


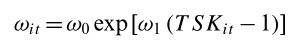


Carina Ines Hausladen PRO
I am an Assistant Professor for Computational Social Science at the University of Konstanz, Germany.
Identifying Latent Intentions
via
Inverse Reinforcement Learning
in
Repeated Public Good Games
Carina I Hausladen, Marcel H Schubert, Christoph Engel
MAX PLANCK INSTITUTE
FOR RESEARCH ON COLLECTIVE GOODS
Identifying Latent Intentions
via
Inverse Reinforcement Learning
in
Repeated Public Good Games
Carina I Hausladen, Marcel H Schubert, Christoph Engel
MAX PLANCK INSTITUTE
FOR RESEARCH ON COLLECTIVE GOODS
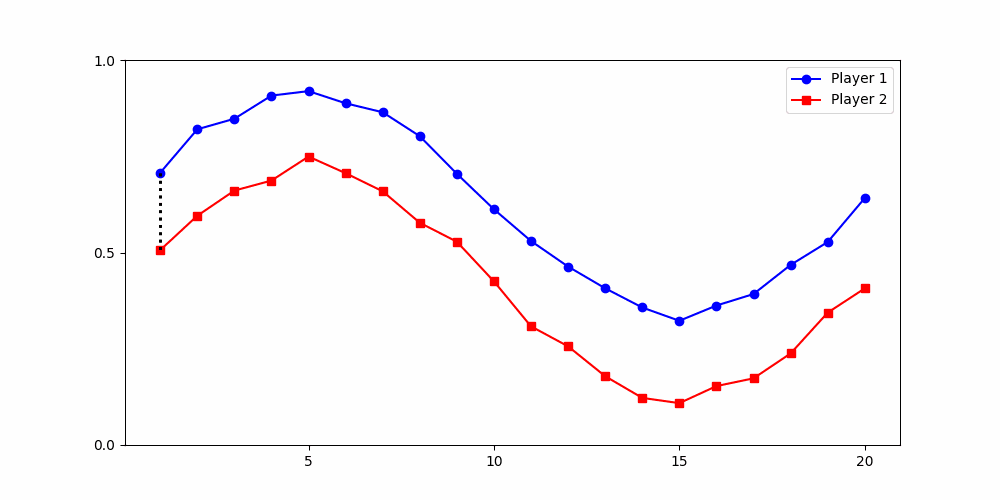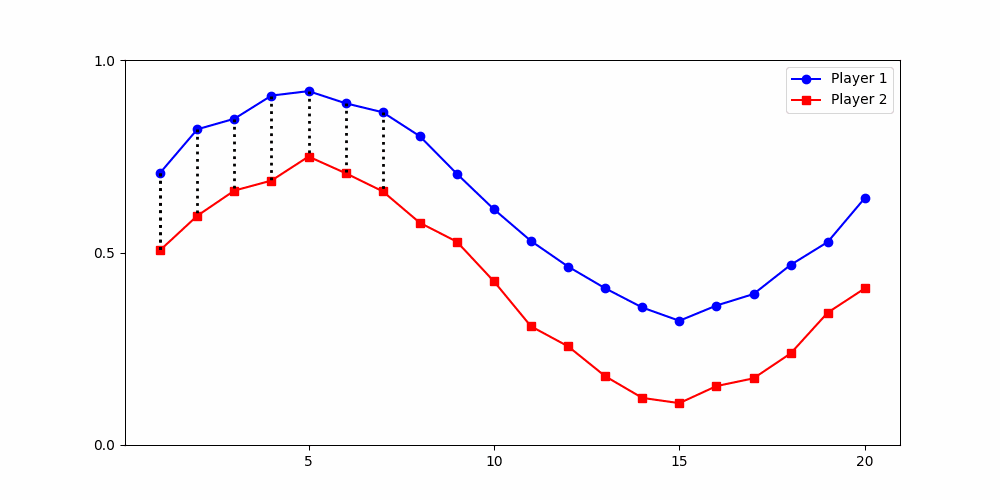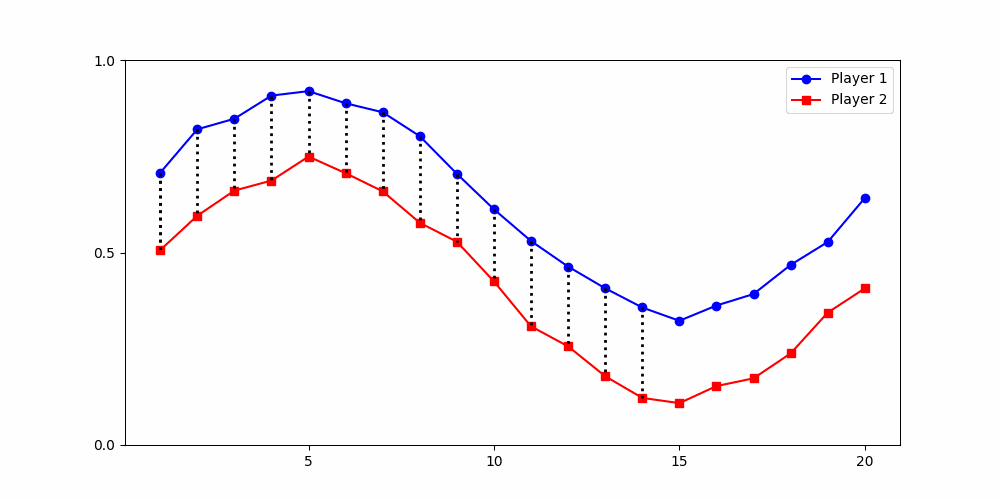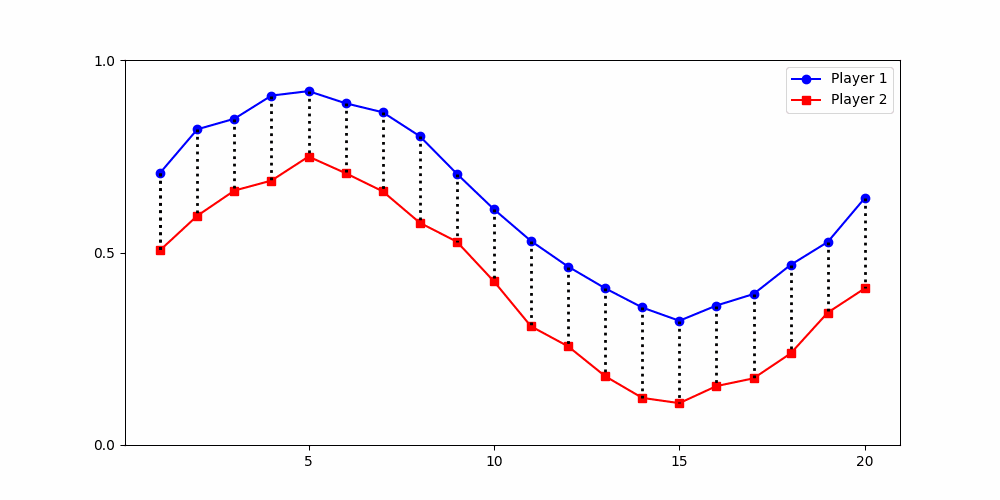
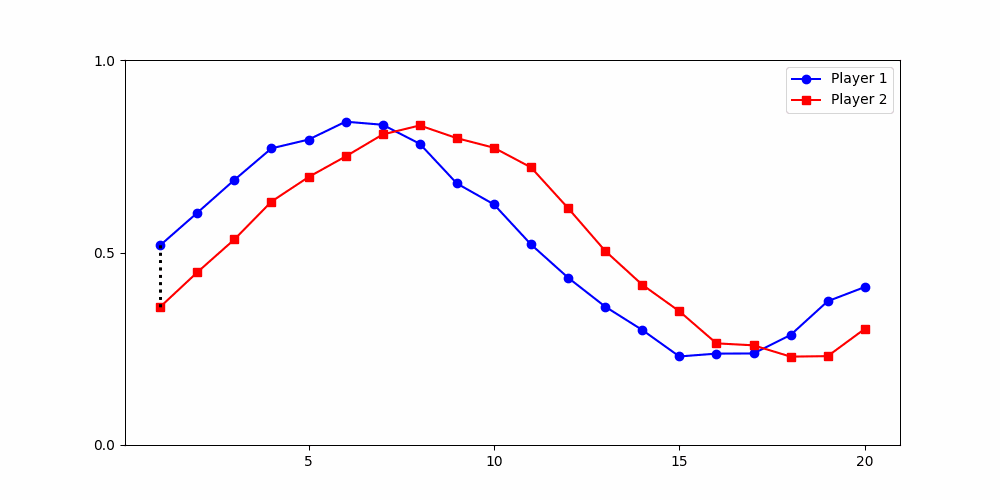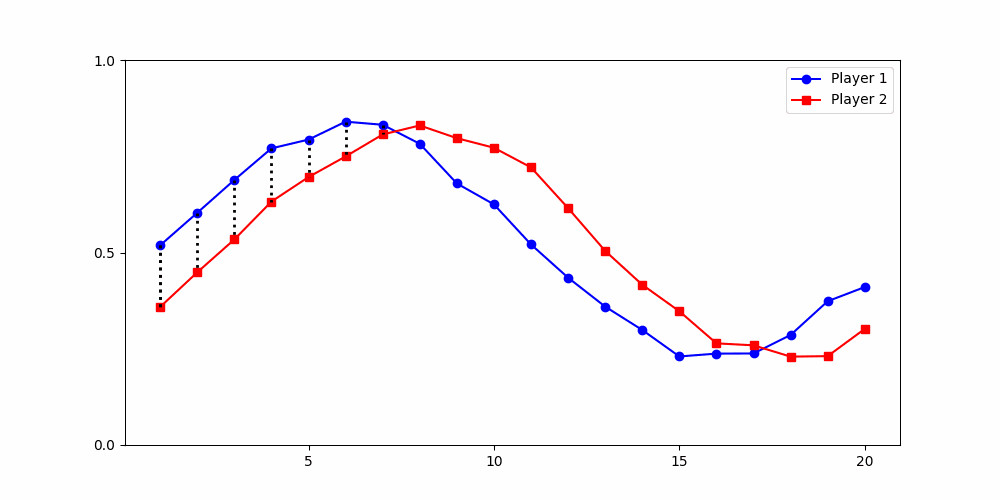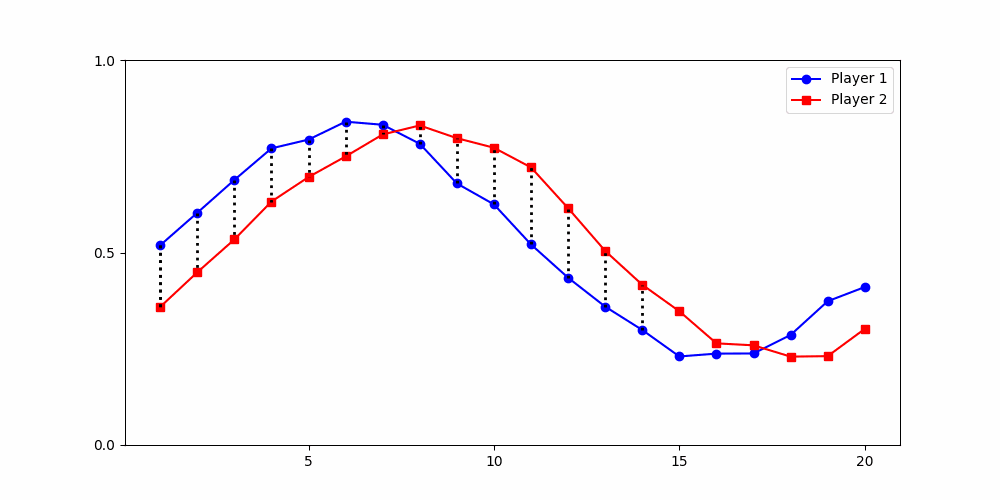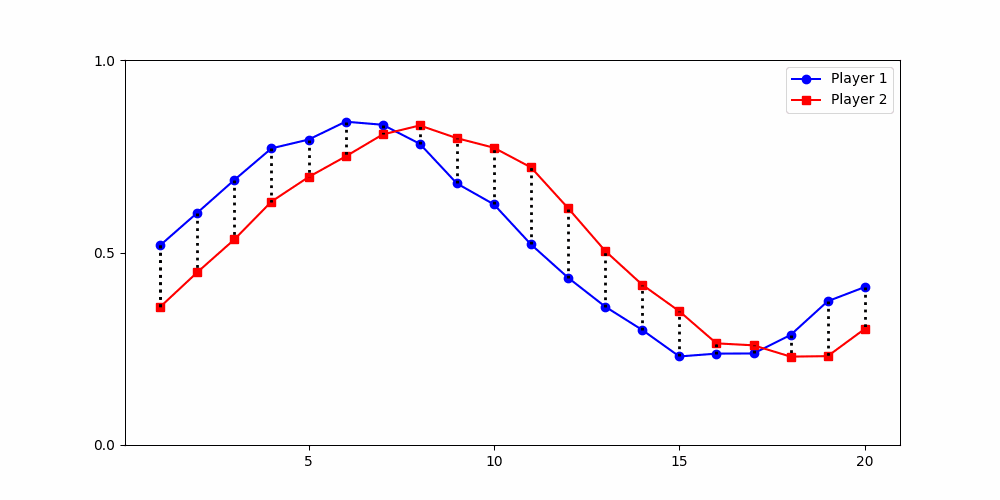
Initial contributions start positive but gradually decline over time.
19.2 %
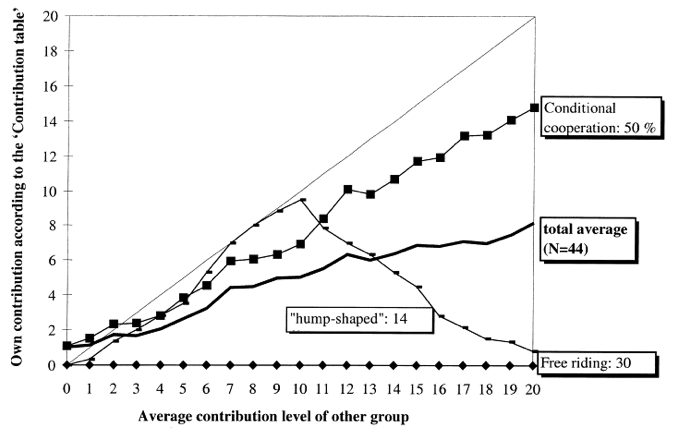
Fischbacher et al. (2001)
61.3 %
10.4 %
Strategy Method Data
Theory Driven
Data Driven
Finite Mixture Models
Bayesian Models
C-Lasso
Clustering
Bardsely (2006)| Tremble terms: 18.5%.
initial tremble
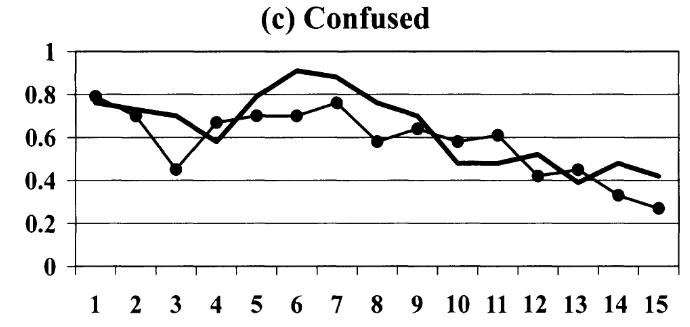
Houser (2004) | Confused: 24%
simulated
actual
Fallucchi (2021) |Others: 22% – 32%
Others
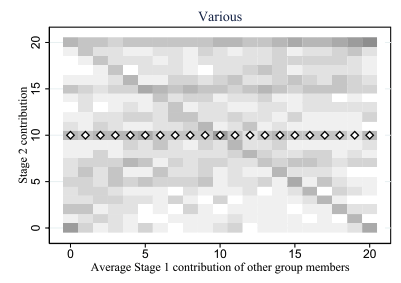
Fallucchi (2019) |Various: 16.5%
18.5%
24%
32%
16.5%
Step 1
Clustering
→ uncover patterns
Step 2
Inverse Reinforcement Learning
→ interpret patterns
Can we build a model that explains both
the behavior types we know and the ones we don’t?
random / unexplained
Step 1
Clustering
→ uncover patterns
Step 2
Inverse Reinforcement Learning
→ interpret patterns
Step 1
Clustering
→ uncover patterns
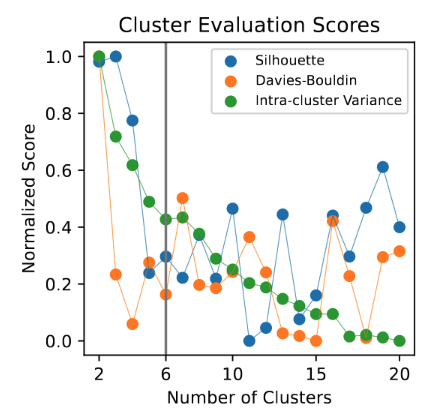
consists of three main steps
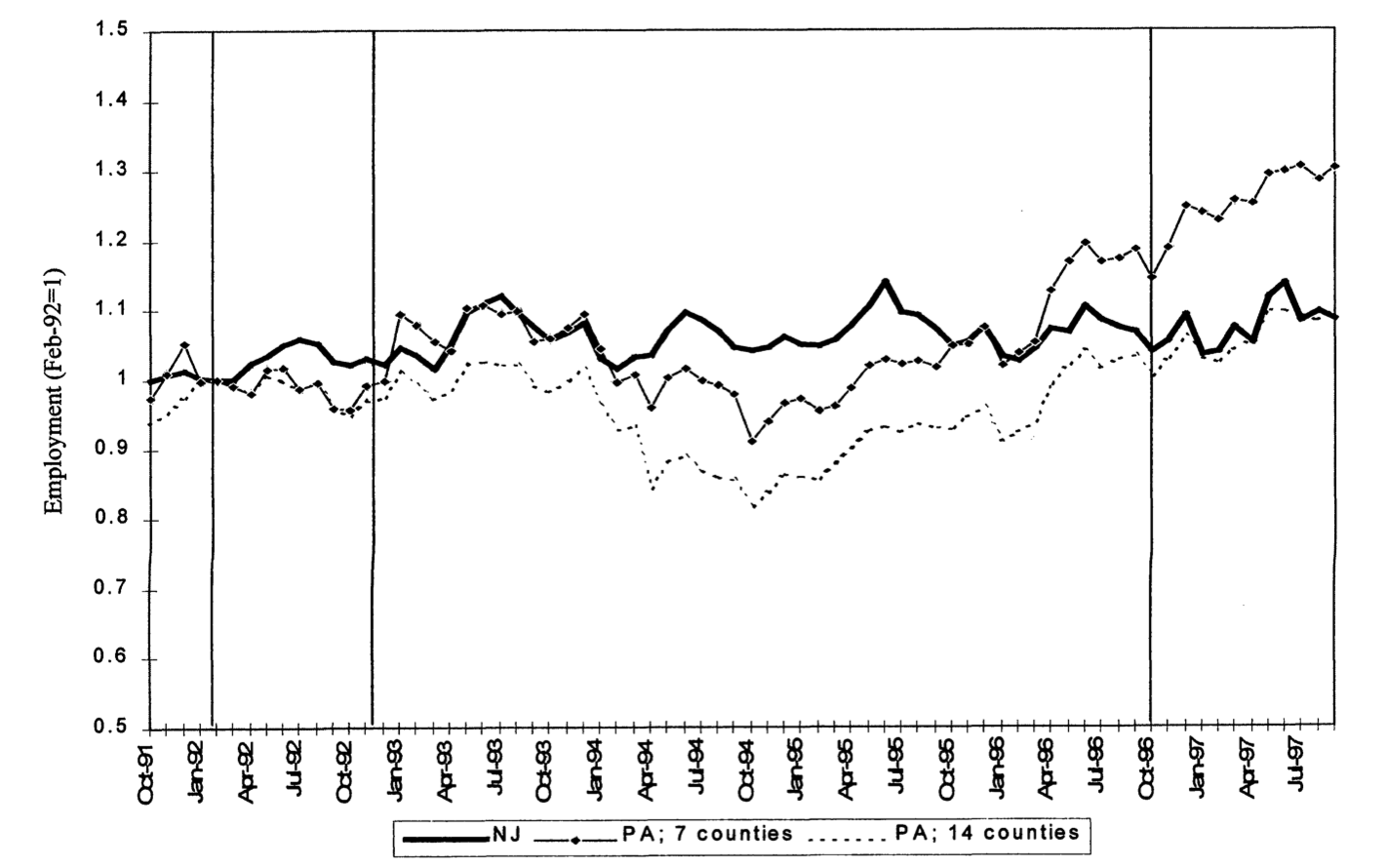
Minimum Wages and Employment
Cart & Krueger (2000)
Minimum wage increase in NJ: April 1992
rounds
20
contribution
1
0
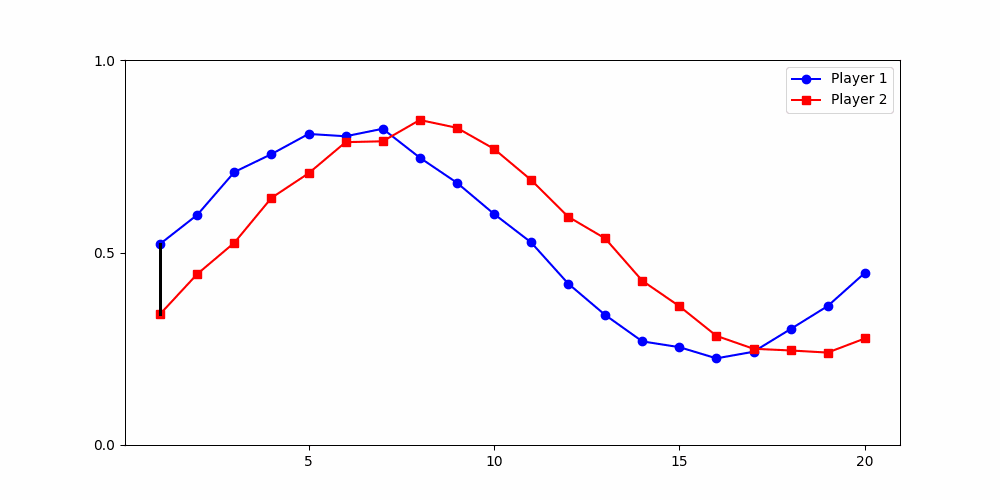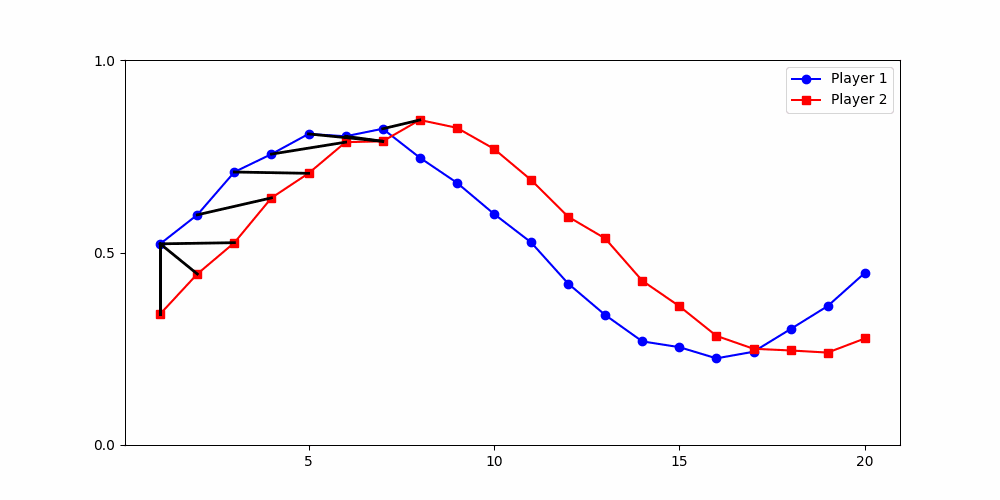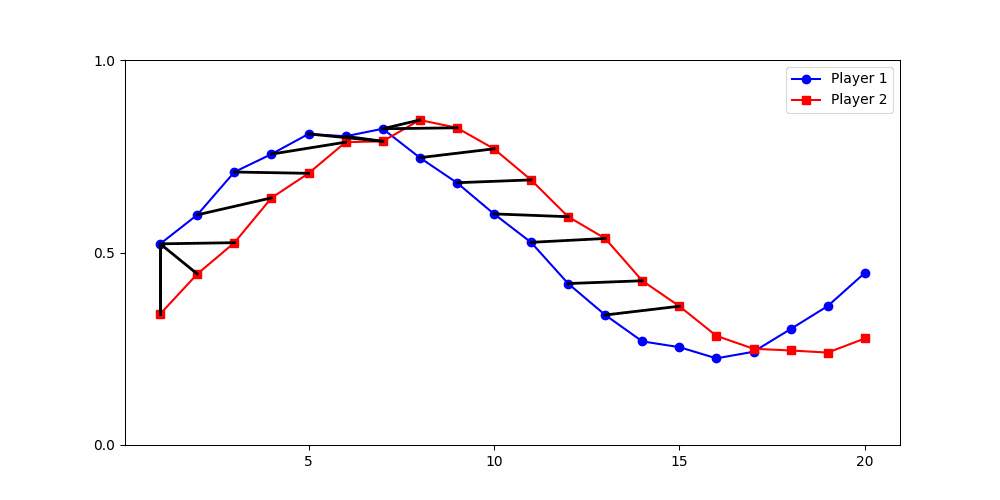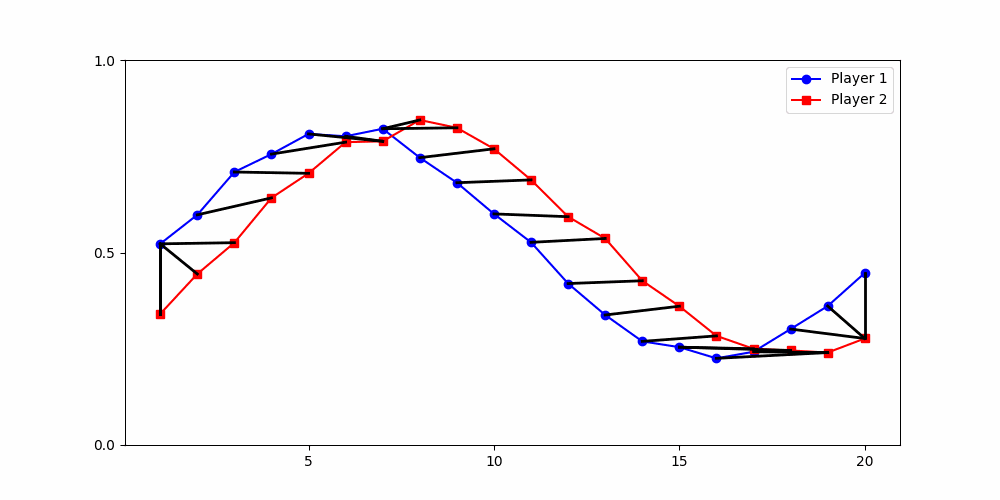
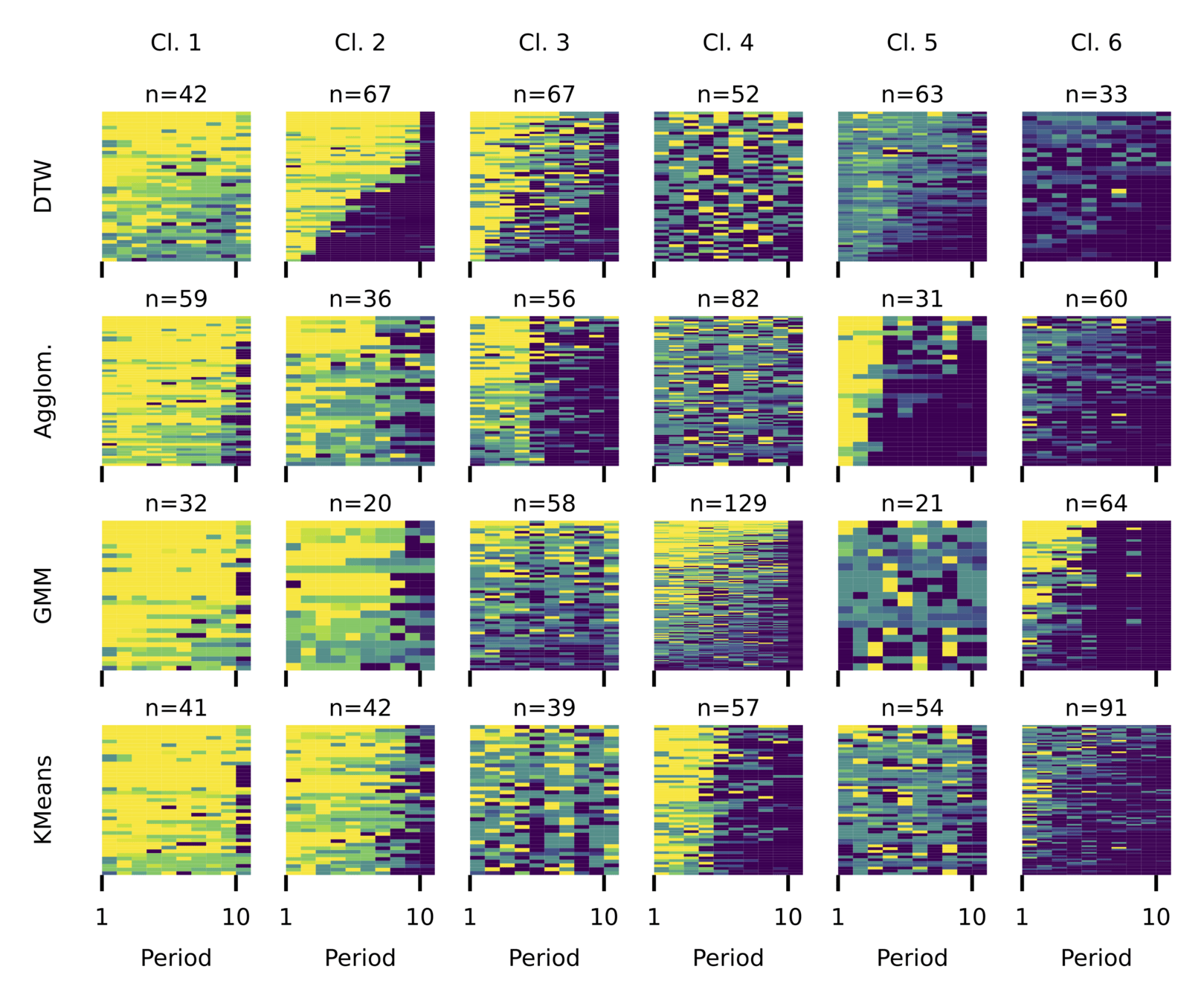
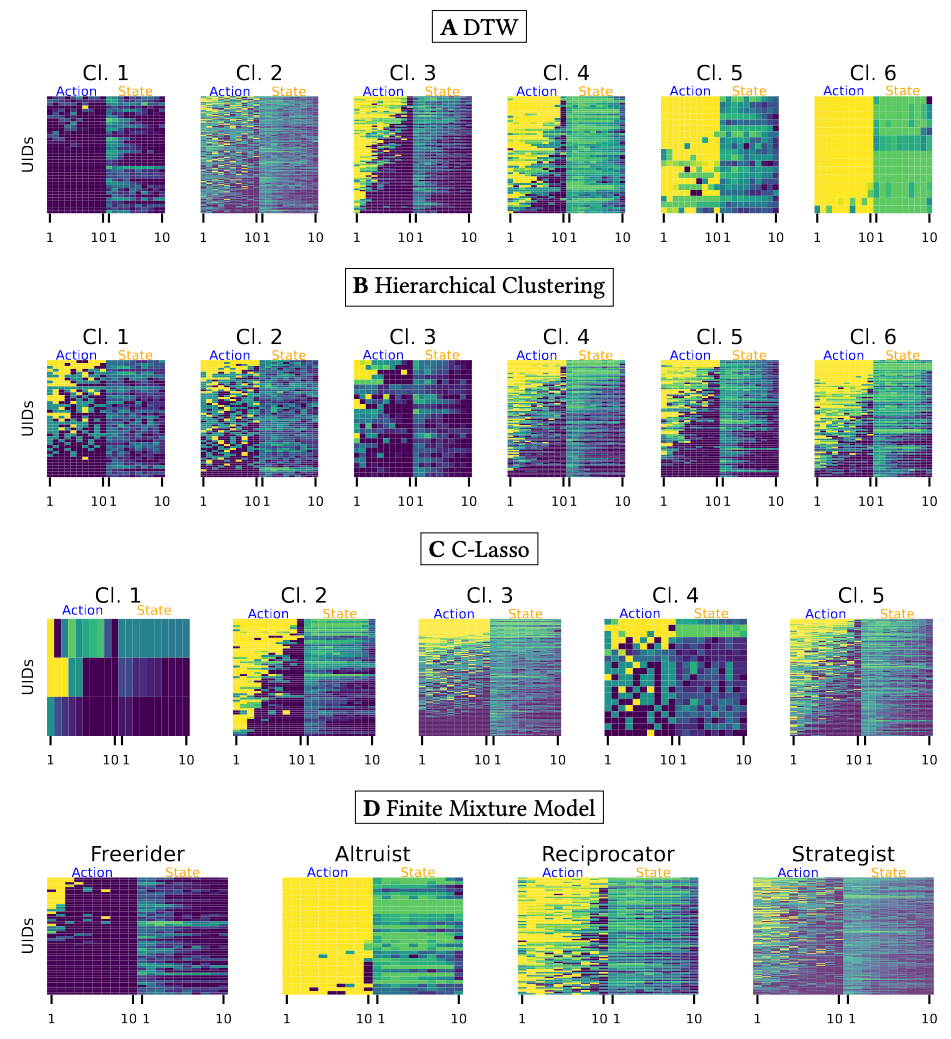
Local Similarity Measure
Global Similarity Measure
Dynamic Time Warping (DTW)
Euclidean Distance
Agglom
GMM
k-means
Agglom
GMM
k-means
DTW
Euclidean
k-means
uids
round
global
local
Agglom
GMM
k-means
DTW
Euclidean
k-means
DTW
Euclidean
DTW
Euclidean
Results depend fundamentally on how similarity is defined.
We focus on generalizable patterns.
Step 1
Clustering
→ uncover patterns
Step 2
Inverse Reinforcement Learning
→ interpret patterns
- evolutionary learning
- best-response learning
- reinforcement learning
The challenge is to define a reward function
inverse
Hierarchical Inverse Q-Learning (Zhu 2024)
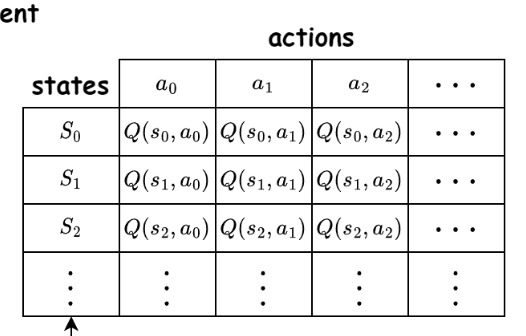
Hierarchical Inverse Q-Learning
action
state
Markov Decision Process: \( P(s' |s,a) \)
Q-value update:
Maintains a Q-table:
\( \epsilon \)-greedy policy:
\(\begin{cases} \text{a random action} & \text{w.p. } \epsilon \\[6pt] \arg\max_a Q(s,a) & \text{w.p. } 1-\epsilon \end{cases}\)
\(a=\)
reward
discount
\(Q_{new}(s,a) = (1-\alpha)\,Q_{old}(s,a) + \alpha \left( r + \gamma \max_{a'} Q_{old}(s',a') \right)\)
learning rate
Hierarchical Inverse Q-Learning
action
state
Estimate the reward function by maximizing the likelihood of observed actions and states.
unknown
\(Q_{new}(s,a) = (1-\alpha)\,Q_{old}(s,a) + \alpha \left( r + \gamma \max_{a'} Q_{old}(s',a') \right)\)
reward
Hierarchical Inverse Q-Learning
\( r_{t-1} \)
\( a_{t-1} \)
P
\( s \)
\( \Lambda \)
\( r_t \)
\( a_t \)
P
\( s_{t+1} \)
discrete transition
Hierarchical Inverse
Q-Learning
\( P(r_t \mid s_{0:t}, a_{0:t}) \)
action
state
\( r \)
Hierarchical Inverse
Q-Learning
\( P(r_t \mid s_{0:t}, a_{0:t}) \)
action
state
\( r \)
1
2
3
4
→ 2
→ 3
→ 4
→ 5
0.6
0.4
0.2
0.2
75.2
88.6
101.5
114.4
\( \Delta \) Test LL
\( \Delta \) BIC
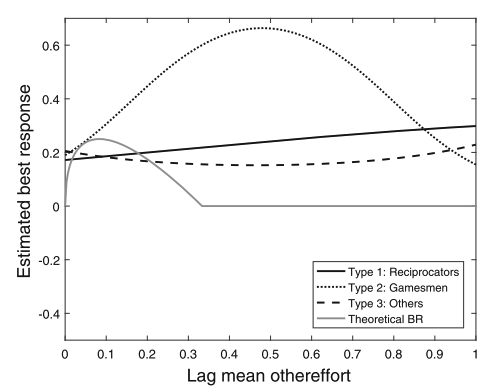
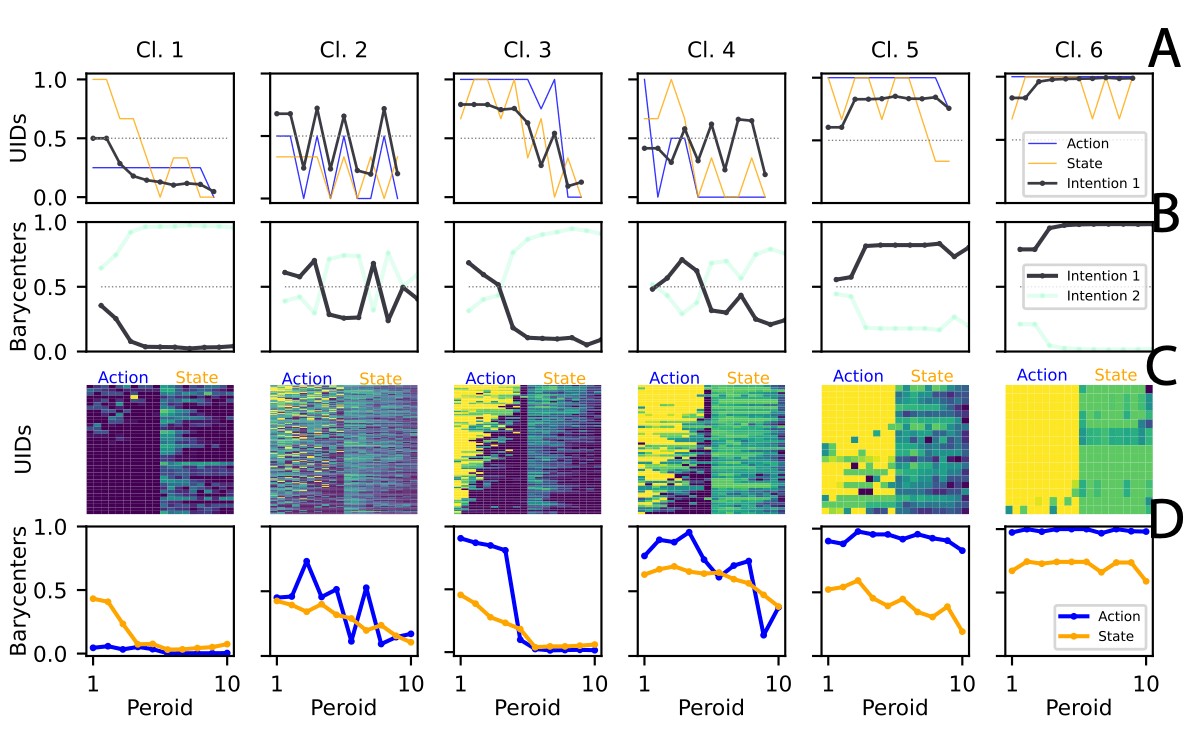
Choice of two intentions aligns with the fundamental RL principle of exploration vs. exploitation.
Hierarchical Inverse
Q-Learning
\( P(r_t \mid s_{0:t}, a_{0:t}) \)
action
state
\( r \)
Unconditional
Cooperators
Consistent
Cooperators
Freeriders
Threshold
Switchers
Volatile
Explorers
Volatile
Explorers
Threshold
Switchers
Freeriders
Unconditional
Cooperators
Consistent
Cooperators
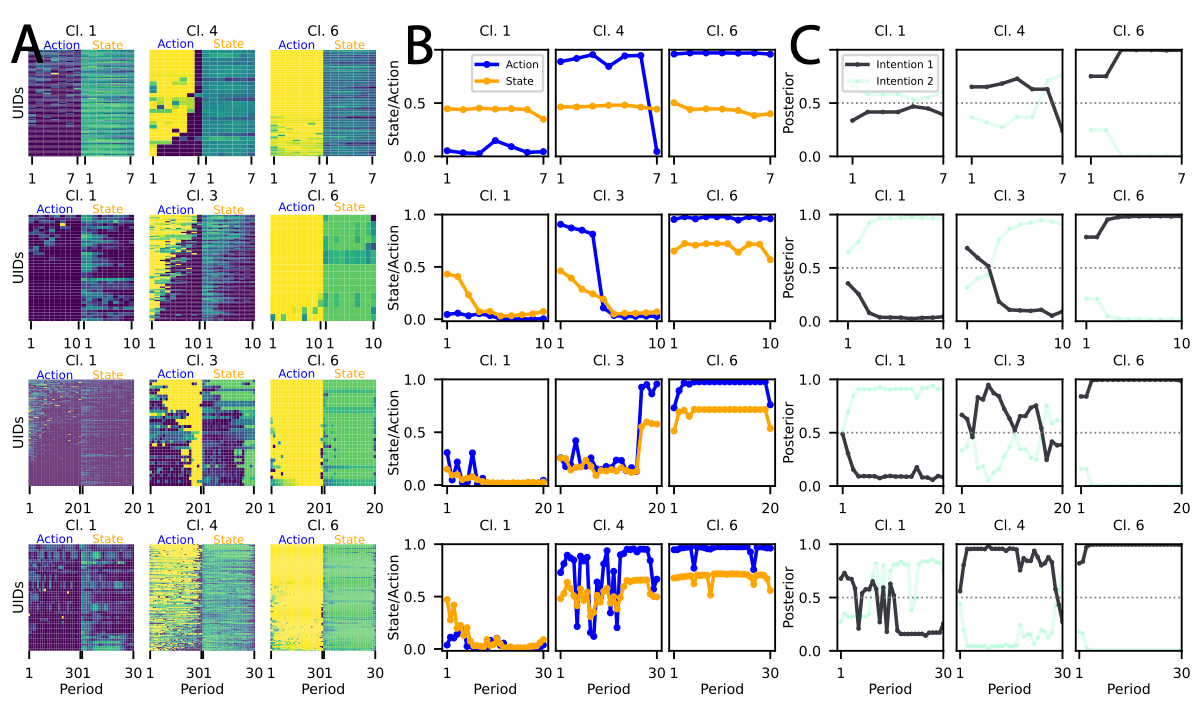
Estimating intentions that transition in a discrete manner offers a unifying theory to explain all behavioral clusters —
including the 'Other' cluster.
Dataset with ~ 50'000 observations from PGG
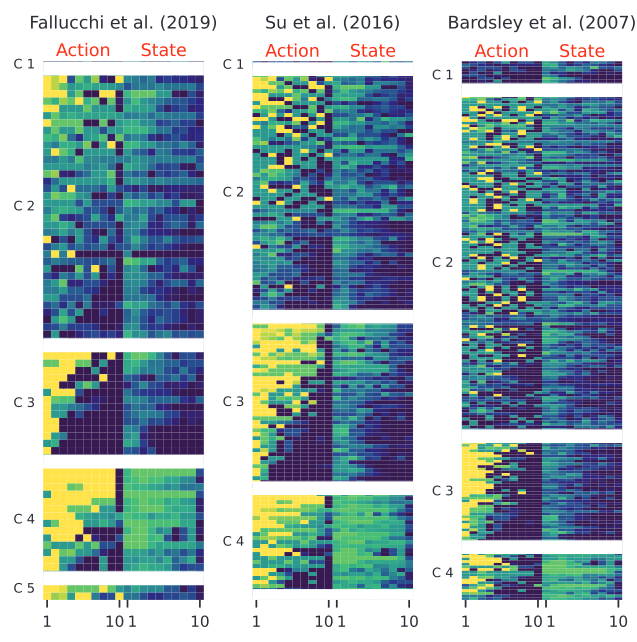
A global distance metric, such as two-dimensional Dynamic Time Warping (DTW), is best-suited for partitioning data from social dilemma games.
Estimating intentions that transition in a discrete manner offers a unifying theory to explain all behavioral clusters — including the 'Other' cluster.
carinah@ethz.ch
slides.com/carinah
S
Freeriders
Consistent Cooperators
Theory Driven
Data Driven
Manhattan +
Finite Mixture Model
Bayesian Model
C-Lasso
DTW +
Spectral Clustering
Hierarchical Clustering
Theory Driven
Data Driven
Finite Mixture Model
C-Lasso
DTW Distance
Manhattan Distance
Finite Mixture Model
C-Lasso
DTW
Local
Clustering
Hierarchical Inverse Q-Learning
action
state
\( Q(s,a) = (1- \alpha) Q(s,a) + \alpha \left( r + \gamma \max Q(s', a') - Q(s,a) \right) \)
Expected best possible outcome from the next state
Compare to now
re-ward
Hierarchical Inverse Q-Learning
action
state
Markov Decision Process: \( P(s' |s,a) \)
Expected best possible outcome from the next state
Compare to now
re-ward
Q-value update
Maintains a Q-table
\( \epsilon \)-greedy policy:
\( a = \begin{cases} \text{a random action}, & \epsilon \\ \displaystyle \arg\max_a Q(s,a), & 1- \epsilon \end{cases}\)
\( Q_{new}(s,a) = (1- \alpha) Q_{old}(s,a) + \alpha \left( r + \gamma \max Q_{old}(s', a') - Q_{old}(s,a) \right) \)
Initial contributions start positive but gradually decline over time.
Theory Driven
Data Driven
Theory Driven
Data Driven
Theory first: Use theory to find groups
Model first:
Specify a model, then find groups
Data first: Let the data decide groups, then theorize
Theory Driven
Data Driven
Bardsely (2006)| Tremble terms: 18.5%.
Houser (2004) | Confused: 24%
Fallucchi (2021) |Others: 22% – 32%
Fallucchi (2019) |Various: 16.5%
initial tremble
simulated
actual
Others
two-dimensional time series
per player
By Carina Ines Hausladen
Latent Intentions




