Health Data Science Meetup
October 24, 2016
Decision Trees
Ensembles
Implementations in Python
Decision Trees
Introduction
- Modern name: Classification and Regression Trees (CART)
- The CART algorithm provides a foundation for important algorithms such as bagged decision trees, random forests, and boosted decision trees
CART Model Representation
- Binary tree
- Node: a single input variable (x) and a split point on that variable
- Leaf node: an output variable (y)
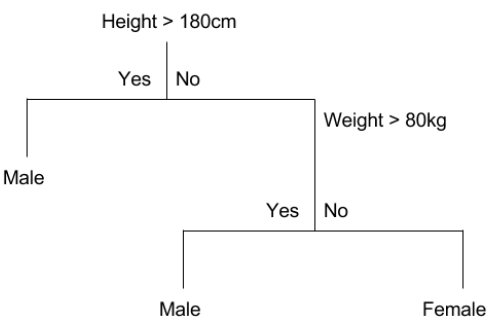
Making Predictions
- Evaluate the specific input started at the root node of the tree
- Partitioning of the input space
- e.g. height=160cm, weight=65kg
- Height>180cm: No
- Weight>80kg: No
- Therefore: Female
Learn a CART Model from Data
- Creating a binary decision tree is actually a process of dividing up the input space
- A greedy approach is used: recursive binary splitting
- all the values are lined up and different split points are tried and tested using a cost function
- the split with the best cost is selected
- Cost functions:
- regression: the sum of squared error
- classification: the Gini cost
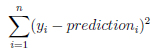
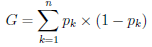
Stopping Criterion
- The recursive binary splitting procedure needs to know when to stop splitting as it works its way down the tree with the training data
- Most common stopping procedure:
- set a minimum count on the number of training instances assigned to each leaf node
- defines how specific to the training data the tree will be
- too specific (e.g. 1) will lead to overfit
- needs to be tuned
Pruning the Tree
- Pruning can be used after the tree is learned to further lift performance
- The complexity of a decision tree is defined as the number of splits in the tree
- Simple trees are preferred
- easy to understand
- less likely to overfit your data
- Work through each leaf node in the tree and evaluate the effect of removing it
- leaf nodes are removed only if it results in a drop in the overall cost function
Ensembles
- Ensembles (combine models) can give you a boost in prediction accuracy
- Three most popular ensemble methods:
- Bagging: build multiple models (usually the same type) from different subsamples of the training dataset
- Boosting: build multiple models (usually the same type) each of which learns to fix the prediction errors of a prior model in the sequence of models
- Voting: build multiple models (usually different types) and simple statistics (e.g. mean) are used to combine predictions
Bagging
- Take multiple samples from your training dataset (with replacement) and train a model for each sample
- The final output prediction is averaged across the predictions of all of the sub-models
- Performs best with algorithms that have high variance (e.g. decision trees)
- Common algorithms:
- bagged decision trees
- random forest
with reduced correlation between individual classifiers
a random subset of features are considered for each split
- extra trees
further reduce correlation between individual classifiers
cut-point is selected fully at random, independently of the outcome
Bootstrap Aggregation
Boosting
- Creates a sequence of models that attempt to correct the mistakes of the models before them in the sequence
- build a model from the training data, then create a second model that attempts to correct the errors from the first model
- models are added until the training set is predicted perfectly or a maximum number of models are added
- Common algorithms:
- AdaBoost
Weight instances in the dataset by how easy or difficult they are to predict
Allow the algorithm to pay more or less attention to them in the construction of subsequent models
- Stochastic Gradient Boosting (Gradient Boosting Machines)
Boosting algorithms as iterative functional gradient descent algorithms
At each iteration of the algorithm, a base learner is fit on a subsample of the training set drawn at random without replacement
Voting
- First create two or more standalone models
- These models can then be wrapped
- Average of the predictions of the sub-models will be used to make predictions for new data
- The predictions of the sub-models can be also weighted
Python
Install XGBoost
HDS Meetup 10/24/2016
By Hui Hu
HDS Meetup 10/24/2016
Slides for the Health Data Science Meetup



