data-driven simulation-based galaxy evolution


Harvard CfA --- Dec 6, 2019
ChangHoon Hahn
arXiv:1809,01665
arXiv:1910.01644
everything we've learned so far from galaxy surveys
... in 30 sec
* about massive galaxies at z<2
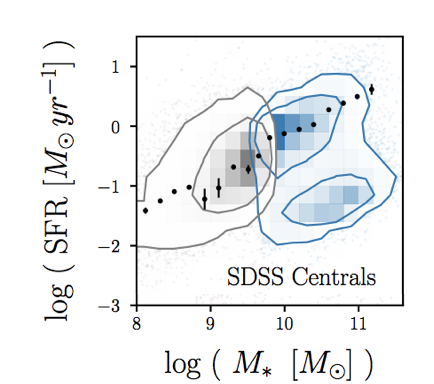
galaxies broadly fall into two categories

star forming galaxies
late-type, disk-like, blue

quiescent galaxies
early-type, elliptical, red
PRIMUS
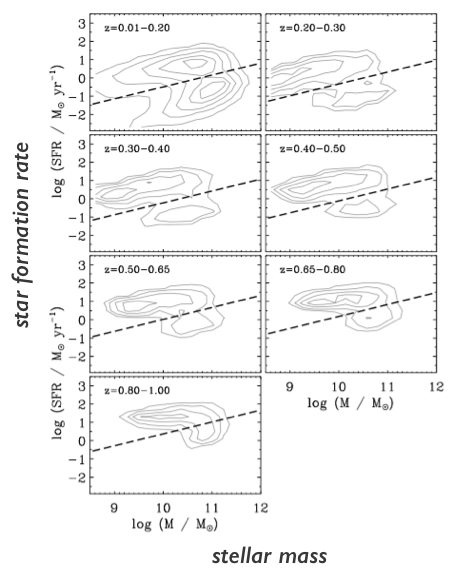
star-forming galaxies lie on the star-forming sequence
Hahn+(2019a)
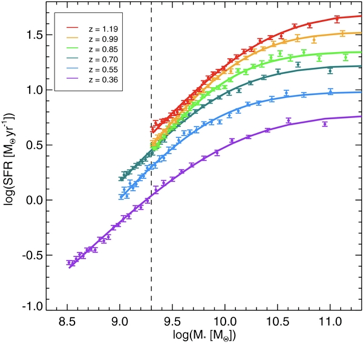
overall decline in star formation over time
Lee+(2015)
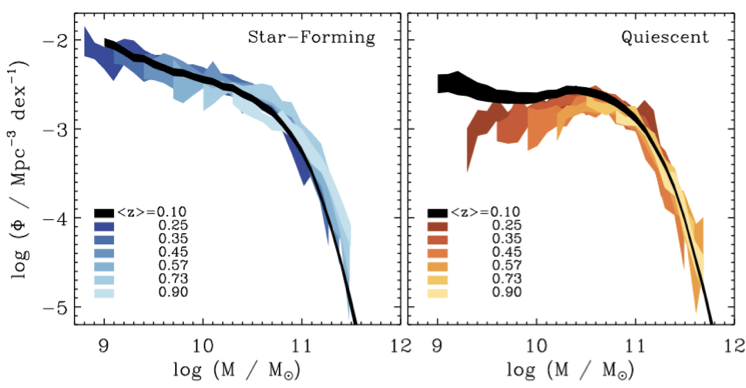
fewer massive star-forming galaxies
more quiescent galaxies over time
Moustakas+(2013)
PRIMUS
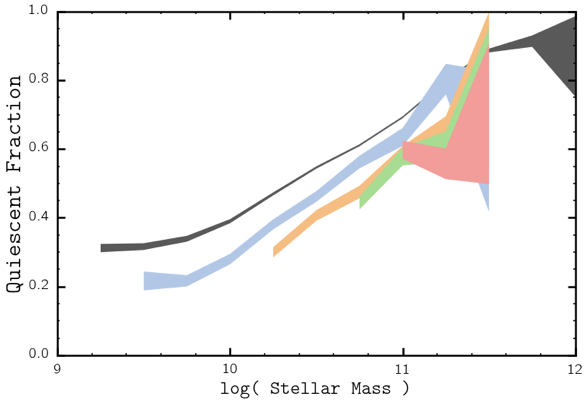
log (stellar mass)
quiescent fraction
SDSS z~0
PRIMUS z~0.9
star formation quenching
how well do state-of-the-art galaxy formation models reproduce these relations?
credit: Illustris TNG

Isolated and Quenched Collaboratory
logo credit: Claire Dickey
https://iqcollaboratory.github.io/
Tjitske Starkenburg, Shy Genel , Christopher Hayward, Rachel Somerville (CCA), Ariyel Maller (CUNY), Ena Choi (KIAS), Jeremy Tinker (NYU), Romeel Davé (ROE), Alyson Brooks(Rutgers), John Moustakas (Sienna), Viraj Pandya (UCSC), Mika Rafieferantsoa(UWC), Claire Dickey, Marla Geha (Yale), Andrew Emerick (Carnegie) ...
original goal: comparing quiescent & central galaxies in sims and observations
Isolated and Quenched Collaboratory
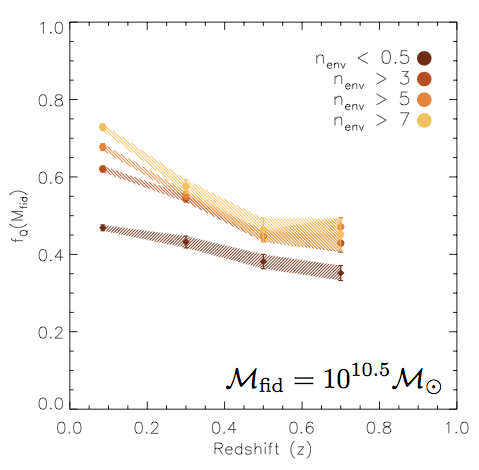
quiescent fraction
at log M* = 10.5
Hahn+(2015); PRIMUS
redshift
centrals: majority of M∗ > 109.5M⊙ galaxies at z = 0
focus on internal quenching mechanisms
Isolated and Quenched Collaboratory
logo credit: Claire Dickey
https://iqcollaboratory.github.io/
current goal: data-driven "apples-to-apples" comparisons of galaxy populations across sims and observations
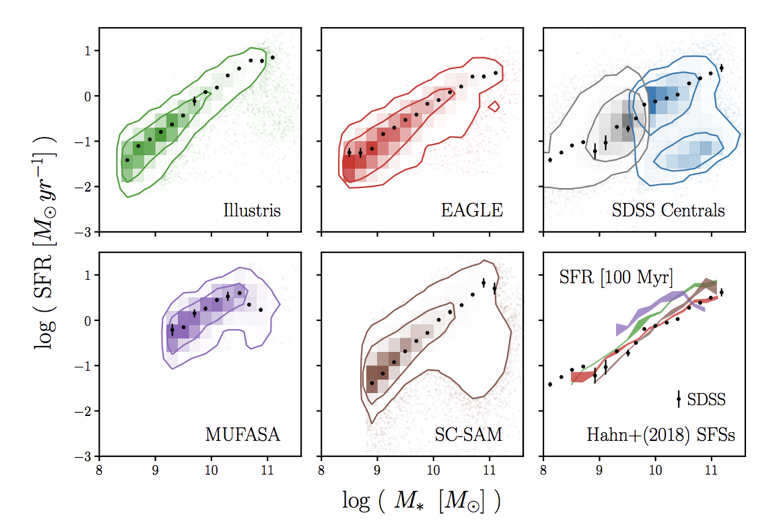
simulations all produce the star-forming sequence (SFS)
Hahn+(2019a)
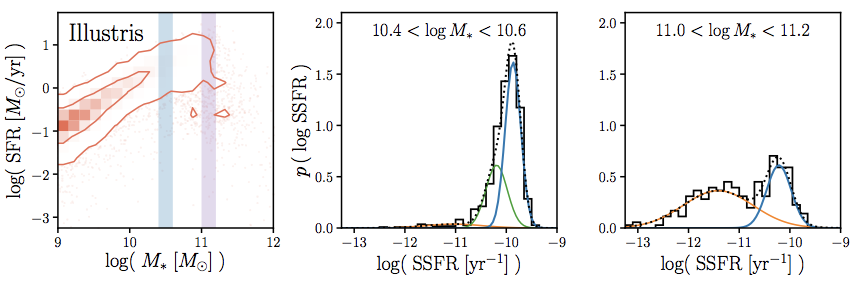
data-driven GMM-based method for identifying the
star-forming sequence
Hahn+(2019a)
out to higher redshifts
Choi, CH+(in prep)
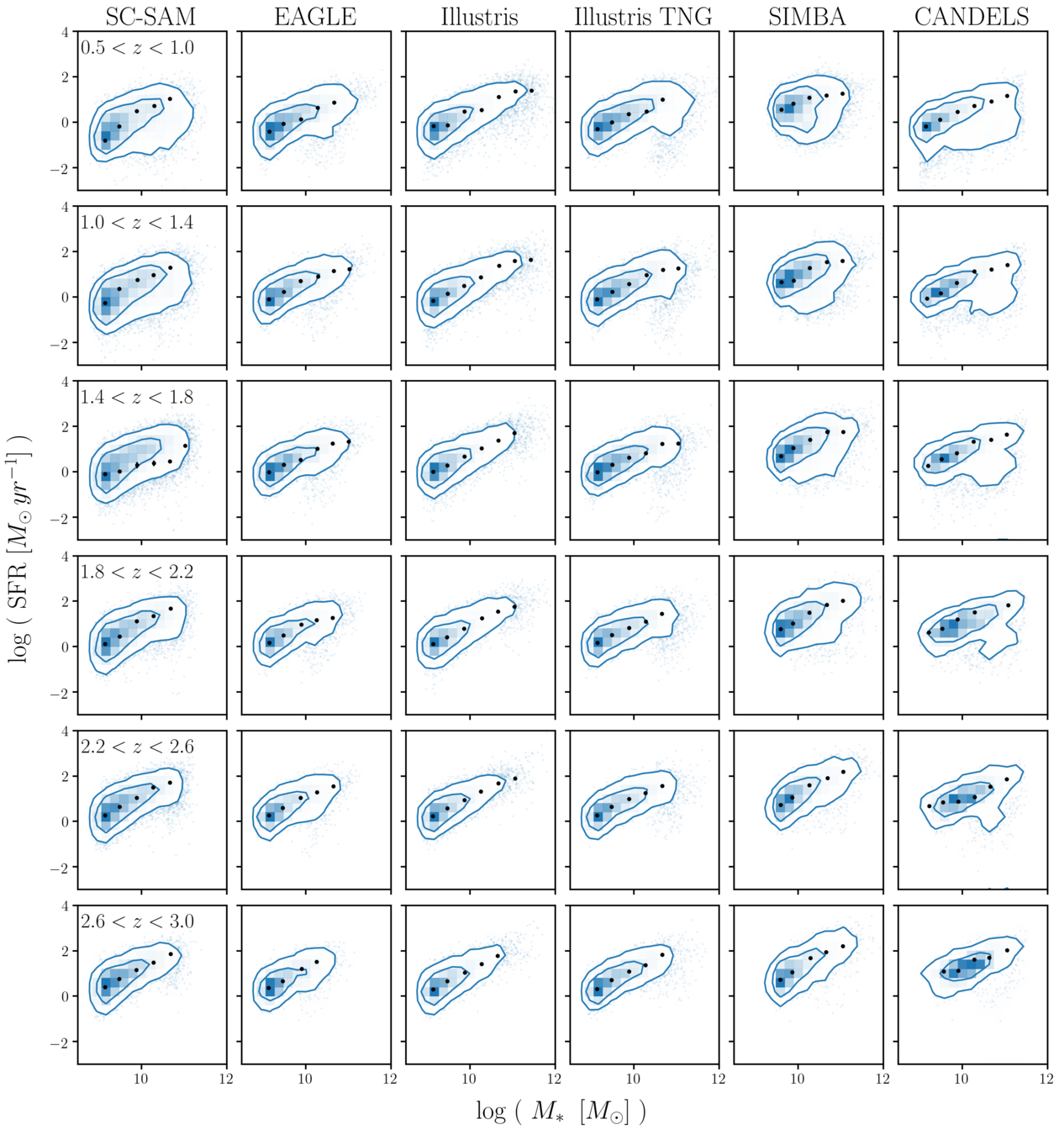
Choi, CH+(in prep)
*...don't worry about SC-SAM
they also reproduce the SFS z evolution
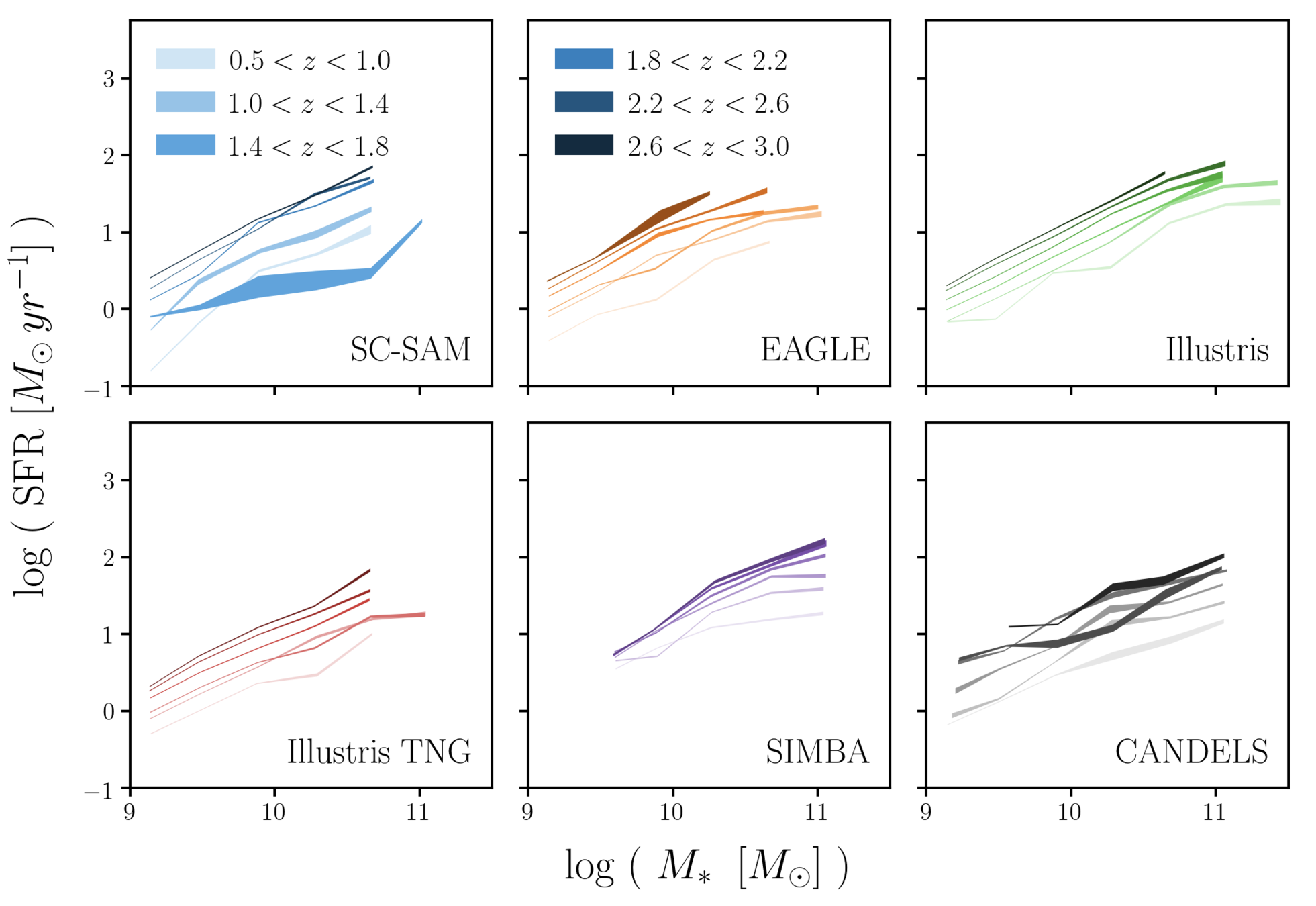
SFS in simulations differ by ~5x at z=0
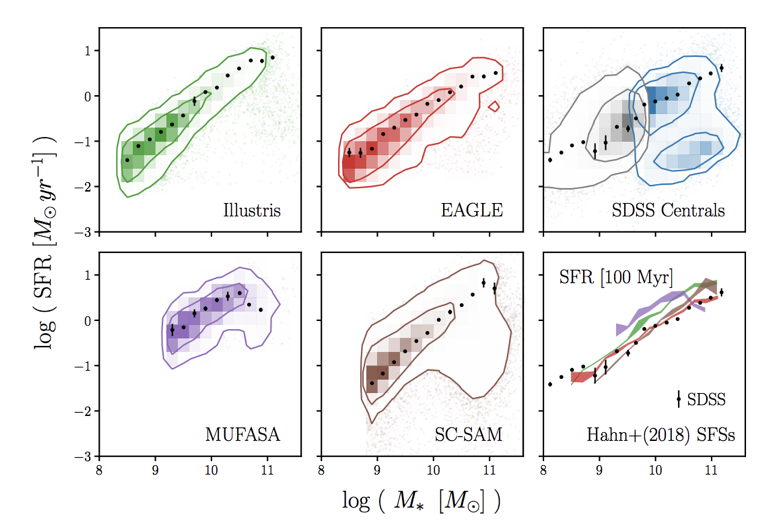
Hahn+(2019a)
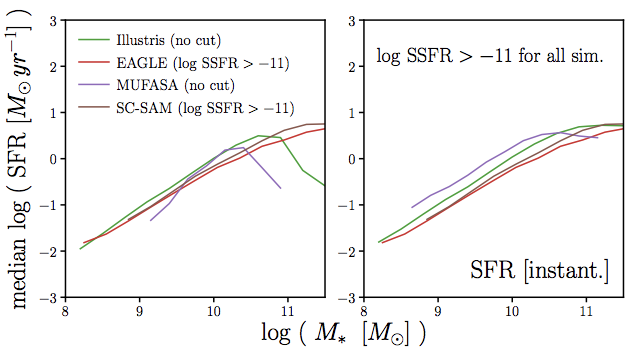
same methods as Somerville & Davé (2015)
why we need data-driven methods
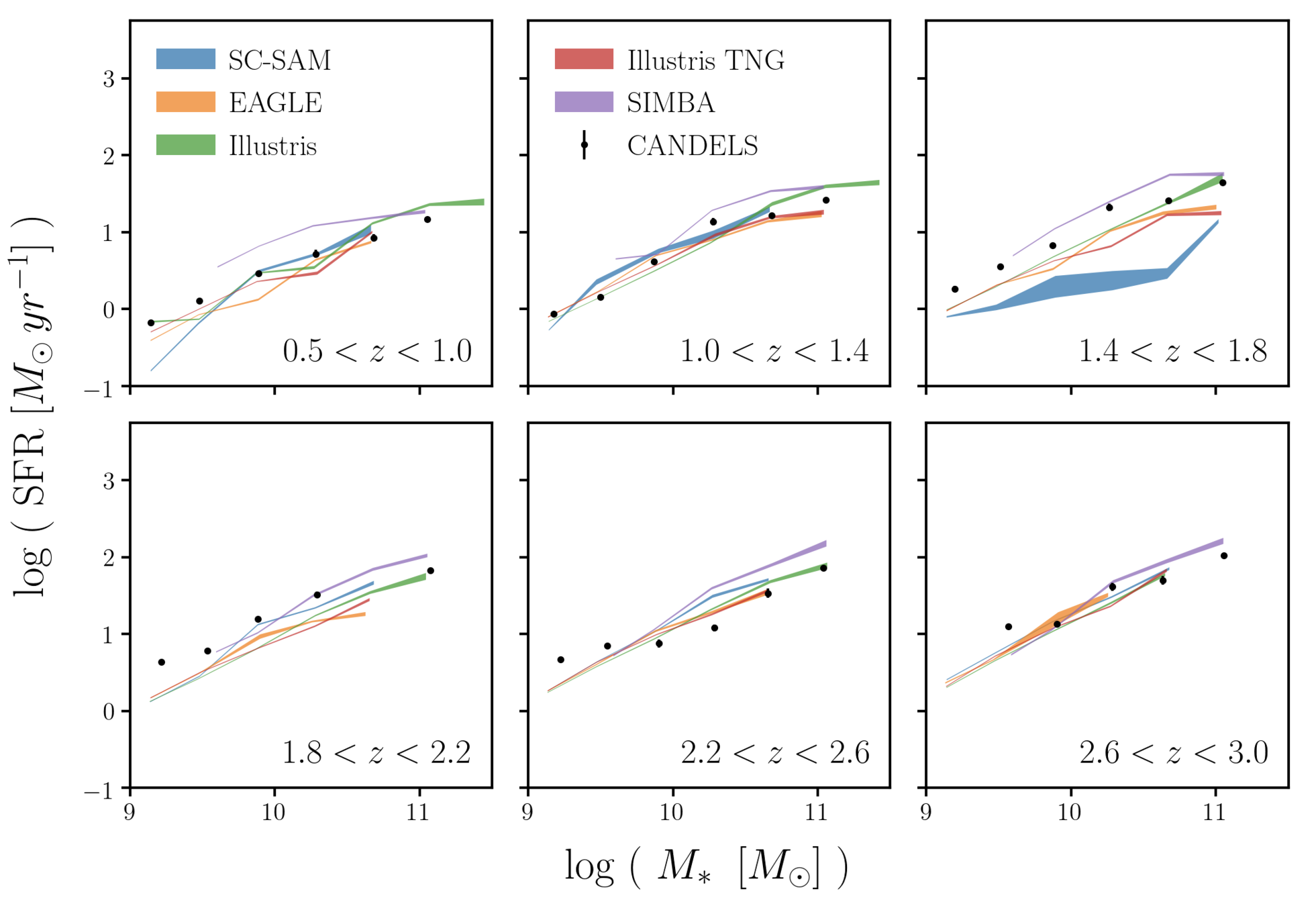
SFS in simulations also differ at z > 0.5
Choi, CH+(in prep)
smaller discrepancies at higher z
differences among simulations beyond the SFS
Hahn+(2019a)
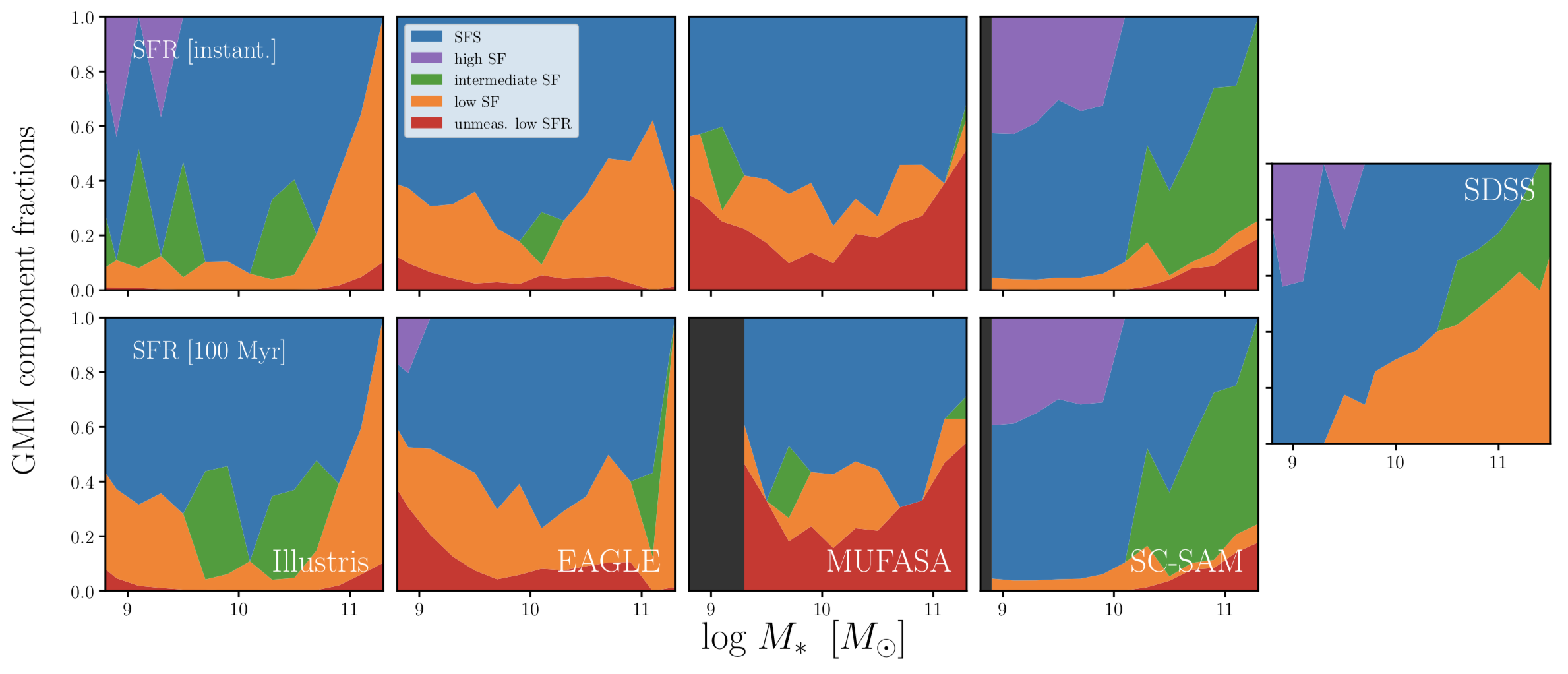
significant quiescent fraction at M*<109M⊙
Q: what's causing these large SFS discrepancies?
why are there quiescent low mass galaxies?

A: must be...
splashback/backsplash/ejected!
resolution limit of hydro sims!
lesson: hydro sims are hard to interpret
empirical models: ΛCDM + observed evolution of galaxies
credit: Wechsler & Tinker (2018)
computationally cheap
easy to interpret
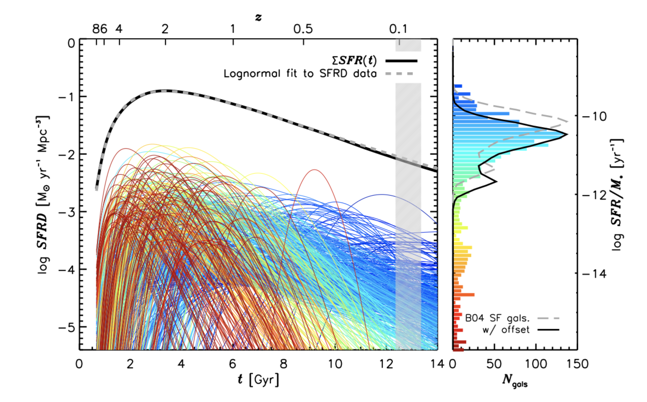
Abramson+(2015, 2016)
claim: loosely constrained log-normal SFH can reproduce SMF, SFS, etc. at z<6

they get stellar masses from the star formation histories but ...what about the stellar-to-halo mass relation?
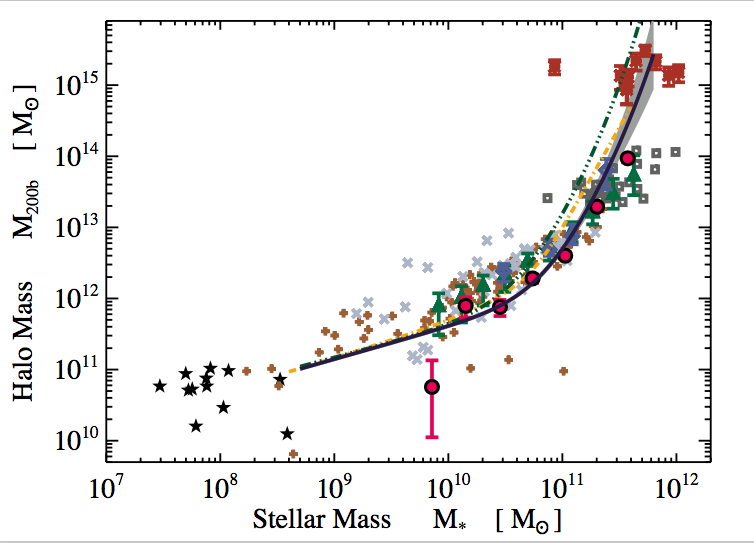
credit: Alexie Leauthaud
for star forming central galaxies
the connection between star formation histories and stellar masses constrained by star forming sequence
the stellar-to-halo mass relation constrains the connection between stellar masses and halo mass
we can constrain star formation histories using the
star-forming sequence and stellar-to-halo mass relation!
star-forming centrals initialized using SMF and SFS at z~1
M* from subhalo-halo abundance matching to SMF
SFR from SFS with 0.3 dex scatter
once quenched always quenched
\log~{\rm SFR}(M_*, t) = \log~{\rm SFR}_{\rm SFS}(M_*, t) + \Delta \log~{\rm SFR}(t)
the connection between star formation histories and stellar masses constrained by star forming sequence
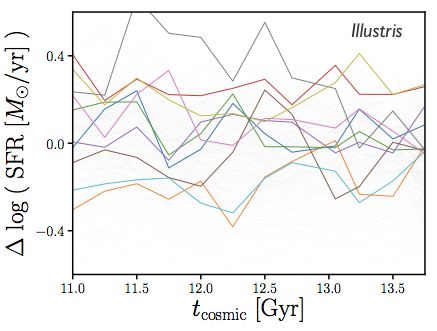
star-forming centrals in Illustris
\log~{\rm SFR}(M_*, t) = \log~{\rm SFR}_{\rm SFS}(M_*, t) + \Delta \log~{\rm SFR}(t)
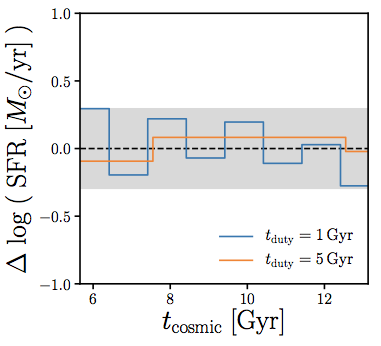
star formation duty cycle: star formation histories that vary on tduty Gyr timescales
M_*(t) \propto \int\limits_{t_0}^{t}{\rm SFR}(M_*, t'){\rm d}t' + M_0
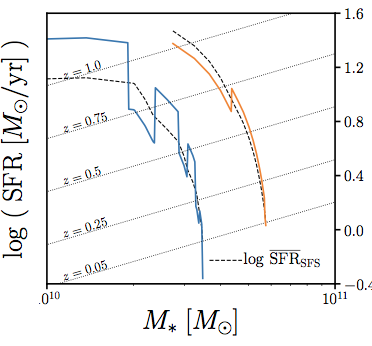
models that reproduce* SMF and SFS at z~0
but have different tduty
*using Approximate Bayesian Computation (more on this later!)
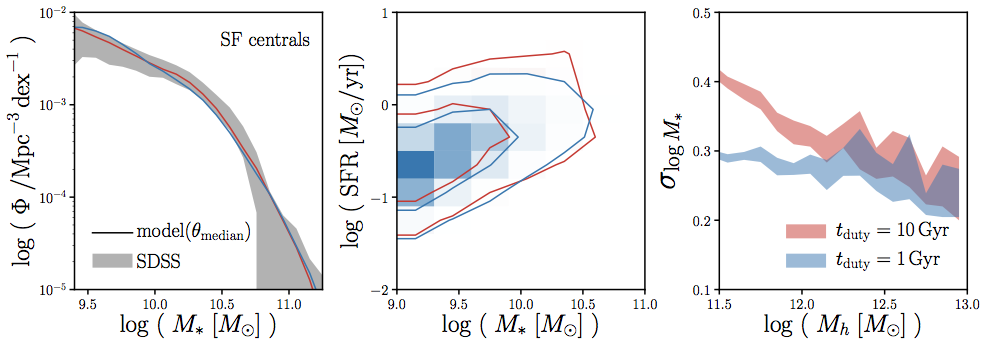
predict different scatter in SHMR
\sigma_{M_*|M_h}
scatter in SHMR at low Mh is sensitive to tduty (i.e. timescale of SF variability)
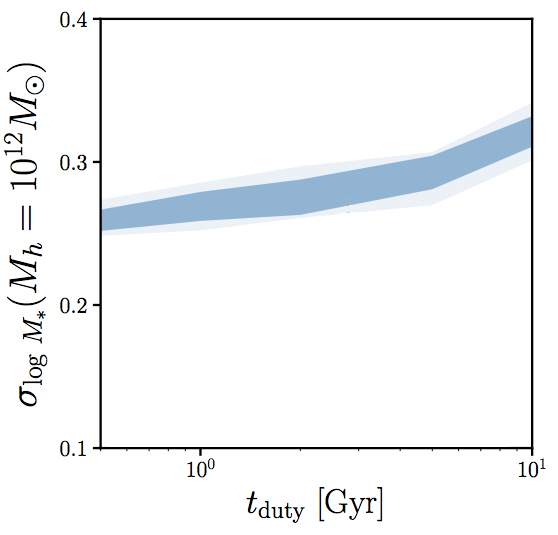
\sigma_{M_*|M_h=10^{12}M_\odot}
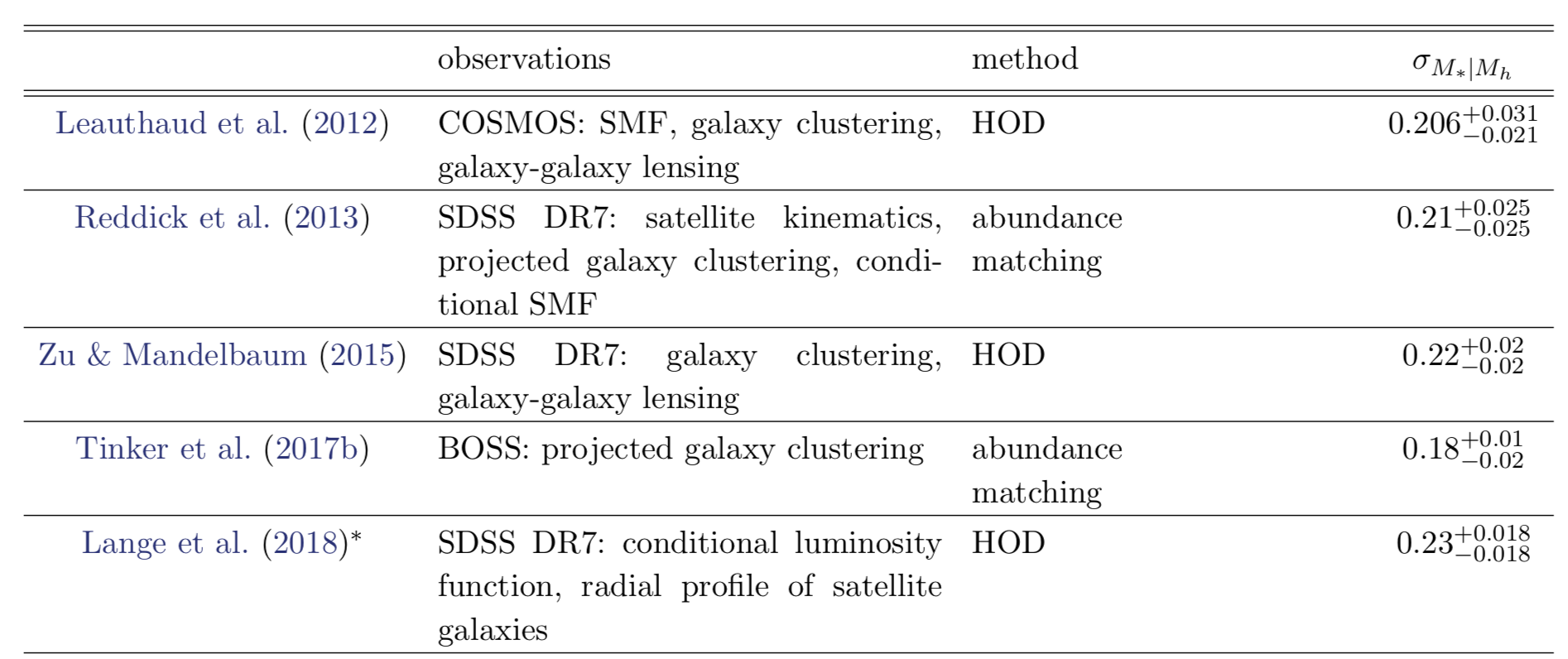
observations find a tight ~0.2 dex scatter in SHMR
\sigma_{M_*|M_h=10^{12}M_\odot}
we add galaxy assembly bias to our model:
star formation histories correlate with Mh history
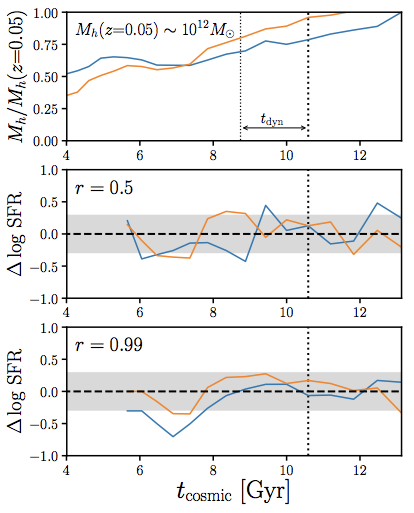
\log~{\rm SFR}(M_*, t) = \log~{\rm SFR}_{\rm SFS}(M_*, t) + \Delta \log~{\rm SFR}(t)
\Delta \log~{\rm SFR}(t)
\Delta M_h(t) = M_h(t) - M_h(t-t_{\rm dyn})
correlated to
similar to Rodríguez-Pubela+(2016), Behroozi+(2019)
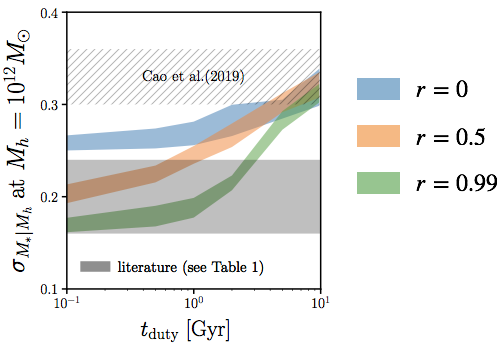
tighter scatter in SHMR for stronger galaxy assembly bias
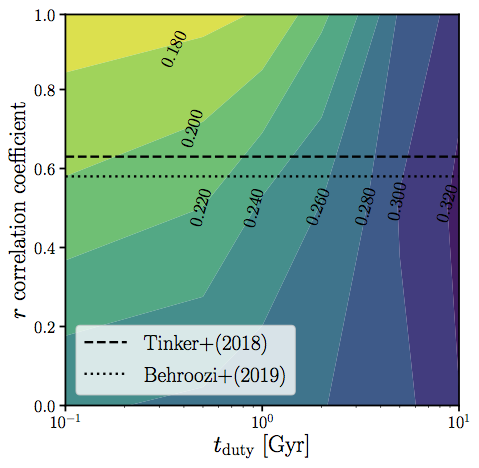
scatter in SHMR sensitive to tduty and rassembly bias
using r~0.6 from literature: tduty < 0.2 Gyr ?
new constraints find larger SHMR >0.3dex scatter

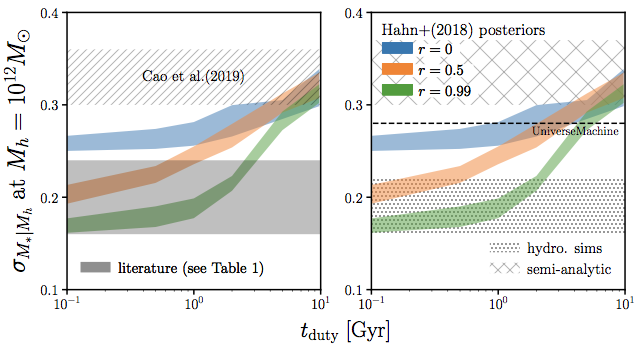
also no consensus among simulations
tight constraint on tduty currently limited by tensions in both observations and simulations
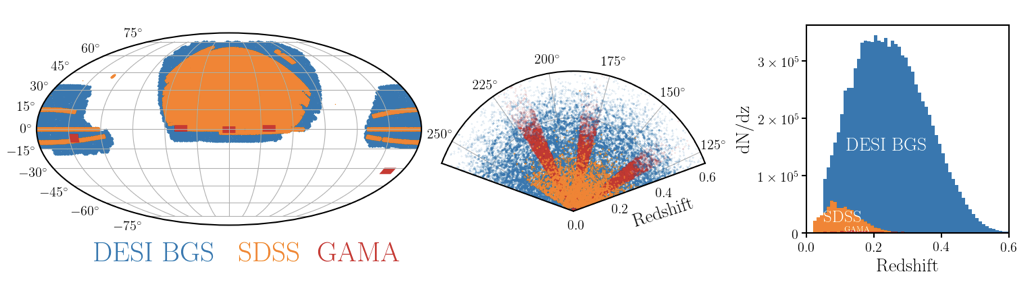
DESI Bright Galaxy Survey
14,000 sq.deg
magnitude-limited to r~20
10 million galaxies
DESI first light!
<1% sky subtraction
the PRObabilistic Value-Added BGS
(PROVABGS)
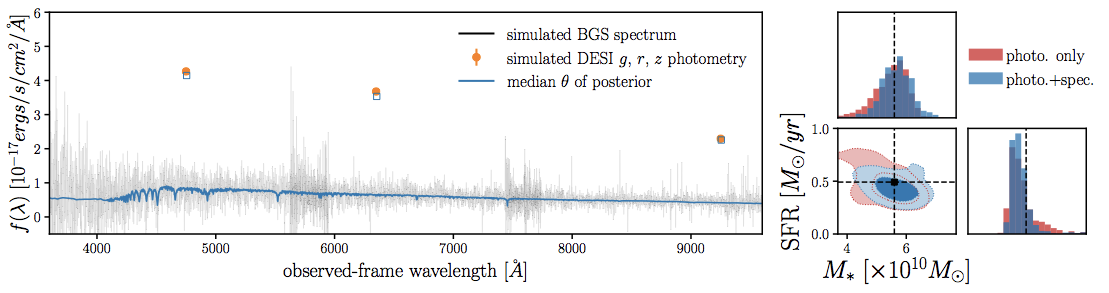
10 million posteriors of galaxy properties from jointly fitting photometry+spectroscopy
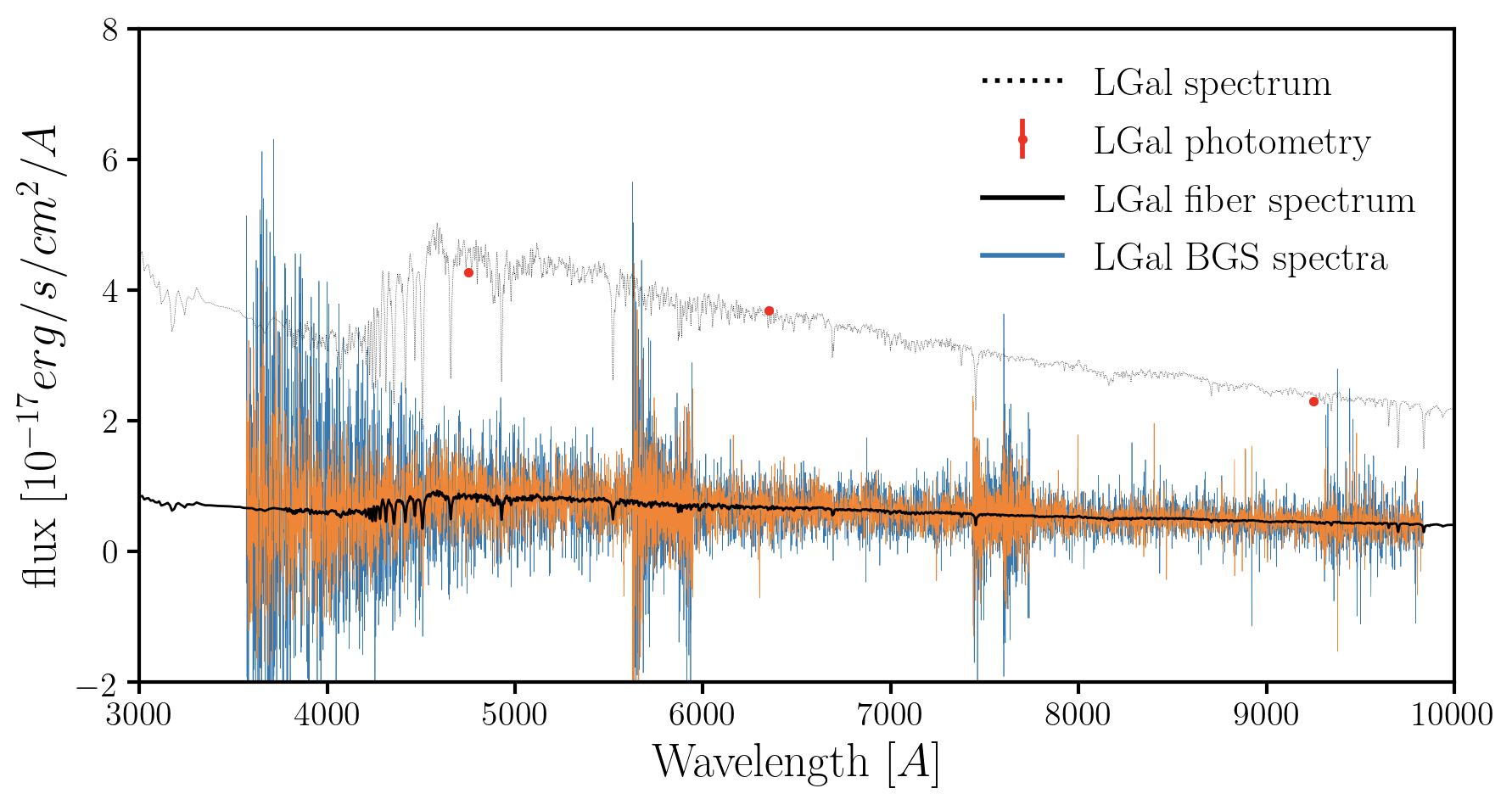
DESI GQP Mock Challenge (MoCha) is currently underway to determine the PROVABGS analysis pipeline
w/ Malgorzata Siudek (IFAE Barcelona), James Kwon (UC Berkeley)
inference using speculator, a PCA neural network SPS emulator
percent-level accuracy and >10,000x faster
Alsing+(2019)
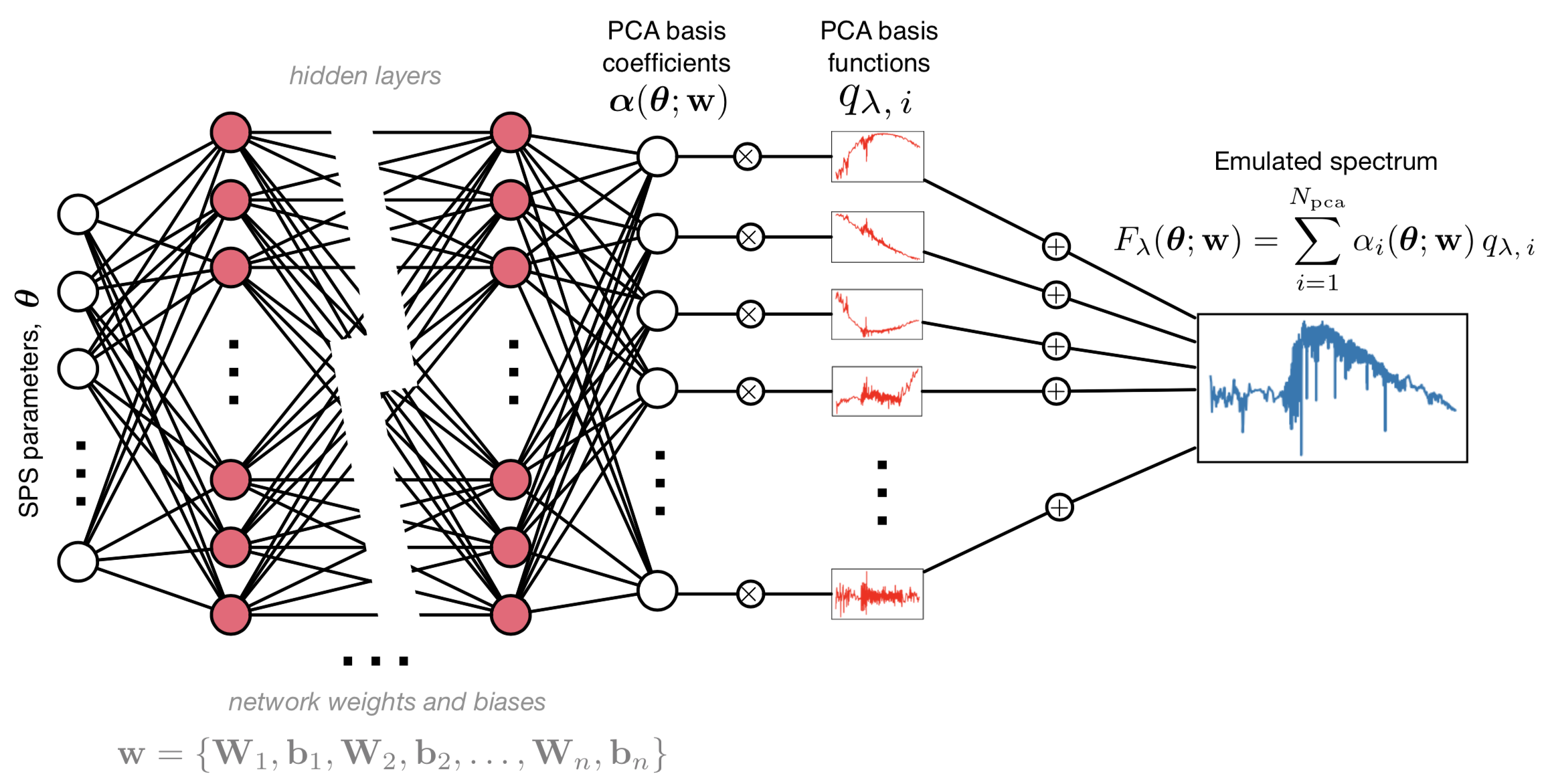
60,000 galaxies --- ~1.5million CPU hours (Leja+2019)
10 million galaxies w/ speculator --- ~24,000 CPU hours
speculator is differentiable (gradient-based inference: HMC, EL2O)
goal: direct inference of galaxy physics from galaxy surveys
simulation-based inference (a.k.a. "likelihood-free")
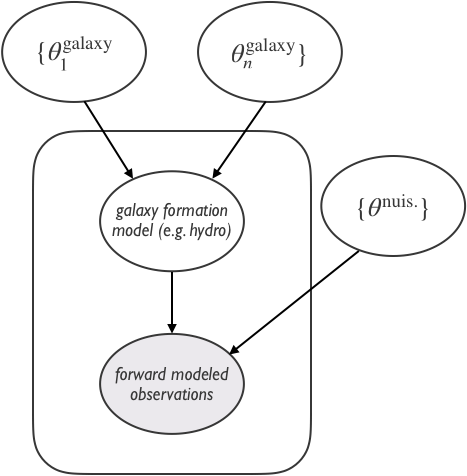
we can forward model observations from simulations
(e.g. IQ collaboratory, MoCha)
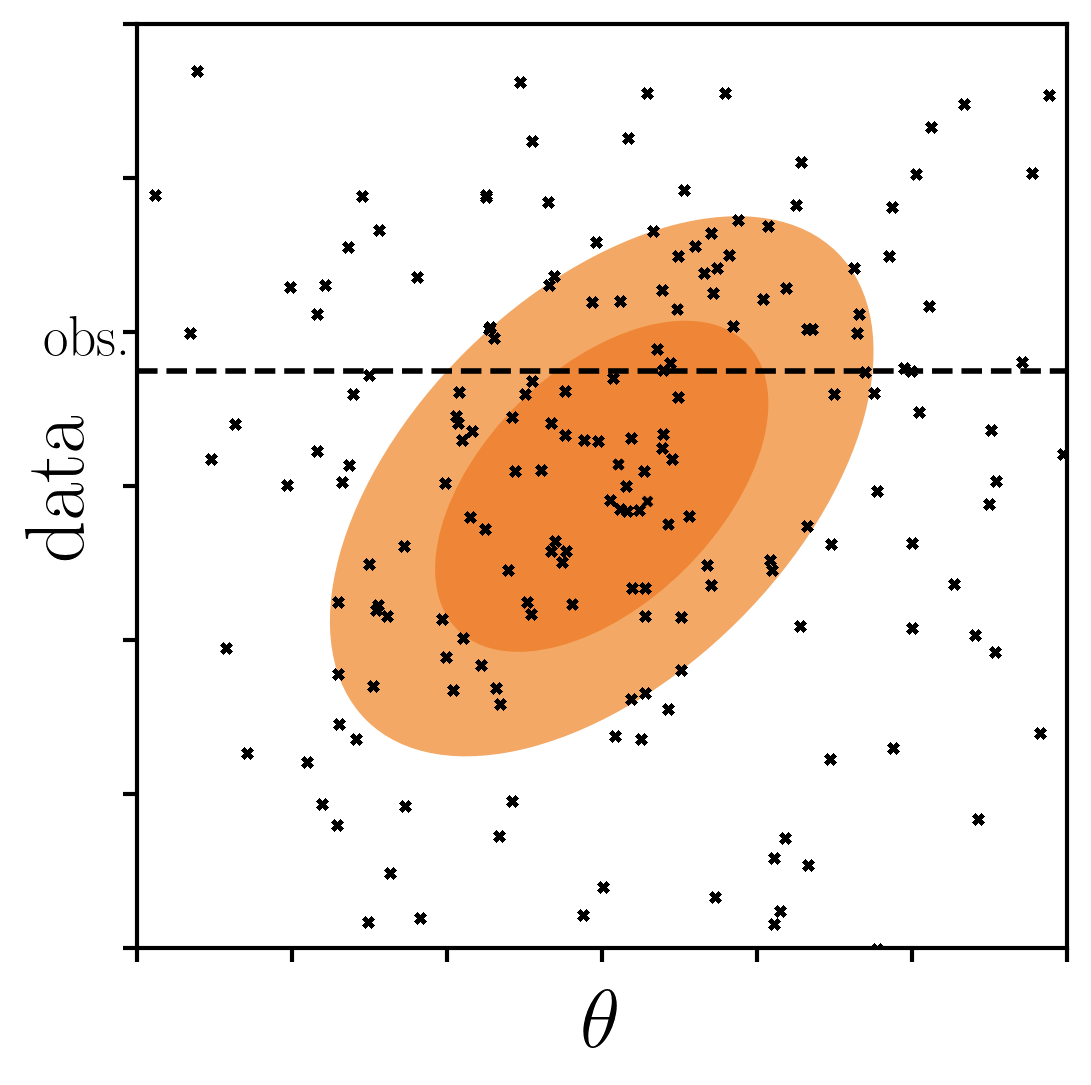
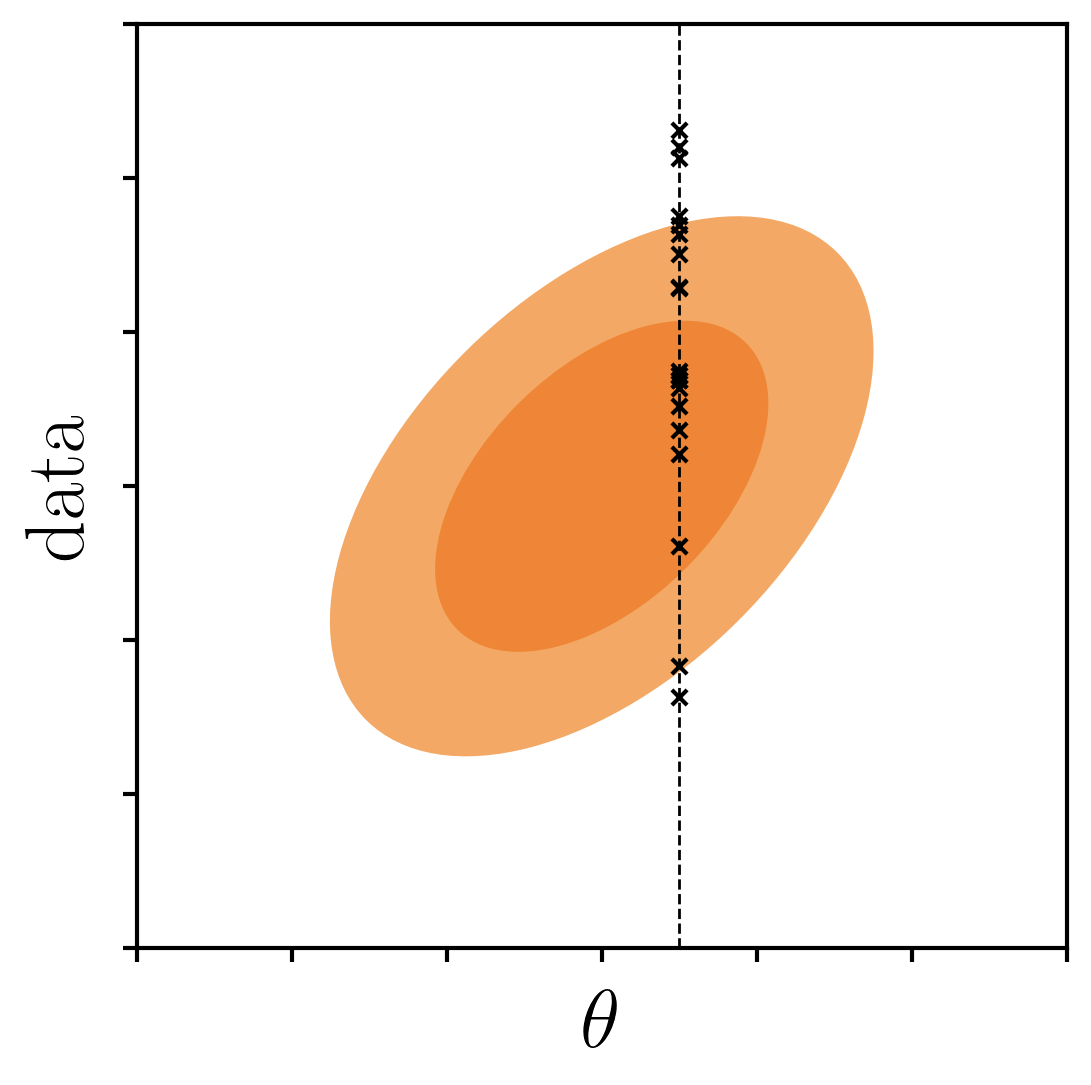
consider p(data,θ)
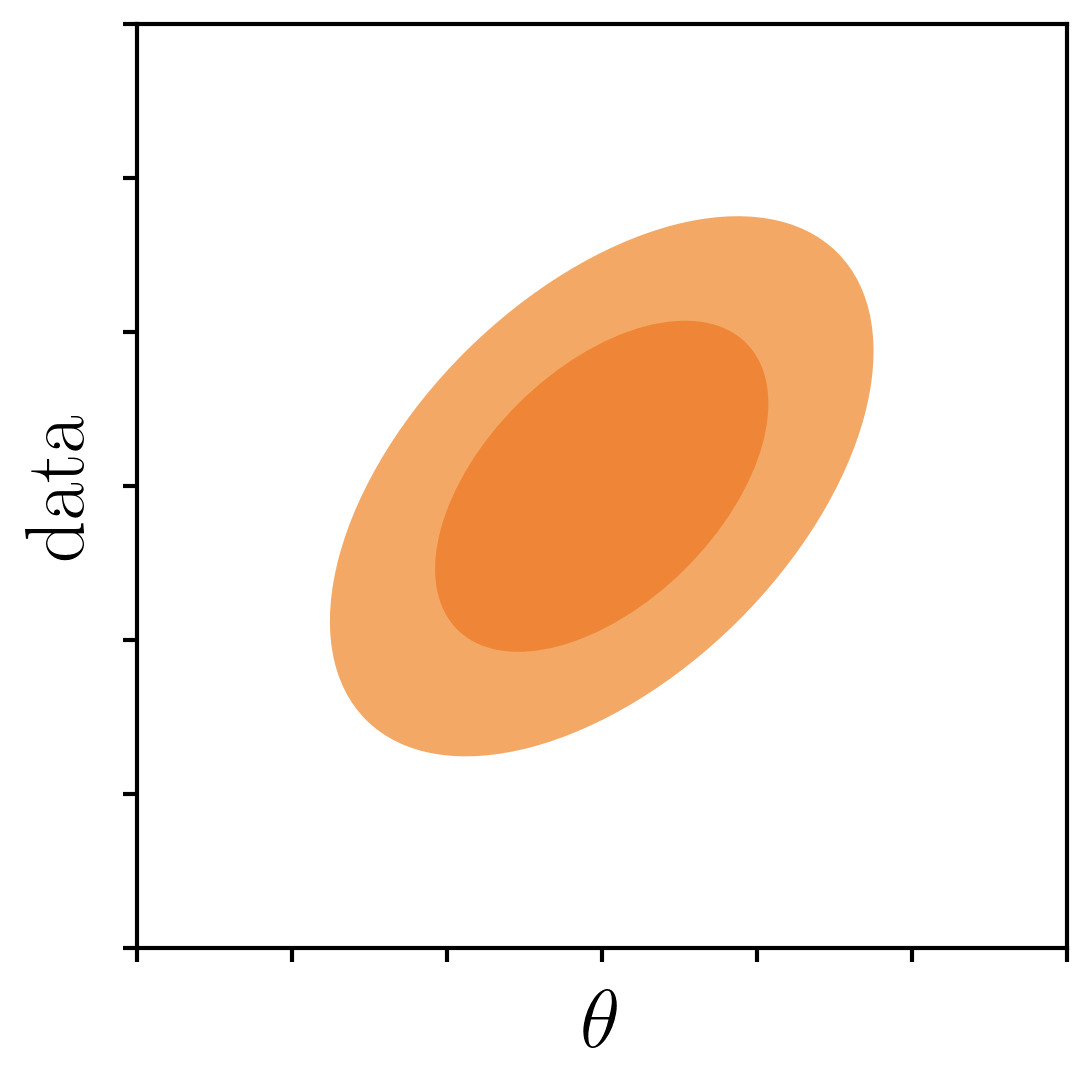
likelihood p(data|θ')
consider p(data,θ)
posterior p(θ|data')
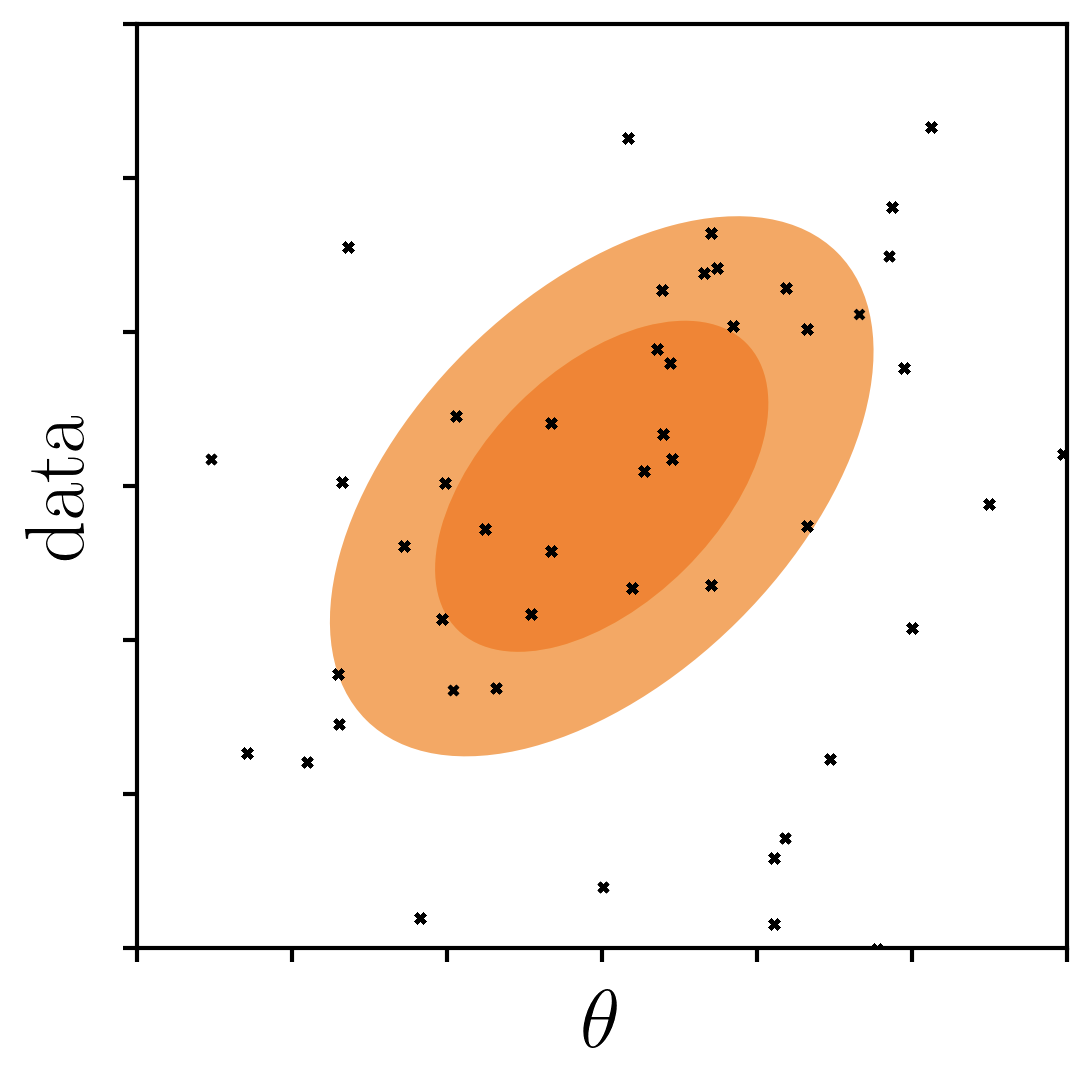
approximate bayesian computation
start by sampling the prior
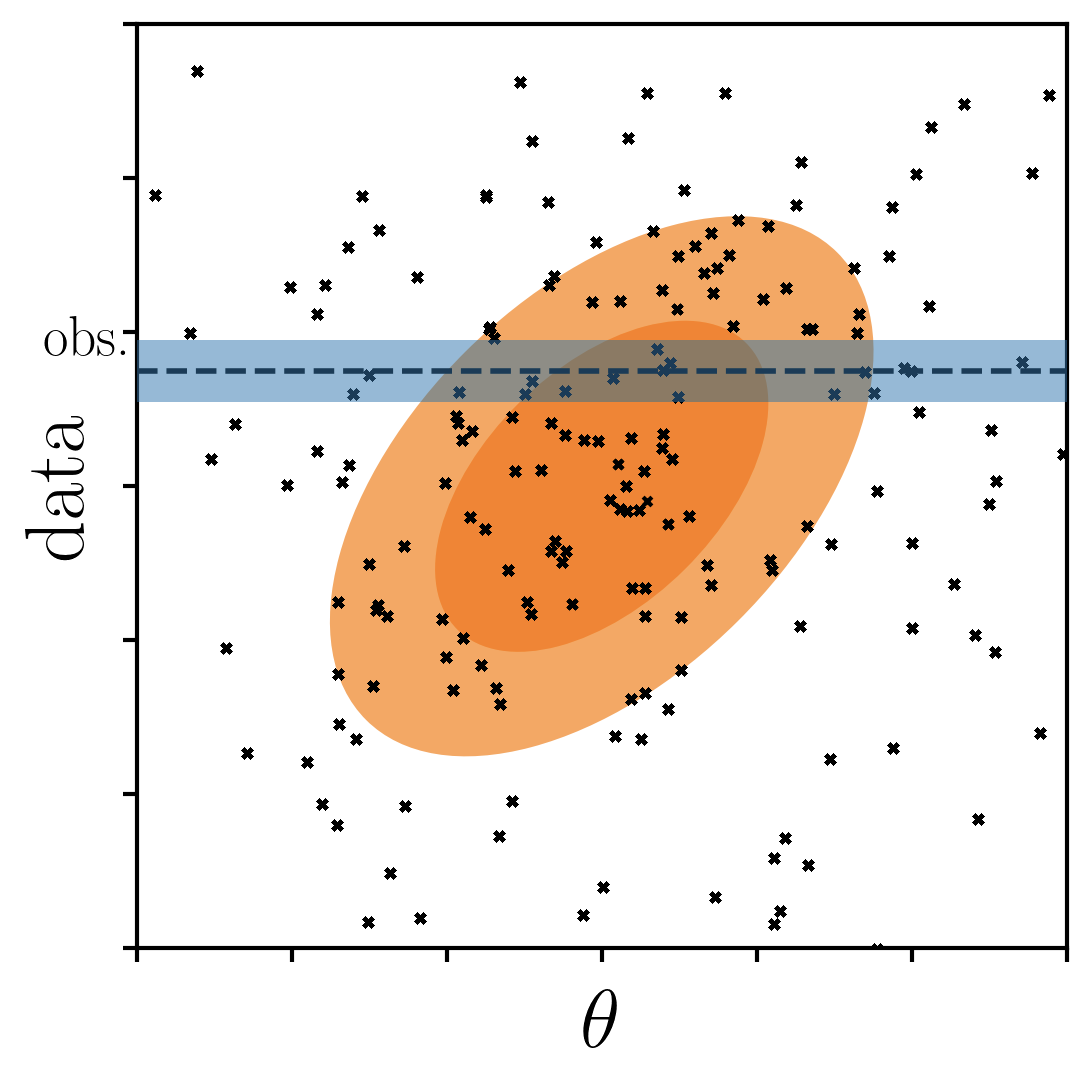
only keep samples within a threshold of observations
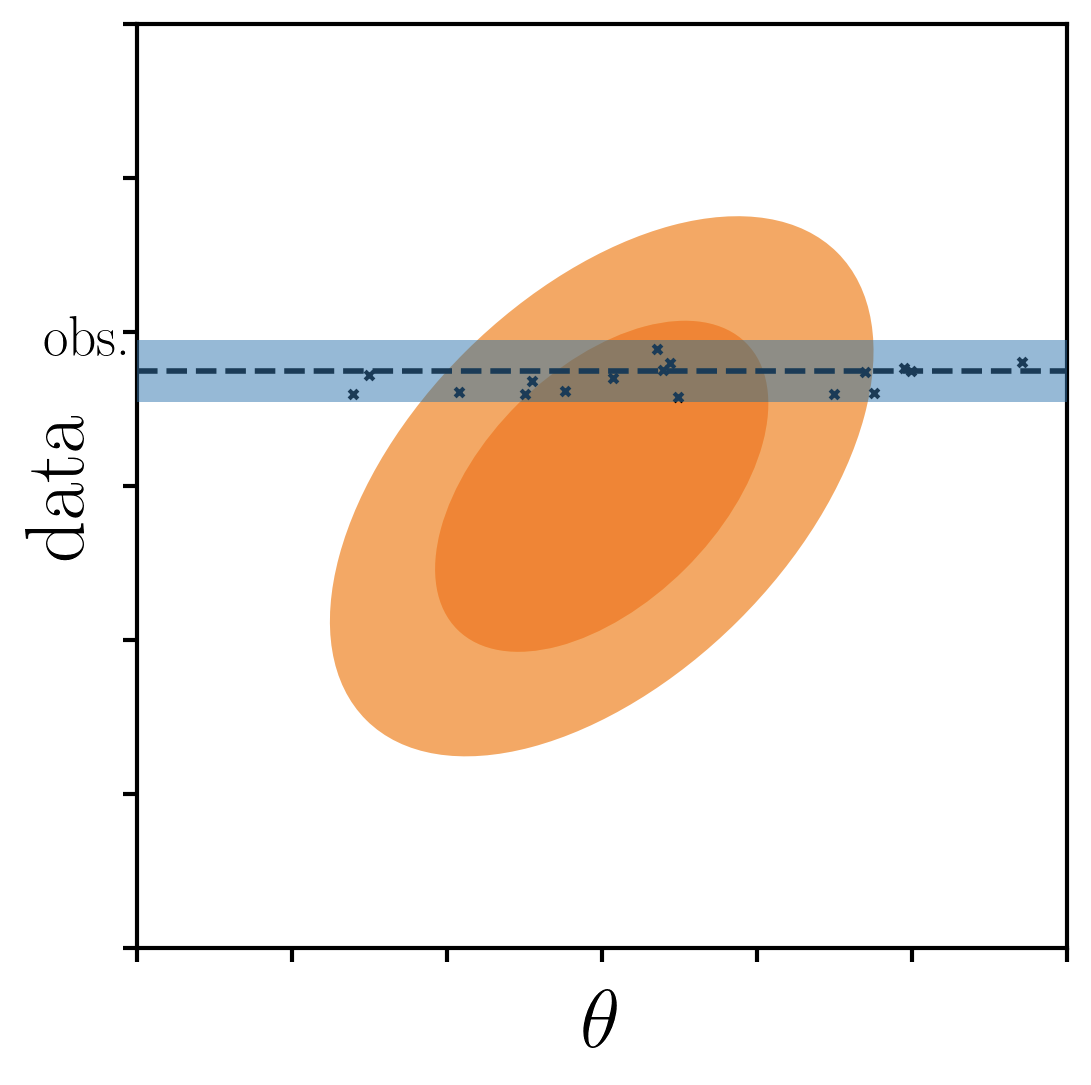
posterior p(θ|obs.)
ABC in practice
summary statistics
Hahn+(2017a): quiescent fraction, SSFR distribution
Hahn+(2019a): SMF of star-forming galaxies
population monte carlo instead of rejection sampling
there are more efficient SBI methods beyond ABC
direct density estimation SBI (e.g. Hahn+2019c)
direct estimates of the likelihood with ICA and GMM
P(k) or GMF
compressed data
DELFI extends this to p(data, θ)
(e.g. Papamakarios&Murray 2016, Alsing+2018)
only tip of the SBI iceberg!
DELFI wiith Neural Density Estimators (Alsing+2019),
ABC with Conditional Density Estimation (Izbicki+2018),
Sequential Neural Posterior Estimation (Lueckmann+2019),
Bayesian Optimization LFI (Gutmann & Corannder 2016),
Inference Aware Neural Optimization (de Castro & Dorigo 2018)
...

the LFI Taskforce is developing new methods for SBI tailored to astronomy
logo credit: @danielhey
with Arin Avsar, Tess Werhane, James Zhu, Vanessa Boehm, Francois Lanusse, Jia Liu (Berkeley)
Virginia Ajani (CEA), Will Coulton (Cambridge), Chieh-An Lin (Edinburgh), Nesar Ramachandra (ANL)
empirical models are cheap and easy to interpret:
e.g. constraining SF variability timescale from SHMR (Hahn+2019c)
DESI Bright Galaxy Survey (PROVABGS) --- 10 million galaxies
hydro sims and SAMs still have plenty of room for improvement and are difficult to interpret (Hahn+2019a)
e.g. tighter constraints on tduty, tquench (Hahn+2017c), assembly bias, hierarchical Bayesian modeling
SBI methods to enable direct inference from galaxy surveys
credit: desi.lbl.gov
IQ collaboratory, ABC, DELFI
harvard2019
By ChangHoon Hahn
harvard2019
talk on star forming central galaxies at Harvard CFA Hernquist meeting Dec 2, 2019




