C++[2]
目錄
複雜度
複雜
複雜度的用處
衡量一個程式的效率
有分時間效率與空間效率
怎麼衡量?
\(O()\)漸進符號
高一數學,方程式的廣域特徵
當我做一個三次方程式
把他拉遠
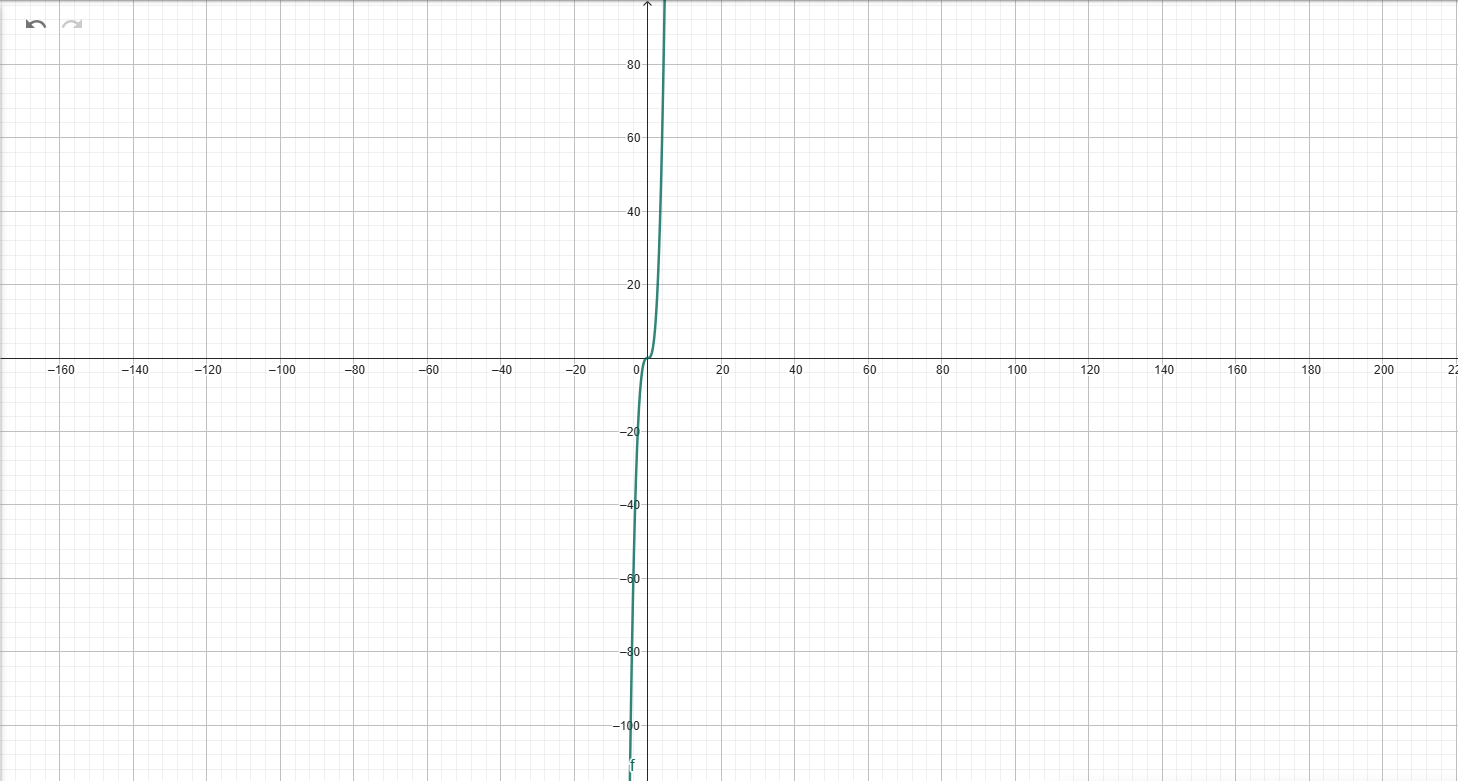
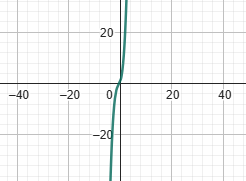
\(y = x^3\)
\(y = x^3+2x^2+3x+1\)
即使方程式不同,圖形大概的趨勢仍然是三次方程式
當 \(x\),也就是輸入的的資料量極大時
則整體趨勢幾乎只受到最大冪次 \(x^3\) 的影響
回到漸進符號
我們把剛剛方程式裡的 \(y\) 想成電腦的運算次數
\(x\) 想成輸入的資料量
假設我現在的程式,他的運算次數 \(y=x^3+20x^2+17x+101\)
當輸入的資料量極大時,運算次數增加的趨勢幾乎只受到\(x^3\)的影響
所以我們稱此程式的複雜度為 \(O(N^3)\)
漸進符號用的資料量通常以 \(N\) 表示
空間複雜度同理
如果運算次數與資料量無關呢?
則複雜度為 O(1),也就是常數複雜度
衡量完之後要幹嘛
當然就是要判斷你的程式會不會超時了
電腦的計算速度大約為每秒 \(10^9\) 次
拿出剛才的複雜度 \(O(N^3)\)
這時候當 \(N\) 大於 \(\sqrt[3]{10^9}=10^3\)時,這個程式通常無法在 1 秒內跑完
當然還要考慮一下常數的影響
所以這個 \(N\) 的上限一定會再低一點
衡量完之後要幹嘛
對於一個競賽題目中,輸入資料量的上限,至少需要多低複雜度的程式才能在 1~3 秒內跑完

STL
STL
是 C++ 內建的各種資料結構、演算法、迭代器......
反正很好用,也很常用
Vector
向量?
高級陣列
vector 與傳統陣列最大的不同,就是他可以隨時改變大小,有些題目用 vector 會好寫很多
宣告
vector<int>a(n);宣告一個名稱為 a,大小為 n,值的資料型態為 int 的 vector
vector<int>a;也可以不給大小
vector<int>a = {0, 1, 2, 3, 4};
vector<int>b(n, 0);也可以先給定值
也可以初始化(歸零)
宣告
vector<vector<int>>a(n, vector<int(m, 0));二維陣列,n*m 的大小
並歸零
常用語法
vector<vector<int>>a;
a.push_back(1);
a.push_back(3);
a.push_back(2);
//a = {1, 3, 2}
a.pop_back();
//a = {1, 3}push_back:從陣列的尾端推一個元素進來
pop_back:把尾端的元素推出去
常用語法
vector<int>a;
for(int i = 0 ; i < 19 ; i++) a.push_back(1);
cout<<a.size() << ' ' << a.capacity(); //19 32
return 0;size:抓目前有使用到的空間大小
capacity:抓目前整個陣列(包含以擴充但未使用部分)
甚麼意思?
常用語法
vector<int>a;
a.push_back(1);
//size=1 capacity=1
a.push_back(1);
//size=2 capacity=2
a.push_back(1);
//size=3 capacity=4
a.push_back(1);
//size=4 capacity=4
a.push_back(1);
//size=5 capacity=8每次push_back時,如果空間不夠,就會先把實際大小擴充成原本的兩倍
常用語法
vector<int>a;
a.push_back(1);
//size=1 capacity=1
a.push_back(1);
//size=2 capacity=2
a.push_back(1);
//size=3 capacity=4
a.push_back(1);
//size=4 capacity=4
a.push_back(1);
//size=5 capacity=8每次push_back時,如果空間不夠,就會先把實際大小擴充成原本的兩倍
常用語法
vector<int>a;
auto bit = a.begin();
auto eit = a.end();a.begin():陣列中第一個值的 iterator
a.end():陣列中最後一個值的 iterator
sort(a.begin(), a.end());
reverse(a.begin(), a.end());可用於 sort, reverse, upper/lower bound 等地方
不好用的語法
vector<int>a(2, 3);
a.insert(1, 4);
//a = {3, 4, 3}a.insert(位置, 數值);
在陣列中的一個位置插入一個數值
\(O(N)\),爛
vector<int>a(15, 3);
a.erase(a.begin() + 3, a.end());
//a = {3, 3, 3}
a.erase(a.begin());
a = {3, 3}a.erase(iterator, iterator);
把陣列中的一段數值刪除
即使只有刪除一個數值,複雜度還是能到\(O(N)\),還是爛
pair
一對
一次存兩個變數
一個 pair 有兩個變數,而且資料型態可以不同
像是我可以把一個人名配對一個分數,再對他做排序等動作,兩個被包在一起的元素就會一起移動
宣告
pair<string, int>a;宣告一個包著 string 與 int 的 pair
pair<string, int>a(wut, 17);可以初始化
vector<pair<int, int>>a;還能包進其他 STL 裡
語法
pair<string, int>a(wut, 17);
a.first = "eee"
cout << a.first; //eee
cout << a.second; //17pair<string, int>a;
a = make_pair("idk", 123);make_pair()生成一個 pair
遍歷
便利
python for
a = [1, 2, 4, 3, 5]
for i in a:
print(i, end = ' ')
#1 2 4 3 5如果你想要把整個陣列的數字一個一個輸出,在 python 中有這種寫法
注意這時候的 i ,他不像一般的 for 迴圈裡的 i,是一個 int而是跑到陣列裡面變成陣列裡的數值
稱為迭代器
要怎麼用 C++ 寫?
C++ for
vector<int> a = {1, 2, 3, 4, 5};
for (int i = 0 ; i < a.size() ; i++){
cout << v[i] << ' ';
}
//1 2 3 4 5vector<int> a = {1, 2, 3, 4, 5};
for(vector<int>::iterator it = a.begin() ; it != a.end() ; it++){
cout << *it << " ";
}
//1 2 3 4 5欸不是這太噁心了吧
還記得 auto 嗎
vector 有自己迭代器的資料型態
C++ for
vector<int> a = {1, 2, 3, 4, 5};
for(auto it = a.begin() ; it != a.end() ; it++){
cout << *it << " ";
}
//1 2 3 4 5還是沒有比原本的好寫啊?
vector<int> a = {1, 2, 3, 4, 5};
for(auto i : a){
cout << i << " ";
}
//1 2 3 4 5這很簡短了
基本上這跟 python 的寫法是一樣的
a = [1, 2, 4, 3, 5]
for i in a:
print(i, end = ' ')
#1 2 4 3 5stack
疊
一疊椅子

你們應該知道這種椅子
當你要拿走椅子的時候,都會是從最上面拿
當你要放椅子的時候,也是從最上面放
想一下現在有一張椅子,他是第一個放進去的
當你要拿椅子的時候,他是不是在最下面,最後一個才能拿到
這種先進後出(LIFO)的資料結構即為 stack
常用語法
Copy of Minimal
By 硼/Boron



