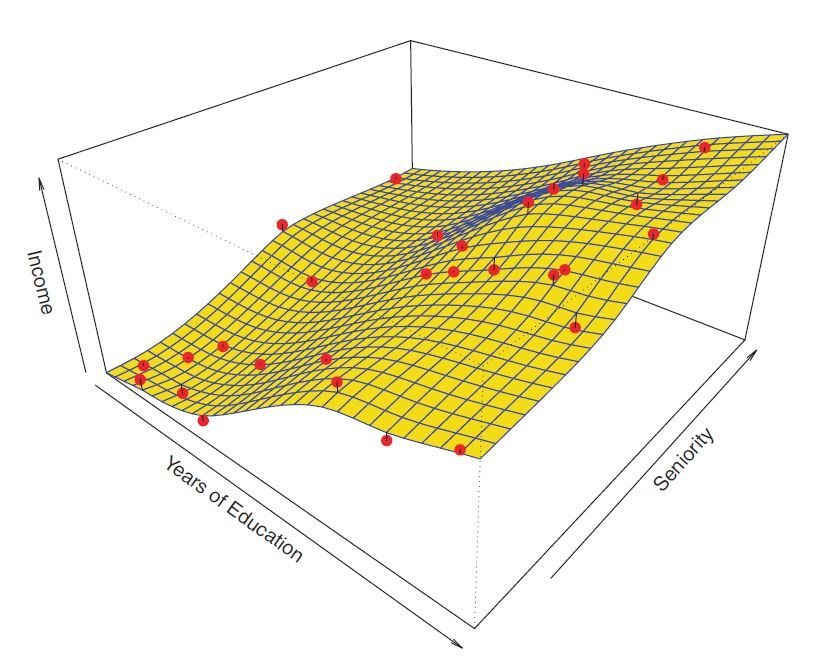
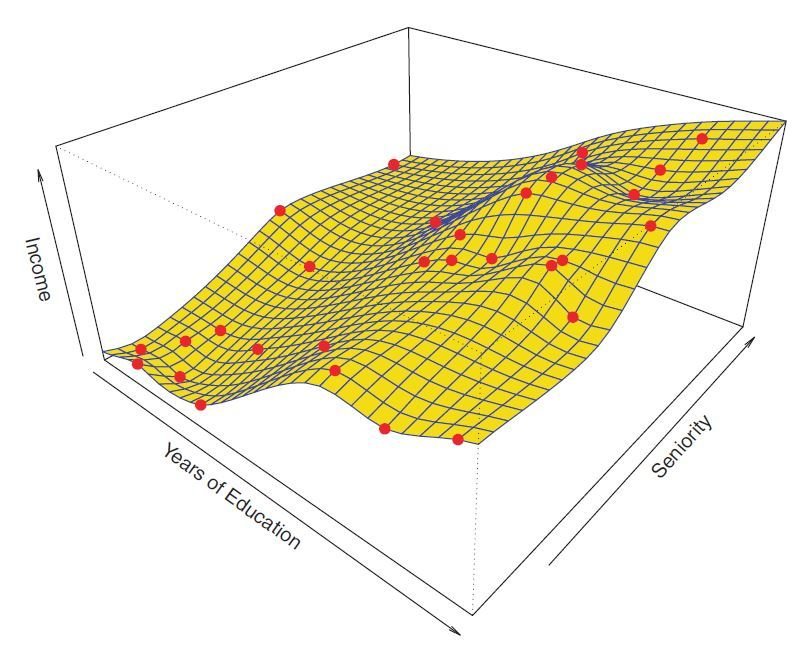
Decomposition of Error

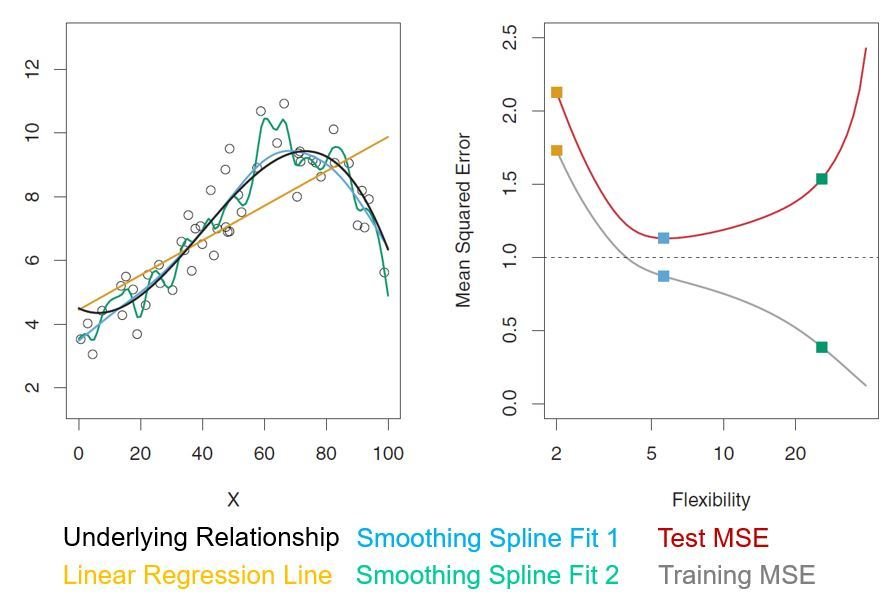

Bias-Variance Trade-off
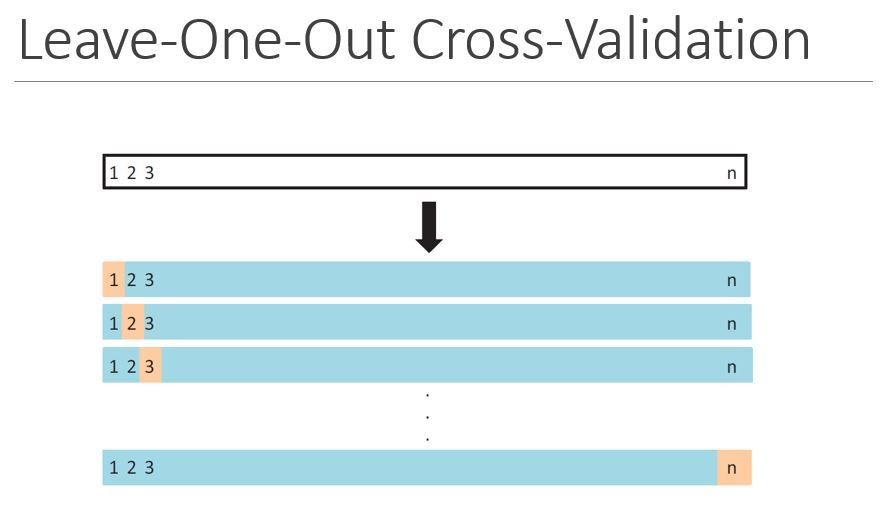
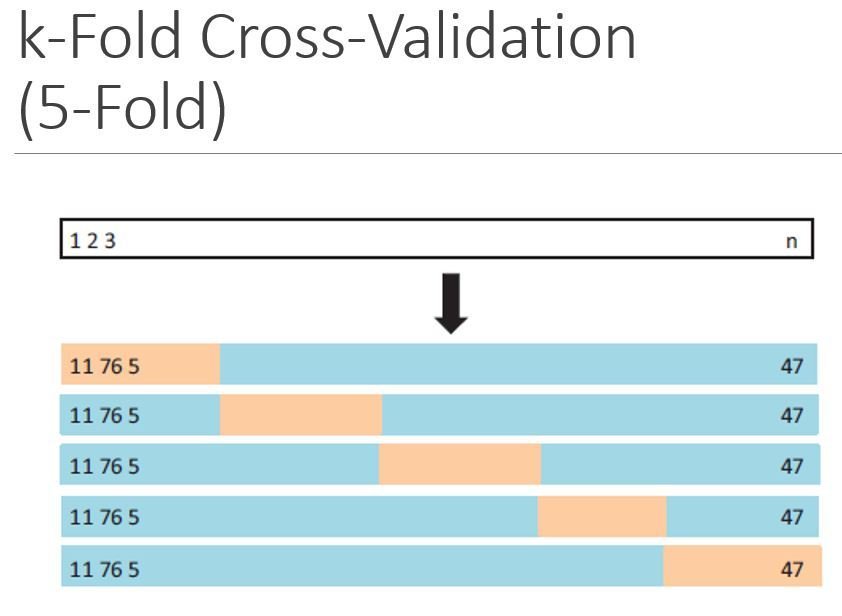
Cross-Validation
- The test error can be calculated if a test dataset is available.
- Unfortunately, this is usually not the case.
We don’t have a very large designated test dataset that can be used to directly estimate the test error rate in most time.
- Cross-validation:
A method that can estimate the test error rate by holding out a subset of the training observations from the fitting process, and then applying the trained method to those held out observations
Training
80%
Testing
20%
k-fold CV
Tune Models
Evaluate Performance
Python


- Install Python 2
- Install numpy
pip install numpy - Install pandas
pip install pandas - Install matplotlib
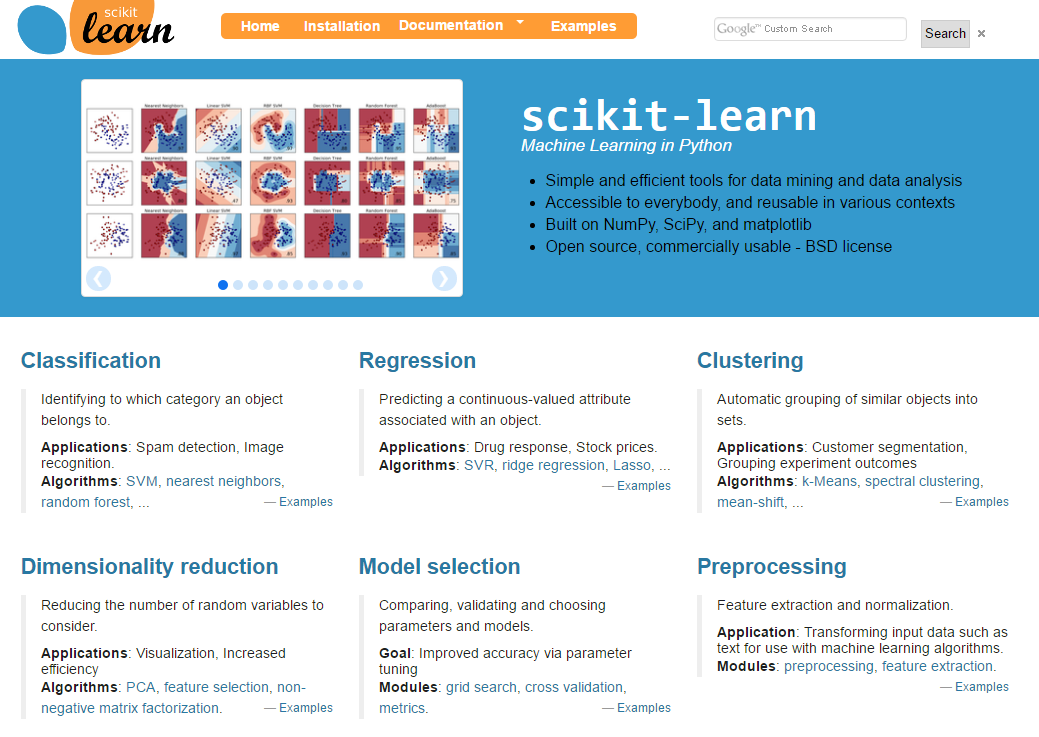
pip install matplotlib - Install scikit-learn
pip install scikit-learn - Install jupyter notebook
pip install jupyter

HDS Meetup 9/26/2016
By Hui Hu
HDS Meetup 9/26/2016
Slides for the Health Data Science Meetup



