Web Crawler
志摩
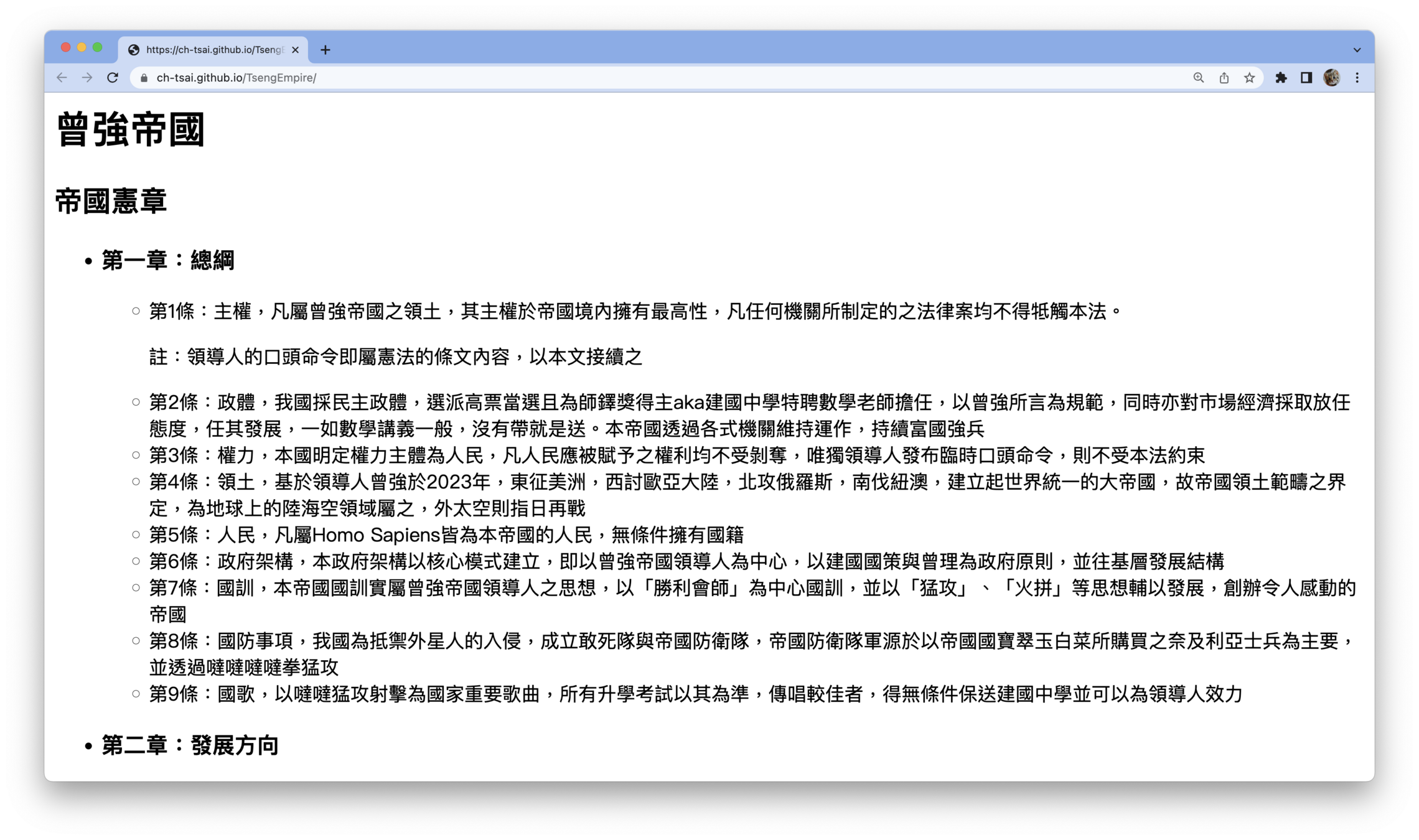
這網站好讚好想複製下來
一個個慢慢複製嗎?
好像沒有很慢
但如果有連結可以點呢?
一個個點進去複製嗎?
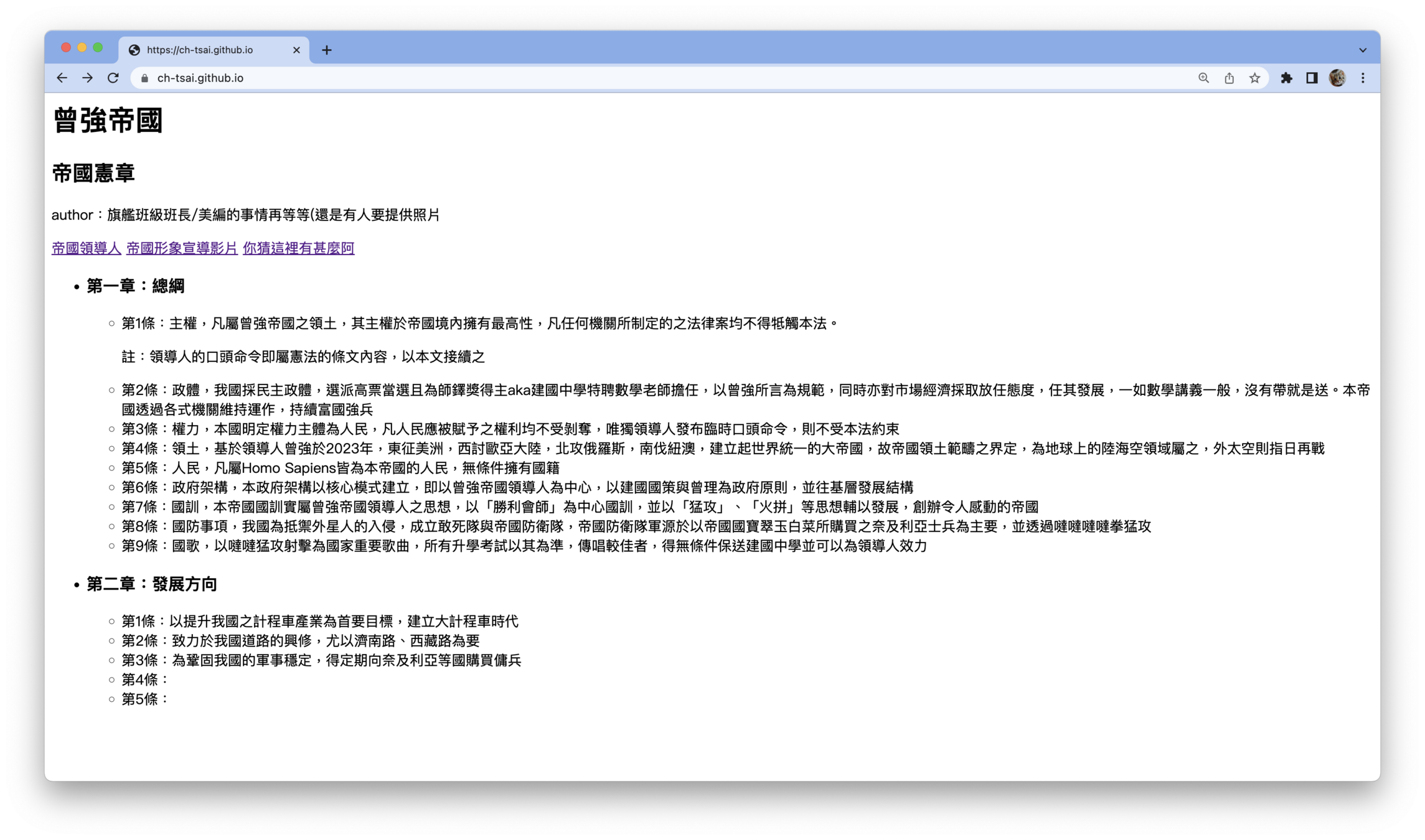

好麻煩
- 網路爬蟲
- 自動抓取網站資料
- 提升搜集效率
Web crawler

抓取網頁HTML
先安裝 requests
pip install requestsrequests
import requests #匯入requests
url = "https://ckefgisc.github.io/" #想要爬的網址
html = requests.get(url) #返回一個response物件
print(html.text) #.text返回網頁原始碼抓網頁的HTML
結果?
requests
抓網頁的HTML
<!DOCTYPE html>
<html lang="zh-TW">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<script src="https://code.jquery.com/jquery-3.6.1.min.js"></script>
<script src="/scripts/include.js"></script>
<script src="/scripts/news.js"></script>
<link rel="stylesheet" href="/styles/index.css">
<title>建北電資 CKEFGISC</title>
</head>
<body>
<header></header>
<div id="main-container">
<div id="title-section" class="section">
<h1>全台最「電」</h1>
<h1>資訊系社團</h1>
<h2><a style="all:inherit" href="/news/posts/iscoj-ctf/4SygTCnmdkQWzpEd/4ZVGbyywh5xSQdKRhpxFKDkX9WmFTMHB.html">建中電子計算機研習社×北一女中資訊研習社</a></h2>
<a href="/linktree/">點我加入</a>
</div>
<div id="news-section" class="section">
<div class="section-title">
<p>最新消息</p>
</div>
<ul id="news-list" class="line-list"></ul>
</div>
<div id="lesson-section" class="section">
<div class="section-title">
<p>課程介紹</p>
</div>
<div id="lesson-links">
<a id="major-lesson" href="/lesson#major-class">大社課</a>
<a id="noon-lesson" href="/lesson#noon-class">北資中午小社課</a>
<a id="after-lesson" href="/lesson#after-class">建北電資聯合<br>放學小社課</a>
</div>
</div>
<div id="faq-section" class="section">
<div class="section-title">
<p>常見問答</p>
</div>
<ul class="line-list">
<li>
<p class="qq">Q:小社是星期幾?</p>
<p>A:</p>
<p>每天放學之後都有喔~(除了段考週和前一週)</p>
<p class="btn"><a class="btn_a" href="/lesson/">點我看小社介紹</a></p>
</li>
<li>
<p class="qq">Q:學長姐,我有第八節,來得及來聽課嗎?</p>
<p>A:</p>
<p>可以喔!</p>
<p>我們基本上會等到北資的同學5:10下課可以安全走到建中的時間才開始上課,不論是北資還是建電的數資、科學班學生,都歡迎來參加小社!</p>
</li>
<li>
<p class="qq">Q:我要怎麼來聽社課呢?</p>
<p>A:</p>
<p>只要你是建北電資的社員,都可以直接來聽課,完全不用事先報名的啦XD</p>
</li>
</ul>
</div>
<div id="aboutsite-section" class="section">
<div class="section-title">
<p>關於本站</p>
</div>
<div class="aboutsite_sec">
<div class="aboutsite_title"><a style="all:inherit" href="/news/posts/iscoj-ctf/4SygTCnmdkQWzpEd/D9bWhXXDuHgTQ8QXb5yAps4gk7xHqEyc.html">緣起</a></div>
<div class="aboutsite_text">
建北電資以往皆有架設網站作為招生及宣傳用途。但是自從建電社辦的伺服器被學校沒收之後,一直以來都找不到一個良好的網站架設環境,也沒有一個地方讓學術們統一放置教材供學弟妹使用。因此,在一三上幹了之後,一二學術長檸檬便一直希望鹽亞倫可以將他們沒有做出的社網完成。因此,不會css的鹽亞倫便找了溫室菜以及北資學術長嗯嗯,嘗試從頭寫出一個網站,並且透過github pages進行架設。<br>
<div style="text-align: right;"><a href="/about/site.html" class="aaa">>>> 閱讀更多本站歷史</a></div>
</div>
</div>
<div class="aboutsite_sec">
<div class="aboutsite_title">製作團隊</div>
<div class="aboutsite_text">專案管理:建電42nd吳亞倫<br>網站架設:北資36th蘇怡恩、建電42nd蔡政廷<br>
<div style="text-align: right;"><a href="/about/site.html" class="aaa">>>> 更多本站資訊</a></div>
</div>
</div>
</div>
</div>
<footer></footer>
<script>
listNews(0, 4);
</script>
</body>
</html>太長了這只是片段
requests
修改url參數
import requests
#法一
url = 'https://httpbin.org/get?key1=value1&key2=value2'
#直接指定網址
html = requests.get(url)
print(html.text)
#方法二
data = {"key1":"value1","key2":"value2"}
url = 'https://httpbin.org/get'
html = requests.get(url, params = data)
#利用params指定
print(html.text)requests
遇到按鈕怎麼辦

requests
遇到按鈕怎麼辦
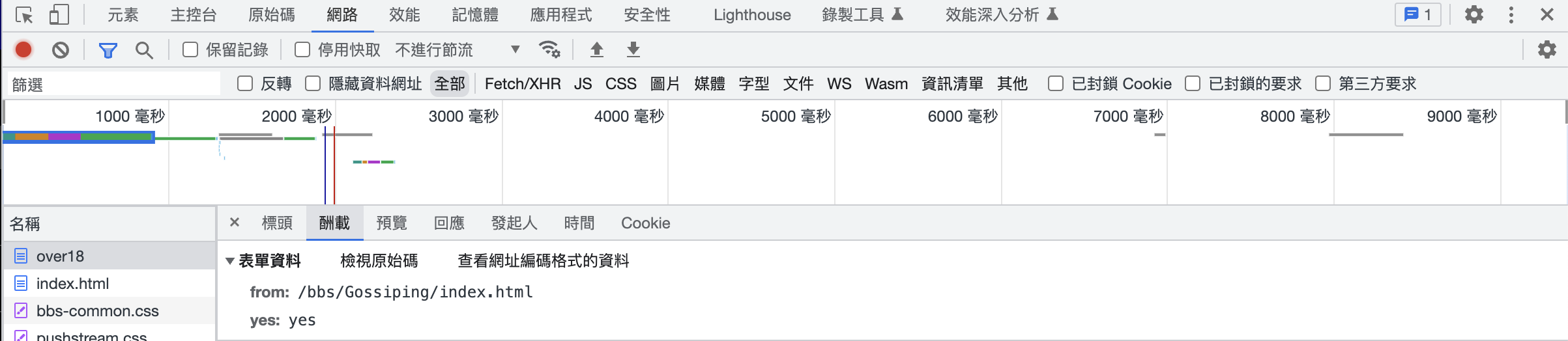
觀察發送的封包
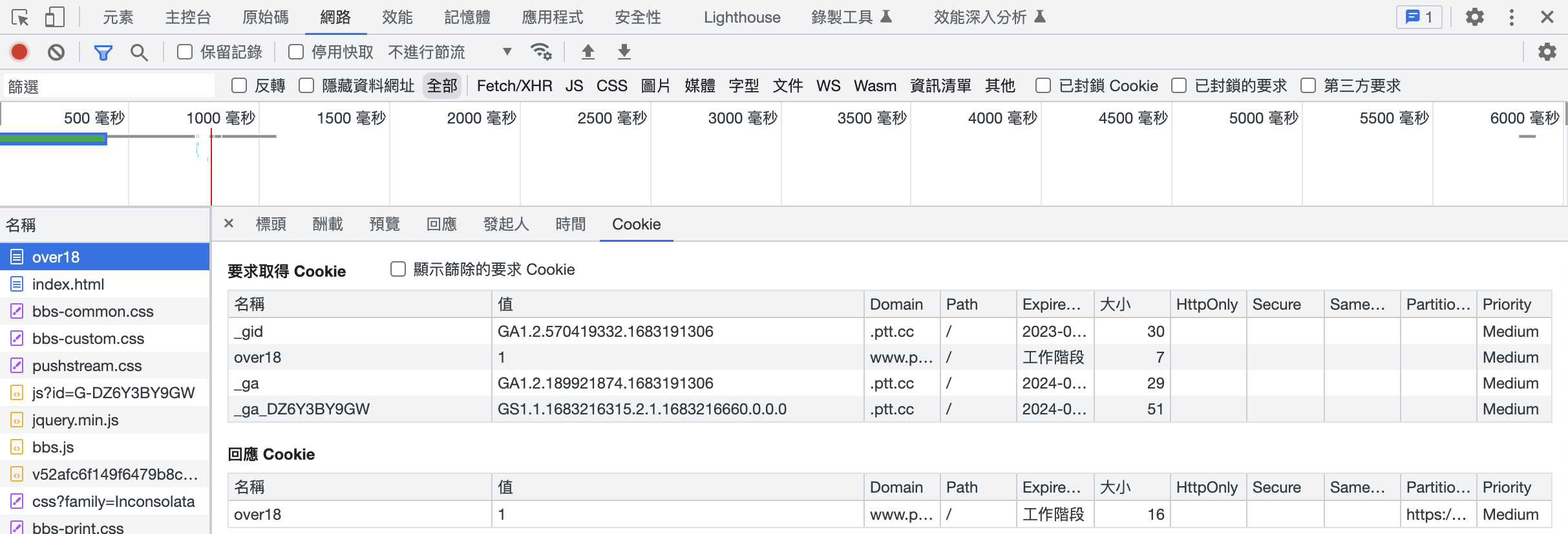
發現有 Cookie 和參數
requests
遇到按鈕怎麼辦
import requests
Cookie = requests.Session() #儲存送出的requests所收到的cookies有需要時發出
data = { #所需之參數
"from":"/bbs/Gossiping/index.html",
"yes":"yes"
}
html_first = Cookie.post("https://www.ptt.cc/ask/over18",data=data)
#模擬點擊按鈕
html_second = Cookie.get("https://www.ptt.cc/bbs/Gossiping/index.html")
print(html_second.text)這樣就能看一些大人才能看的東西了
requests
headers
import requests
url='https://ckefgisc.github.io/'
html=requests.get(url)
print(html.headers) #返回headersrequests
偽裝headers
import requests
url = 'https://httpbin.org/'
headers = {"user-agent":"Mozilla/5.0"} #指定headers
html = requests.get(url, headers = headers)
print(html.text)requests
偽裝headers
為什麼要偽裝?
網站的自我保護機制
為了避免被爬蟲吃太多資源
一開始直接判定送來的requests有沒有headers
為了避免被擋而加上headers來偽裝成使用者
requests
其他的一些功能
html = requests.put('http://httpbin.org/put', data = {'key':'value'})
html = requests.delete('http://httpbin.org/delete')
html = requests.head('http://httpbin.org/get')
html = requests.options('http://httpbin.org/get')
html = requests.patch('http://httpbin.org/get')以上的函式有什麼作用有興趣自行了解一下
講下去有點偏離主題
解析網頁HTML
先安裝 beautifulsoup
pip install bs4BeautifulSoup4
解析HTML
How
import requests
from bs4 import BeautifulSoup
url = 'https://ckefgisc.github.io/'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'html.parser')
#兩個參數 第一個是原始碼 第二個是解析方式
#把解析後的結果傳進soup
print(soup.prettify())#輸出排版後的結果BeautifulSoup4
用HTML標籤尋找
import requests
from bs4 import BeautifulSoup
url = 'https://ckefgisc.github.io/'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'html.parser')
print(soup.find('a'))#尋找第一個<a>標籤
print(soup.find_all('a'))#尋找所有的<a>標籤
print(soup.find_all('p', limit=3))#尋找前三個<p>標籤
print(soup.find("div", class_="aboutsite_text"))
#尋找<div>標籤中的特定class的內容BeautifulSoup4
取得連結
import requests
from bs4 import BeautifulSoup
url = 'https://ckefgisc.github.io/'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'html.parser')
for link in soup.find_all('a'): #每一個<a>標籤中
print(link.get("href")) #取得擁有href屬性的東東BeautifulSoup4
取得內文
import requests
from bs4 import BeautifulSoup
url = 'https://ckefgisc.github.io/'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'html.parser')
print(soup.find('li').getText())
#印出第一個<li>內的文字結束啦
隨附上學期練習的爬蟲跟Dcbot結合
雖然校網更新了🥲
Web_Crawler
By brianlai


