Klasyfikacja i regresja z zastosowaniem algorytmu RandomForest

autor: Michał Bieroński
album: 218324
Agenda
- Wprowadzenie
- Drzewa decyzyjne
- Zespoły klasyfikatorów
- Losowy las
- Proces budowy lasu
- Metody usprawniające działanie
- Regresja
- Zastosowania
- Porównanie z innymi metodami
- Przykład
- Zalety i wady
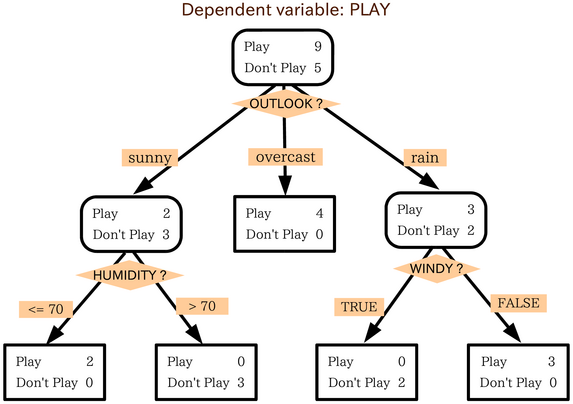
Drzewa decyzyjne
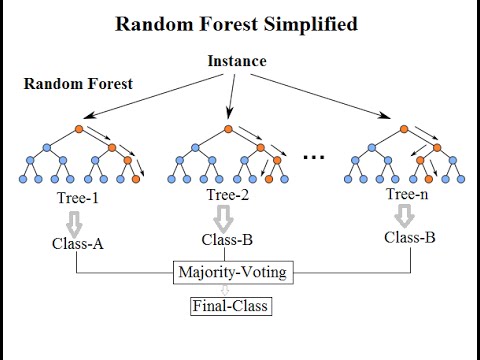
Zespoły klasyfikatorów


Losowe lasy

+
=


+
Budowa drzew
| Chest Pain |
Good Blood Circ. | Blocked Arteries | Weight |
Heart Disease |
|---|---|---|---|---|
| No | No | No | 125 | No |
| Yes | Yes | Yes | 180 | Yes |
| Yes | Yes | No | 210 | No |
| Yes | No | Yes | 167 | Yes |
Oryginalny dataset
| Chest Pain |
Good Blood Circ. | Blocked Arteries | Weight | Heart Disease |
|---|---|---|---|---|
| Yes | Yes | Yes | 180 | Yes |
| No | No | No | 125 | No |
| Yes | No | Yes | 167 | Yes |
| Yes | No | Yes | 167 | Yes |
Bootstrapped dataset
1. Bootstrapping
Budowa drzew
| Chest Pain |
Good Blood Circ. | Blocked Arteries | Weight | Heart Disease |
|---|---|---|---|---|
| Yes | Yes | Yes | 180 | Yes |
| No | No | No | 125 | No |
| Yes | No | Yes | 167 | Yes |
| Yes | No | Yes | 167 | Yes |
Bootstrapped dataset
2. Random subset
W skrócie: na każdym poziomie rozpatrujemy tylko losowe podzbiory niewykorzystanych cech.
Budowa losowego lasu
- Powtarzaj kroki 1 i 2, aż do uzyskania n drzew.
-
Agregacja decyzji - głosowanie większościowe
Remark:
Bootstrapping
+
Decission aggregating
=
Bagging
Budowa losowego lasu
| Chest Pain |
Good Blood Circ. | Blocked Arteries | Weight |
Heart Disease |
|---|---|---|---|---|
| No | No | No | 125 | No |
| Yes | Yes | Yes | 180 | Yes |
| Yes | Yes | No | 210 | No |
| Yes | No | Yes | 167 | Yes |
Oryginalny dataset
Out-Of-Bag Dataset
Co dalej?
Jak go wykorzystać?...
Budowa losowego lasu
Out-Of-Bag Dataset
- Czy maksymalna liczba losowo rozpatrywanych cech rzeczywiście była dobra?
- Jak dobrać odpowiednią wartość?
Problemy
- Wykorzystajmy Out-Of-Bag Dataset do walidacji!
Rozwiązanie
Wróćmy do metody random subset...
Budowa losowego lasu
Out-Of-Bag Dataset c.d.
- Dla każdego z drzew zbudowanych bez obiektów z tego zbioru sprawdź jaka klasa zostanie przypisana (walidacja)
- Dokonaj agregacji decyzji
- Sprawdź czy dokonano poprawnej klasyfikacji i oblicz "Out-Of-Bag Error"
"Out-Of-Bag Error"
(proporcja niepoprawnych klasyfikacji do wszystkich)
Budowa losowego lasu
Out-Of-Bag Error
Jak wykorzystać tę informację?
Można lepiej dobrać parametr ograniczenia do metody random subset.
- Zazwyczaj sprawdzana jest okolica
- Zbuduj las w oparciu o nową wartość parametru
- Powtórz proces dla k parametrów
- Wybierz ten o największej dokładności
\sqrt{N}
N - liczba cech
Regresja dla drzew decyzyjnych
CART - classification & regression tree

Budowa drzewa
*MSE - tutaj błąd śr. kw. odległości wartości atrybutów od wartości średniej w danym podziale

Regresja dla drzew decyzyjnych
Dla każdego regionu wartością regresji jest średnia obiektów do niego przynależących.
Regresja dla losowego lasu
- Trenujemy N drzew (używając metod baggingu, random subset itd.)
- Agregujemy wartości zwracane przez drzewa za pomocą średniej
Zastosowania
- Bankowość
- identyfikowanie lojalnych klientów
- wykrywanie oszustw
- Medycyna
- zatwierdzanie leków
- identyfikacja chorób
- Giełda
- przewidywanie wzrostów bądź spadków
- E-commerce
- część silnika rekomendacyjnego (identyfikacja likelihoodu, że klientowi będzie podobał się rekomendowany produkt)
- Computer Vision
- Microsoft Kinect (identyfikacja części ciała)
- Inne
- Teledetekcja
- Czytanie z ruchu warg
- Klasyfikacja mowy
Porównanie z innymi metodami (klasyfikacja)

from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
clf = RandomForestClassifier(n_estimators=10,
criterion='entropy',
max_features='sqrt',
max_depth=4,
n_jobs=-1)
clf.fit(X, y)
print(clf.predict([[0, 0, 0, 0]]))
>>> [1]Jak używać (Python)
Zalety
- Zdolne zarówno do klasyfikacji i regresji
- Potrafią obsłużyć i zachować dokładność dla brakujących danych
- Zapobiegają przeuczeniu
- Radzą sobie z dużymi zbiorami danych o dużej wymiarowości
Wady
- Z regresją nie radzą sobie tak dobrze jak z klasyfikacją
- Ciężko kontrolować model
Źródła
-
http://dataaspirant.com/2017/05/22/random-forest-algorithm-machine-learing/
-
http://www.vision.cs.chubu.ac.jp/MPRG/C_group/C058_mishina2014.pdf
-
https://www.r-bloggers.com/how-random-forests-improve-simple-regression-trees/
-
http://urszula.libal.staff.iiar.pwr.wroc.pl/docs/aro/aro8.pdf
-
StatQuest: Random Forests Part 1 - Building, Using and Evaluating
-
StatQuest: Random Forests Part 2: Missing data and clustering
Random forests
By bierus



