OmegaT for techies
Hello world

XLIFF
In an untranslated XLIFF file, the <target> nodes have no text content (they are empty).
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="index.html" source-language="en-US" target-language="es-ES" datatype="x-text/html">
<body>
<group id="1" restype="div">
<trans-unit id="1_1">
<source xml:lang="en-ZZ">Hello world!</source>
<target xml:lang="es-ES" state="needs-translation" />
<note>Translate "world" as in "people", not as in "planet".</note>
</trans-unit>
<trans-unit id="1_2">
<source xml:lang="en-ZZ">How are you?</source>
<target xml:lang="es-ES" state="needs-translation" />
</trans-unit>
</group>
</body>
</file>
</xliff>Therefore, the Okapi XLIFF filter only extracts the source text.
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="index.html" source-language="en-US" target-language="es-ES" datatype="x-text/html">
<body>
<group id="1" restype="div">
<trans-unit id="1_1">
<source xml:lang="en-ZZ">Hello world!</source>
<target xml:lang="es-ES" state="needs-translation" />
<note>Translate "world" as in "people", not as in "planet".</note>
</trans-unit>
<trans-unit id="1_2">
<source xml:lang="en-ZZ">How are you?</source>
<target xml:lang="es-ES" state="needs-translation" />
</trans-unit>
</group>
</body>
</file>
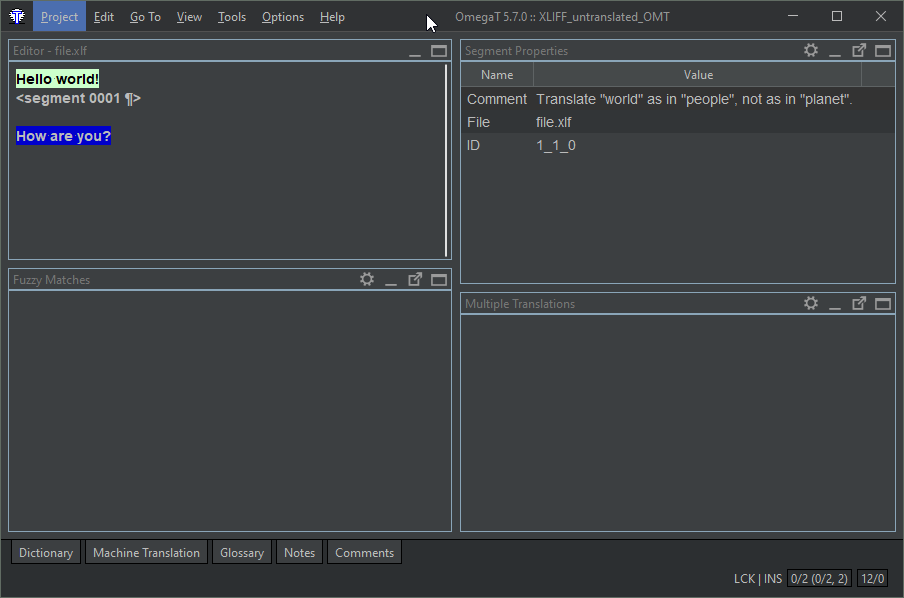
</xliff>This is what the file looks like in OmegaT before translating it
This is what the file looks like in OmegaT after translating it
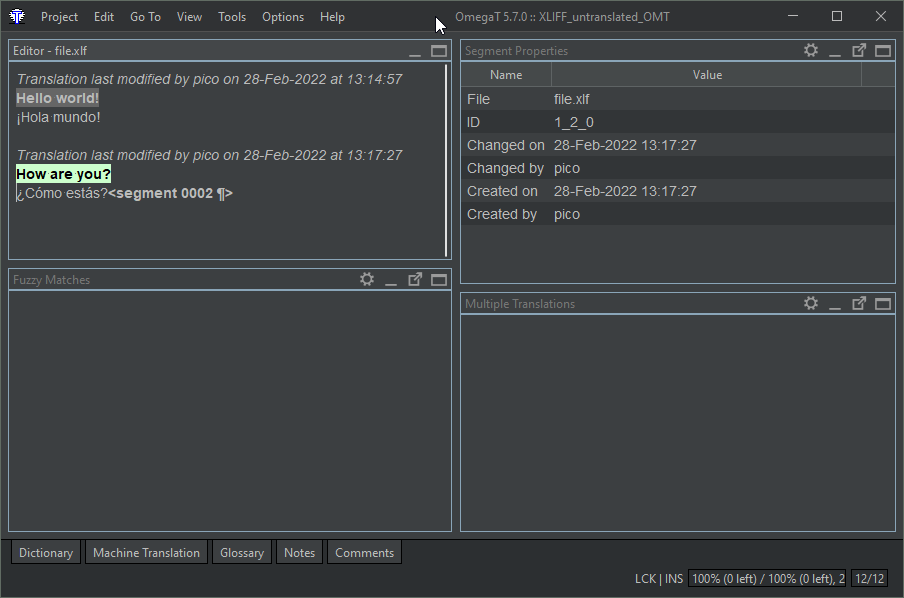
The Okapi XLIFF filter merges the target text in the target XLIFF file.
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="index.html" source-language="en-US" target-language="es-ES" datatype="x-text/html">
<body>
<group id="1" restype="div">
<trans-unit id="1_1">
<source xml:lang="en-ZZ">Hello world!</source>
<target xml:lang="es-ES" state="needs-translation" />
<note>Translate "world" as in "people", not as in "planet".</note>
</trans-unit>
<trans-unit id="1_2">
<source xml:lang="en-ZZ">How are you?</source>
<target xml:lang="es-ES" state="needs-translation" />
</trans-unit>
</group>
</body>
</file>
</xliff>Therefore, the Okapi XLIFF filter can extract both the source text and the target text.
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:okp="okapi-framework:xliff-extensions" xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsxlf="http://www.w3.org/ns/its-xliff/" its:version="2.0">
<file original="index.html" source-language="en-US" target-language="es-ES" datatype="x-text/html">
<body>
<group id="1" restype="div">
<trans-unit id="1_1" approved="yes">
<source xml:lang="en-ZZ">Hello world!</source>
<target xml:lang="es-ES" state="translated">¡Hola mundo!</target>
<note>Translate "world" as in "people", not as in "planet".</note>
</trans-unit>
<trans-unit id="1_2">
<source xml:lang="en-ZZ">How are you?</source>
<target xml:lang="es-ES" state="signed-off">¿Cómo estás?</target>
</trans-unit>
</group>
</body>
</file>
</xliff>OmegaT/XLIFF for PMs and engineers (5) - XLIFF -- Hello world
By cApStAn LQC
OmegaT/XLIFF for PMs and engineers (5) - XLIFF -- Hello world
Hello world



