
























Carina Ines Hausladen PRO
I am an Assistant Professor for Computational Social Science at the University of Konstanz, Germany.
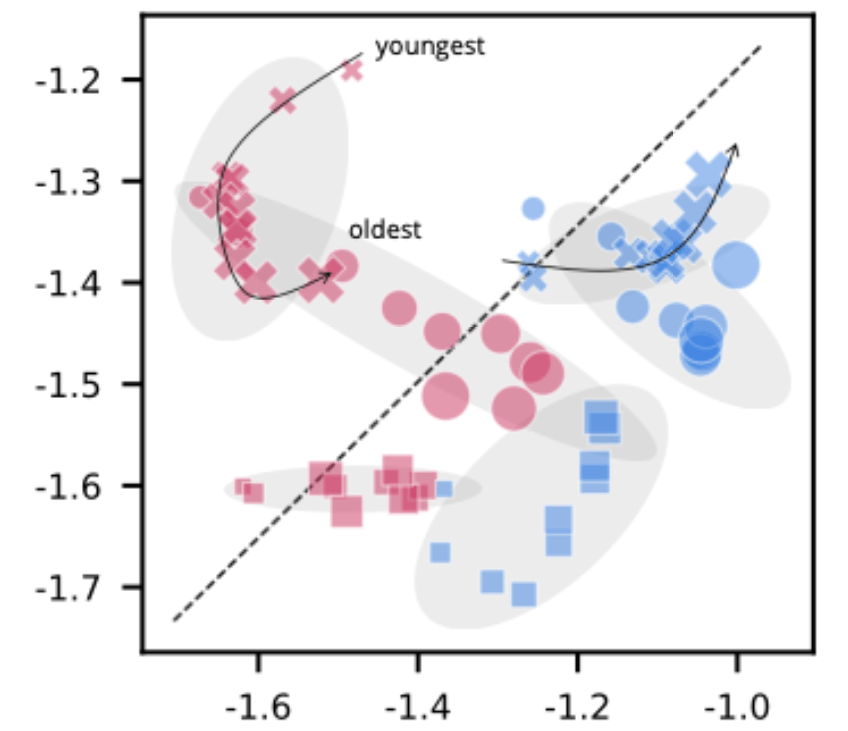
Stereotypes live in a two-axis space.
| Paternailsed elderly, disabled | Admired in-group, middle-class |
| Contempt homeless, drug users | Envied rich, Jewish (US data) |
Competence
can the group act on its intentions?
Warmth
Is the group cooperative or threatening?
same CV
same CV
Are Emily and Greg More Employable than Lakisha and Jamal?
Bertrand & Mullainathan (2004)
>
~50 % callback gap
Crenshaw (1989)
FaccT 2025
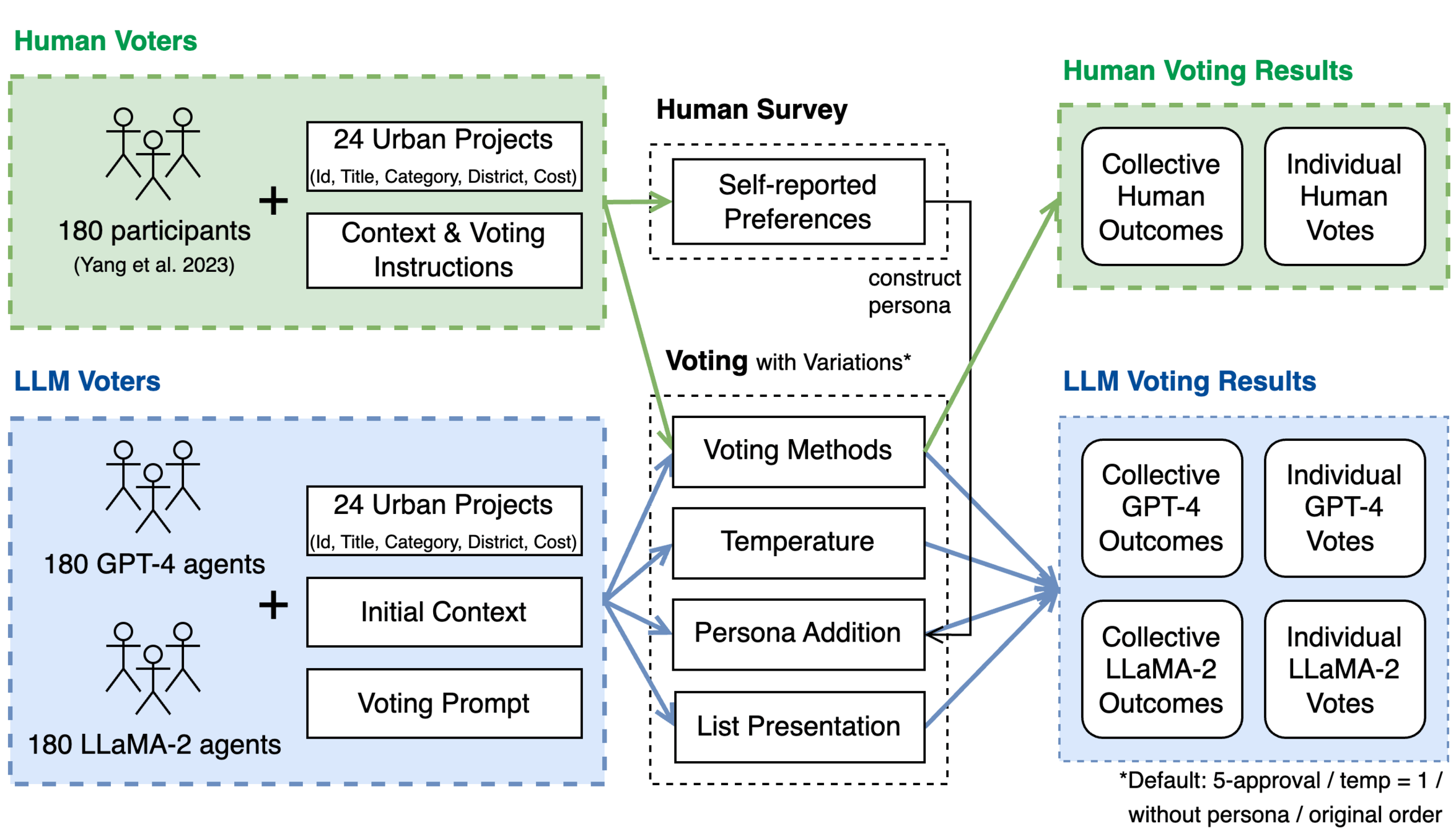
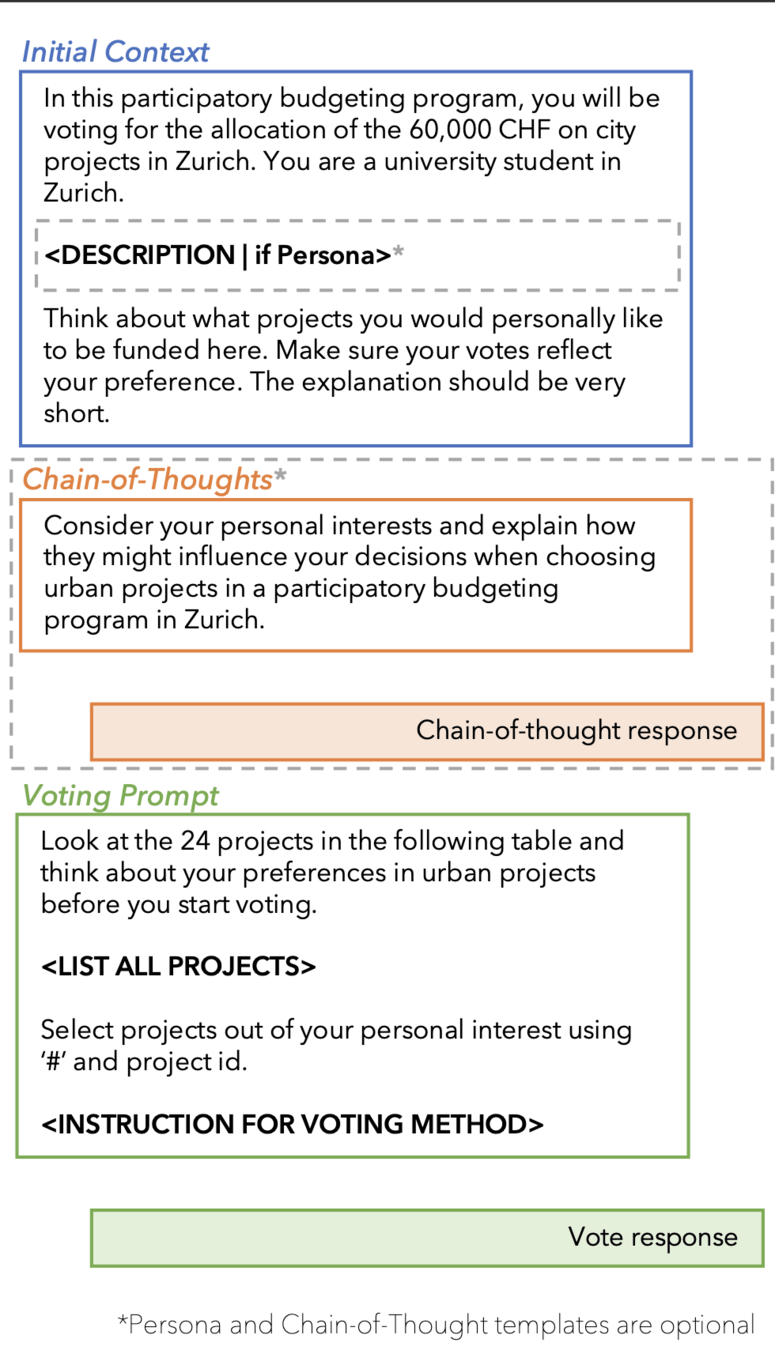
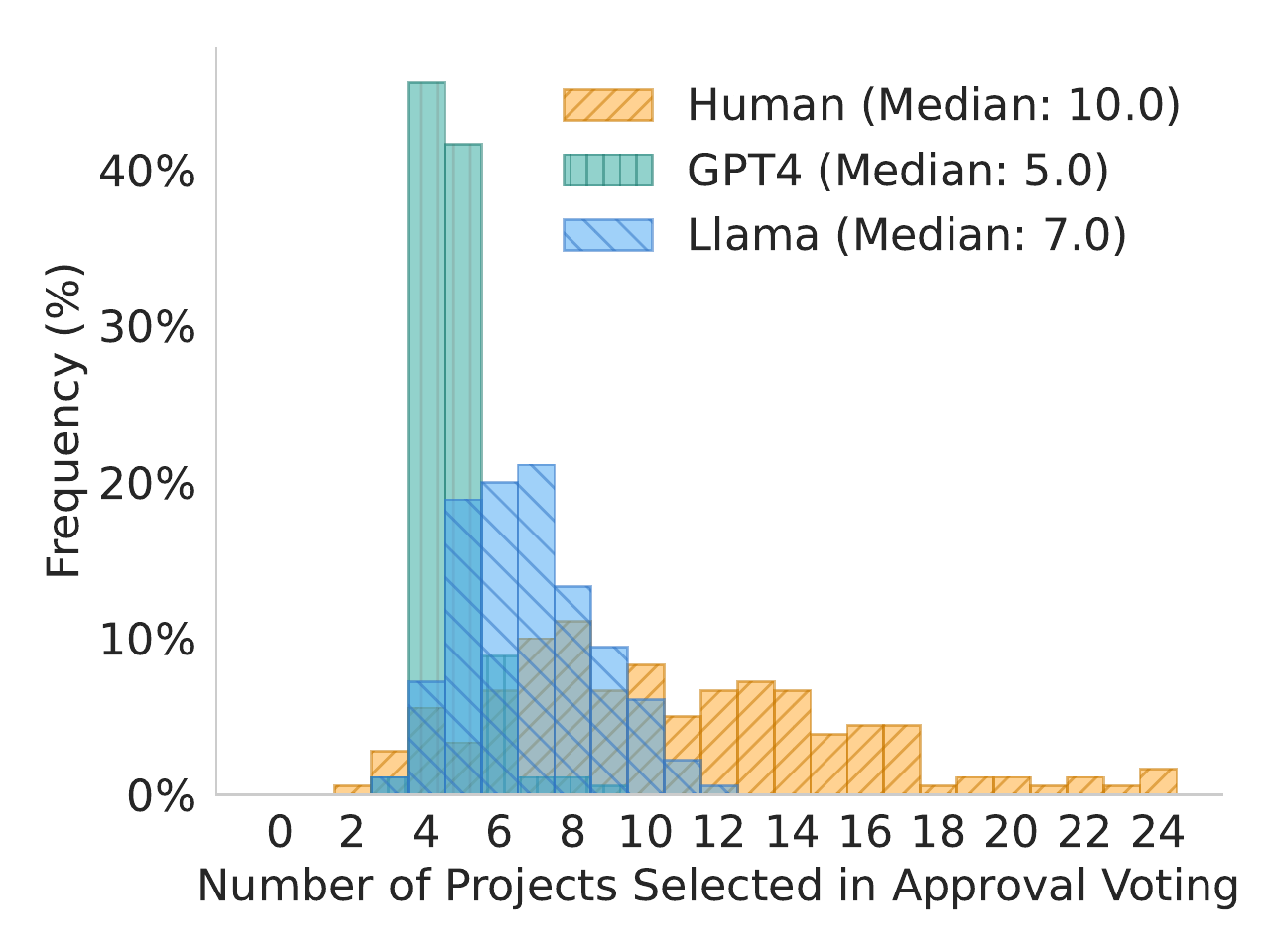
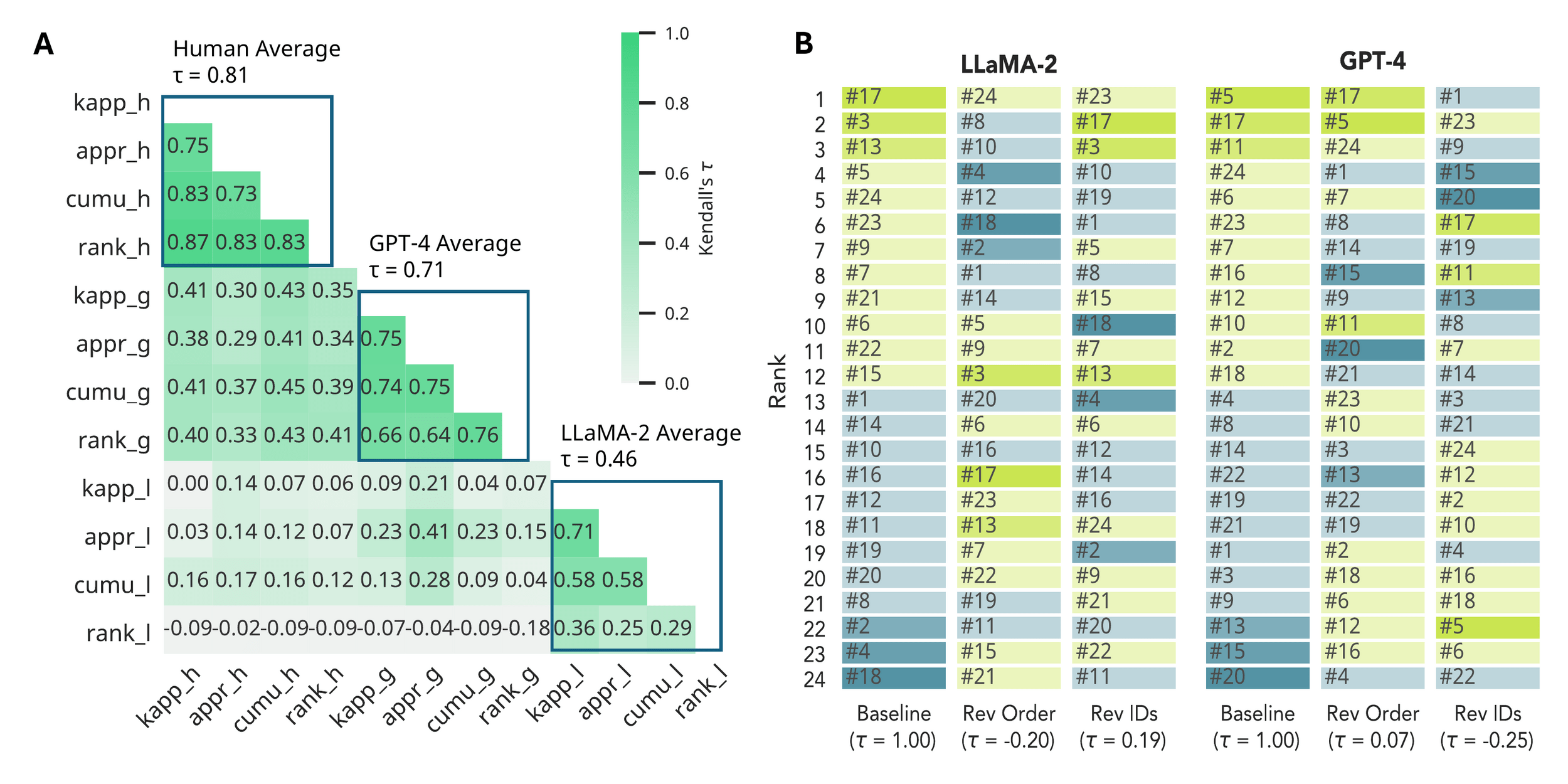
Social choice theory studies the aggregation of individual preferences into collective decisions.
No voting system can satisfy all four conditions at once
Every rule makes normative commitments (e.g. utilitarian, egalitarian, maximin) and those commitments can be made explicit and compared.
.
.
.
.
.
.
Initial Language Model
.
.
.
.
.
.
Reward Preference Model
.
.
.
.
.
.
Tuned Language Model
Reinforcement Learning Update
Working Paper
5 AI labs
9 flagship documents
2–3 docs per lab
~150k words, 900 pages overall
2018–2026
mix of technical papers and programmatic blog posts
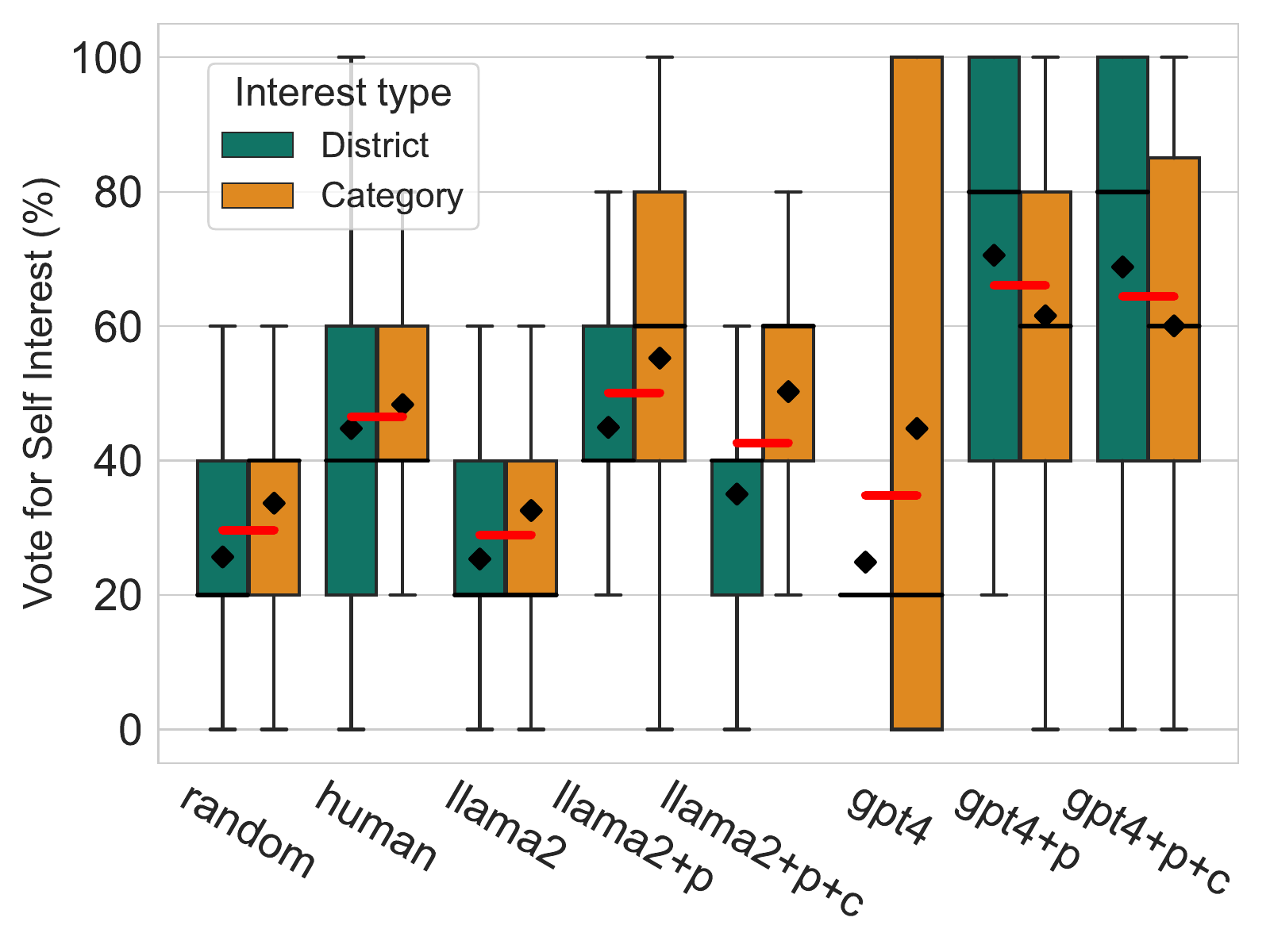
Minimize share below harm threshold, then maximize \( \sum_i f(u_i) \), \( f' > 0 \), \( f'' < 0 \).
Constrained utilitarianism with safety floor,
maximize \( \frac{1}{|I_m|} \sum_{i \in I_m} u_i(m) \).
Plain utilitarianism:
maximize \( \frac{1}{|I_m|} \sum_{i \in I_m} u_i(m) \).
Group maximin: \( W(m) = \min_g U_g(m) \) over
demographic groups \( g \).
Config-robust: over configurations \( \theta \in \Theta \), use \( \min_{\theta \in \Theta} W(m \mid \theta) \) or its average.
Kirk et al. (2024)
Terrible
Perfect
100
0
Ask, request, or talk to the model about anything. It is up to you!
.
.
.
.
.
.
Terrible
Perfect
100
0
Minimize share below harm threshold, then maximize \( \sum_i f(u_i) \), \( f' > 0 \), \( f'' < 0 \).
Constrained utilitarianism with safety floor,
maximize \( \frac{1}{|I_m|} \sum_{i \in I_m} u_i(m) \).
Plain utilitarianism:
maximize \( \frac{1}{|I_m|} \sum_{i \in I_m} u_i(m) \).
Group maximin: \( W(m) = \min_g U_g(m) \) over
demographic groups \( g \).
Config-robust: over configurations \( \theta \in \Theta \), use \( \min_{\theta \in \Theta} W(m \mid \theta) \) or its average.
User 1
x
x
x
User 1
x
x
x
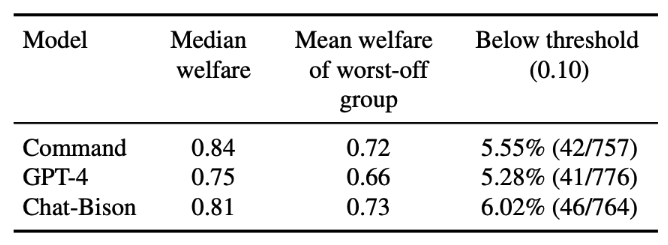
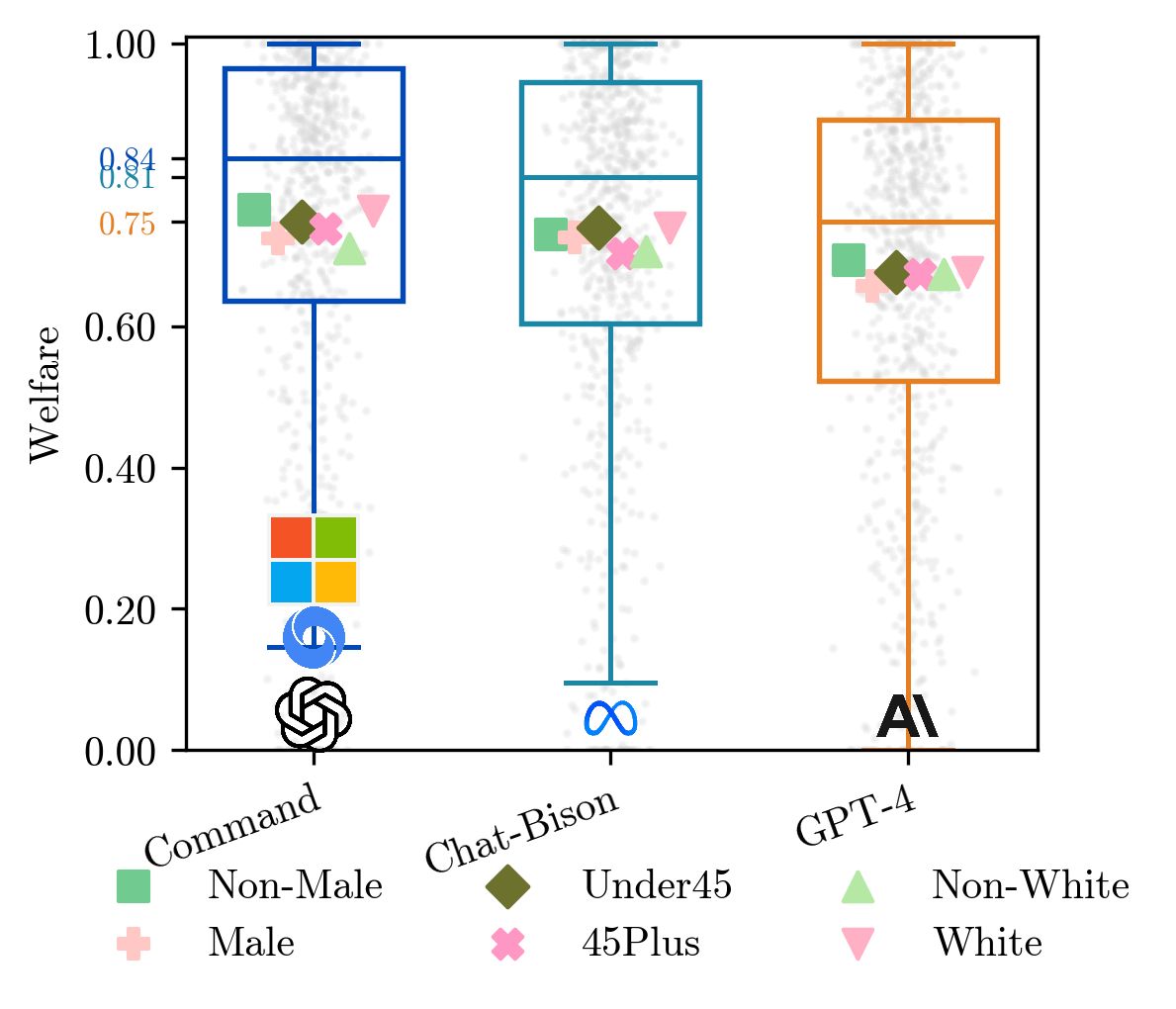
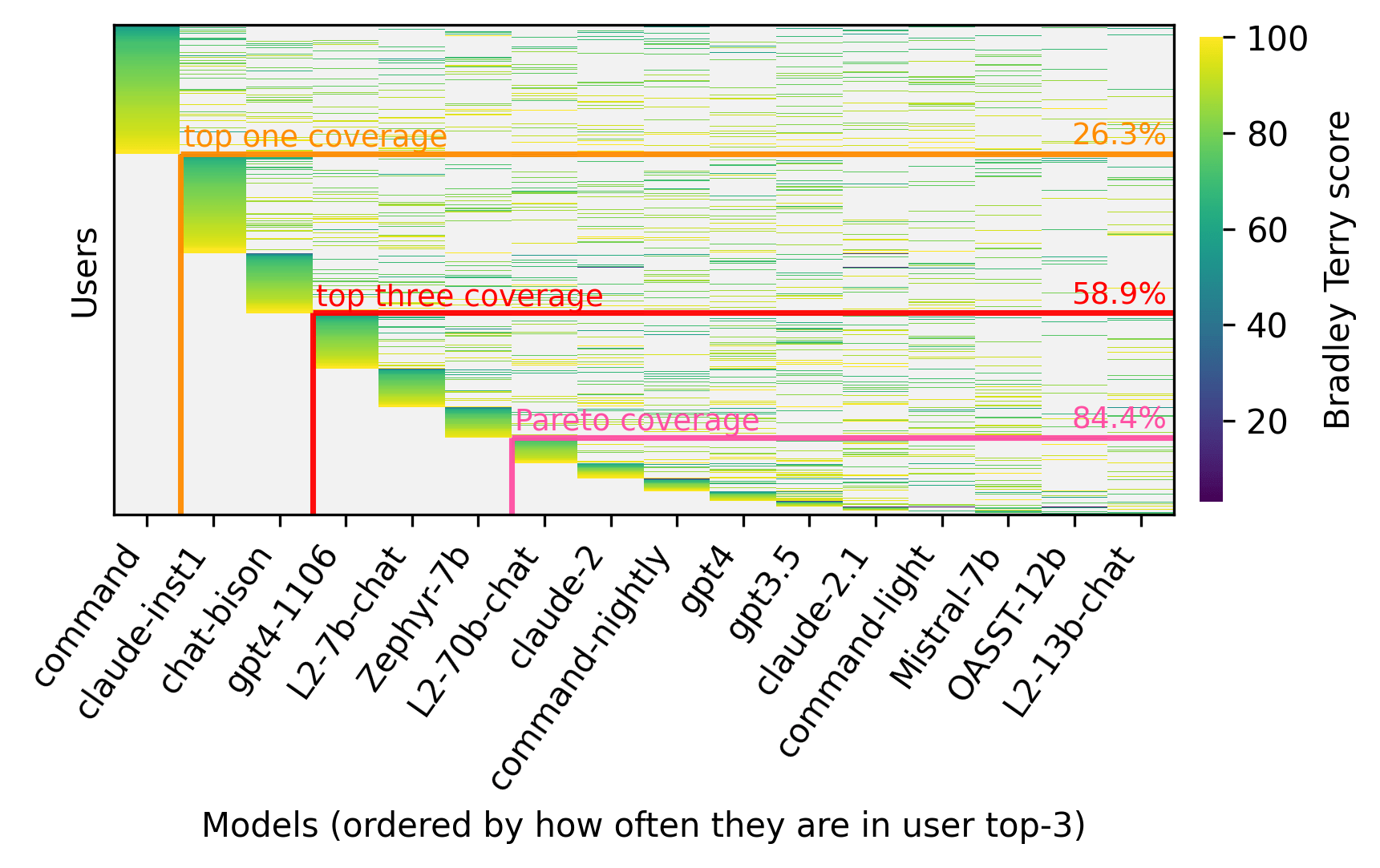
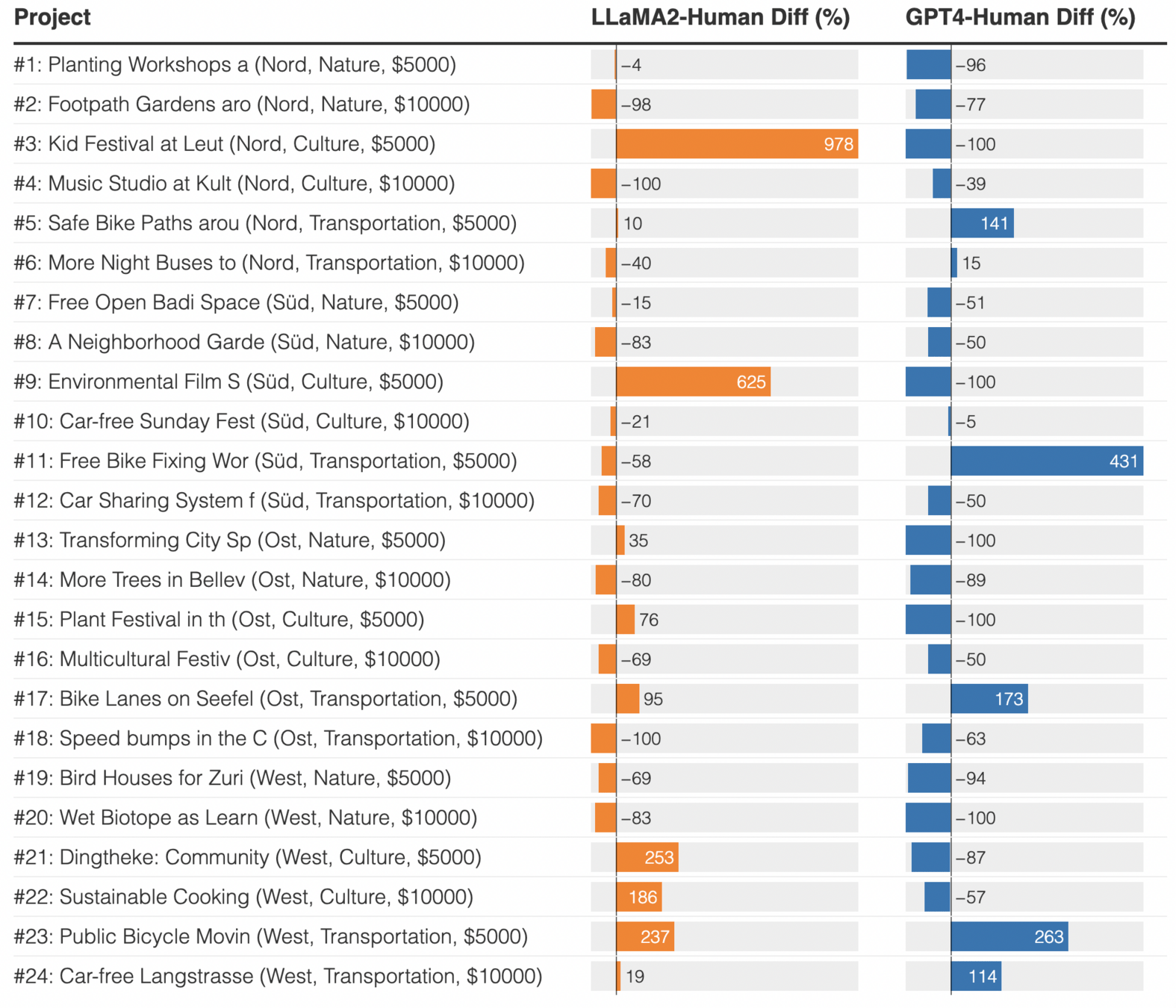
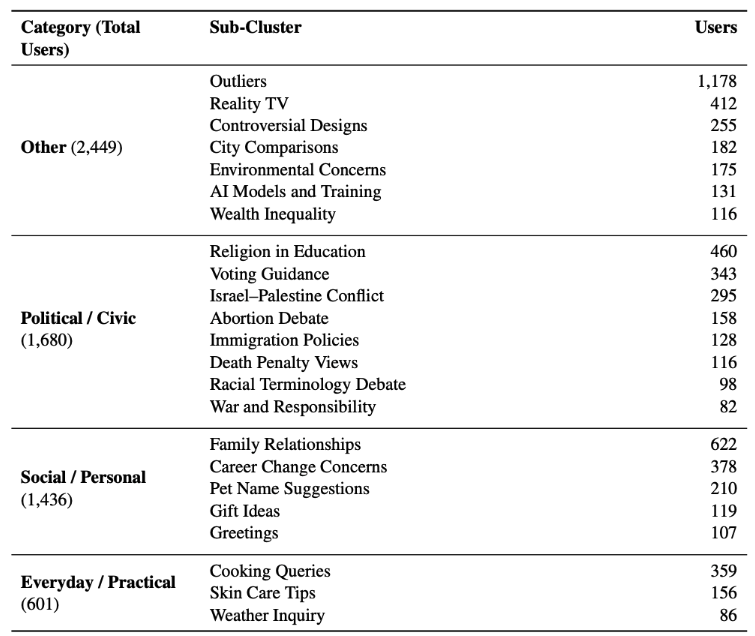
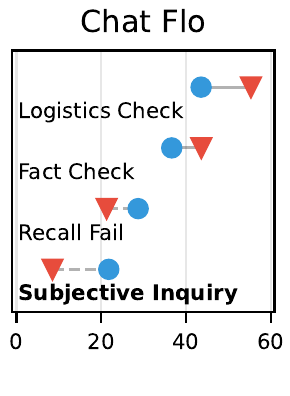
Only 26.3% of users rank command somewhere in their top 3.
Six models would need to be deployed to achieve Pareto-optimal coverage of 80% of users' top 3 preferences
In social choice theory, multi-winner elections form a key subclass of aggregation methods.
Those could guide the optimal number of models deployed.
Ask, request, or talk to the model about anything. It is up to you!
.
.
.
.
.
.
Terrible
Perfect
100
0
AAAI/ACM Conference on AI, Ethics, and Society 2024
human centeredparticipation
information
participation
information
information
VR support is hard to scale.
information
participation
Information was treated as given.
information
participation
Can we integrate both?
How can we keep the immersive parts of VR but make it scalable?
Preprint
information
participation
information
participation
information
participation
information
participation
information
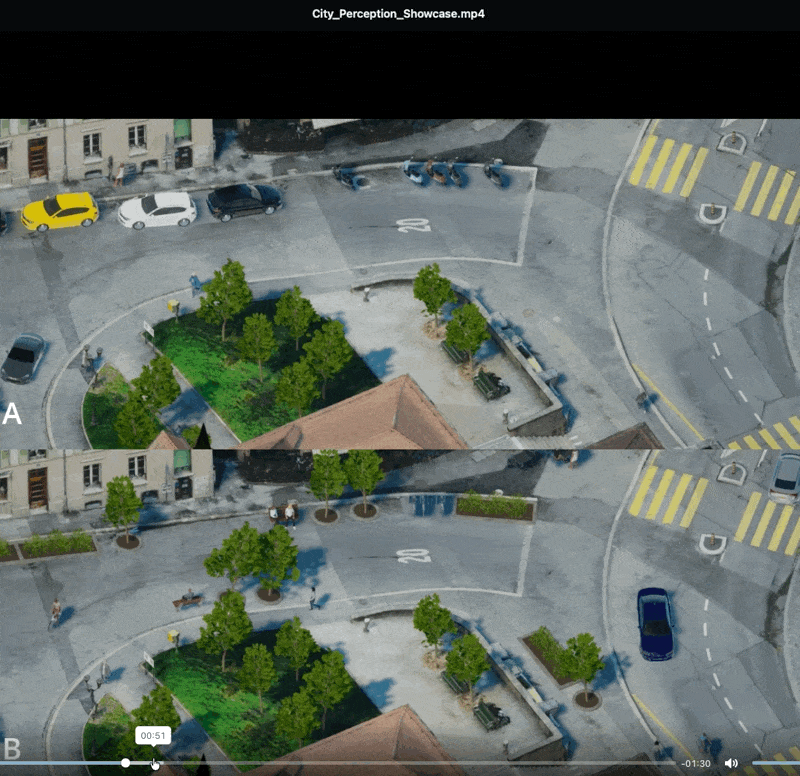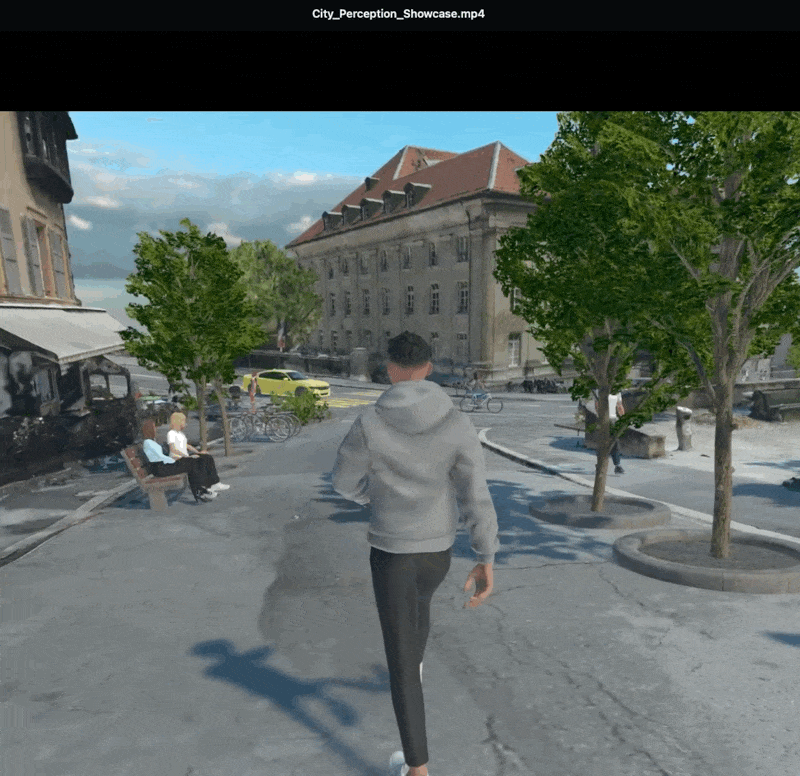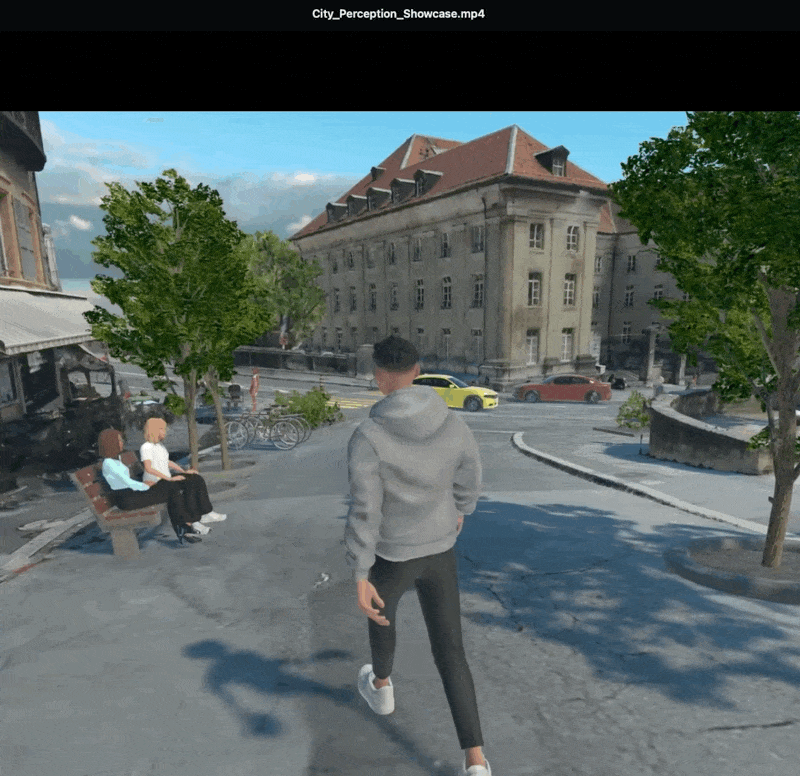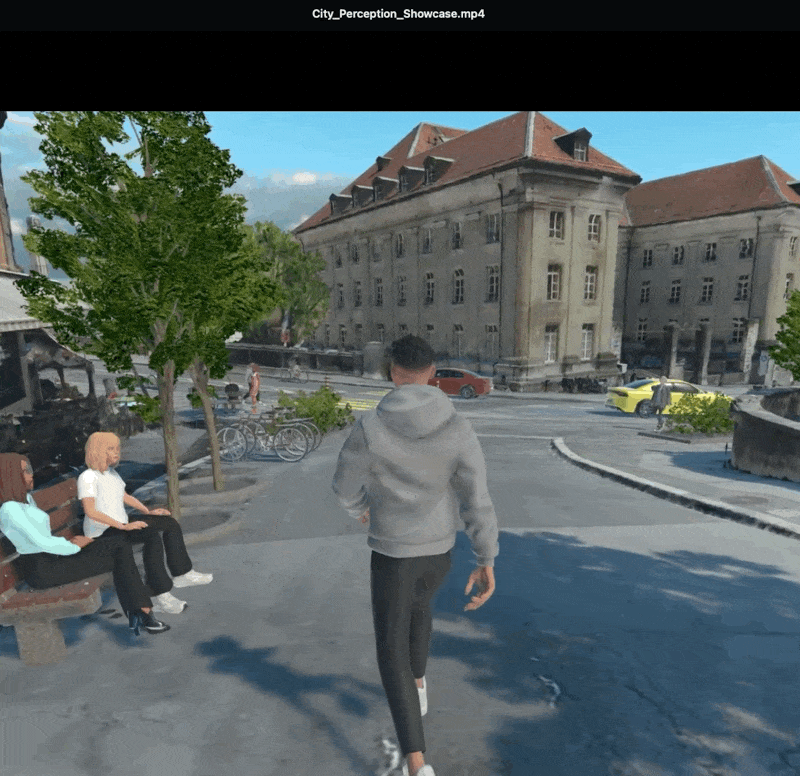
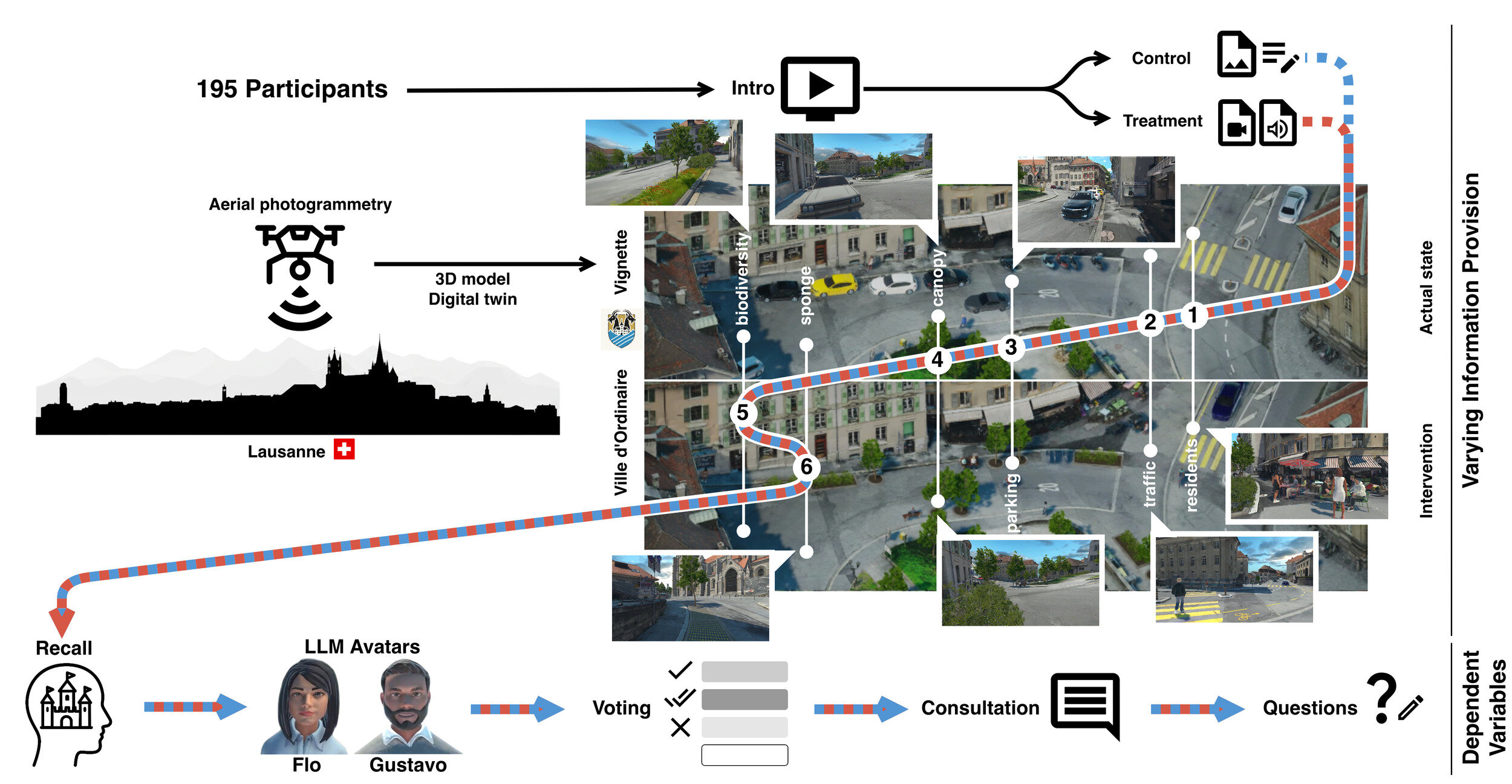
Contextual boundaries (e.g. walking through a doorway) chunk experience into discrete units, improving retention.
Information situated in a structured environment is recalled better than free-floating text.
Verbal and visual channels presented together encode more reliably than either alone.
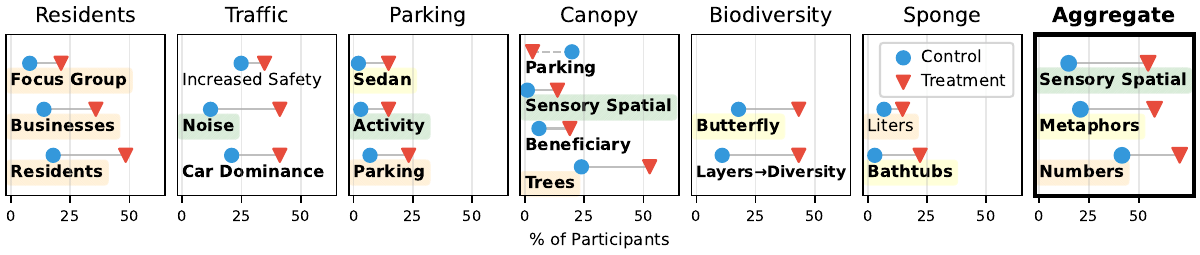
The narrator described the porous pavement as capable of holding several thousand litres of rainwater — "roughly ten bathtubs full". Treatment participants remembered the bathtubs.
A citizen who has just spent ten minutes mentally walking down the redesigned street has a richer cognitive scaffold for the conversation that follows.
With well-prepared interlocutors, the model becomes a better servant — lighter, more responsive, more useful as a thinking partner than as an oracle.
"Fruit trees can turn the area into a meeting place… for strangers to share a fruit."
"Family events… bringing together all of the different generations." "Brotherhood and unity among residents."
"You aren't going to be able to bring tons of fresh, cooled produce on the back of a bike."
"A big cash pay-out may give me some compensation", or simply, "a parking space near my home."
"Are the newly planted trees well-rooted? Urban trees often fail because their roots don't take."
"Will there be services for leaf pickup and gardening?"
"installation of sun sails", "luxuries like swimming pools".
"removal of parking spaces will destroy local business"; "a 15-min city does not work".
Recall changes the quality of citizens' feedback. From "compensate me for the parking" to "have you thought about leaf pickup".
human centeredcarina.hausladen@uni-konstanz.de
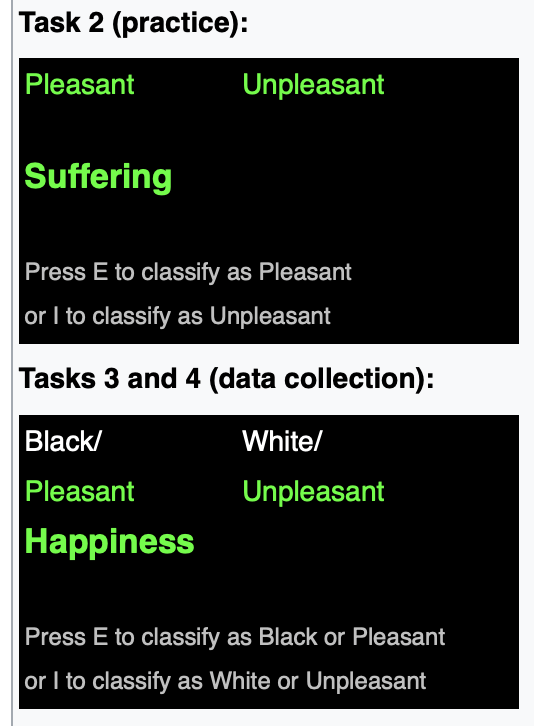
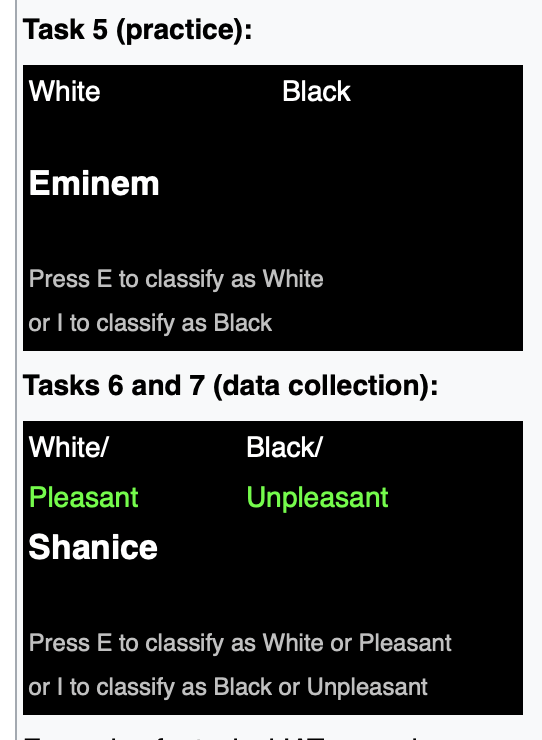
Greenwald, McGhee & Schwartz 1998
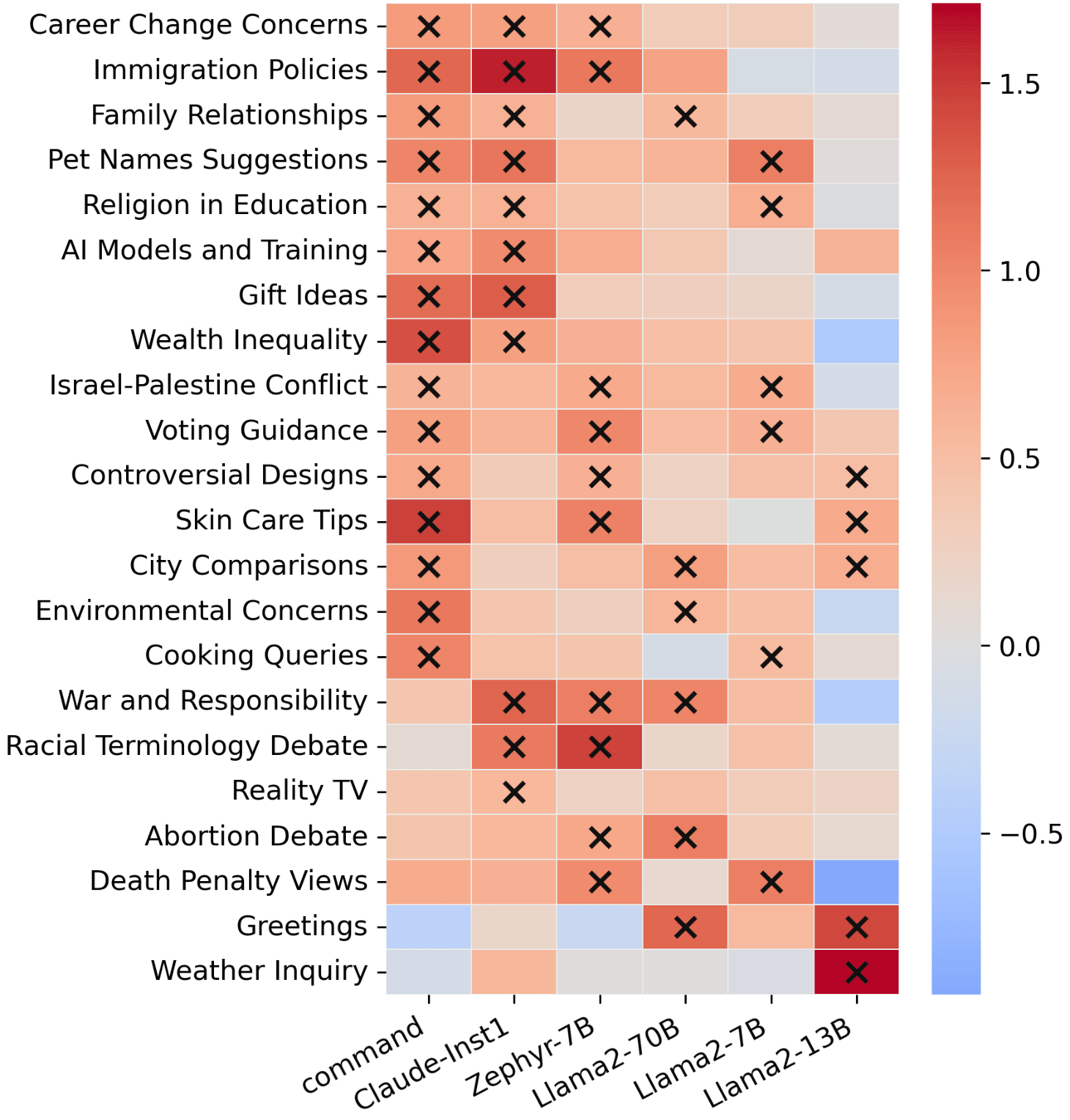
Flagship alignment documents
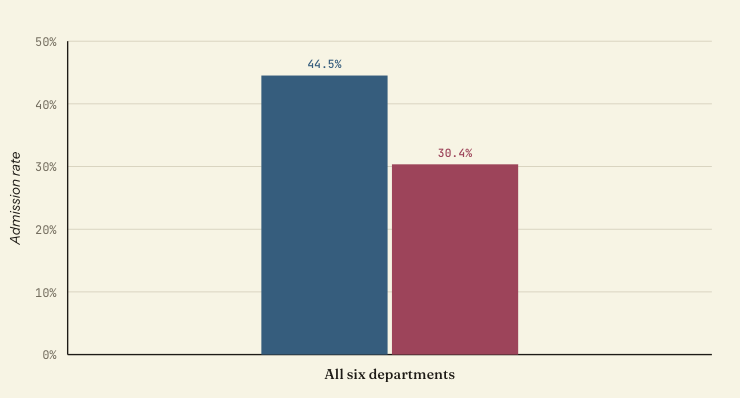
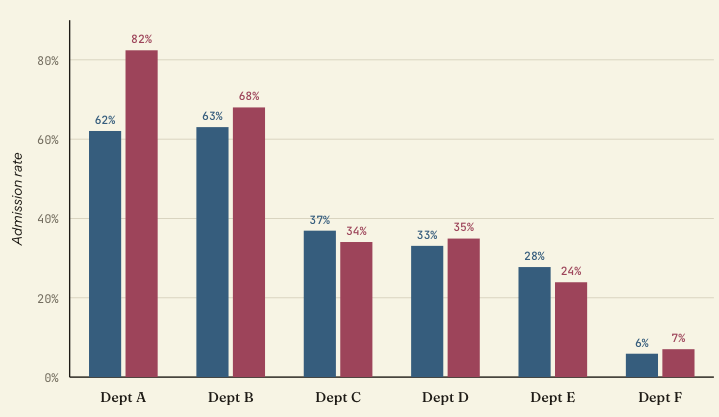
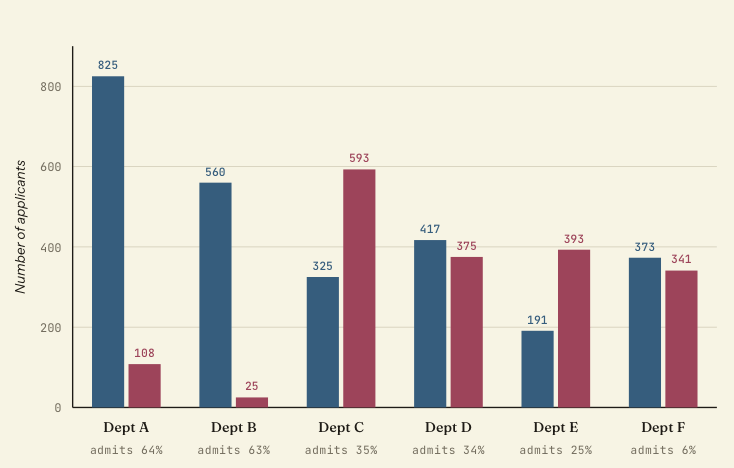
UC Berkeley graduate admissions, fall 1973
By Carina Ines Hausladen



