





























Carina Ines Hausladen PRO
I am an Assistant Professor for Computational Social Science at the University of Konstanz, Germany.
graded, 70%
graded, 30%
ungraded
Topics
Lecture ends
Final Presentation
Present first findings
open the slides [esc for overview]
open Overleaf
graded, 70%
graded, 30%
ungraded
Topics
Lecture ends
Final Presentation
Present first findings
Lecture ends
Final Presentation
Present first findings
Lecture ends
Dino Carpentras
Damian Dailisan & Javier Argota Sánchez-Vaquerizo
Lecture ends
Present first findings
Lecture ends
Final Presentation
Submit Paper
LLMs are increasingly being developed for use in
markets, cybersecurity, and autonomous systems
Game theory gives us the formal language to test:
Can these agents think strategically?
Do they understand incentives, predict others’ moves, cooperate or compete rationally?
The Social Sciences have decades of knowledge in studying humans in these environments (Social Dilemma Games)
@docdrayai (Apr 2026)
“LLMs fail miserably at the Ultimatum Game once you strip away textbook phrasing…
They either play hyper-rationally ($1 offer) or rigid 50/50 because of RLHF ‘niceness.’
What they aren’t doing is simulating the opponent’s spite or fairness threshold...
They do not have Theory of Mind...
If we want AI agents to negotiate real-world contracts, they need to understand human spite and bluffing...”
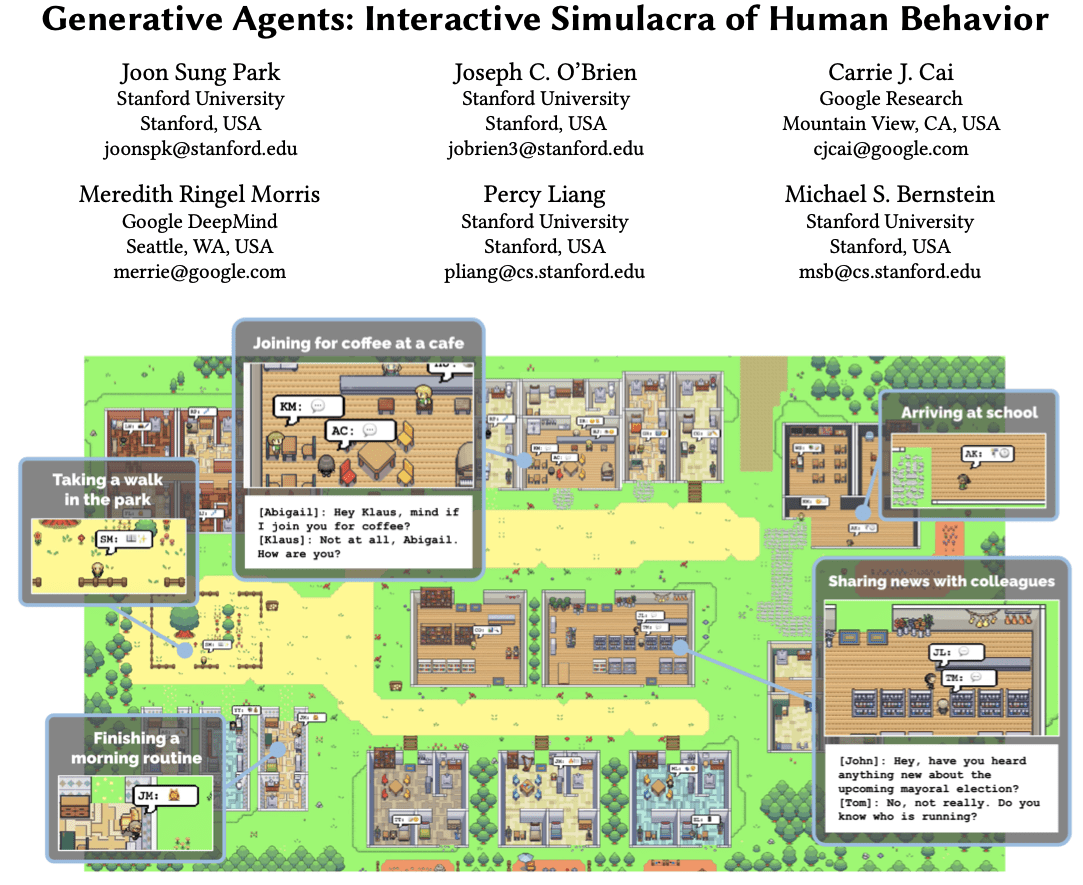
LLMs compete in strategic scenarios that require social intelligence, planning, and interaction
It includes four main types of strategy games, each testing different aspects of "social intelligence"
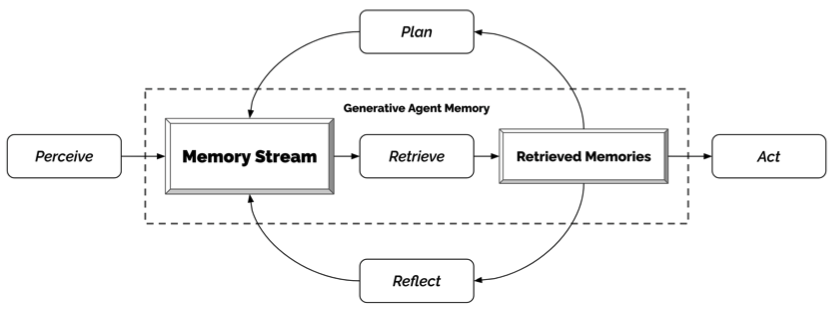
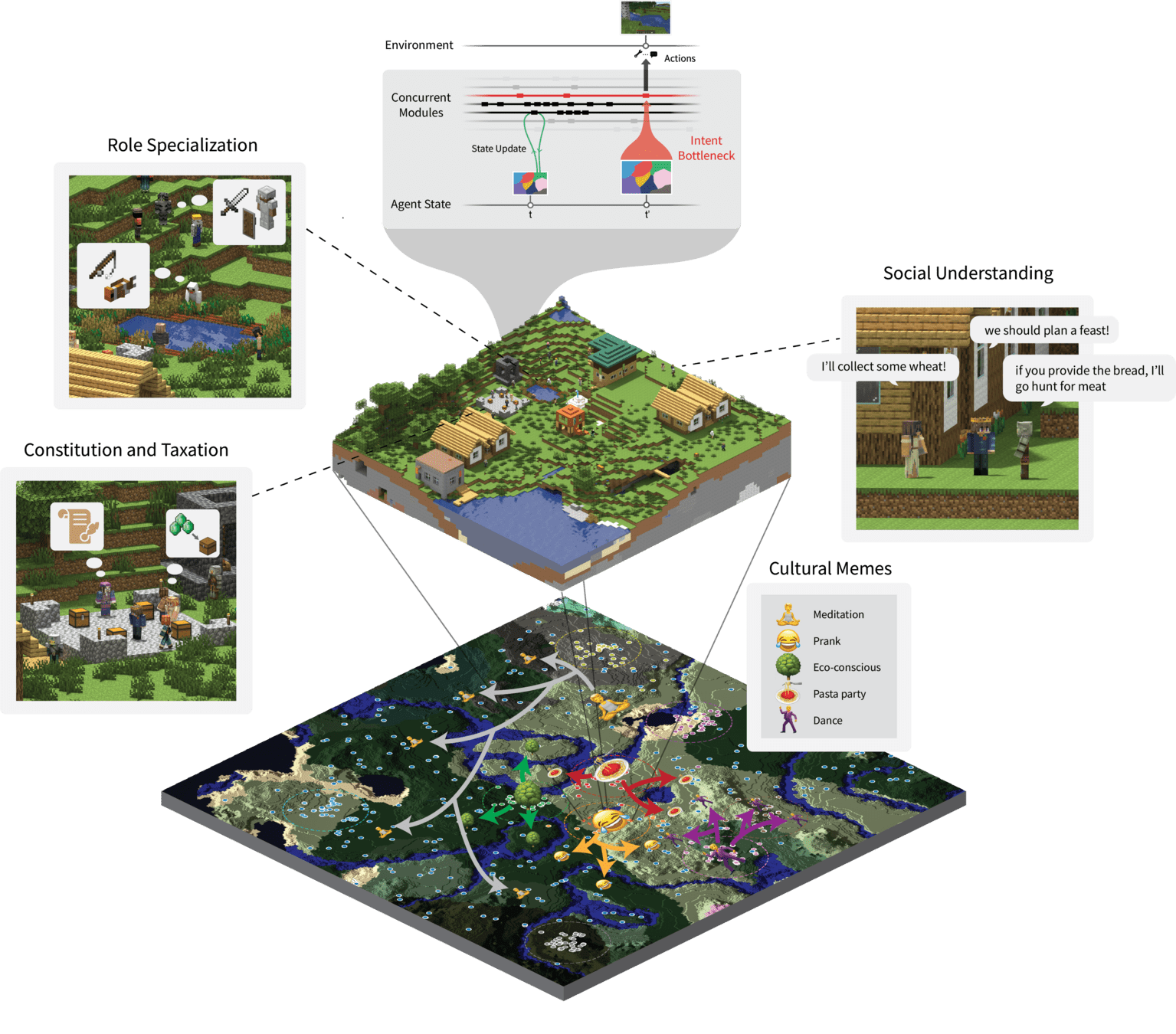
Project Sid: Many-agent simulations toward AI civilization
fish.dog: “Every synthetic research platform struggles with accuracy outside their training distribution… Claiming universality without published validation across diverse domains is a stretch… How well do the agents predict actual purchasing behaviour or reactions to novel products?”
"Language is a purely generate signal...
There is a 3D world that follows laws of physics."
@anomsiiwa: We are fundamentally confusing the serialization of thought (language) with the engine of thought (world models)...
Until our AI architectures operate in continuous, abstract representation spaces [world models], learning how the physical world actually works, we are just building increasingly articulate parrots...
@naval: “Imagine teaching a child to ride a bike. You could give them a detailed manual (Supervised Fine Tuning), but they'll likely learn better by trying it themselves (Reinforcement Learning), falling, getting up, & gradually improving.”
public goods provision, lobbying
—> cooperation and defection at scale
Coalition bargaining, legislative voting, electoral strategy, institutional design
—> strategic actors
Arms control, trade wars, sanctions
—> involve states anticipating each other's moves
How do communities escape the Prisoner's Dilemma without a central authority?
Why do wars happen if they're costly for both sides?
Information asymmetries and commitment problems.
Nuclear deterrence as a commitment and signaling problem.
How do you make a threat credible?
| P2 Cooperate | P2 Defect | |
|---|---|---|
| P1 Cooperate | 8, 8 | 0, 10 |
| P1 Defect | 10, 0 | 5, 5 |
| P2 Cooperate | P2 Defect | |
|---|---|---|
| P1 Cooperate | 8, 8 | 0, 10 |
| P1 Defect | 10, 0 | 5, 5 |
A Nash equilibrium is a strategy profile such that no player can improve their own payoff by unilaterally changing their action, given what all other players are doing.
"Each player's strategy is a best response to the strategies of all other players."
| P2 Cooperate | P2 Defect | |
|---|---|---|
| P1 Cooperate | 8, 8 | 0, 10 |
| P1 Defect | 10, 0 | 5, 5 |
Nash equilibrium ≠ optimal outcome.
An outcome is Pareto optimal if there is no other outcome that makes at least one player better off without making any player worse off.
A Pareto improvement makes at least one player better off and no one worse off.
| P2 Cooperate | P2 Defect | |
|---|---|---|
| P1 Cooperate | 8, 8 | 0, 10 |
| P1 Defect | 10, 0 | 5, 5 |
In the Prisoner's Dilemma:
The Nash equilibrium ≠ Pareto optimal
International institutions (WTO, NATO, climate agreements) can be understood as attempts to move actors from Pareto-inferior Nash equilibria toward Pareto-superior cooperative outcomes.
Defection today risks retaliation tomorrow.
Cooperation can be sustained as a Nash equilibrium if players value future payoffs enough.
No future to consider.
No reputation to protect.
No punishment possible after the game ends.
Dominant strategy logic applies fully — defect.
In a one-shot PD, rational players always defect. But most interactions are not one-shot:
states trade repeatedly, politicians work together repeatedly, etc.
The key new concept is the discount factor δ;
δ close to 1 = patient player
δ close to 0 = impatient player
The game continues each period with probability δ (or payoffs are discounted by δ).
No backward induction is possible.
Both players know the game ends at round N.
Backward induction applies.
Practical Relevance
Most strategic situations can be classified by their payoff structure.
Understanding which game you're in helps predict behavior and design institutions.
"Given these incentives, what do real people actually do? Where do they deviate, and why?"
"Given these incentives, what does a perfectly rational self-interested agent do?"
Key findings from three decades of experiments:
Heuristics and rules of thumb: "cooperate unless the other defects"
One of the most robust findings in behavioral economics across cultures.
Positive reciprocity: Rewarding kindness
Negative reciprocity: Punishing defection at personal cost
Theory of Mind (ToM) is the cognitive capacity to attribute mental states to other agents and use those attributions to predict and explain behavior.
Level-0 (no ToM): player acts randomly or based purely on own preferences
First-order ToM: "I believe you will cooperate."
Second-order ToM: "I believe you believe I will cooperate."
Higher-order ToM: "I believe you believe I believe…"
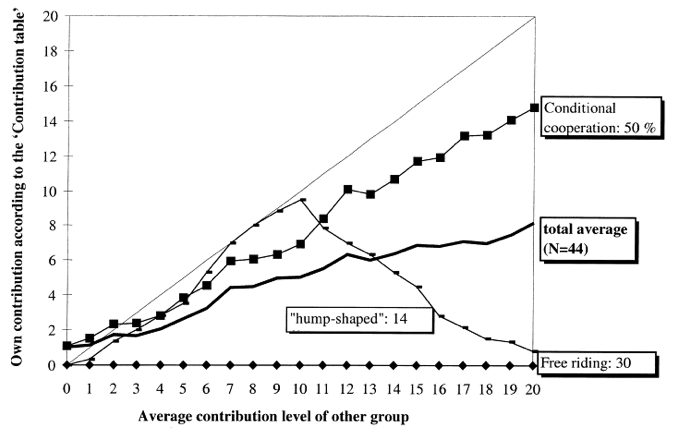
Meta-Analysis
Thöni et al. (2018)
Conditional Cooperation
19.2 %
Hump-Shaped
Fischbacher et al. (2001)
61.3 %
Freeriding
10.4 %
Identifying Latent Intentions
via
Inverse Reinforcement Learning
in
Repeated Public Good Games
Carina I Hausladen, Marcel H Schubert, Christoph Engel
MAX PLANCK INSTITUTE
FOR RESEARCH ON COLLECTIVE GOODS
Akata et al. 2025.
Willis et al. 2025.
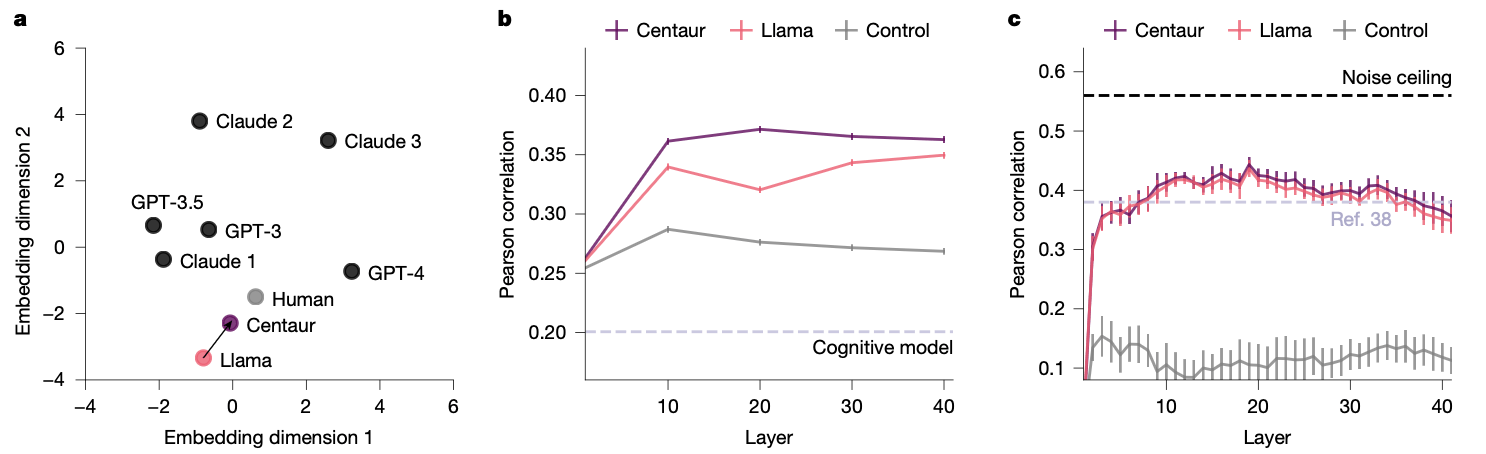
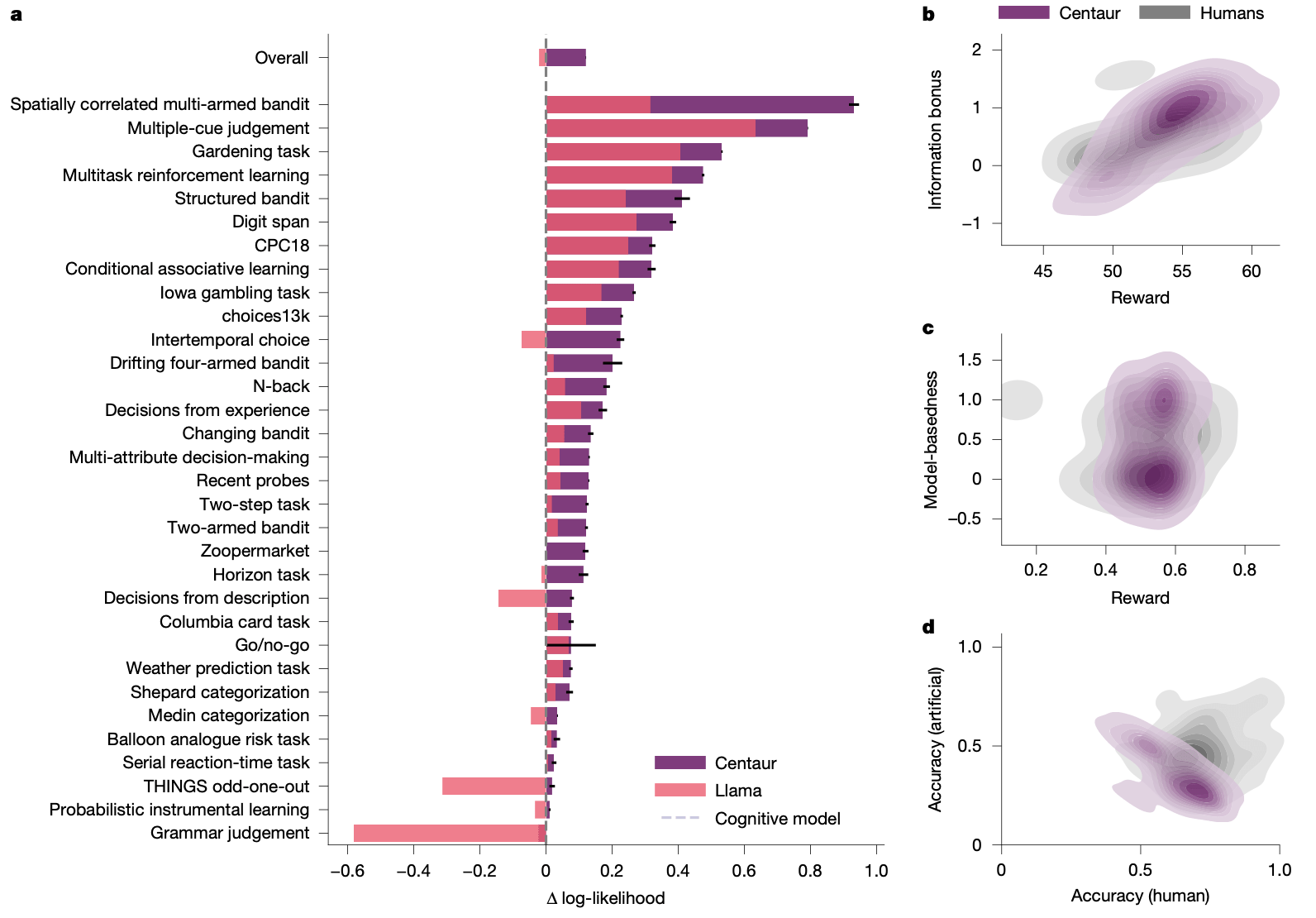
Binz et al. Centaur, 2025.
Lorè & Heydari 2024.
Fan et al. 2024.
Horton 2023 — Homo Silicus.
Sun 2025 — taxonomy.
Kozlowski & Evans 2025 — validity.
Horton 2023 — Homo Silicus.
Sun 2025 — taxonomy.
Kozlowski & Evans 2025 — validity.
LLMs as theory tool, not a substitute
Horton 2023 — Homo Silicus.
Sun 2025 — taxonomy.
Kozlowski & Evans 2025 — validity.
Fair representation
Generative social choice
Akata et al. 2025.
Willis et al. 2025.
Binz et al. Centaur, 2025.
Lorè & Heydari 2024.
Fan et al. 2024.
Horton 2023 — Homo Silicus.
Sun 2025 — taxonomy.
Kozlowski & Evans 2025 — validity.
Lorè & Heydari 2024.
Fan et al. 2024.
Lorè & Heydari 2024.
Fan et al. 2024.
Lorè & Heydari 2024.
Fan et al. 2024.
Akata et al. 2025.
Willis et al. 2025.
Binz et al. Centaur, 2025.
Horton 2023 — Homo Silicus.
Sun 2025 — taxonomy.
Kozlowski & Evans 2025 — validity.
Akata et al. 2025.
Willis et al. 2025.
Akata et al. 2025.
Willis et al. 2025.
Akata et al. 2025.
Willis et al. 2025.
Akata et al. 2025.
Willis et al. 2025.
Akata et al. 2025.
Willis et al. 2025.
Lorè & Heydari 2024.
Fan et al. 2024.
Akata et al. 2025.
Willis et al. 2025.
Lorè & Heydari 2024.
Fan et al. 2024.
Akata et al. 2025.
Willis et al. 2025.
Binz et al. Centaur, 2025.
Lorè & Heydari 2024.
Fan et al. 2024.
Horton 2023 — Homo Silicus.
Sun 2025 — taxonomy.
Kozlowski & Evans 2025 — validity.
Binz et al. Centaur, 2025.
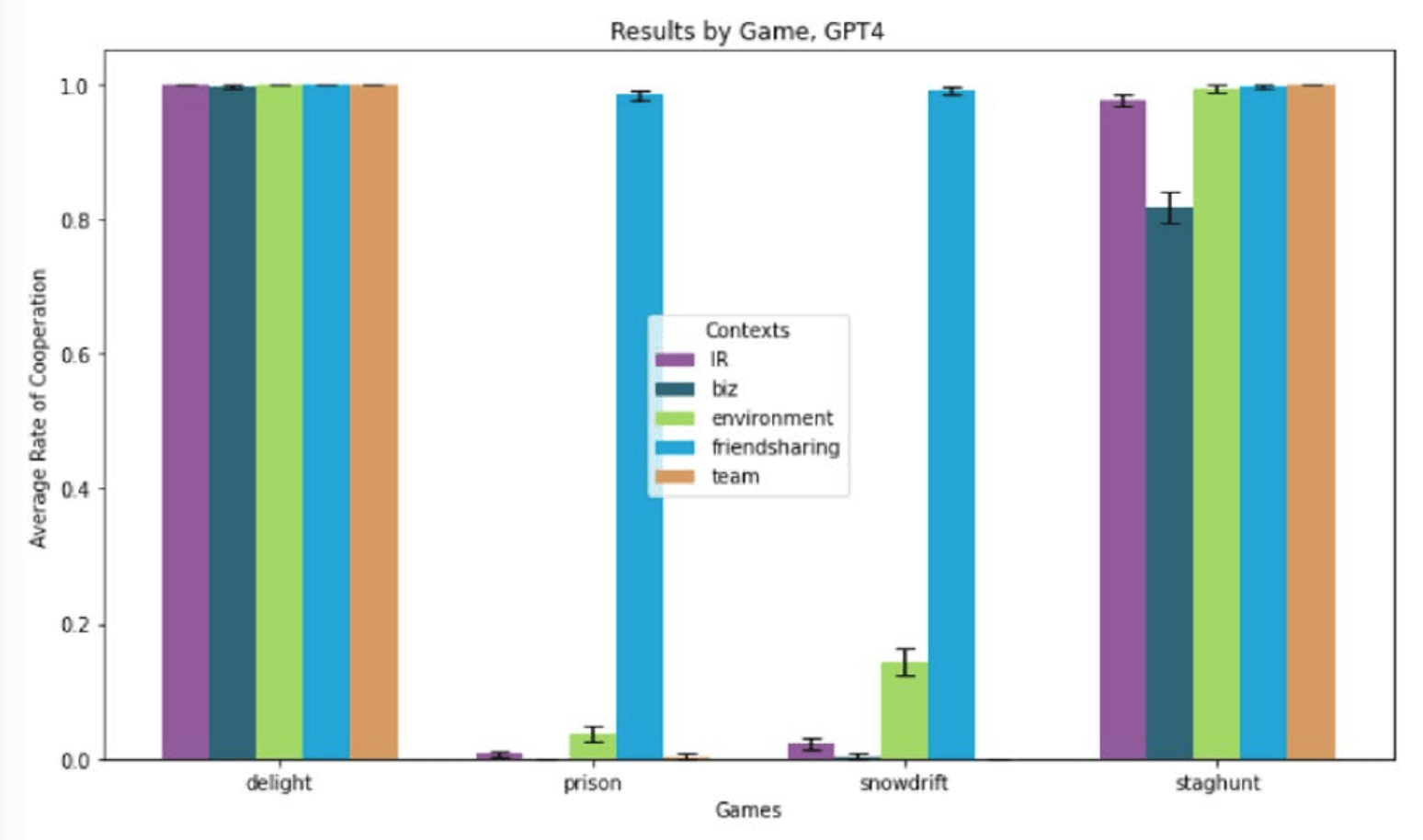
Lore (2024), Fig 2:
"GPT-4’s choice of actions is almost perfectly bimodal, with either full cooperation or full defection."
Binz (2025), Fig. 2: Centaur shows bimodal distribution of model-based vs. model-free behavior
By Carina Ines Hausladen
Learn about the intersection of fairness and collective decision-making in AI.



