OmegaT for PISA 2025
Translating and reviewing
HTML/XML with and without XLIFF

What is the purpose
of these trainings?
- That you learn and become more capable and autonomous
- That you understand explanations from the tech team
- That you can better participate in technical decisions
- That you can make more informed requests
✓
✓
✓
✓
[quiz]
Contents
In this session we'll cover two basic tasks:
- Translation (includes reconciliation)
- Editing (e.g. revision or verification)
Therefore we'll see how OmegaT interacts with:
- Monolingual files like XML/HTML
- Untranslated XLIFF files for translation or editing tasks
- Translated XLIFF files for editing tasks
This presentation is meant mostly to provide the essential background information you need to understand about how OmegaT interacts with XLIFF files.
Let's start with a
translation task
Stating the obvious: in a translation task, the input is an untranslated file and the output is a translated file.
HTML
The original file is a questionnaire,
the format is a web page (HTML+CSS+JS)
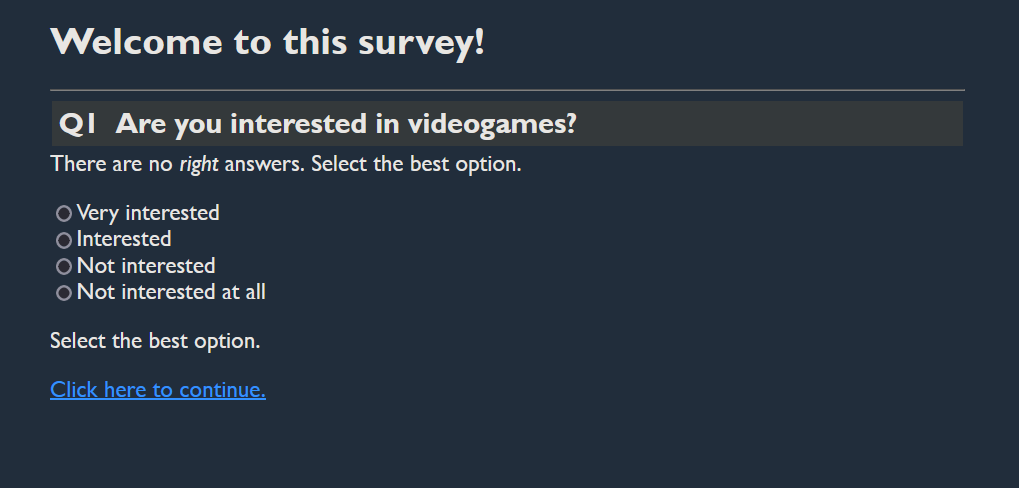
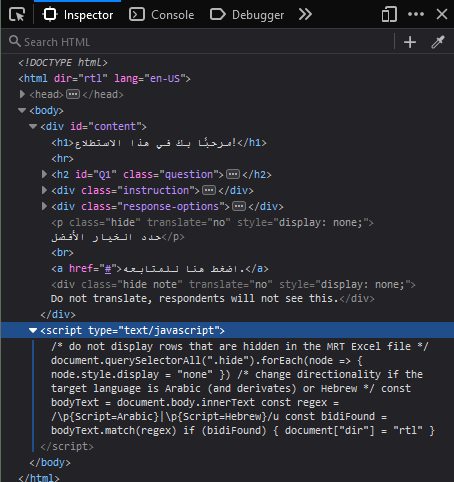
The source code of the original HTML file.
<!doctype html>
<html lang='en-US'>
<head>
<meta charset='UTF-8' />
<style>...
</style>
</head>
<body>
<div id="content">
<h1>Welcome to this survey!</h1><hr />
<h2 class="question" id="Q1">Are you interested in videogames?</h2>
<div class="instruction">There are no <em>right</em> answers. Please select one response.</div>
<ul class="response-options">
<li><input type="radio">Very interested</li>
<li><input type="radio">Interested</li>
<li><input type="radio">Not interested</li>
<li><input type="radio">Not interested at all</li>
</ul>
<p class='hide' translate='no'>Select the best option.</p>
<a href="#">Click here to continue.</a>
<div class='hide note' translate='no'>Do not translate, respondents will not see this.</div>
</div>
<script type='text/javascript'>...
</script>
</body>
</html>We want to translate (and therefore extract) only the (translatable) text.
The translatable text in
the original HTML file.
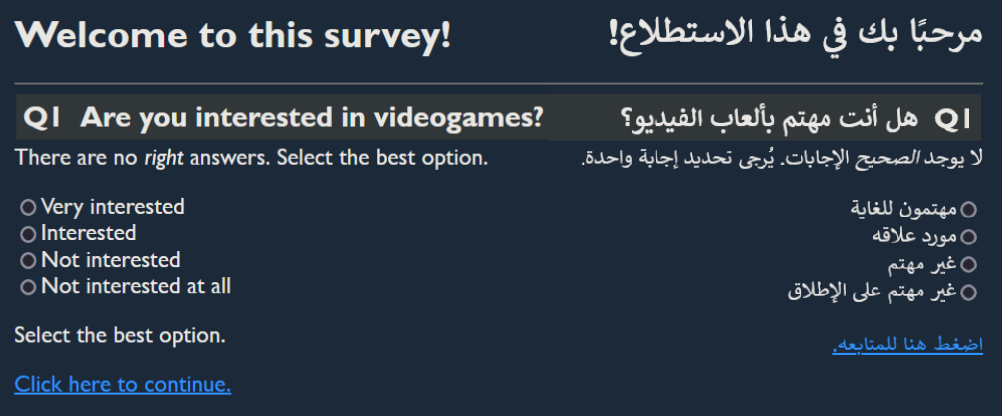
Welcome to this survey!
Are you interested in videogames?
There are no <em>right</em> answers. Please select one response.
Very interested
Interested
Not interested
Not interested at all
Click here to continue.
This is what it looks like in OmegaT
before translation
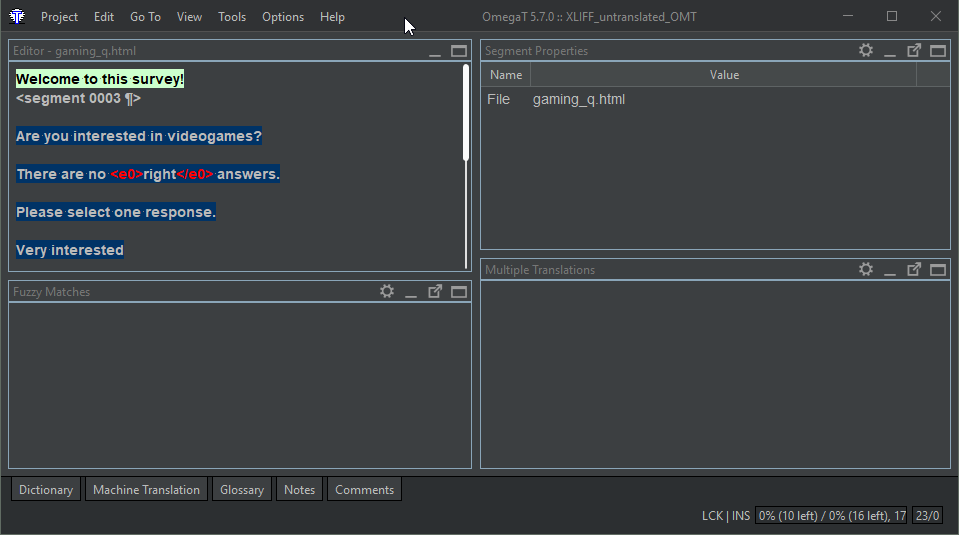
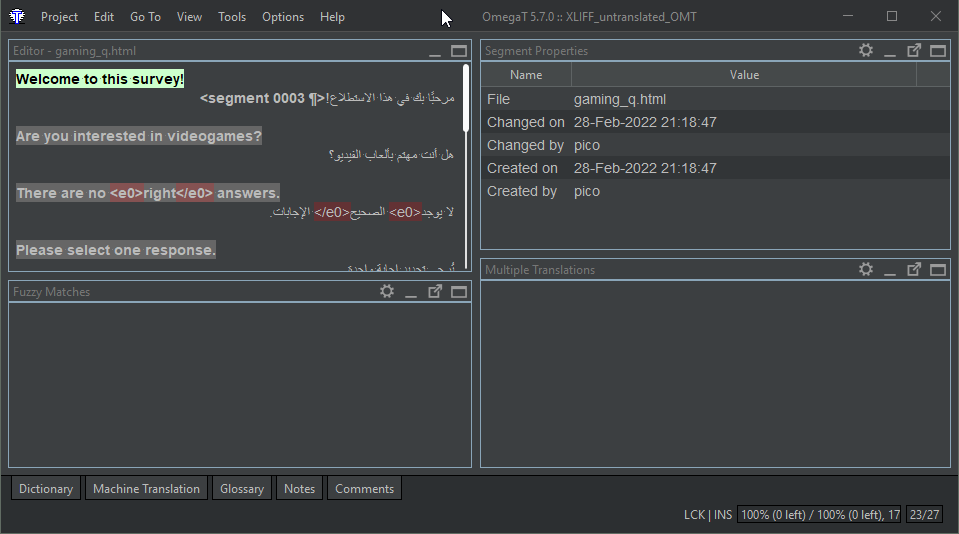
This is what it looks like in OmegaT
after translation
<!doctype html>
<html lang='en-US'>
<head>
<meta charset='UTF-8' />
<style>...
</style>
</head>
<body>
<div id="content">
<h1>مرحبًا بك في هذا الاستطلاع!</h1><hr />
<h2 class="question" id="Q1">هل أنت مهتم بألعاب الفيديو؟</h2>
<div class="instruction">لا يوجد<em> الصحيح</em> الإجابات. يُرجى تحديد إجابة واحدة.</div>
<ul class="response-options">
<li><input type="radio">مهتمون للغاية</li>
<li><input type="radio">مورد علاقه</li>
<li><input type="radio">غير مهتم</li>
<li><input type="radio">غير مهتم على الإطلاق</li>
</ul>
<p class='hide' translate='no'>حدد الخيار الأفضل</p>
<a href="#">اضغط هنا للمتابعه.</a>
<div class='hide note' translate='no'>Do not translate, respondents will not see this.</div>
</div>
<script type='text/javascript'>...
</script>
</body>
</html>And this is the target HTML file,
translated in Arabic.
And this is what the target file looks like in the browser.
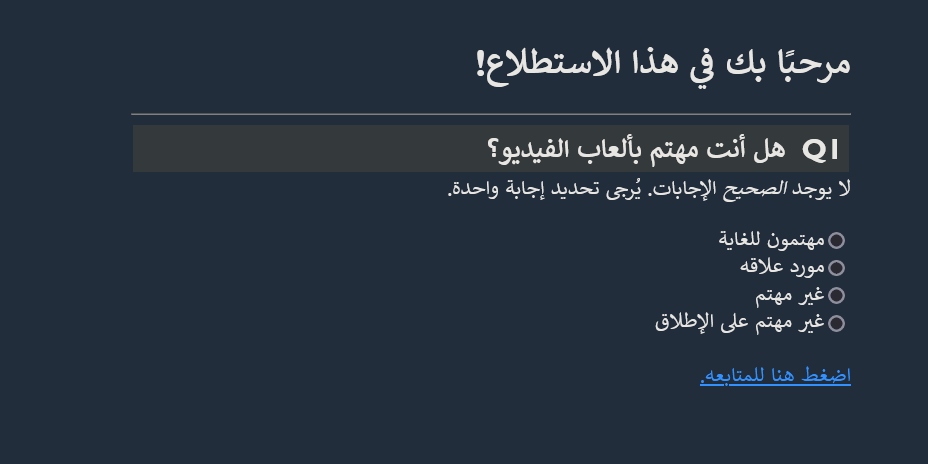
Source and target side by side:
XML
The original file is a questionnaire,
the format is XML (with external styles)

The original file is a questionnaire,
the format is HTML+CSS+JS
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="styles.css"?>
<bq>
<itemGroup visible="true" id="PA152" layout="">
<styles type="column" match="2">
<key name="size">22</key>
</styles>
<styles type="column" match="1">
<key name="size">78</key>
</styles>
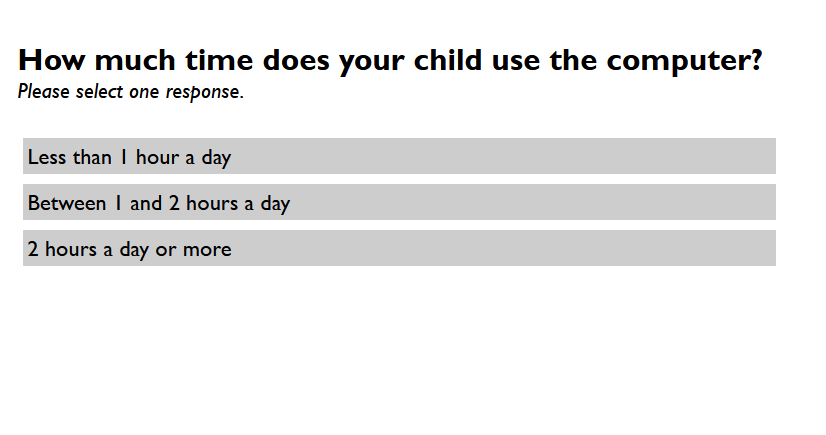
<subject>How much time does your child use the computer?</subject>
<instruction>Please select one response.</instruction>
<item id="item" layout="simpleMultipleChoiceRadioButton">
<responses>
<response>
<code>PA152Q01IA</code>
<label translate="no">We do not have a computer at home</label>
</response>
<response>
<code>PA152Q02IA</code>
<label translate="no">We have a computer at home, but my child does not use it</label>
</response>
<response>
<code>PA152Q03IA</code>
<label>Less than 1 hour a day</label>
</response>
<response>
<code>PA152Q04IA</code>
<label>Between 1 and 2 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="no">Between 2 and 3 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="yes">2 hours a day or more</label>
</response>
<response>
<code>PA152Q06IA</code>
<label translate="no">3 hours a day or more</label>
</response>
</responses>
</item>
<id value="180700">180700</id></itemGroup>
</bq>
The source code of the original XML file.
Notice how some parts are hidden and therefore not translatable.
The original file is a questionnaire,
the format is HTML+CSS+JS
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="styles.css"?>
<bq>
<itemGroup visible="true" id="PA152" layout="">
<styles type="column" match="2">
<key name="size">22</key>
</styles>
<styles type="column" match="1">
<key name="size">78</key>
</styles>
<subject>How much time does your child use the computer?</subject>
<instruction>Please select one response.</instruction>
<item id="item" layout="simpleMultipleChoiceRadioButton">
<responses>
<response>
<code>PA152Q01IA</code>
<label translate="no">We do not have a computer at home</label>
</response>
<response>
<code>PA152Q02IA</code>
<label translate="no">We have a computer at home, but my child does not use it</label>
</response>
<response>
<code>PA152Q03IA</code>
<label>Less than 1 hour a day</label>
</response>
<response>
<code>PA152Q04IA</code>
<label>Between 1 and 2 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="no">Between 2 and 3 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="yes">2 hours a day or more</label>
</response>
<response>
<code>PA152Q06IA</code>
<label translate="no">3 hours a day or more</label>
</response>
</responses>
</item>
<id value="180700">180700</id></itemGroup>
</bq>
The source code of the original XML file.
Only these parts will be extracted for translation.
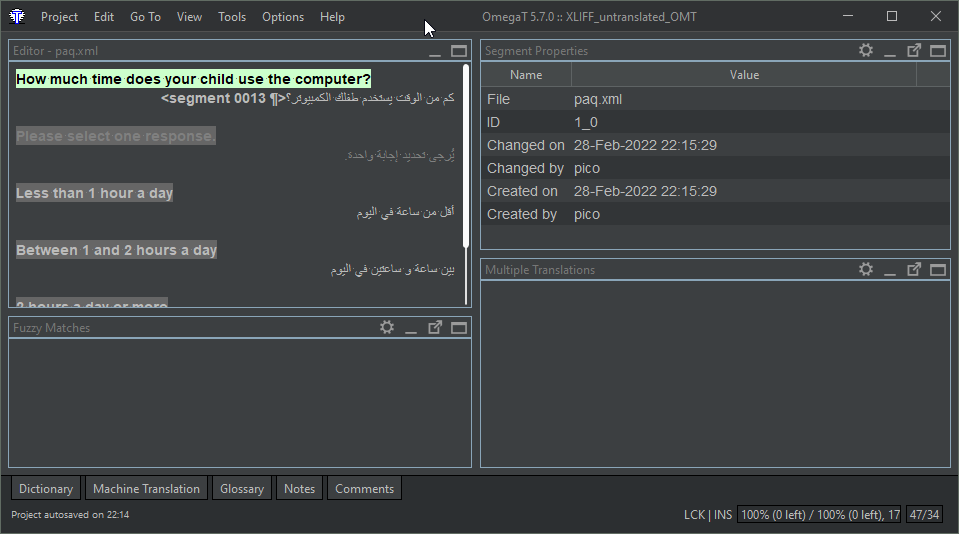
This is what it looks like in OmegaT
before translation
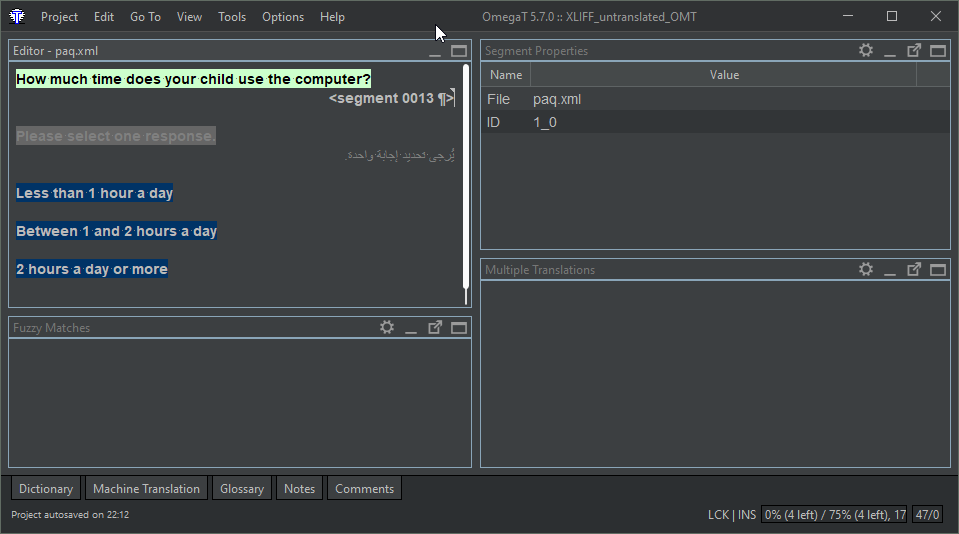
auto-propagation
The parts out of scope for translation are not extracted.
of the default translation
(repeated segment, previously translated)
registered in the working TM
This is what it looks like in OmegaT
after translation
The original file is a questionnaire,
the format is HTML+CSS+JS
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="styles.css"?><bq>
<itemGroup id="PA152" layout="" visible="true">
<styles match="2" type="column">
<key name="size">22</key>
</styles>
<styles match="1" type="column">
<key name="size">78</key>
</styles>
<subject>كم من الوقت يستخدم طفلك الكمبيوتر؟</subject>
<instruction>يُرجى تحديد إجابة واحدة.</instruction>
<item id="item" layout="simpleMultipleChoiceRadioButton">
<responses>
<response>
<code>PA152Q01IA</code>
<label translate="no">We do not have a computer at home</label>
</response>
<response>
<code>PA152Q02IA</code>
<label translate="no">We have a computer at home, but my child does not use it</label>
</response>
<response>
<code>PA152Q03IA</code>
<label>أقل من ساعة في اليوم</label>
</response>
<response>
<code>PA152Q04IA</code>
<label>بين ساعة و ساعتين في اليوم</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="no">Between 2 and 3 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="yes">ساعتان في اليوم أو أكثر</label>
</response>
<response>
<code>PA152Q06IA</code>
<label translate="no">3 hours a day or more</label>
</response>
</responses>
</item>
<id value="180700">180700</id></itemGroup>
</bq>The source code of the translated XML file.
Only translatable parts are merged.
And this is what the target file looks like in the browser.

styles, code, id {
display: none;
}
subject {
font-size: 1.4em;
font-weight: bold;
}
instruction {
font-style: italic;
display: block;
margin: 0 0 30px 0;
}
response {
display: grid;
}
label[translate="no"] {
display: none;
}
label {
margin: 5px;
background-color: #cdcdcd;
padding: 5px;
max-width: 100%;
}
However, text direction is still left-to-right.
And this is what the target file looks like in the browser with correct directionality.
* {
direction: rtl;
}
styles, code, id {
display: none;
}
subject {
font-size: 1.4em;
font-weight: bold;
}
instruction {
font-style: italic;
display: block;
margin: 0 0 30px 0;
}
response {
display: grid;
}
label[translate="no"] {
display: none;
}
label {
margin: 5px;
background-color: #cdcdcd;
padding: 5px;
max-width: 100%;
}
Looks good now.

XLIFF
Let's see now what the process looks like if we convert those two files to XLIFF 1.2 outside of OmegaT.
So far, we have imported and translated the original files directly in OmegaT, using the Okapi HTML and XML filters.
The L10n engineer's job is to identify and extract the parts of the file that must be translated.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="styles.css"?>
<bq>
<itemGroup visible="true" id="PA152" layout="">
<styles type="column" match="2">
<key name="size">22</key>
</styles>
<styles type="column" match="1">
<key name="size">78</key>
</styles>
<subject>How much time does your child use the computer?</subject>
<instruction>Please select one response.</instruction>
<item id="item" layout="simpleMultipleChoiceRadioButton">
<responses>
<response>
<code>PA152Q01IA</code>
<label translate="no">We do not have a computer at home</label>
</response>
<response>
<code>PA152Q02IA</code>
<label translate="no">We have a computer at home, but my child does not use it</label>
</response>
<response>
<code>PA152Q03IA</code>
<label>Less than 1 hour a day</label>
</response>
<response>
<code>PA152Q04IA</code>
<label>Between 1 and 2 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label translate="no">Between 2 and 3 hours a day</label>
</response>
<response>
<code>PA152Q05IAa</code>
<label>2 hours a day or more</label>
</response>
<response>
<code>PA152Q06IA</code>
<label translate="no">3 hours a day or more</label>
</response>
</responses>
</item>
<id value="180700">180700</id></itemGroup>
</bq>
The prepping routine (1) identifies the nodes that contain translatable text,
<subject>How much time does your child use the computer?</subject>
<instruction>Please select one response.</instruction>
<label>Less than 1 hour a day</label>
<label>Between 1 and 2 hours a day</label>
<label>2 hours a day or more</label>... (2) extracts the translatable text (without the nodes that contain it),
How much time does your child use the computer?
Please select one response.
Less than 1 hour a day
Between 1 and 2 hours a day
2 hours a day or moreHow much time does your child use the computer?
Less than 1 hour a day
Please select one response.
2 hours a day or more
Between 1 and 2 hours a day
How much time does your child use the computer?
Less than 1 hour a day
Please select one response.
2 hours a day or more
Between 1 and 2 hours a day
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="paq.xml" source-language="en" target-language="ar" datatype="xml" xml:spacing="preserve">
<body>
<trans-unit id="1">
<source xml:lang="en">How much time does your child use the computer?</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar" />
</trans-unit>
</body>
</file>
</xliff>
... and (3) uses the translatable text as the source text in the XLIFF file.
In an untranslated XLIFF file, the <target> nodes have no text content (they are empty).
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="paq.xml" source-language="en" target-language="ar" datatype="xml" xml:spacing="preserve">
<body>
<trans-unit id="1">
<source xml:lang="en">How much time does your child use the computer?</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar" />
</trans-unit>
</body>
</file>
</xliff>
Therefore, the Okapi XLIFF filter in OmegaT only extracts the source text.
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="paq.xml" source-language="en" target-language="ar" datatype="xml" xml:spacing="preserve">
<body>
<trans-unit id="1">
<source xml:lang="en">How much time does your child use the computer?</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar" />
</trans-unit>
</body>
</file>
</xliff>
Two extraction points

original file
XLIFF file



OmegaT editor
Preparing the original file as XLIFF
Loading the XLIFF file in OmegaT
the L10n tool extracts the translatable text from the original file
This is what the XLIFF file looks like in OmegaT before translating it
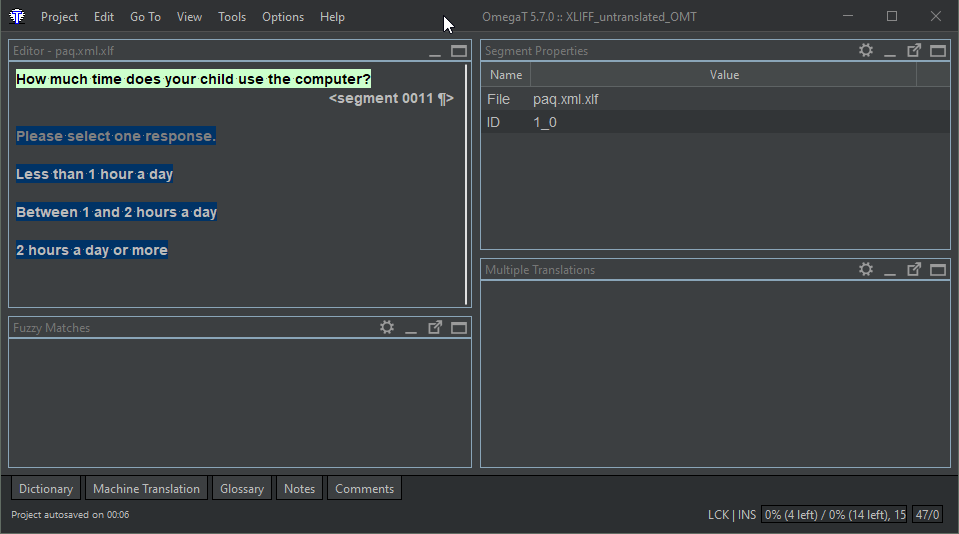
As you may notice, it's not too different from the extracted text from the XML file.
This is what the XLIFF file looks like in OmegaT after translating it
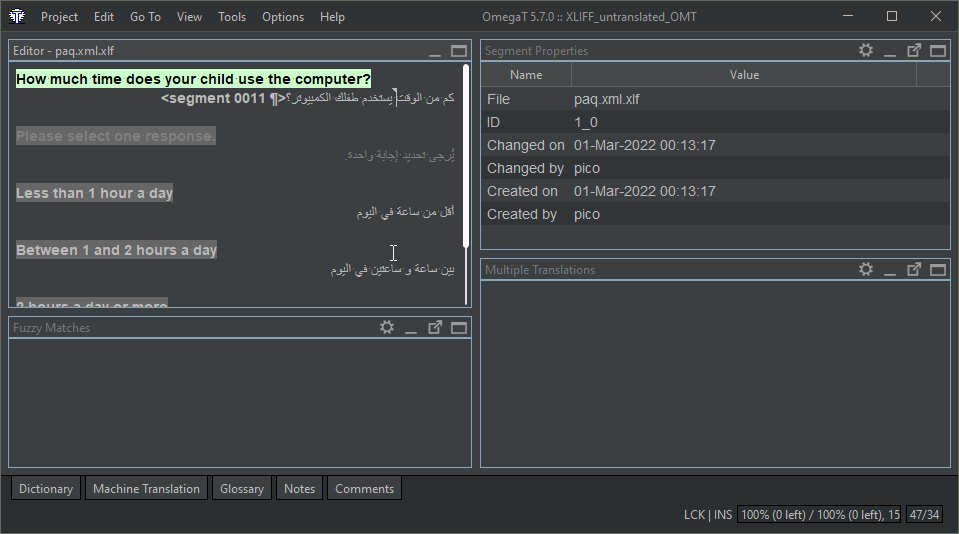
The Okapi XLIFF filter merges the target text in the target XLIFF file.
<?xml version="1.0" encoding="UTF-8"?>
<xliff xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" version="1.2" its:version="2.0">
<file original="paq.xml" source-language="en" target-language="ar" datatype="xml" xml:spacing="preserve">
<body>
<trans-unit id="1">
<source xml:lang="en">How much time does your child use the computer?</source>
<target xml:lang="ar">كم من الوقت يستخدم طفلك الكمبيوتر؟</target>
</trans-unit>
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar">أقل من ساعة في اليوم</target>
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar">بين ساعة و ساعتين في اليوم</target>
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar">ساعتان في اليوم أو أكثر</target>
</trans-unit>
</body>
</file>
</xliff>As you can see, the outcome of the translation task is a translated/bilingual XLIFF file
Let's now look at
an editing task
Stating the obvious: in an editing task, both the input and the output are a translated file.
There are two potential approaches for file flow in the OmegaT project for editing tasks.
translation
editing

source files
source files
reviewed target files
target files to review
=

The target files (output) of the translation project are the source files (input) of the editing project.
There is only one project for both tasks, files are imported at the beginning of the workflow and exported at the end of the workflow.
reviewed target files
approved
(same project)
(new project)
In a translated XLIFF file, the <target> nodes have text content (they are populated).
<?xml version="1.0" encoding="UTF-8"?>
<xliff xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" version="1.2" its:version="2.0">
<file original="paq.xml" source-language="en" target-language="ar" datatype="xml" xml:spacing="preserve">
<body>
<trans-unit id="1">
<source xml:lang="en">How much time does your child use the computer?</source>
<target xml:lang="ar">كم من الوقت يستخدم طفلك الكمبيوتر؟</target>
</trans-unit>
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar">أقل من ساعة في اليوم</target>
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar">بين ساعة و ساعتين في اليوم</target>
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar">ساعتان في اليوم أو أكثر</target>
</trans-unit>
</body>
</file>
</xliff>To edit the translated XLIFF file, the Okapi XLIFF filter can extract both the source text and the target text.
<?xml version="1.0" encoding="UTF-8"?>
<xliff xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" version="1.2" its:version="2.0">
<file original="paq.xml" source-language="en" target-language="ar" datatype="xml" xml:spacing="preserve">
<body>
<trans-unit id="1">
<source xml:lang="en">How much time does your child use the computer?</source>
<target xml:lang="ar">كم من الوقت يستخدم طفلك الكمبيوتر؟</target>
</trans-unit>
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar">أقل من ساعة في اليوم</target>
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar">بين ساعة و ساعتين في اليوم</target>
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar">ساعتان في اليوم أو أكثر</target>
</trans-unit>
</body>
</file>
</xliff>Transferring legacy translations using translation memories
Either a TMX file or a bilingual XLIFF file can be used as a TM (translation memory) in OmegaT.
Cases:
- Translation of a new version of materials that is similar to a previous version
- Trend transfer from a previous cycle to the current cycle
- Translation of content that refers to other materials that have already been translated
-
An adaptation task, where a language version (fr-CA) is based on (and "borrows") another version (fr-FR).
- Any task where consistency is required with other existing translations
Simple matches are based on:
- Similarity of the source text
In-context exact matches are based on:
- 100% source text
- Segment ID
- Filename (optional)
OmegaT displays matches found in TMs and can use 100% matches to auto-populate segments
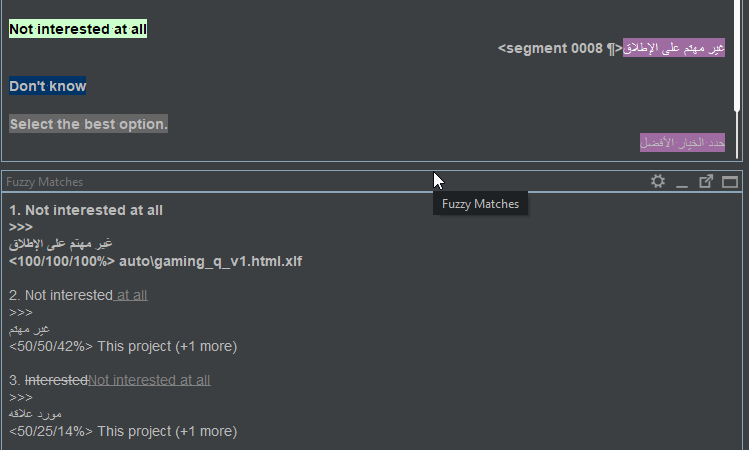
There is a 100% match
OmegaT displays matches found in TMs and can use 100% matches to auto-populate segments
The segment gets auto-populated.
XLIFF 1.2 requirements and caveats
XLIFF files must meet certain
requirements to be used in OmegaT.
XLIFF files must comply with the XLIFF 1.2 specification and validate
- XLIFF Validation (except for ZZ region codes)
- DTD: xliff.dtd
- Schema: xliff-core-1.2-strict.xsd
- Schema: xliff-core-1.2-transitional.xsd
All <trans-unit> nodes in the XLIFF files must have unique IDs
<trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar">أقل من ساعة في اليوم</target>
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar">بين ساعة و ساعتين في اليوم</target>
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar">ساعتان في اليوم أو أكثر</target>
</trans-unit><trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit>
<trans-unit id="3">
<source xml:lang="en">Less than 1 hour a day</source>
<target xml:lang="ar">أقل من ساعة في اليوم</target>
</trans-unit>
<trans-unit id="4">
<source xml:lang="en">Between 1 and 2 hours a day</source>
<target xml:lang="ar">بين ساعة و ساعتين في اليوم</target>
</trans-unit>
<trans-unit id="5">
<source xml:lang="en">2 hours a day or more</source>
<target xml:lang="ar">ساعتان في اليوم أو أكثر</target>
</trans-unit><source> nodes in the XLIFF files should not have leading or trailing space
<trans-unit id="2">
<source xml:lang="en"> Please select one response. </source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit><trans-unit id="2">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit><file> nodes should instruct OmegaT to preserve whitespace.
<file datatype="plaintext" xml:space="preserve" original="stimulus1.html" source-language="en-ZZ" target-language="ar-PS">
Translatable text must be segmented
<trans-unit id="tu3">
<source xml:lang="en">There are no <g id="1">right</g> answers. Please select one response.</source>
<target xml:lang="ar" />
</trans-unit><trans-unit id="tu3_0">
<source xml:lang="en">There are no <g id="1">right</g> answers.</source>
<target xml:lang="ar" />
</trans-unit>
<trans-unit id="tu3_1">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar" />
</trans-unit>Segmentation rules follow the SRX standard, which provides a common way to segment text for translation.
Language codes must be compliant with the BCP-47 standard
mne-MNE
ara-JOR
zhs-HKGcnr-ME
ar-JO
zh-Hans-HKTranslated XLIFF files that are imported into an OmegaT project for an editing task must be "approved"
<trans-unit id="1_1" approved="yes">
<source xml:lang="en">Please select one response.</source>
<target xml:lang="ar">يُرجى تحديد إجابة واحدة.</target>
</trans-unit>
That's to avoid having the current translation in the file being accidentally overwritten by another translation.
PROS
- No untranslatable content needs to be included in the file
- Unique segment ID's (enough context for alternative translations)
- No need to create TMs (translated XLIFF files can be used instead)
CONS
- No local preview
- More complex roundtrip
- Segmentation must be embedded in the file (rather than applied in OmegaT)
XLIFF
This presentation was meant mostly to provide the essential background information you need to understand about how OmegaT interacts with XLIFF files.
However, there might be other more advanced options that need to be considered when preparing a project, so please check with the tech team if you have doubts or questions.
OmegaT for PISA25 engineers -- 2022
By cApStAn LQC
OmegaT for PISA25 engineers -- 2022
Translating and reviewing HTML/XML with and without XLIFF



