NodeJS
Basics of NodeJS, Express and REST API
Bartosz Szczeciński
2022
Agenda - Module 1
- Introduction to Node.js
- History, theory, application
- Working with Node.js apps
- Debugging
- TypeScript in Node.js
- Express
- Hello World
- Simple API (GET), working with request object
- Middleware
- REST
- Theory, design
Agenda - Moduł 2
- Introduction to databases
- SQL
- CRUD
- Transactions
- Keys, indexes
- Migrations
- SQLite in Node.js
- Bonus
- idempotency
- Swagger + OpenAPI
Intro to Node.js
Depending on whom you ask, and in what context, Node.js can be defined as either a JavaScript runtime or a JavaScript framework.
You can use Node.js to execute "plain" JS code outside of a browser environment, but you can also use one of the build in modules (imagine a C standard library) to help interact with I/O operations.
Install
Node.js follows the SemVer versioning pattern and is versioned independently from npm (which it bundles).
LTS is the "long term support" version of node, which is recommended for production applications.
Install: MacOS
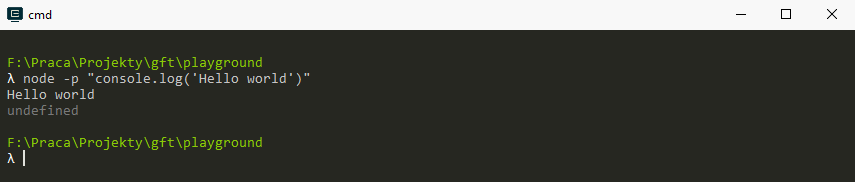
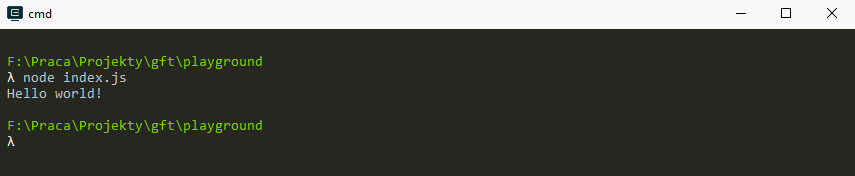
Running the code

Popular modules
Buffer & Stream
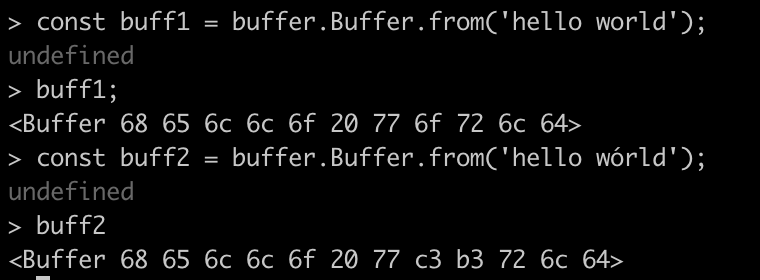
Node.js introduces and makes frequent use of two special data types that make working with data that is big, binary or both.
Node.js buffers are similar to TypedArrays (they implement the Uint8Array mechanism, by default). Buffers are fixed size which is determined at creation:
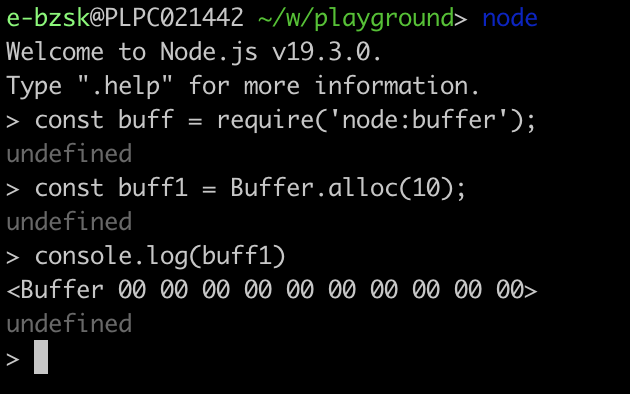

Buffer: creating and reading
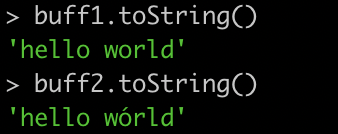
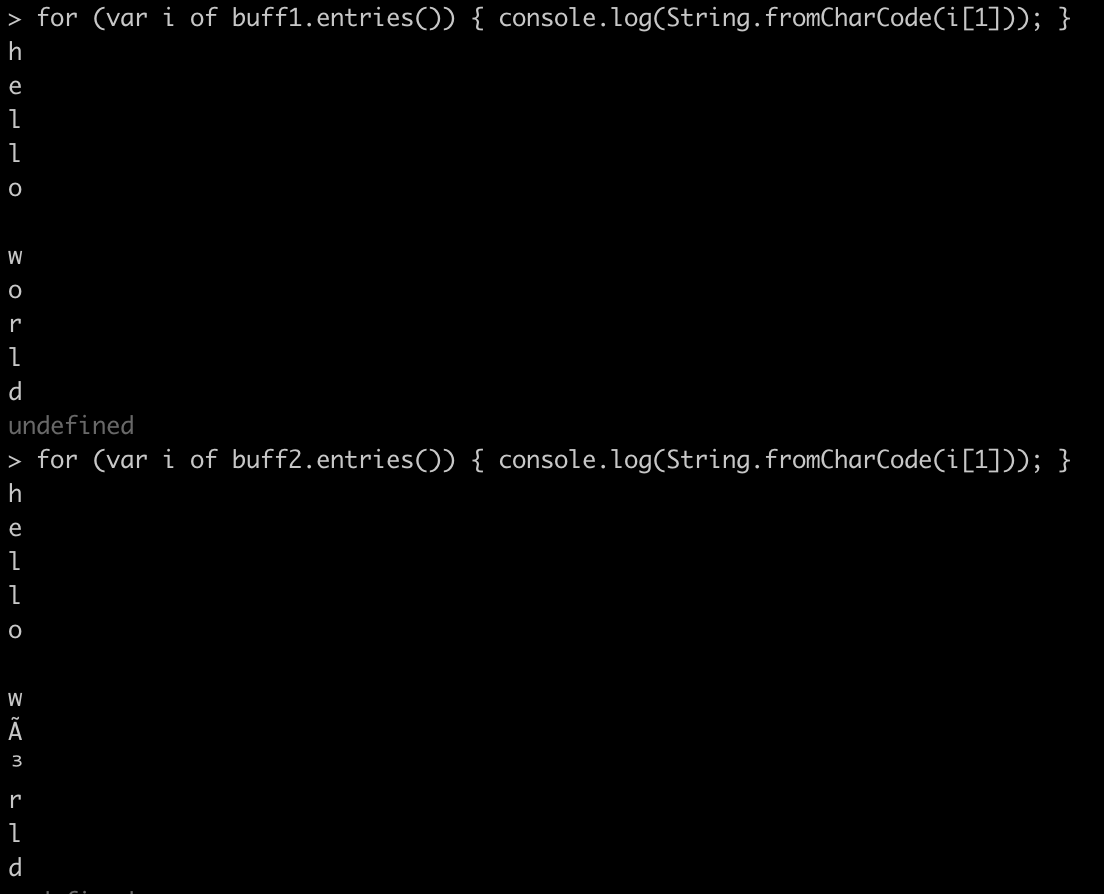
You can also create a buffer from a string:
Streams
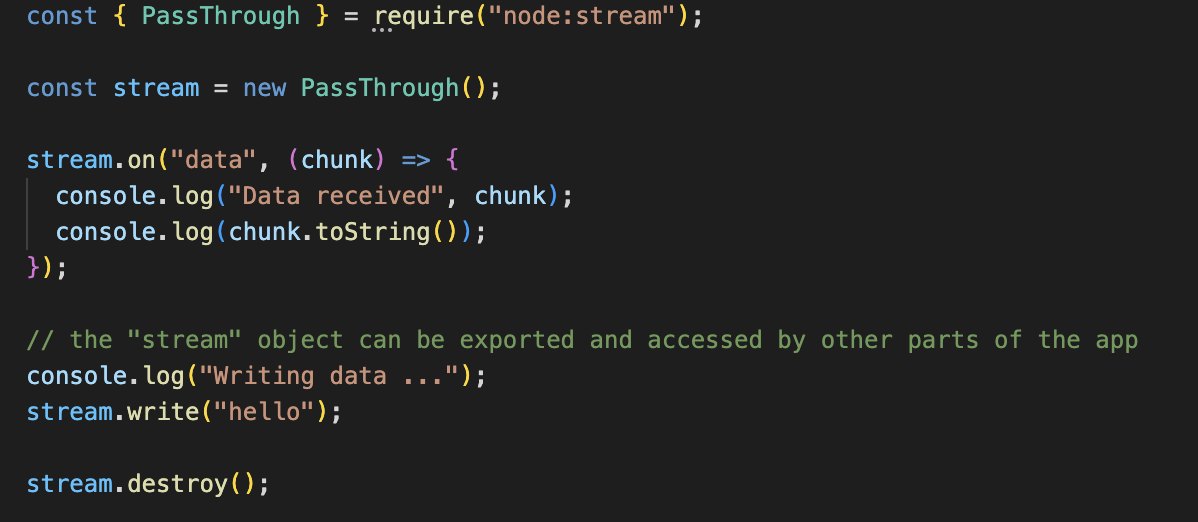
Similarly to buffers, streams are data types that represent a binary data, but one that might not be held in memory (so we don't know its size) and might come from local or remote IO system.
The concept of streams allows us to operate on big datasets without having to load them to memory all at once and thus keep our app fast and with small memory footprint.
Majority of operations exposed by the node:fs module will offer both asynchronous (streamed) and synchronous (blocking) methods.

Types of stream
Node has 3 major types of streams:
- readable - most commonly used to read file, http call responses
- writeable - used to write data to file, communicate with remote servers
- duplex - can be used to communicate within single app context, e.g. to implement an EventEmitter or PubSub pattern
Example stream

Node.js version management

nvm
The nvm tool allows you to have multiple version of node.js installed on your system at the same time.
It operates on the principle of changing symlinks to the executable and all the enviroments.
This has some important implications:
- it is not scopped to a project
- each node version has its own npm ecosystem
nvm: usage
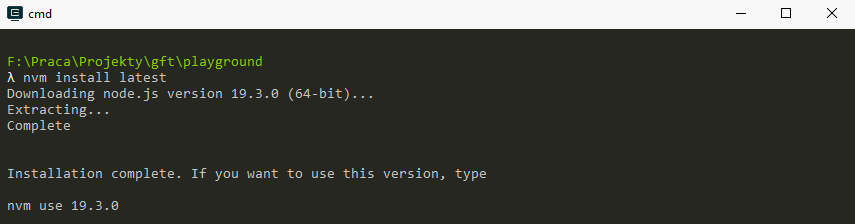
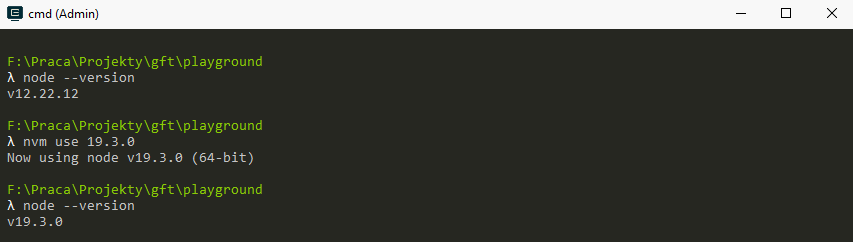
In order to switch node version you need to first install it:
.nvmrc
In order to "ensure" your project is ran with the correct version of node, you can use the .nvmrc file and include the version number:


Important
- each node installation with nvm has its own environment - this means that it will have a different version of global node modules
- some modules are built for specific node version when installed
- you need admin rights to use nvm on Windows (you can sidestep this by using WSL2 node, which is sadly slower)
npm
The node package manager (npm) is standard tool used in Node.js ecosystem to provide sharable features. There's practically no difference in using it for typical Node.js application of when building a browser project.
npx
npx is a command line tool installed with npm which allows you to invoke (among other) the binary artefacts of node packages
It will first check the node_module/.bin folder, and failing to find the command there it will try to pull from the registry (npmjs.org)
package.json
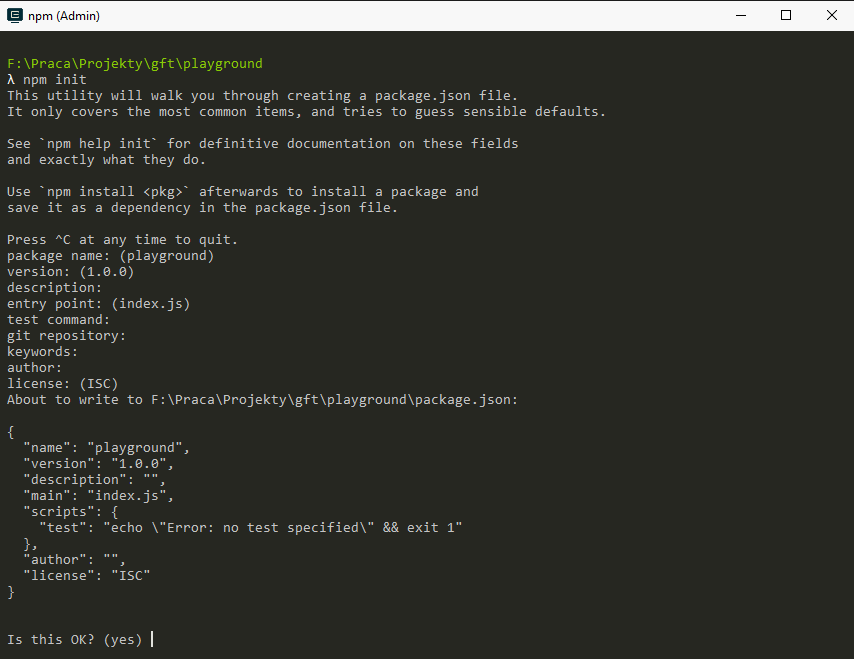
Although not required, it is good practice to have a package.json file in your project. The file describes the project with both metadata (project name, version, author etc.) and list of modules it requires in order to run properly.
npm init
npm scripts
The most important part of package.json for us (outside of dependencies) will be the "scripts" key. It contains list of commands that we can pre-define and execute with npm run
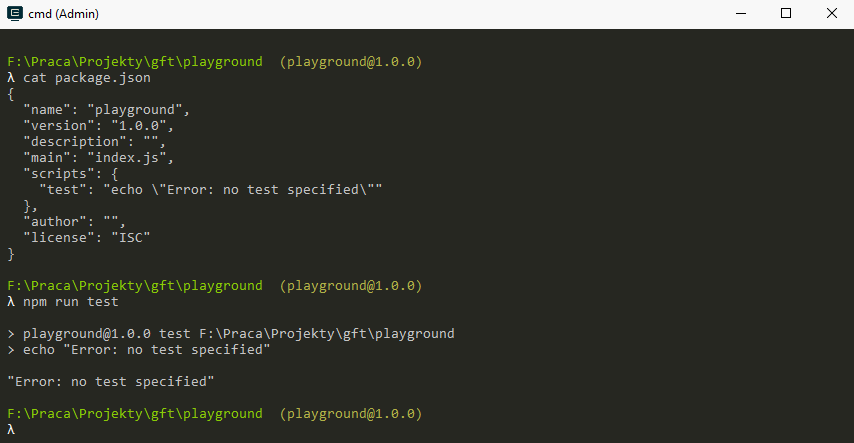
npm scripts
The scripts can contain both invocation of npm binaries (which will be executed in the context of the project) and operating system commands. You can use the OS operators like && to start commands in sequence etc.
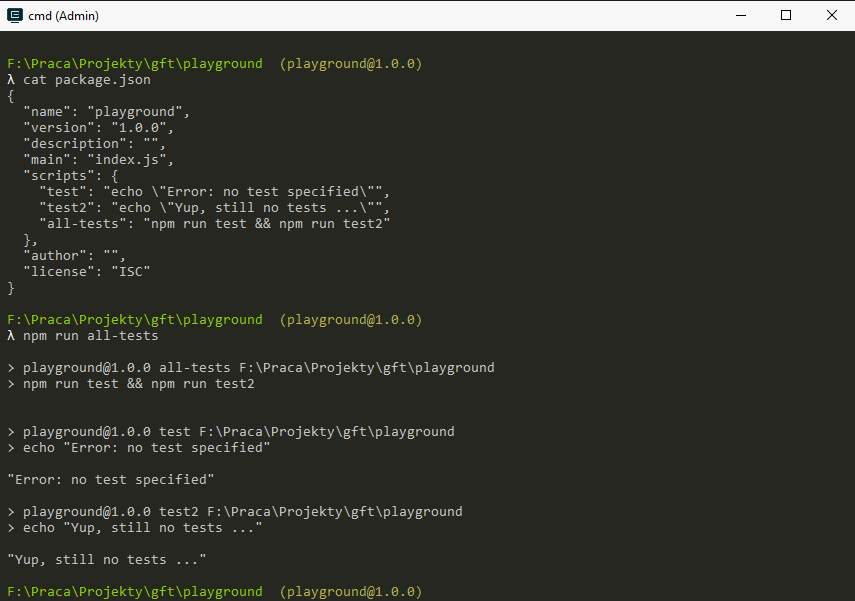
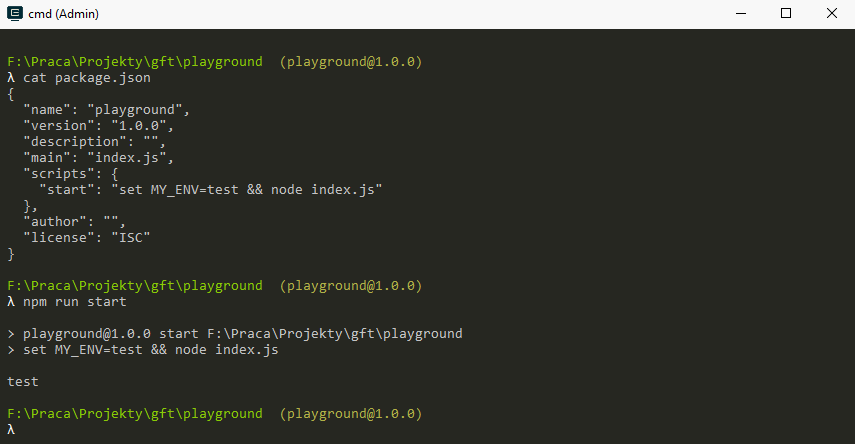
Environment variables
We can set environment variables in two ways. Either define them in the execution context prior to running the command, or pass them as part of the command itself:
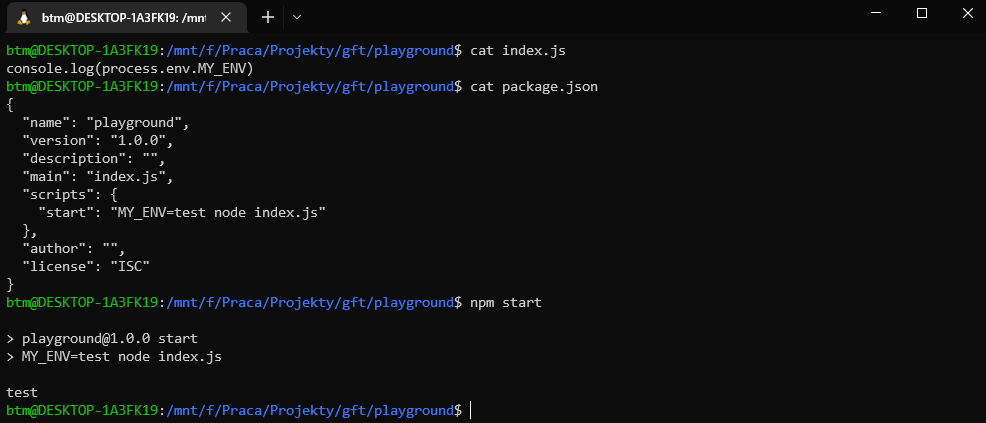
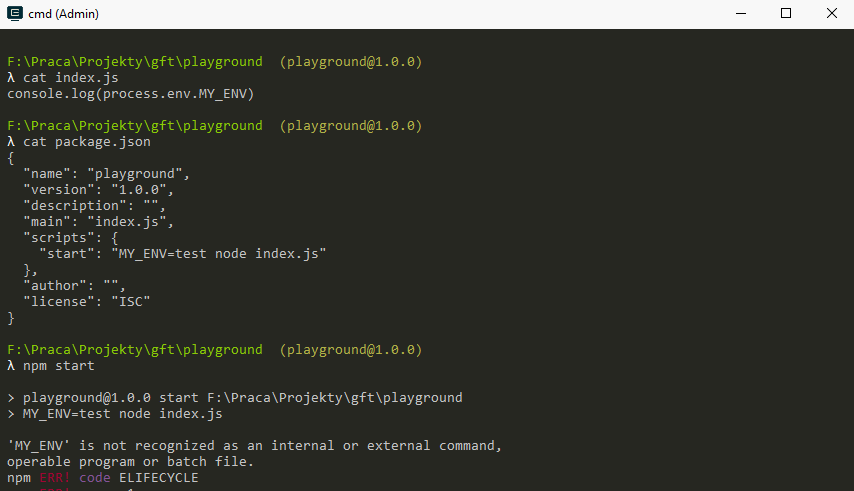
Environment variables: OS
cross-env
If you need to be able to run the same commands regardles of your runtime use a package like cross-env
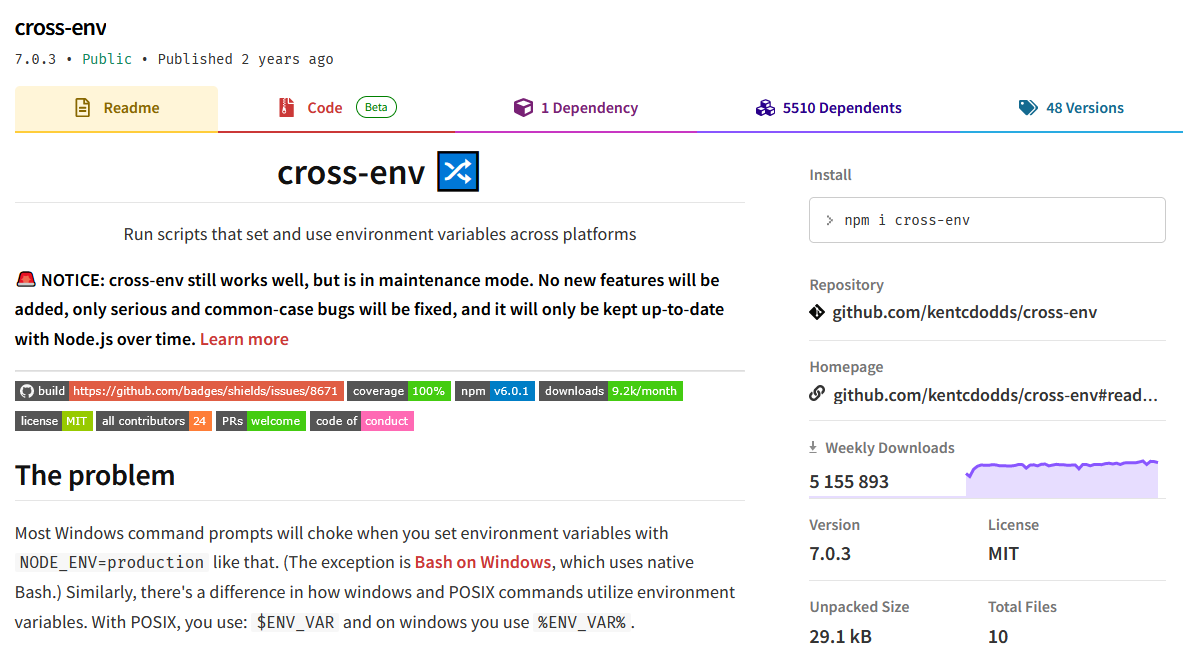
cross-env
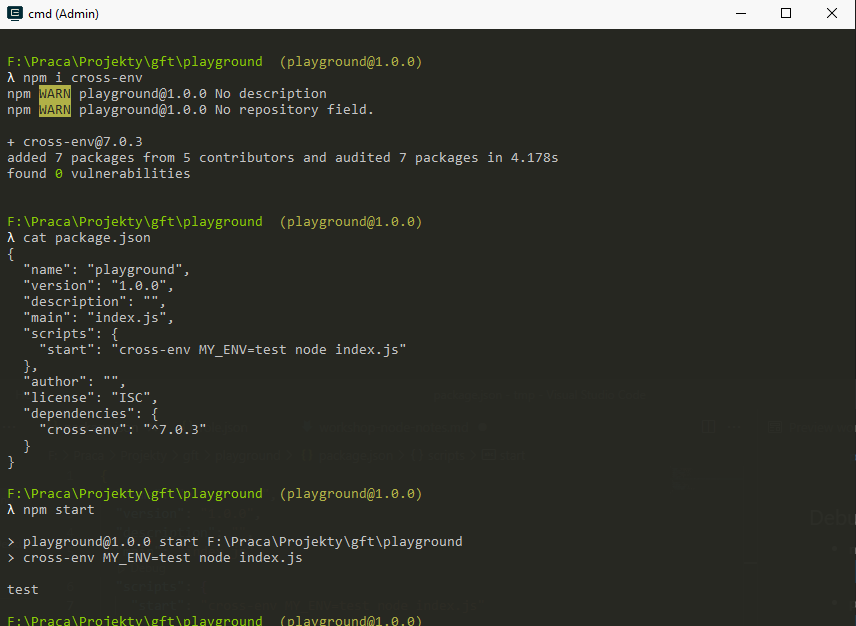
.env
As the number and complexity of our environment variables grows maintaining them via the command line is hard. We should use .env files
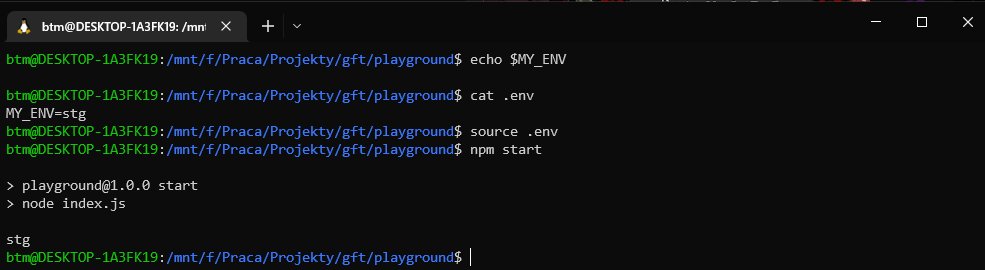
Note: the source command is not available on Windows :(
dotenv
We can use a library like dotenv to get around the Windows limitation ...
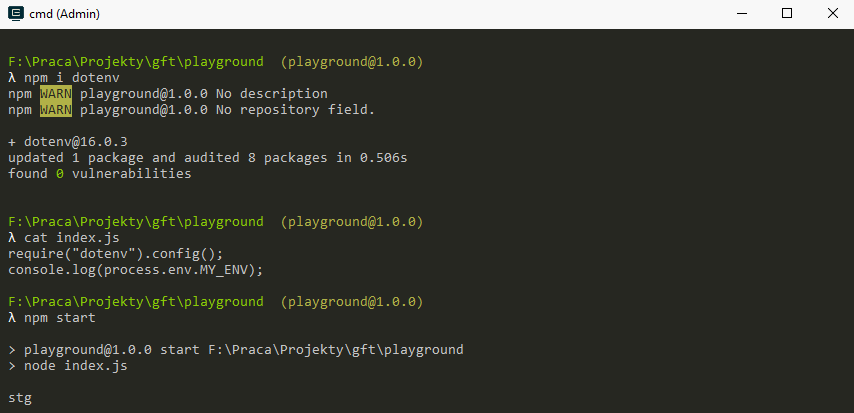
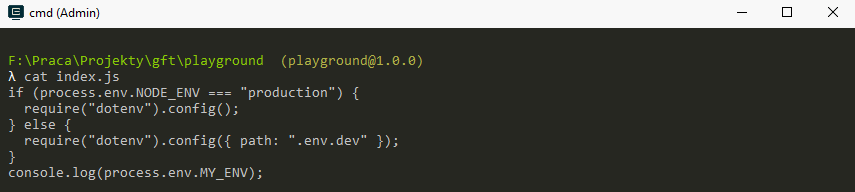
dotenv
... and to add some QoL features!
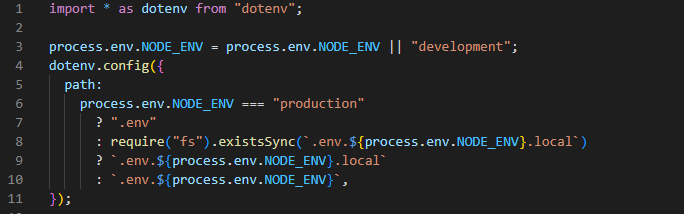
Modules: CommonJS, ES Module
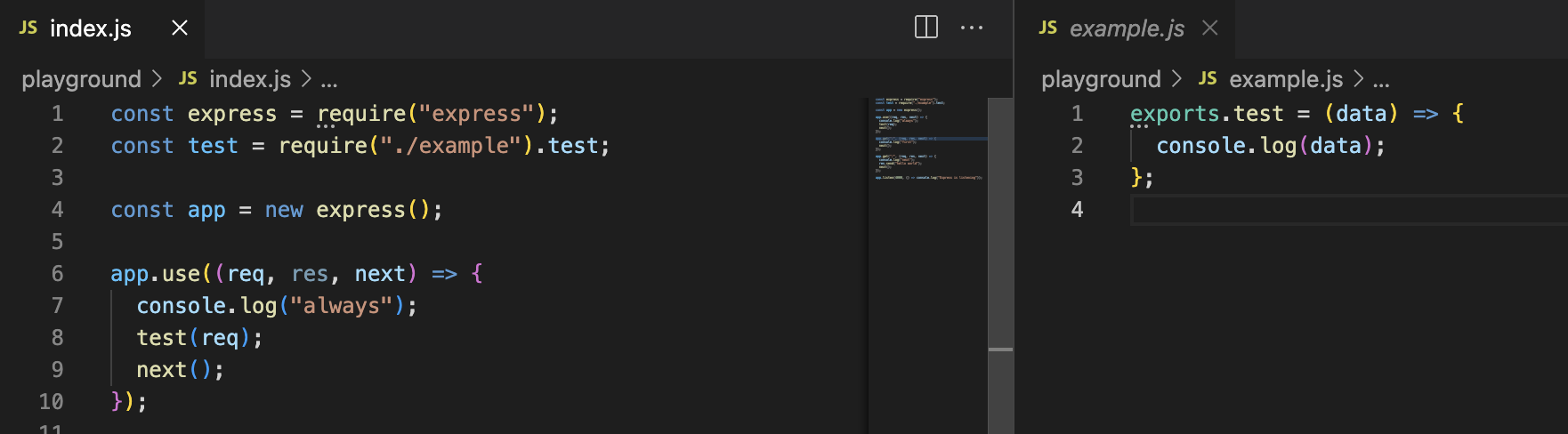
The default module mechanism is CommonJS, this means that you need to use the require syntax:
Modules: enabling ES Modules
You can enable your code to use ES Modules by changing your package.json to include "type": "module" property:
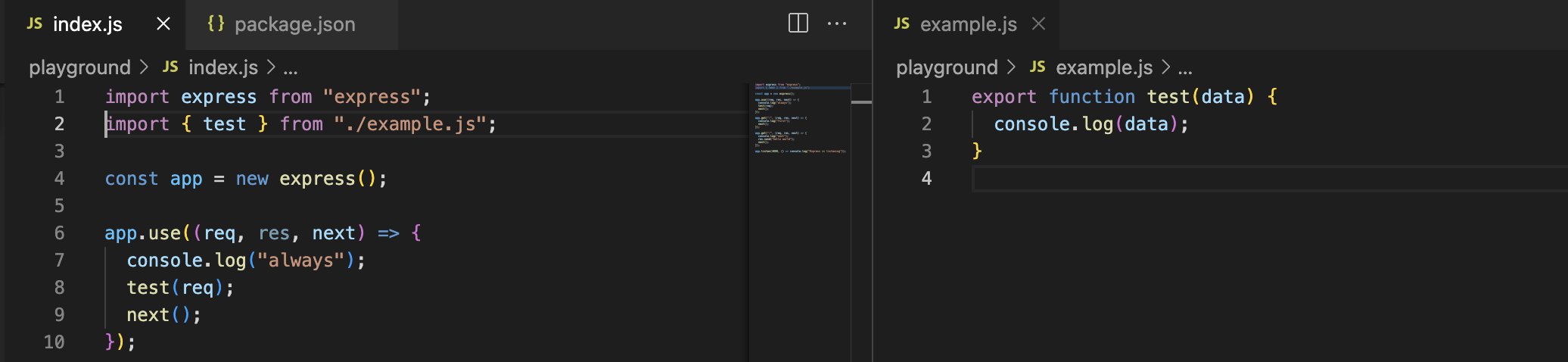
Please note that unlike when using popular bundlers (like webpack, vite) if you want to import a local module, you need to specify the extension of the file.
Modules: mixing modules
If you opted to use the ES Module mechanism in your package.json it is still possible to consume code written with CommonJS - in this case it is required to use the cjs file extension.
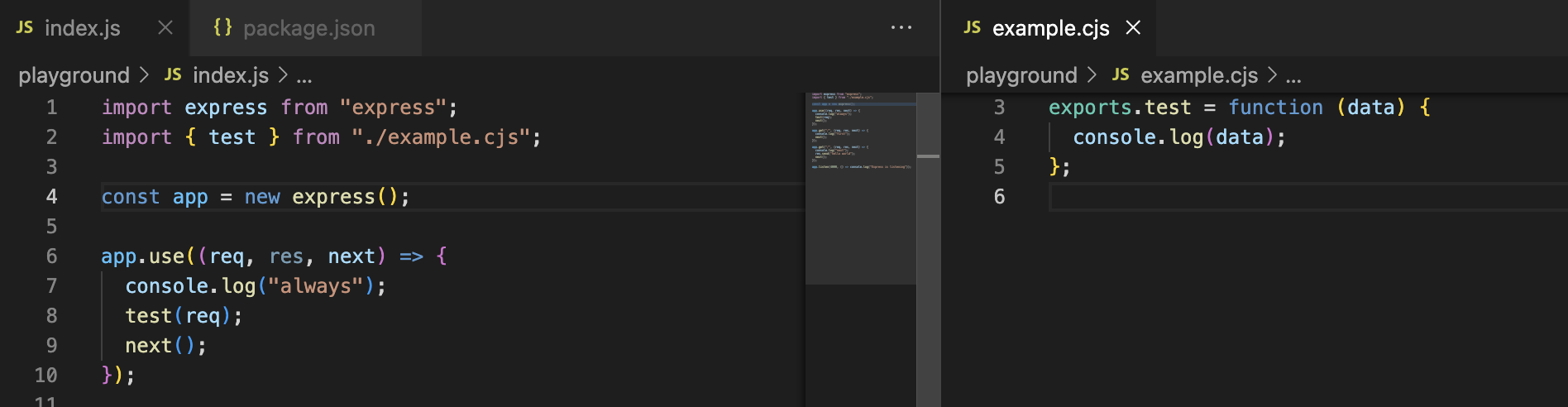
Modules: mixing modules
It is possible to mix the modules in the other direction as well, but such operation requires usage of dynamic imports:
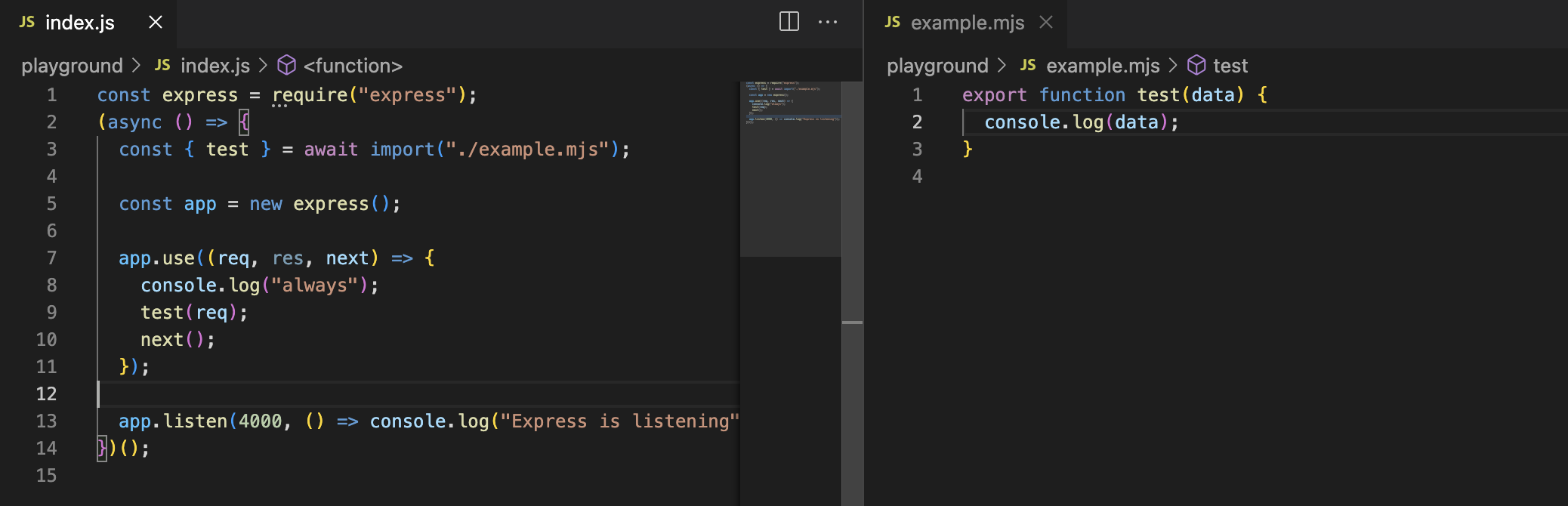
Prefix-only core modules
As the number of modules on npmjs grew - and thus the possibilty of name clash - a new feature was introduced called "scoped packages" (like @scope/package).
The same is true for internal node packages (like fs, path etc). To get around this the "prefix-only core modules" syntax was added:
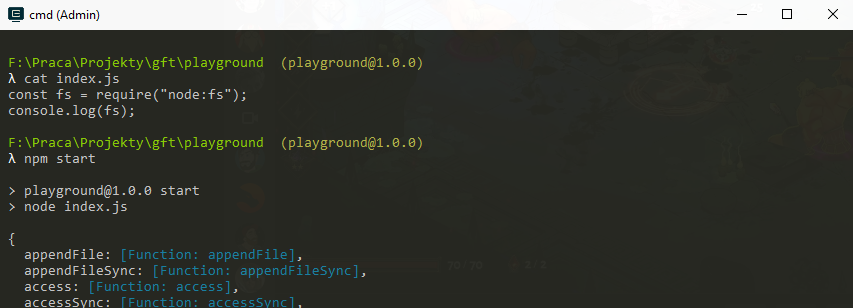

Debugging
Because Node.js internally uses the V8 engine we have the "full" debugger capabilities available to us out of the box:
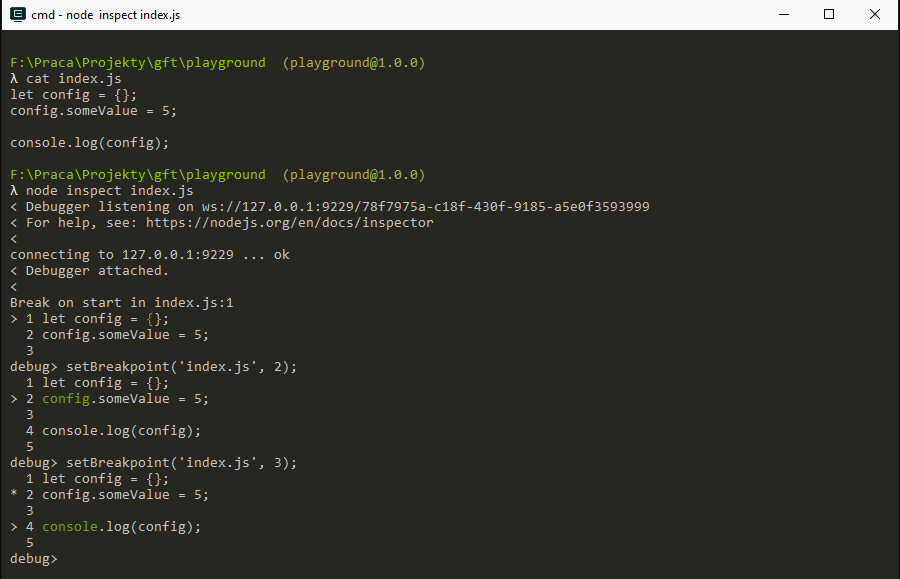
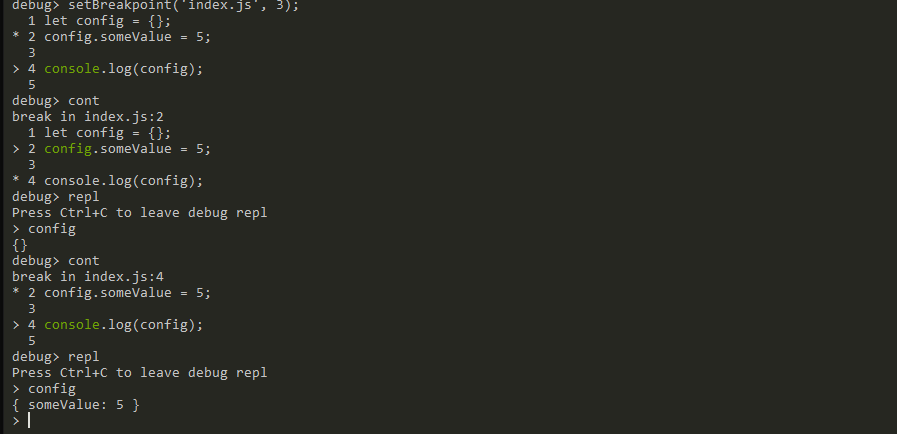
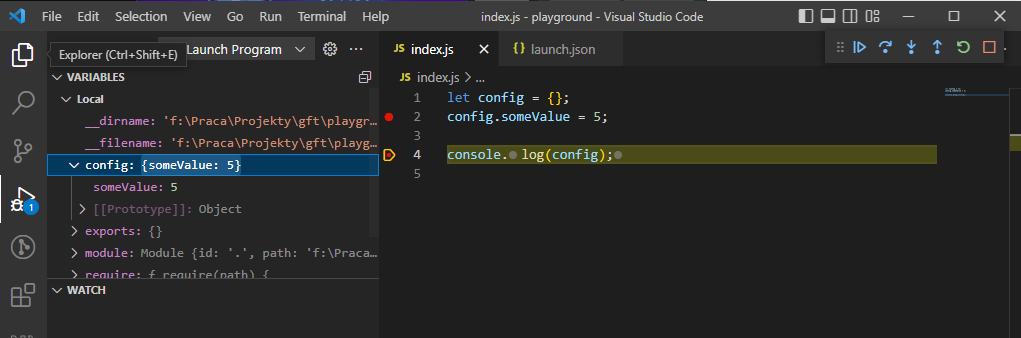
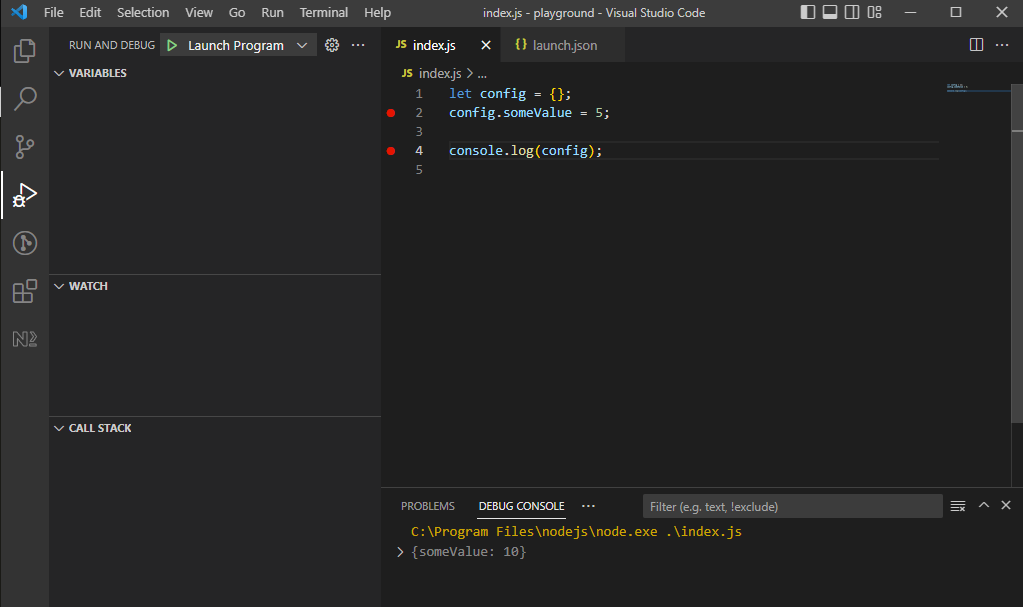
Debugging: VS Code
Of course this is not very developer friendly, so we'd rather use a tool like VS Code to connect to the process and monitor it:
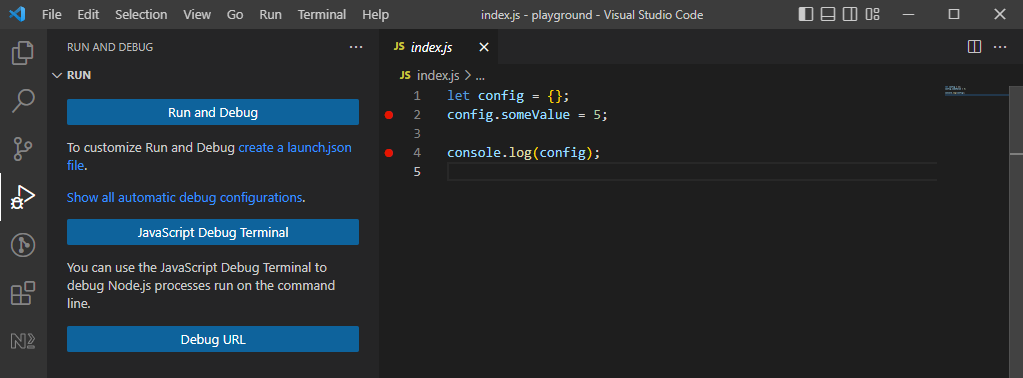
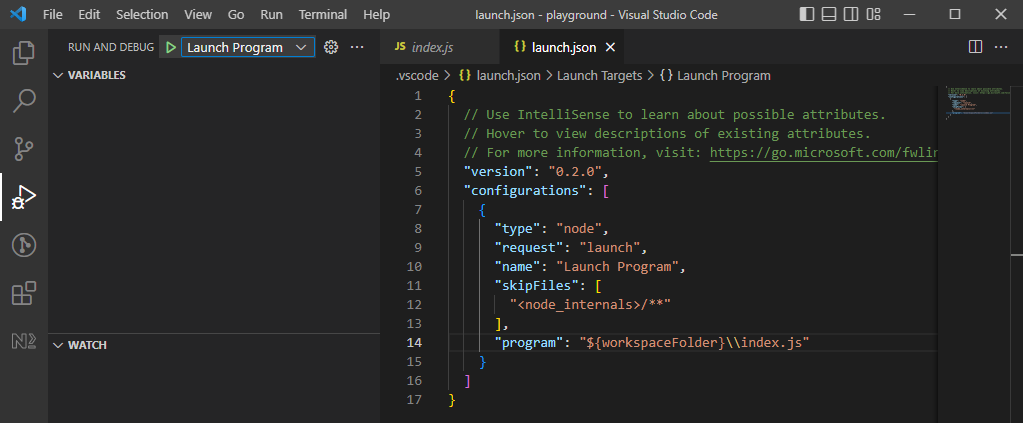
nodemon
No matter if itterating on a utility script, or working on a "24/7" app, we'd like to see results without having to manually start (or kill and restart!) the app.
nodemon
Nodemon is and app just for that!

Workshop
Knowing how to use Node.js, package.json write an app:
1. As a user, I want to start the app by calling npm start
2. As a user, I want the app to output to the console the current time, and add a new entry every 1 second
Production version
In contrary to a browser app there's not that much emphasis on having a dedicated build for production version (there ARE some cases where you'd want that!)
Instead, node apps follow the "build once, run anywhere" principle where the app is instrumented by a set of environment variables and potentially changes its behaviour depending on "where" the same code is ran.
The most important in this case is the NODE_ENV variable, which should be set to production when runnig a production release.
dependencies: normal vs dev
When declaring a dependency for your app you can either declare it as dependency or devDependency.
While declaring the dependency type doesn't impact things like performance, it might impact the production version of your app.
It is common practice to only install the dependency list of module for production build, as it assumes development libraries (such as testing, linting, transpilation) aren't needed and would only "bloat" the file size.
Similarly, there's very little benefit (or it is even disadvantageous) to using code bundlers for Node.js apps.
dependencies: stay in sync
Node.js applications are more susceptible to differences in build/run environment. As discussed before we can use .nvmrc to hint nvm what version to use.
Other thing to keep in mind is making sure the versions of your dependencies are locked (e.g. use "1.2.3" instead of "^1.2.3") and installing the exact version your app was tested with - this can be done by using npm ci instead of npm install.
Keep your app alive
There are two types of applications, those that:
- run, process some data, output and exit
- run 24/7 accepting data, processing it and awaiting further instructions
When developing Node.js apps we will be often working with both. If we need to make sure our application is alive 24/7 we need to make sure of that.
Keep your app alive: DIY

We can use tools offered by our OS that allow us to run a command on repeat. On Linux that would be until or even a while loop with bash:
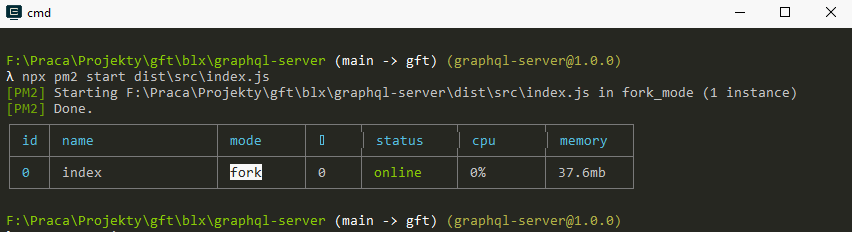
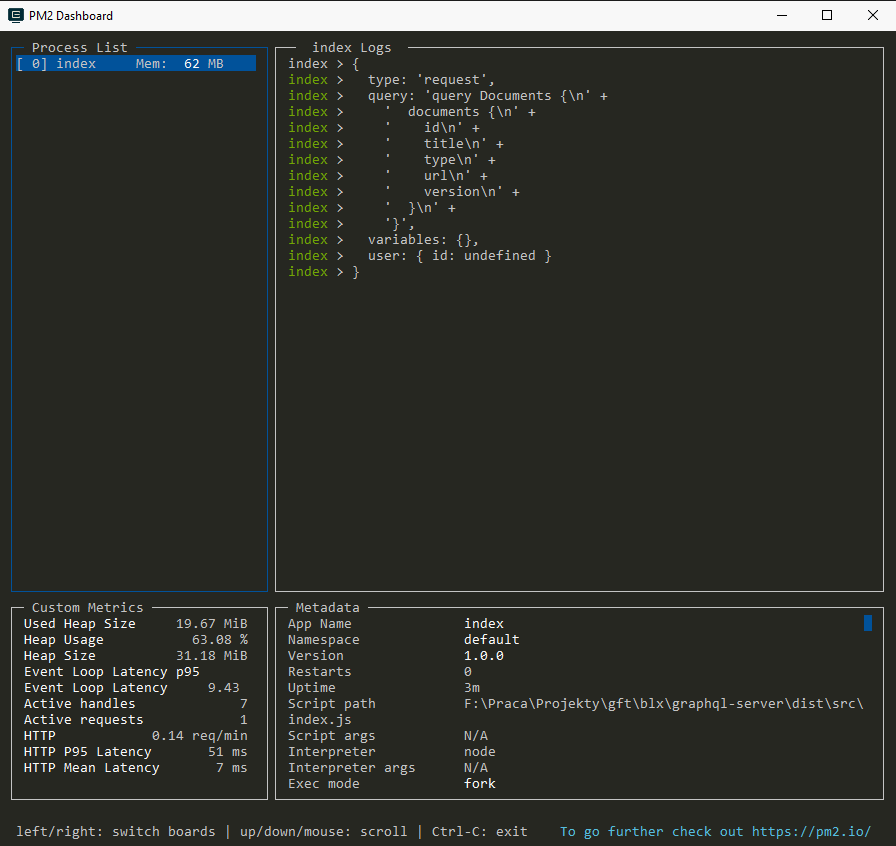
Keep your app alive: pm2
A much better tool is pm2 which can be used as both an application deamon and load balancer
Keep your app alive: pm2
TypeScript
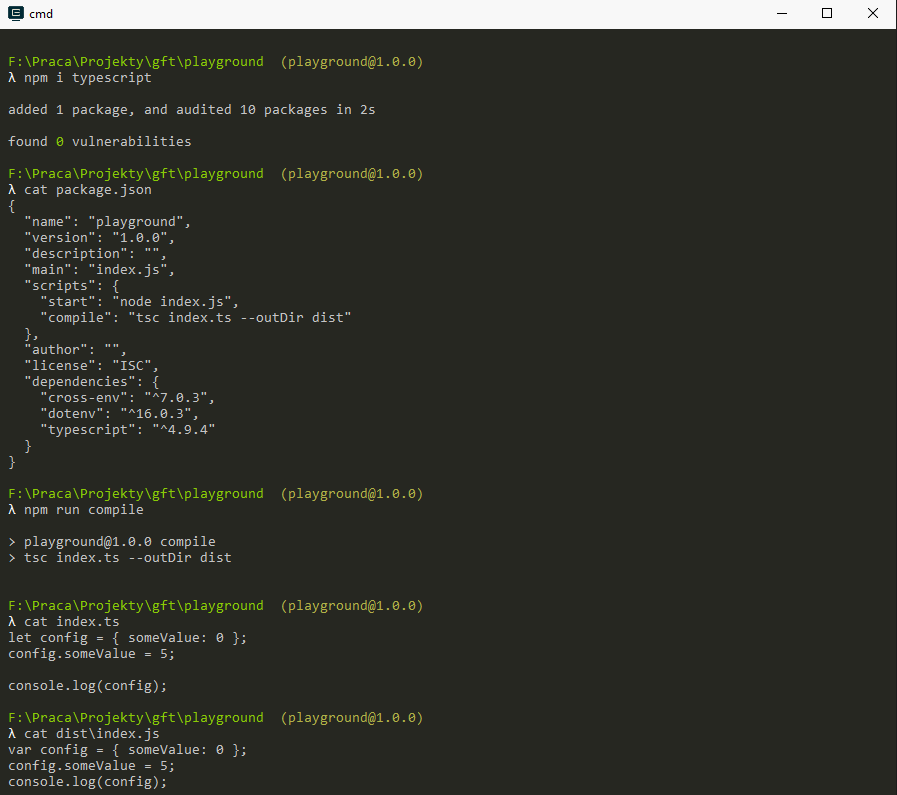
Node.js does not nativelly support TypeScript - it can only run JavaScript
In order to run our TS app on Node we will need to compile it back to JavaScript.
TypeScript
TypeScript
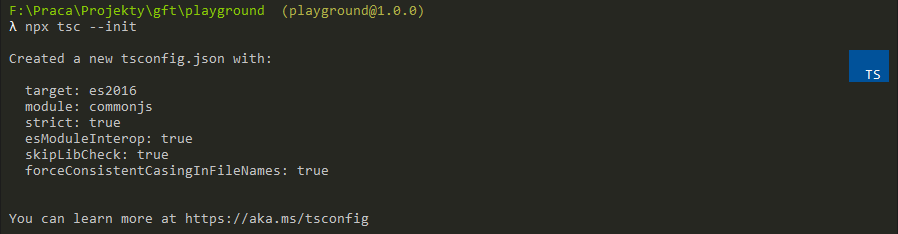
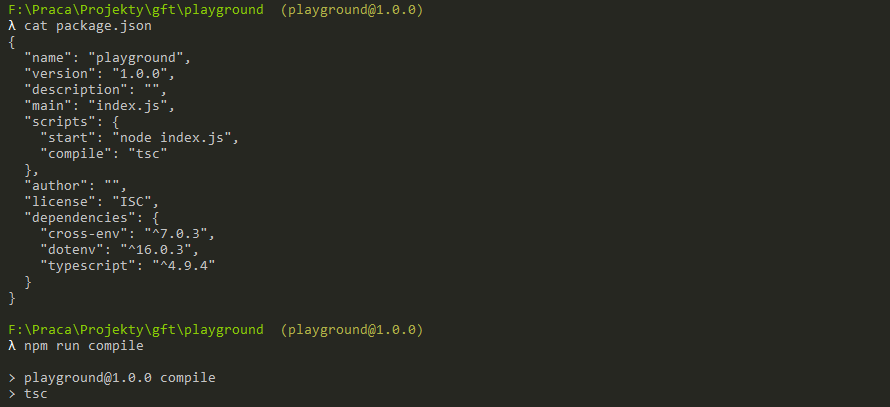
TypeScript: take care!
Please note that we defiend the outDir in both cases! This is very important because if you do not provide the flag, tsc will put the compiled .js files next to the source file. This will not only mess up your project structure (by creating a lot of files you might even need to delete manually) but also might introduce some errors that are hard to track...
ts-node, ts-node-dev
While the tsc approach is the "correct one" it will slow down your developer experience. To help keep things moving please look into those two packages:

Express
Express is a web framework for the Node.js platform which provides user with a set of functions which can be used to create various HTTP delivery platforms.
It's main purpose is to make it easy to create "web server" type applications by making it easier to work withe the request-response cycle.
Hello world
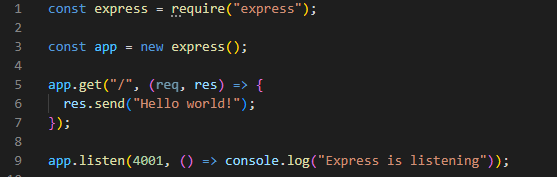
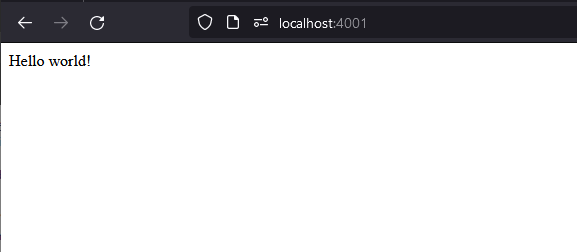
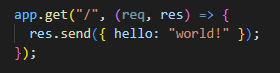
Hello world.json
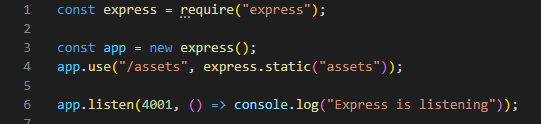
Static assets hosting
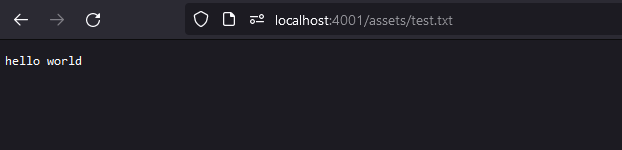
Chaining
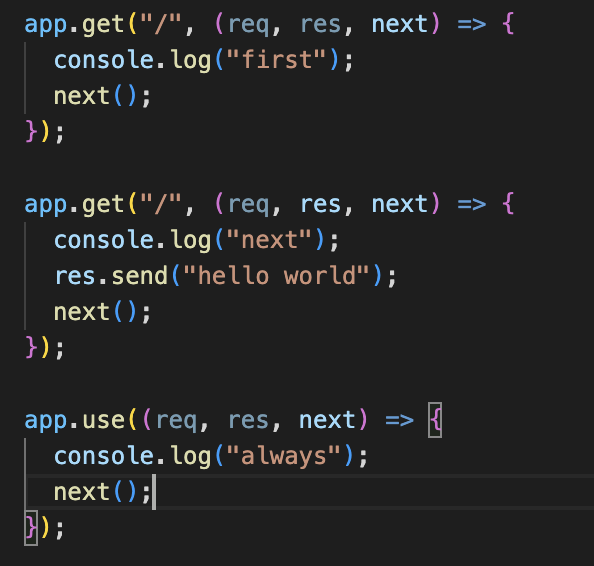
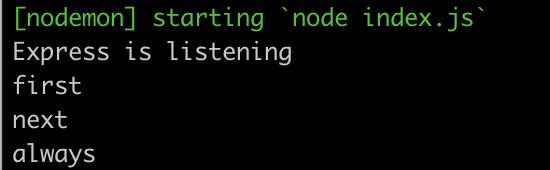
Your app can define multiple handlers for a single resource (URL) - they will all be called in sequential order.
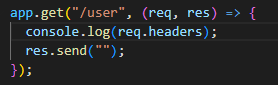
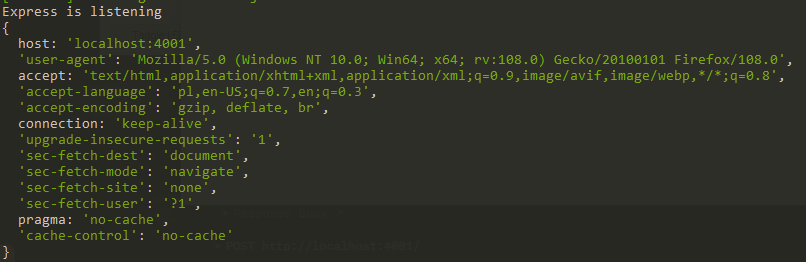
Working with the request object
We have a couple of ways we can pass data when making a HTTP call:
1. Path param - pass it as part of the URL
2. Query string


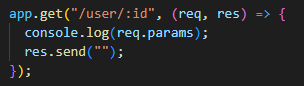
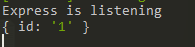
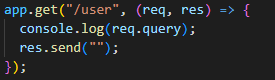
Working with the request object
3. Request payload
4. Headers / cookies
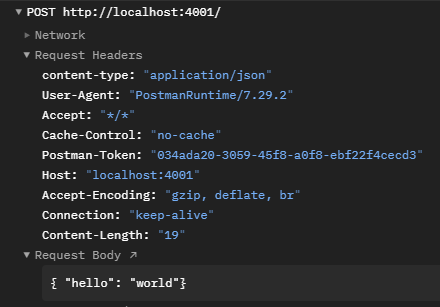
Intermission: Postman
Middleware
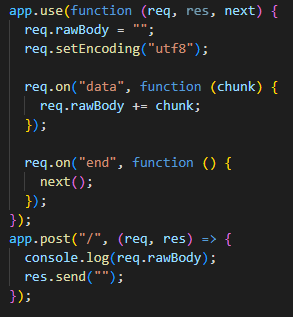
The chaining feature of Express allows us to "inject" functionality that will be triggered on each of the incoming requests.
This functionality is called "middleware" - we already used it when we created a static file server.
Depending on where in the code, and how is the middleware registered it can be executed both before and after the actual handler for the call.


Middleware
Workshop
Knowing how to use Node.js and Express, please create a simple app:
1. As a user, I want to call GET /users to receive a JSON object that lists some users
2. As a user, I want to call GET /assets/image.jpg to return some image
3. As a developer, I want to see a log of calls made to my server in console, with a timestamp and possibly the requested method + URL.
REST
"Representational state transfer" is a standard describing the model of working in a distributed environment, where the client application is able to synchronously communicate with a server which holds and processes all or part of application data and state.
REST: verbs
The REST standard defines a few verbs which are used when performing HTTP calls to indicate what type of operation the client is attempting:

Note: The OPTIONS request is rarely implemented in typical REST APIs. Your API does not need to implement all of those to be considered REST / RESTful
REST: responses
The API call must result in a correct response with a proper HTTP status code. The code belongs to one of the 4 groups:
- 2xx - success, the operation was completed
- 3xx - indicates that the call was intercepted and either needs redirection (client action needed) or cached data was returned
- 4xx - indicates an error when performing the operation; the error is on the client side, and the client should correct it before re-attempting the call
- 5xx - indicates an error when performing the operation; the error is on the server side, and the client can re-attempt the exact same call in hopes the issue is resolved
REST: response body
The API call can also optionally contain a response body, but this is not part of the REST specification.
Some APIs will implement a response JSON object with status field, e.g.: {"status": "ok"} but this should just serve as additional metadata on top of the HTTP status response.
Please note that some REST APIs might agree on using a HTTP 200 response for all calls and then implementing the status in the body. While not typical this happens - such implementation could be problematic for some auto-generated code.
REST: Uniform Resource Locator
The REST API should implement a way to identify a resource on which we want to perform the operation. This is implemented via the URL (Uniform Resource Locator) that describes the resource, its potential relationships and can control the way data is presented.
GET /users - returns a collection of users
GET /users/1 - returns a user identified by "1"
POST /users - creates a new user
PUT /users/1 - replaces the user identified by "1"
PATCH /users/1 - partially updates the user identified by "1"
DELETE /users/1 - deletes the user identified by "1"
REST: Uniform Resource Locator
We can further instrument the server by providing more information about the expected resource shape:
GET /users?order=createdAt - fetch the list of users, order by "createdAt" property
REST does not define the syntax of query string arguments, so all the following are valid:
GET /users?order[]=createdAt&order[]=name
GET /users?order=createdAt,name
GET /users?order=createdAt,-name
REST: Uniform Resource Locator
What we SHOULDN'T do however is to make those instructions part of the URL:
GET /users/createdAt/desc
This will make both serving and querying for the data very complex and is not the expected pattern.
REST: Sub-resources
If we want to operate on sub-resources which belong to a specific parent resource, we can either indicate this relationship in URL:
GET /users/1/tweets - returns a collection of tweets belonging to user "1"
DELETE /users/1/tweets/2 - deletes a tweet identified by "2" which belongs to use "1"
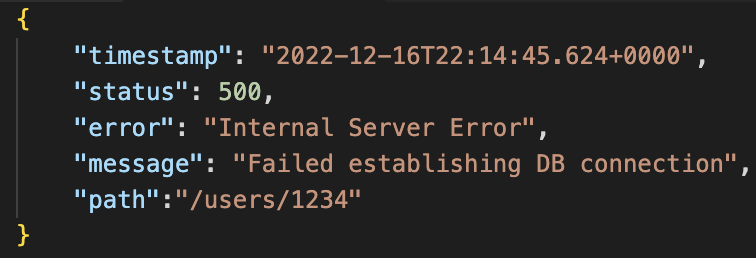
REST: Error handling
Other than using the HTTP status code to indicate error response, REST doesn't provide any requirements on how the details of the error should be communicated to the client. It's up to the API designer to decide on the payload.
REST: Authentication
If your API isn't meant to be publicly available, you should consider implementing an authentication layer. The two most common approaches to authentication are:
- Using a personal API key, generated for the user after signing up for the service. Such key is usally sent as a x-api-key header
- Using a authentication protocol like OAuth, where each request contains a JWT that is further verified agains the provider. Such token is usually sent as authorization: Bearer ... header
REST: Versioning
Our APIs will change over time. We will be introducing new features and sunsetting old ones. If we need to introduce a breaking change (e.g. removing some endpoint, removing some fields from the response, marking the payload field as mandatory but also changing the values of a returned enum!) we should publish a new version of our API.
In order to support this, API versions can be scoped in the URL:
GET /v1/users
GET /v2/users
REST: Versioning
Other approaches can include:
- deploying the API on a different domain/subdomain
- accepting the API version as a header during the API call
Richardson Maturity Model
Level 0 - only part of the specification is that we're using HTTP as transfer medium; all API calls are made towards single endpoint (e.g. POST /api) and the body fully describes our action. RPC pattern.
Level 1 - we introduce the resource identifiers. The calls are still mostly POST with a body describing the operation, but we have multiple URLs that help identify the resource(s) we want to work on
Level 2 - we introduce the HTTP verbs; this makes our API more readable and easier to work with, we can use things like API gateway to proxy / redirect API calls
Level 3 - Hypermedia Controls
HATEOAS
Hypermedia As the Engine of Application State

Workshop
Understanding how Node.js, Express and REST specification work together, please create a REST API for our Twitter clone supporting the following:
1. As a user, I want to be able to retrieve a list of all tweets, ordered by date, from newest to oldest
2. As a user, I want to be able to retrieve profile of a specified user
3. As a user, I want to be able to retrieve list of tweets of a specified user
4. As a user, I want to be able to create a new tweet
5. As a user, I want to be able to delete a tweet
Check https://gist.github.com/bartosz-szczecinski-wp/2f19e8de9e09eaffcac65b9b2c599974 for example data
Database
Database software allows us to persist the data that is processed by our application.
There are different types of databases, starting from key-value storage to a fully fledged relational database (RDBMS).
The three most popular database types we're going to run across in web application development will be:
- SQL (Structured Query Language) - e.g. MySQL, MariaDB, PostgreSQL, Oracle, SQLite
- NoSQL - e.g. MongoDB, DynamoDB
- key-value storage - e.g. Reddis
SQLite
For the purpose of this workshop, we're going to be working with SQLite, which is a implementation of a SQL database engine.
SQLite databases are self-contained and are stored as a single file on your file system. This allows us to use SQLite on multiple platforms - from dedicated instances, embeded devices or even in-memory with browser JavaScript
SQLite might not offer some of the features other SQL databases offer, and might not be as performant but due to its easy setup and fact that it can be embeded directly in your app it is one of the most popular SQL choice.
SQL: basic concepts
- Each SQL database can contain one or more tables.
- Tables are used to hold resources.
- Each resource can be desribed by one or more column.
- Columns can be defined as different type which improves the performance of data storage and retreival.
To help visualize the concept, let's consider an Excel document:
- Excle file can contain multiple sheets
- Tables are sheets
- Resources are rows
- Columns are columns
SQL: CRUD
Any database should provide a CRUD interface:
- CREATE - you should be able to create a resource
- READ - once created, we should be able to retreive it
- UPDATE - we should also be able to update
- DELETE - and delete it
SQL: Creating a table
Before we start storing our data in a SQL database, we need to define the "shape" of the data we want to save. Each record in a table will have multiple fields. Depending on the type of data we can represent it as one of the SQL types (subject to engine support):
- text - CHAR, VARCHAR, TEXT, BLOB, ENUM ...
- numeric - BIT, INT, BOOLEAN, DOUBLE, FLOAT ...
- date - DATE, DATETIME, TIMESTAMP ...
- unique - XML, PATH, POLYGON, GEO ...
SQL: Creating a table
Let's create a simple table. We're going to be working with SQLite, so create a new database with sqlite3 database.sqlite and then use the CREATE TABLE statement:
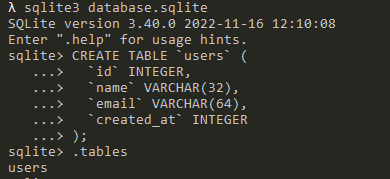
Note: tables usually use plurals in their names: users, groups etc.
SQL: Inserting data
Once our table is ready, we can start inserting some data into it with the INSERT INTO statement:

Our insert statement VALUES should match the order and count of the fields in the table. If we want to skip some of them, we need to explicitly name the ones we want to fill:
We can also create multiple records in one go:

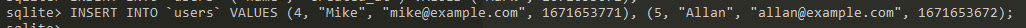
SQL: Reading data
Now that we've populated the table with some data, we can read it back:
Hint: if your UI looks different, enable the column display (command .mode column) and headers (.headers on).
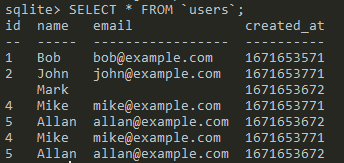
SQL: Reading data
While reading the data is perfectly fine, the real power of a DB lies in the ability to search and order the records.
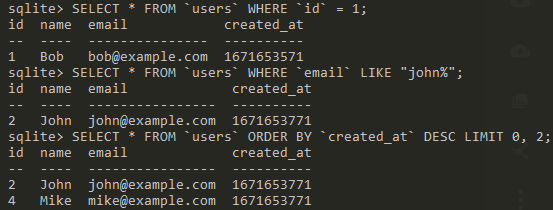
SQL: Updating data
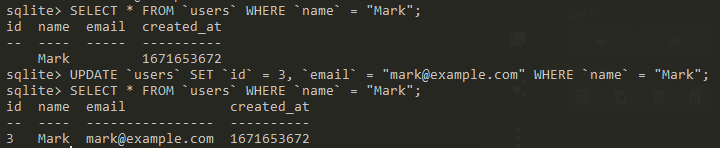
You might have noticed we missed adding an id and email to Mark; we can fix that with the UPDATE statement.
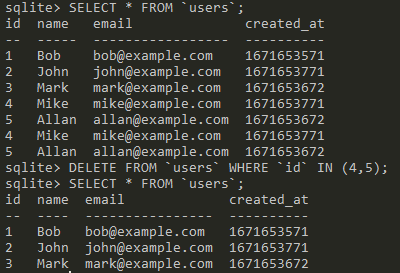
SQL: Deleting data
We can use the DELETE statement to remove some of the data:
Note: you should make sure you have a habbit to adding the WHERE statement when trying to update data ;)
SQL: relationship
We call a database a "relational database" because the dataset contained in different table can still relate to eachother.
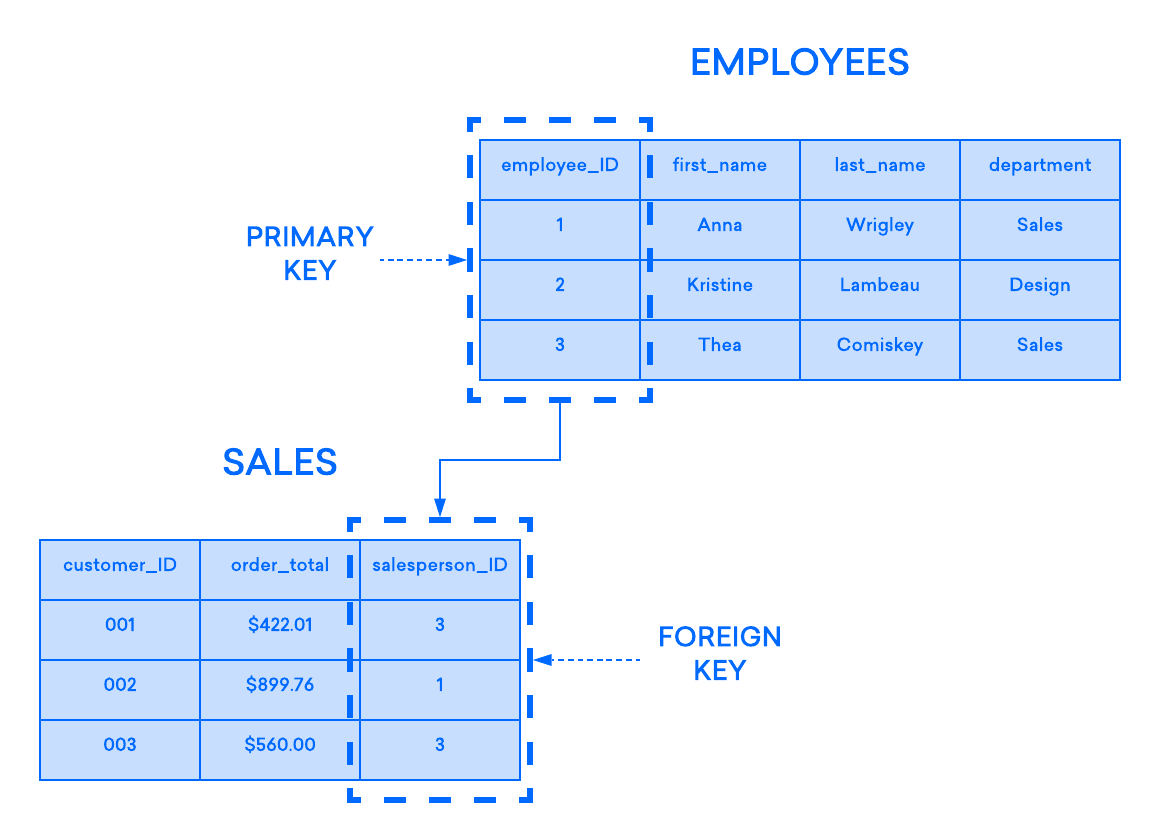
SQL: relationship
Let's create a tweet table and add some tweets for our users:
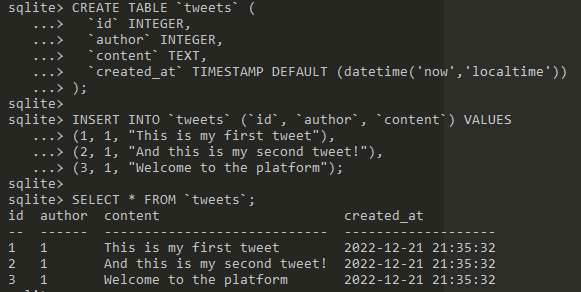
SQL: relationship
We can now query for a list of users and all of their tweets:
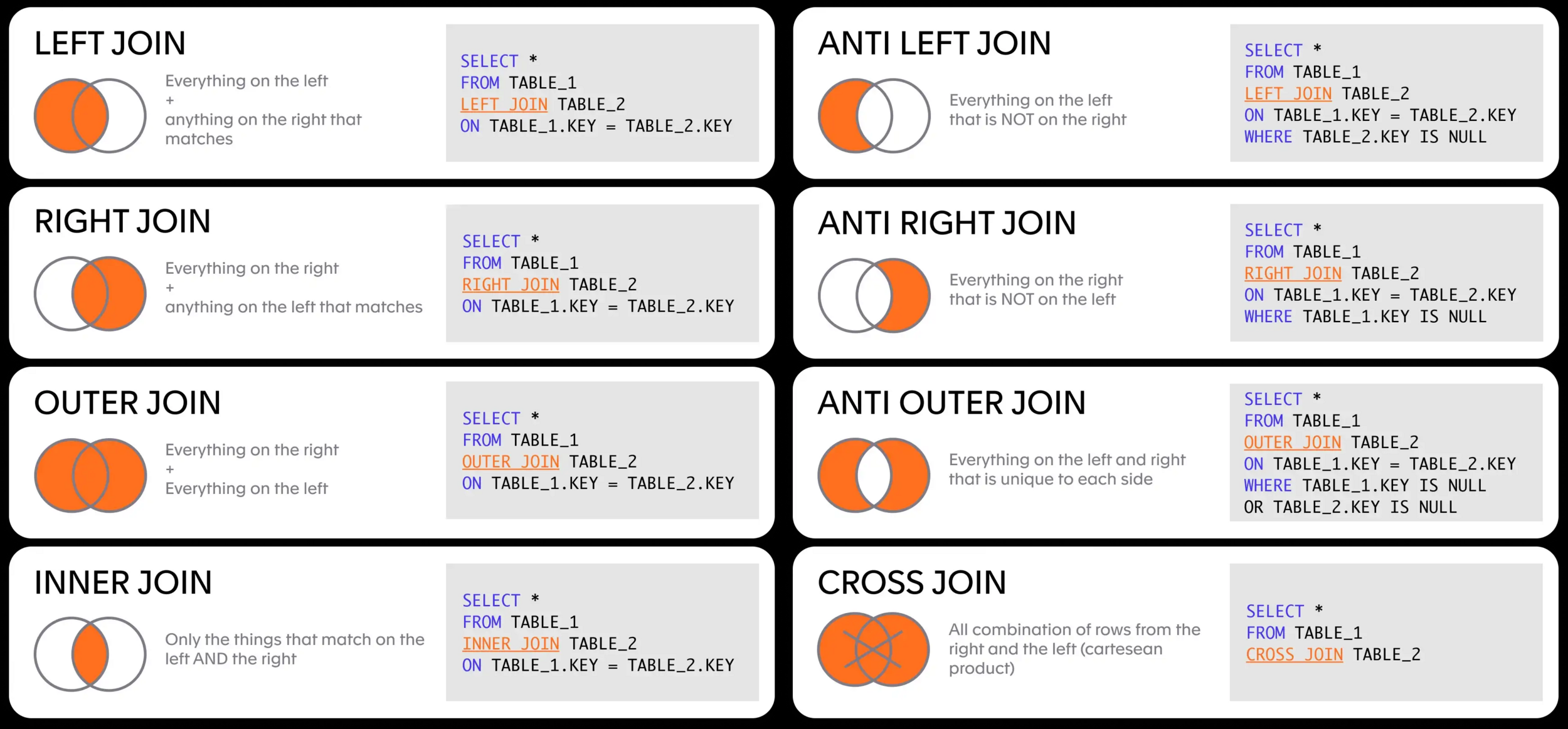
This query will return all entries from the users table and match data from tweet. We can remove the "empty" relationships with a different join:


SQL: JOINs
SQL: Types of relationships
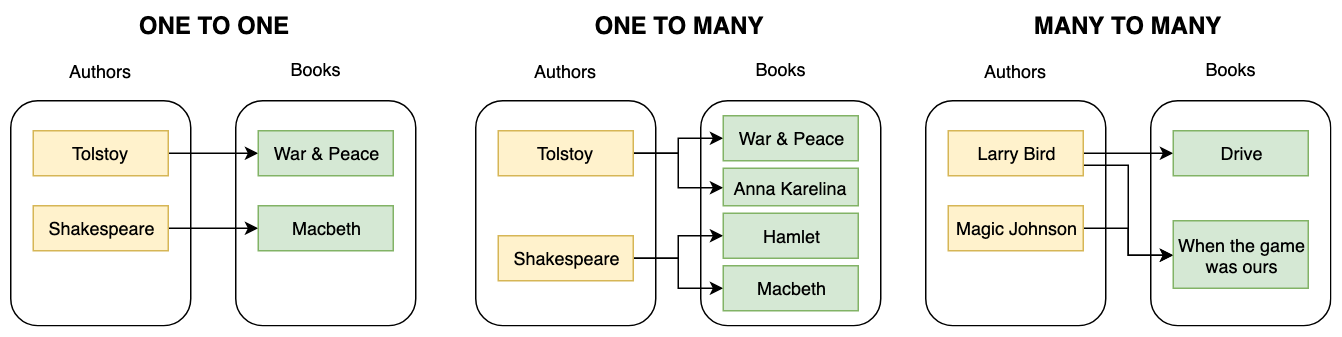
The many to many relationship would require an additional table, usually foollowing the pattern table1_table2, e.g. authors_books that would contain pairs of keys from both tables.
SQL: ACID transactions
Imagine a scenario where you need to get some data from the DB, perform some calculations, and update the database back with the results of the operation.
While such operations can take fractions of a second to happen, there are multiple problems that can happen in those miliseconds:
- the original data might have changed (multiple money withdrawals)
- the data might be corrupted
- the server might crash between operations
To address those issues, SQL introduces the concept of transactions
SQL: ACID transactions
A transaction is a set of operations that can be performed on a database in sequence, and can be either commited or rolled back.
- Atomicity - each step of the transaction is executed in turn and if one of the step fails, we should be able to rollback the transaction
- Consistency - changes to tables/data should happen in a predictable way; if an error happen it shouldn't impact other data
- Isolated - multiple transactions (e.g. by multiple users) shouldn't interact with eachother
- Durable - once executed, changes are commited to storage
SQL: ACID transactions
A transaction is STARTED and can be either COMMITED or ROLLEDBACK.
SQL:
START TRANSACTION;
COMMIT;
ROLLBACK;
SQLite:
BEGIN;
COMMIT;
ROLLBACK;
SQL: Keys - PRIMARY
Keys are fields indicated by the database designer that help to identify a resource. SQL supports keys created on one or more columns. The primary function of keys is to provide an unique identifier for a resource:
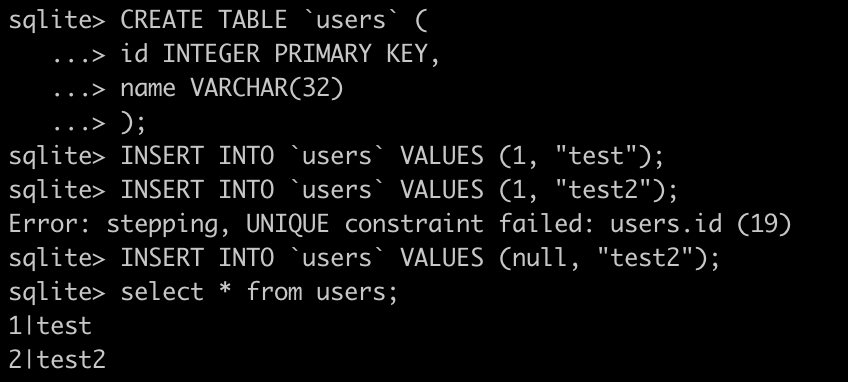
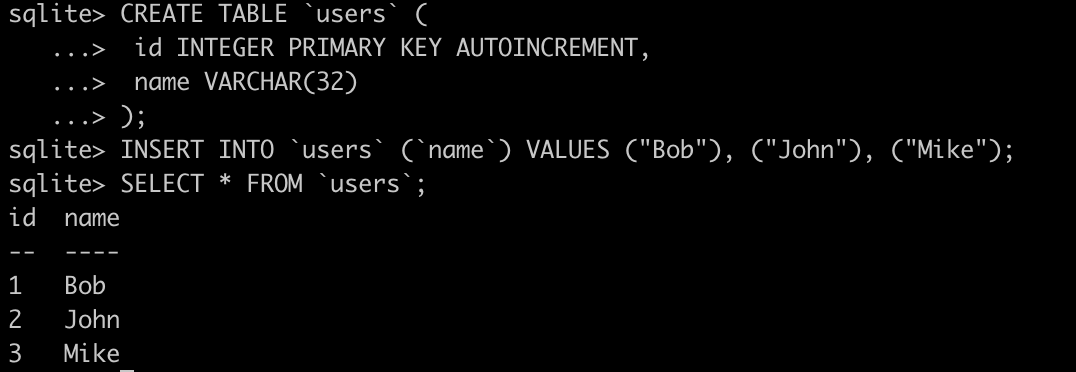
SQL: Keys - AUTOINCREMENT
Up to now, when creating new records we had to keep in mind what will be the id of it to have a unique way to identify the resource. SQL can automate this process for us:
SQL: On the topic of ID ...
While it might seem good idea to use an integer and have it automatically increment as we create new records, it is not the most optimal / secure solution.
- it adds overhead on either the client or server to have to read the id
- you need to either reserve space in advance or risk getting past the INT limitation at one point
- it enables enumeration attacks, might expose number of resources
As such it is often recommended to use uuid as resource identifier.
SQL: Keys - FOREIGN
Another type of key is a FOREIGN key, it is used to reinforce a relationship between two objects and helps ensure consistency of data in a database.
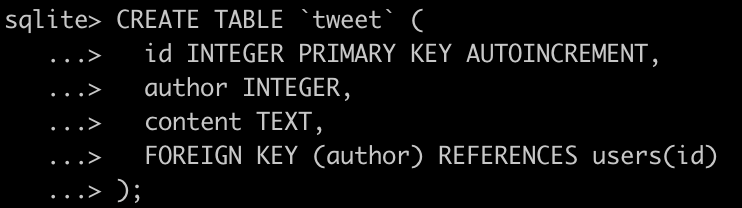


Note: SQLite doesn't enable FOREIGN KEYS by default. You need to execute a command PRAGMA FOREIGN_KEYS = on
SQL: Indexes
Although SQL engines are pretty good at searching through the stored data, sometimes we know that certain fields will be used for searches very often, and our databases will probably be read-heavy. To help improve the performance of searches we can use INDEXES.

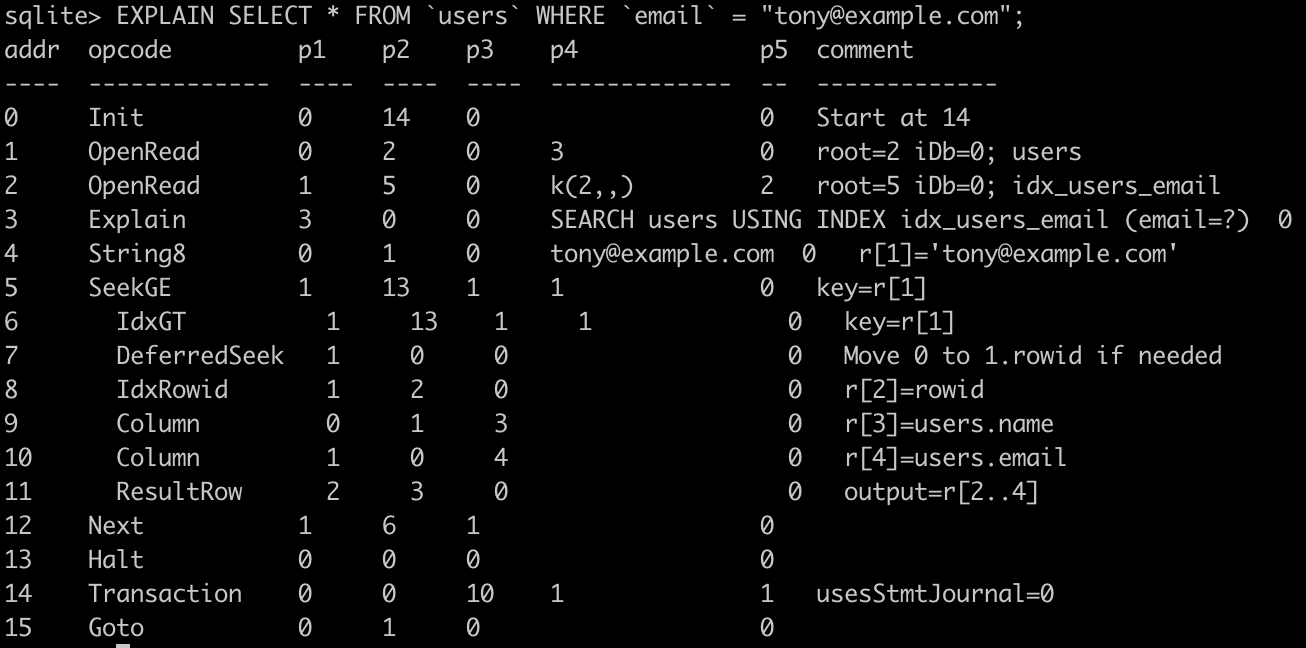
SQL: Migrations
As we develop our application and iterate on new releases our database schema and values (e.g. we have a dictionary of available options) will change. This poses a problem when we want to update a production application.
To solve this issue, SQL encourages the mechanism of migrations (also called "schema migration").
The process is based on developers creating "migration" files that illustrate the DB schema changes between iterations. Those steps will usually consist of CREATE/ALTER/DROP table commands.
SQL: Migrations
Once a migration is completed, it is saved in a file with sequential name (e.g. using timestamp), and then can be executed on the SQL server.
In order to keep track of which migrations are already executed by each host, they usually have a dedicated SQL table (e.g. migrations) that holds the name of executed SQL files. Before executing a new SQL migration, the table is consulted - if the migration was executed it is skipped.
Otherwise, the migration SQL is executed and a new entry is created in the table.
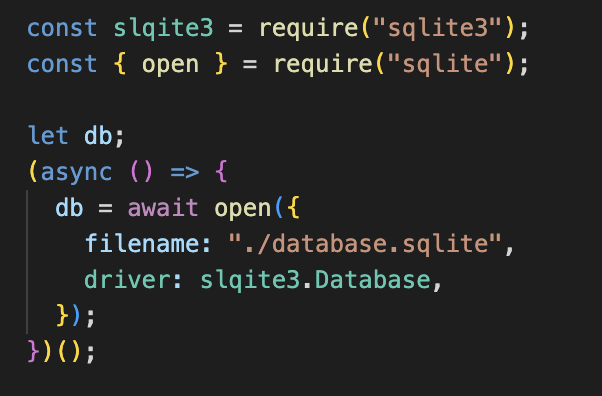
SQLite in NodeJS
In order to use SQLite in Node.js application we can use the sqlite3 library:
A SQLite database is by default not encrypted, so make sure not to accidentally expose it to the world (e.g. by using express.static)

SQLite in NodeJS
Once the connection to the database is established we can operate on it - read and write data.
The library provides a few helper methods, the most popular you'll be working with are:
- run(sql, [params], [callback])
- get(sql, [params], [callback])
- all(sql, [params], [callback]);
SQLite in NodeJS
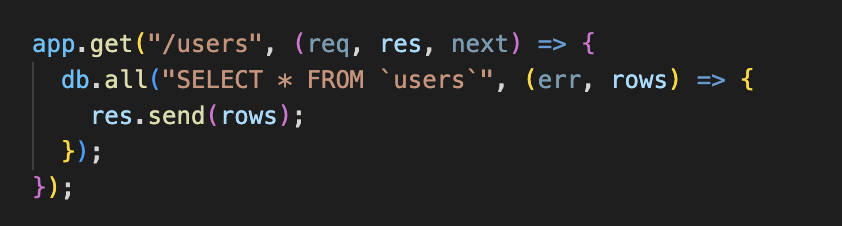
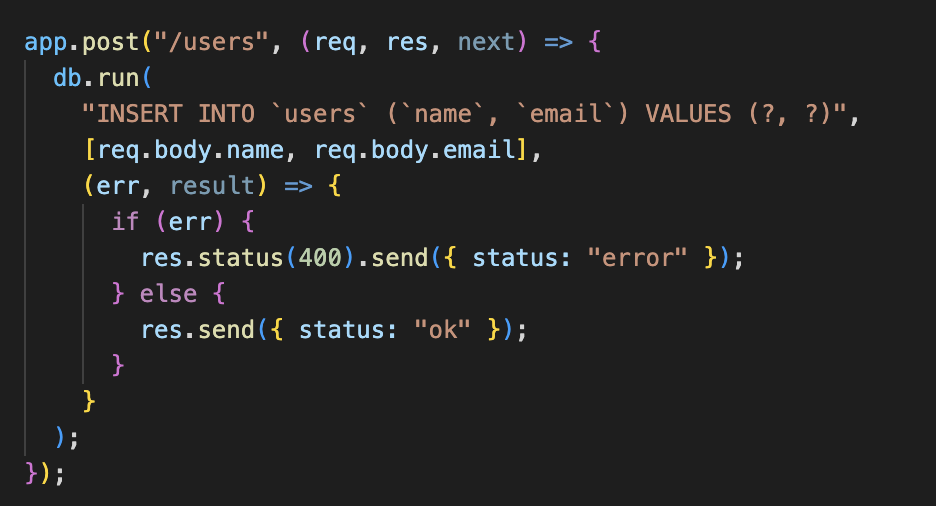
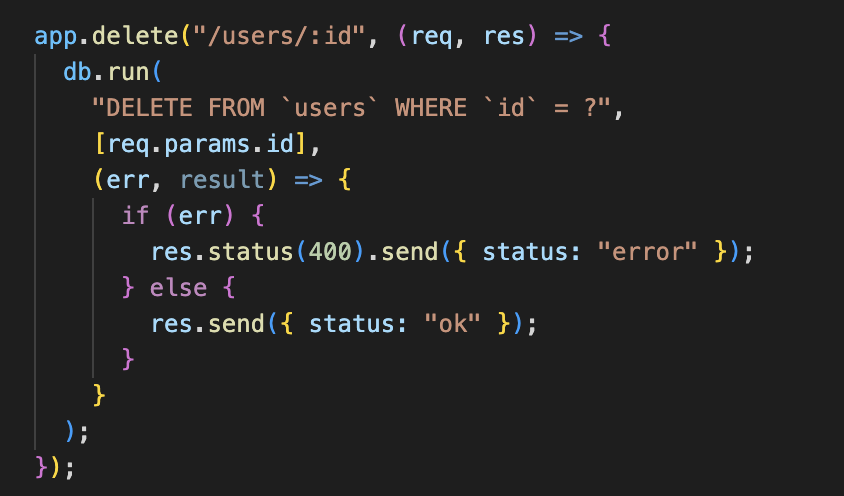
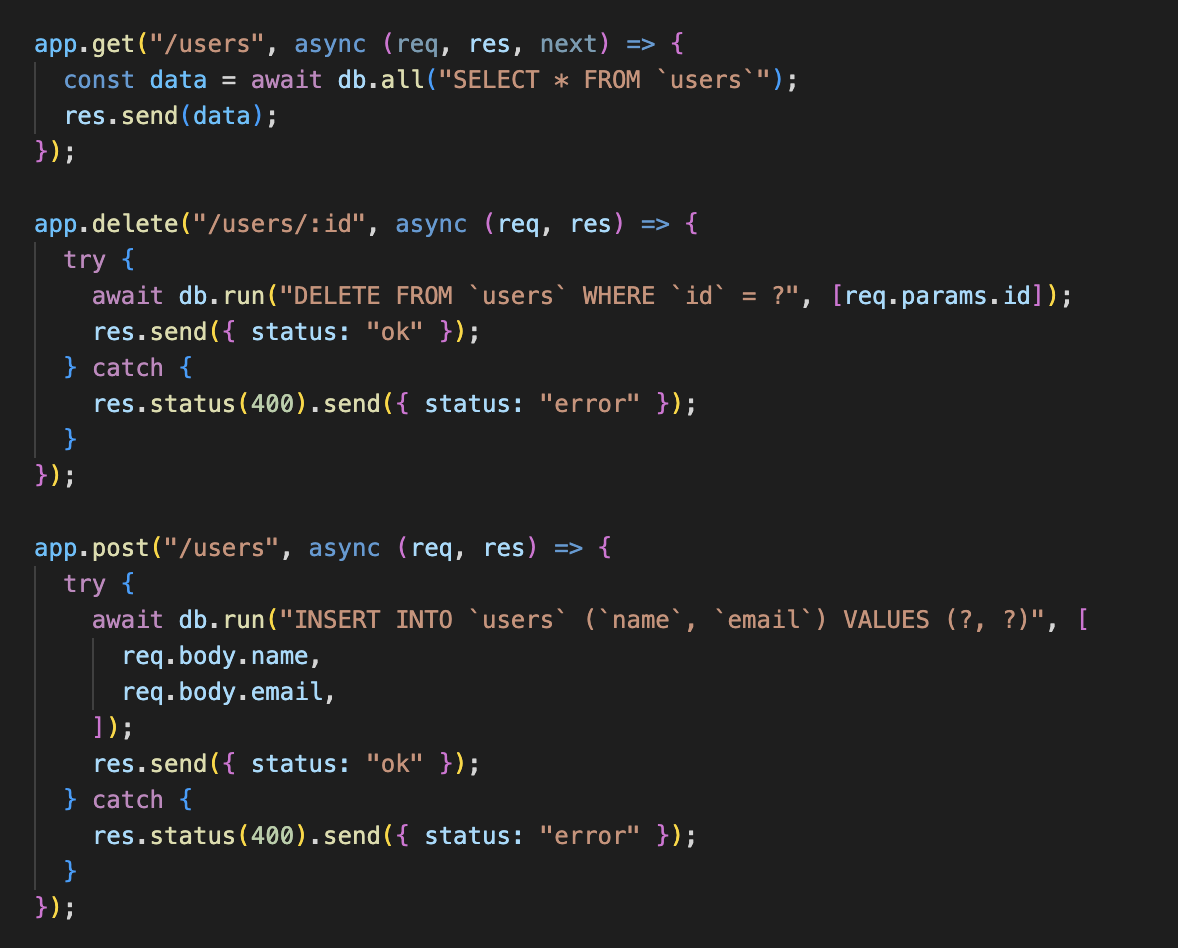
SQLite: Promises
Workshop
Understanding how Node.js, Express and SQLite work together, please create a REST API for our Twitter clone supporting the following:
- As a user, I want to be able to retrieve a list of all tweets, ordered by date, from newest to oldest
- As a user, I want to be able to retrieve profile of a specified user
- As a user, I want to be able to retrieve list of tweets of a specified user
- As a user, I want to be able to create a new tweet
- As a user, I want to be able to delete a tweet
- BONUS: As a developer, I want to prevent users from creating tweets on accounts other than their own (you can add a password field and require the user to pass it as API key)
- BONUS: As a user, I want to be able to make friends (add / remove users to friends list, see my friends list)
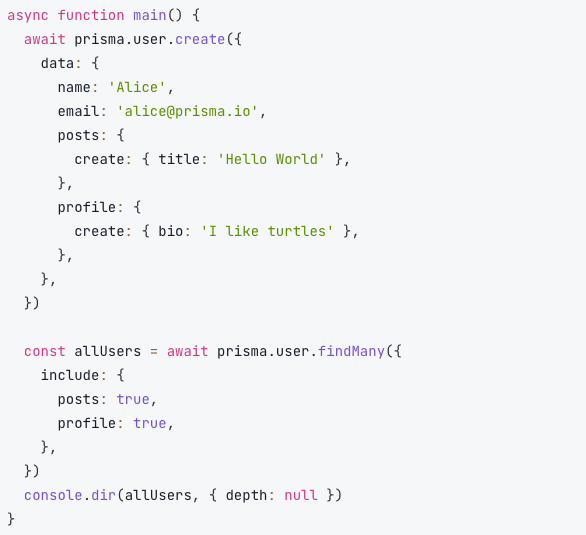
SQL: Abstractions
Since each SQL database can implement the syntax in slightly different way and you might need to at times change the SQL engine your app is using, and also to make it easier to work with DB without having to actually write queries, it is quite popular to see an abstraction added on top of the SQL client. Those abstractions often take form of ORM (Object Relationship Mapper).
The most popular you might run across in JS world are:
- Sequelize
- TypeORM
- Prisma

Bonus: idempotency
If you'll look at our API you can notice a "problem". If there is a connection issue or for some other reason the client ends up sending the same request twice two requests might end up reaching the server and the same query might be invoked multiple times.
To prevent this kind of issue, database clients should implement the mechanism of idempotency. The server should reject a CREATE operation which is determined to be an accident.
Note: while the UPDATE, DELETE and READ operations are idempotent by design. Executing the same UPDATE request twice shouldn't affect the state of object. You can still implement additional idempotency on top of it if needed.
Bonus: idempotency
The simplest approach to this is to require client to send a unique string (idempotency key) witch each request. If the request is transmitted twice and the idempotency key is the same for both request an error is reported.
The server should be able to:
- identify that the request is a duplicate (usually by checking the URI, payload and headers)
- checking that the idempotency is a duplicate
- reject or pass the request to next handler
Bonus: swagger + OpenAPI
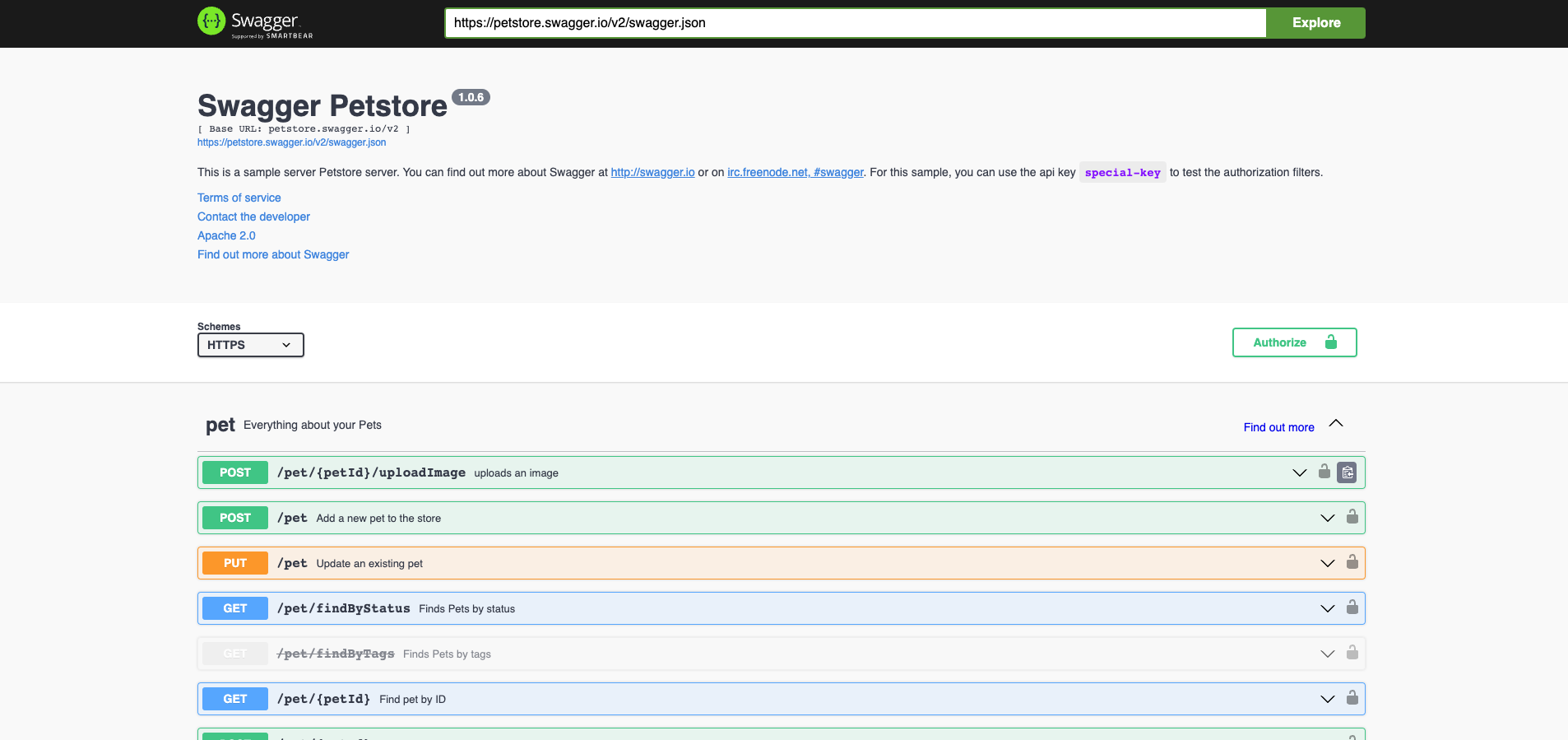
https://petstore.swagger.io/
https://github.com/OAI/OpenAPI-Specification/blob/main/examples/v3.0/petstore.yaml
Bonus: swagger + OpenAPI
https://github.com/jhannes/openapi-generator-typescript-fetch-api/blob/main/snapshotTests/snapshot/petstore/api.ts

Thank you :)
Node.js - module 1
By btmpl



