Gestion des documents
et des
Schémas de données
MongoDB vs mySQL
Base NOSQL
non relationnelle
orientée document
Vocabulaire
SQL vs Mongo
- Base <=> Base
- Collection <=> Table
- Document / Objet <=> Ligne / Enregistrement
- Champ <=> Colonne
- Sous document ou Lien <=> Jointure

Mongo
Base de données
- NoSQL avec
- replication
- sharding
- Orientée documents
- sans schéma
- sans relationnel

Théorème CAP
- Cohérence
- Disponibilité
- Tolérance au partitionnement
MongoDB
Consistency
Availability
Partition Tolerance
fail
Replication & Sharding
- Redondance des nœuds d'instance
Duplication des données sur plusieurs nœuds- En cas d'indisponibilité du nœud principal, la redondance assure la disponibilité des données
- Distribution des données
Répartition des documents selon une de leur caractéristique- Répartition de la charge
- Localisation des données
Orientée document
Document <=> Objet JSON avec un champ "_id"
- Limite de taille à 16Mo pour du BSON (format interne)
- Sinon recourt au GridFS
{
"_id" : ObjectId("5811bac48b0cf22ea39e16ec"),
...
}{
"_id" : "toto",
...
}{
"_id" : 42,
...
}Pas de schéma
des objets
NoSQL Orientée document
=>
et aussi
- Pas de transactionnel
(sauf au sein d'une unique requête)
- Pas de relationnel
- Pas de schéma
(en option)
Pas de schéma
Du coup on peut avoir plusieurs types d'objets qui cohabitent dans la même collection !
{
"name": "Voiture",
"plate": "AR-456-YI",
"nextControlDate": ISODate("2017-10-01T00:00:00.000Z"),
"nbSeats": 5
}
{
"name": "Camion",
"plate": "AD-123-PS",
"nextControlDate": "none",
"capacity": 20
}
Pas de schéma
Certes mais
- on doit savoir ce qu'on manipule
- les documents peuvent avoir des relations entre eux
- c'est à l'utilisateur (code) de gérer
- les schémas
- les relations
- les cycles de vie
Relations entre objets
type, composition et agrégation
Stockage d'objets
- C'est fait pour !
- Pas besoin des complications de SQL
Quid du polymorphisme ?
Règles de bon sens
- On met un seul type d'objet dans une collection
=> On sait a priori ce qui est stocké
- On met une famille d'objets dans la collection
& on identifie le type de chaque objet
=> Pour savoir précisément ce qu'on manipule
Quel est le type de mon document ?
Il faut une caractéristique d'identification
- on peut ajouter un champ "_type", "_class" ou autre
ainsi
- on sait quel type on manipule
- si absent => type générique de la collection
Comment on identifie le type ?
Quel est le type de mon document ?
Exemple
{
"_type": "car",
"name": "Voiture",
"plate": "AR-456-YI",
"nextControlDate": ISODate("2017-10-01T...Z"),
"nbSeats": 5
}
{
"_type": "truck",
"name": "Camion",
"plate": "AD-123-PS",
"nextControlDate": "none",
"capacity": 20
}
Pas de relationnel
Pourtant l’agrégation et l'association sont des concepts de base des relations entre objets
Pas de relationnel
Mais on peut avoir des objets composés
{
_id: "564f36c87dcbd96cf6f3e2ea",
name: "Tactilia",
address: {
city: "Saint Grégoire"
...
},
products: [
"fidbe", ...
],
...
}
Pas de relationnel
Mais on peut mettre des références vers un objet
{
_id: "564f36c87dcbd96cf6f3e2ea",
name: "Tactilia",
employees: [
"/employees/564f36c87dcbd07cf6f3e2ea",
...
],
logo: "564f36c87dcbd97cf6f3e2ea",
...
}
L'aggrégation est à
gérer à la main
Agrégation & relation
{
_id: "5b50f8968656472a58970167",
password: "xxx",
userId: "bchanclo",
??? lien vers le tiers ???
}{
_id: "564f36c87dcbd97cf6f3e2ea",
firstname: "Benoît",
lastname: "Chanclou",
birthdate: ...
}Account
Tiers
Exemple un compte d'accès en lien avec un tiers
Un simple id
- suppose qu'on sache où aller chercher la ressource
- on sait faire
-
un accès direct à la base
- ou via l'api du référentiel Tiers
-
un accès direct à la base
{
_id: "5b50f8968656472a58970167",
password: "xxx",
userId: "bchanclo",
user: "564f36c87dcbd97cf6f3e2ea",
}
GET http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2eadb.tiers.findOne({_id: "564f36c87dcbd97cf6f3e2ea"})Une uri (c'est universel !)
- ne présuppose rien sur la localisation de la ressource
- on sait
- extraire l'id pour une requête directe à la base
- ou appeler l'url correspondant à l'uri
{
user: "http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2ea",
}
Une référence enrichie
- les objets de type "Tiers" sont dans une collection ou un référentiel connu
- on sait
- récupérer la ressource
- que ce sera un objet de type Tiers
{
user: {
type: "Tiers",
id: "564f36c87dcbd97cf6f3e2ea"
},
}
Les doublons
C'est le mal !
Ben non, c'est même plutôt utile
Les doublons
un cache
=> il faut une référence
- Pour les requêtes croisées
pas d'aggregate pour les requête croisées - Pour les données en lecture seule
pour les tableaux par exemple - Il faut un mode de synchronisation
Requêtes croisées
Trouver des livraisons faites par un "John"
Impossible en une seule étape
utilisation de deux requêtes ou d'un aggregate
{
...
"deliveryMan": xxx,
...
}{
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789",
...
}db.Deliveries.find(
{ deliveryMan: {$in : johnIdsList } }
)db.Tiers.find(
{ firstname: "John" }
)Tiers
Deliveries
Requêtes croisées
Impossible sauf en mettant
les champs nécessaires dans le cache
{
...
"deliveryMan": xxx,
...
}{
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789",
...
}{
...,
"deliveryMan": {
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789"
},
...
}db.Customers.find(
{ deliveryMan.firstname: "John" }
)Tiers
Customers
Customers
Une référence avec cache
- si on veut juste le nom et le prénom
- inutile d'aller charger la ressource secondaire
- on utilise le cache
- sinon, on sait récupérer la ressource secondaire complète dans son référentiel
{
"contact": {
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789"
},
}
Avantages et Contraintes du cache
+ Accès rapide
+ Recherches rapide possible sur les champs mis en cache
+ Lazy loading de la ressource référencée
- Gérer le cycle de vie du cache :
- Invalidation
- Mise à jour
Mise à jour du cache
- Asynchrone/Passif :
Lorsque la ressource secondaire est chargée (en lazy loading), on en profite pour mettre à jour le cache si nécessaire
-
Synchrone/Actif :
Lorsque la ressource secondaire est mise à jour- En local :
Le cache est lui aussi mis à jour - Dans un autre référentiel :
Le secondaire appelle un webhook du principal pour mettre à jour le cache
- En local :
Versionner
Pourquoi ?
Les objets sont vivants
Un objet a un cycle de vie
- création
- modification
- destruction
destruction
- delete
ou
- Archivage permettant la restauration
=>Ajout d'un champ _archive: true
find({
...,
$or: [ { _archive: { $exists: false } }, { _archive: false } ]
})find({
...,
_archive: true
})Les objets ont des champs
- en plus
- en moins
- renommés
- qui changent de type
En plus
- si c'est un champ qui ne peut pas être nul
=> initialiser la valeur par défaut dans le constructeur/loader - au prochain enregistrement il apparaîtra

En moins
- il suffit de ne plus l'utiliser !
- au prochain enregistrement complet il disparaîtra
- au pire utiliser $unset (cas d'une champs volumineux)

Renommage
- garder les deux noms
- ajouter accesseur et mutateur
ou
- utiliser un système de version de schémas
ou
- mettre à jour les objets de la base avec $rename
Changement de type
- ajouter accesseur et mutateur
pour retourner le bon type
ou
- utiliser un système de version de schémas
ou
- mettre à jour les objets de la base
Un objet
- change de nature
- fusionne avec un autre
- se scinde en deux
changement de nature
- le nouveau format est dans une autre collection
- grâce au UUIDs
- si l'objet est dans la nouvelle collection => ok
- sinon l'objet est dans l'ancienne
=> convertir l'objet
ou
- utiliser un système de version de schémas
ou
- on met à jour les objets de la base
fusion
- utiliser un système de version de schéma
- à la lecture l'objet principal agrège le second objet
ou
- mettre à jour les objets de la base
scission
-
l'objet principal reste dans sa collection
- à la lecture si encore agrégé scinder l'objet
- le second objet est transféré dans une autre collection
- l'objet est dans la nouvelle collection => ok
-
sinon l'objet est encore agrégé à l'objet principal
=> convertir la partie du second objet
(mettre aussi à jour l'objet principal) - problème de génération de l'id du second objet
ou
- on met à jour les objets de la base
Versionner les schémas
Pourquoi ?
- Parce qu'il n'y a pas de schéma !
=> plusieurs versions différentes peuvent cohabiter- pas la peine de mettre les documents à jour
=> pas de script de mise à jour
(sauf énorme changement) - mais on ne sait pas quelle version on manipule
=> ajouter un champ "_version"
(si absent = version 0)
- pas la peine de mettre les documents à jour
Comment ?
{
"addressStreet": "rue d'Alembert",
"addressZipCode": "35000",
"addressCityName": "Rennes",
...
}{
"_version": 1
"address": {
"street": "rue de Gauss",
"zipCode": "56230",
"cityName": "Questembert"
},
...
}{
"_version": 2
"address": {
"street": "rue du Rennes",
"city" : {
"zipCode": "35700",
"name": "Saint Malo"
}
},
...
}var CONVERTERS = [
obj => {
obj.address = {
street: obj.addressStreet,
zipCode: obj.addressZipCode,
cityName: obj.addressCityName
};
delete obj.addressStreet;
delete obj.addressZipCode;
delete obj.addressCityName;
obj._version = 1;
},
obj => {
obj.address.city = {
zipCode: obj.address.zipCode,
name: obj.address.cityName
};
delete obj.address.zipCode;
delete obj.address.cityName;
obj._version = 2;
}
];
while (obj._version < CONVERTERS.length) {
CONVERTERS[obj._version](obj);
}Avantages et Contraintes
+ le code ne manipule que des objets au dernier format
+ on n'est pas obligé de mettre à jour toute la collection
+ pas de migration =
- pas d'interruption de service
- conversion au fil de l'eau
- recherche complexifiées
- il faut rechercher dans toutes les versions
utile dans une grosse base où peu d'objets sont utilisés
(ex.: liste de commandes clients, au quotidien on ne manipule que les plus récentes)
Gérer l'historique
Cas #1
Un document par version
{ "docId" : 174, "rev" : 1, "attr1": 165 } /*version 1 */
{ "docId" : 174, "rev" : 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "rev" : 3, "attr1": 184, "attr2": "A-1" }db.docs.find({ "docId": 174 }).sort({ "rev": -1 }).limit(-1);findone
db.docs.aggregate( [
{ "$sort": { "docId" : 1, "rev" : -1 } },
{ "$group" : { "_id" : "$docId",
"doc": { "$first" : "$$ROOT" }
} },
{ "$match": { "doc.attr1": 184 } }
] );find
Cas #1a
Un document par version avec current
{ "docId" : 174, "v" : 1, "attr1": 165 }
{ "docId" : 174, "v" : 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "v" : 3, "attr1": 184, "attr2": "A-1", "current": true }db.docs.findOne({ "docId": 174, "current": true }));findone
db.docs.find({ "doc.attr1": 184, "current": true }));find
Cas #2
un seul document contenant toutes les versions
{
"docId" : 174,
"current" : { "attr1": 184, "attr2": "A-1" },
"prev": [ { "attr1": 165 }, { "attr1": 165, "attr2": "A-1" } ]
}db.CurrentCollection.findone({ "docId": 174 }, { current: 1 });findone
db.CurrentCollection.find(
{ "current.attr1": 184 },
{ current: 1 }
);find
Cas #3
Deux collections
CurrentCollection:
{ "docId" : 174, "rev": 3, "attr1": 184, "attr2": "A-1" }
PreviousCollection:
{ "docId" : 174, "rev": 1, "attr1": 165 }
{ "docId" : 174, "rev": 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "rev": 3, "attr1": 184, "attr2": "A-1" }db.CurrentCollection.findone({ "docId": 174 });findone
db.CurrentCollection.find({ "attr1": 184 });find
Cas #4
Un document par version mais on stocke les deltas
sous forme de JSONPatch
{ "_id": ..., "id": 174, "userId": "xxx", "date": ISODate(...), patch: [
{ "op": "add", "path": "/attr1", "value": 165 }
] }
{ "_id": ..., "id": 174, "userId": "yyy", "date": ISODate(...), patch: [
{"op": "add", "path": "/attr2", "value": "A-1" }
] }
{ "_id": ..., "id": 174, "userId": "zzz", "date": ISODate(...), patch: [
{ "op": "replace", "path": "/attr1", "value": 184 }
] }chaque patch contient
- id du document
- date de modification
- patch à appliquer
en option
- id utilisateur
- son rôle
- id du tenant
find
Compliqué on doit procéder en deux étapes
- créer une collection où on reconstruit les objets
- puis effectuer la recherche
db.docs.aggregate( [
{ $match: { id: "174" } }, // recherche tous les patches sur l'entité
{ $sort: { "date" : 1 } }, // trie les résultats par date
{ $unwind : "$patch" }, // aplati tous les patchs
{ $group: { _id: "$id", patch: { $push:"$patch" } } }
// regroupe tous les patchs en un tableau
] );findone
- On agrège tous les patchs lié à l'id de l'objet puis on applique la liste de patchs sur un objet vide
- On peut ajouter un filtre sur la date pour gérer les révisions
Cas #3+4
Deux collections
SnapshotCollection:
{ "id" : 174, "v": 3, "attr1": 184, "attr2": "A-1" }
PatchCollection:
{ "_id": ..., "id": 174, "userId": "xxx", "date": ISODate(...), patch: [...] }
{ "_id": ..., "id": 174, "userId": "yyy", "date": ISODate(...), patch: [...] }
{ "_id": ..., "id": 174, "userId": "zzz", "date": ISODate(...), patch: [...] }db.SnapshotCollection.findone({ "docId": 174 });findone
db.SnapshotCollection.find({ "attr1": 184 });find
Cas #5
oplog
Le but est d'utiliser les logs de mongo pour gérer l'historique des versions du document (voir ce blog)
Au final
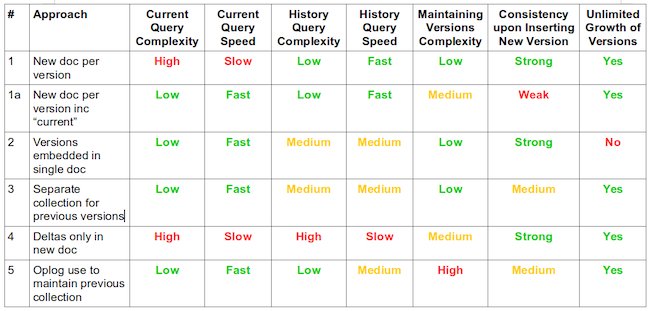
S'adapter
au besoin
et
à la volumétrie
Indexation
Accélérer les recherches
Qu'est-ce qu'un index ?
Une structure de recherche
- but :
réduire le temps de réponse de requêtes - inconvénient :
prend de la place
consommateur de ressources
Quand les utiliser ?
- il faut les utiliser mais pas en abuser
-
les utiliser pour les requêtes identifiées comme
- lentes
- fréquentes
champ _id
- indexé par défaut
Créer un index
- Différents types d'index :
- simple, composé, multi-clé, géospatial, texte, hash
- Propriétés
- unique, partiel, clairsemé, TTL,
db.xxx.createIndex( <key & index type specification>, <options> )Indexation
- Pour le geospatial c'est top
- Pour le texte c'est bof mais ça s'améliore
il faut mieux utiliser une base d'indexation basée sur lucene
(comme solr ou elasticsearch, ou des services tout fait comme algolia)
MongoDB
Résumé
Nécessité d'un modèle
- Connaître le contenu est indispensable
=> Spécifier le type de document
Sous types
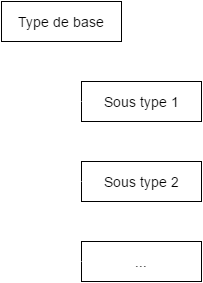
=> utiliser le "_type"
{
"_id": ...,
"_type": "Sous type 1",
"champSpecifiqueSousType1" : []
...
}l'héritage c'est le mal,
l'agrégation c'est le bien
Agrégats
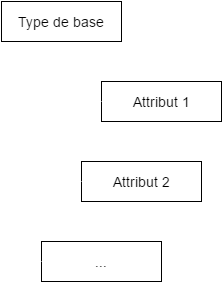
=> utiliser un tableau de "_tags"
{
"_id": ...,
"_tags": [ "Attribut_1", "Attribut_2", ...],
"champSpecifiqueAttr1" : null,
"champSpecifiqueAttr2" : ""
...
}=> utiliser des sous-objets
{
"_id": ...,
"Attribut_1": { "champSpecifiqueAttr1" : null },
"Attribut_2": { "champSpecifiqueAttr2" : "" },
...
}Champs dynamiques
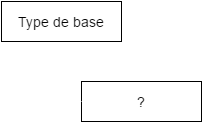
=> utiliser un modèle
{
"_id": ...,
"_modId": [ 123 ],
"aaa": 42
...
}{
"_id": 123,
"fields": [ {
"name": "Champ quelconque",
"label": "aaa",
"type": "int",
.... },
... ]
}Modèle
- dans le nom de la collection
Les tenants
- dans les documents
db.data_564f36c87dcbd97cf6f3e2ea.find()Mettre un id de tenant
db.data.find({ownerId: "564f36c87dcbd97cf6f3e2ea"}){
...,
ownerId: "564f36c87dcbd97cf6f3e2ea",
...
}Identifiant(s)
La plupart du temps on ne distingue pas les identifiants
- technique (mongo _id)
- de l'objet
On utilise le premier pour le second
Identifiant(s)
Cas où un objet est scindé en plusieurs documents mongo
- trop gros (>limite de document de 16Mo)
- en plusieurs parties
On distingue alors les identifiants
- les identifiants techniques
- un unique identifiant d'objet
pour récupérer l'objet on fusionne tous les documents mongo ayant cet identifiant d'objet
Liens
bibliographie
Documentations
- Documentation mongo (la recherche marche bien)
- Wikipédia : Bases de données orientées documents
- Wikipédia : Théorème CAP
- MongoDB et le Théorème CAP
- Stack MEAN (on préfèrera remplacer Angular par React !)
- Mongoose
Blogs & présentations
Utiliser un framework
certains frameworks savent gérer ce type de références
(au sein d'une même application, même db)
- java : Spring
- js : mongoose (populate)
MongoDB DA
By Benoît Chanclou
MongoDB DA
en cours



