高效能 PostgreSQL
Routine Maintenance
Jack Yu 2015.10.15
今天講的是
-
日常的維護 Σ( ° △ °|||)
-
MVCC 介紹
-
Vacuum 介紹
-
Query Log 分析
日常維護要幹嘛?
- 清除操作 DB 所殘留的垃圾
- PostgreSQL 為了提供平行讀寫會留垃圾
- 垃圾越多,效能就會下降
- 觀察 Log 來瞭解 DB 是否正常
- 是否有 slow query 等等
MVCC
MultiVersion Concurrency Control
什麼是 MVCC
- 處理平行讀寫相同資料的方法
- 每次 transaction 都看到一個資料庫的 snapshot
- 讀不會阻塞寫,寫不會阻塞讀
- 比鎖定整個表有效率
- 資料庫大多使用 MVCC
- BerkeleyDB, Oracle..
- http://www.postgresql.org/docs/9.3/static/mvcc-intro.html
PostgreSQL 的實現
- 每個交易都有個 Transaction ID (XID)
- 全局遞增
- 每個 Row 都有 insertion XID (xmin), delete XID (xmax)
- xmin: 最低看得到修改的 XID
- xmax: 最大看得到的 XID
- INSERT 或 UPDATE 的時候更新 xmin
- DELETE 的時候更新 xmax
INSERT 範例
- Bullet One
- Bullet Two
- Bullet Three

UPDATE 範例
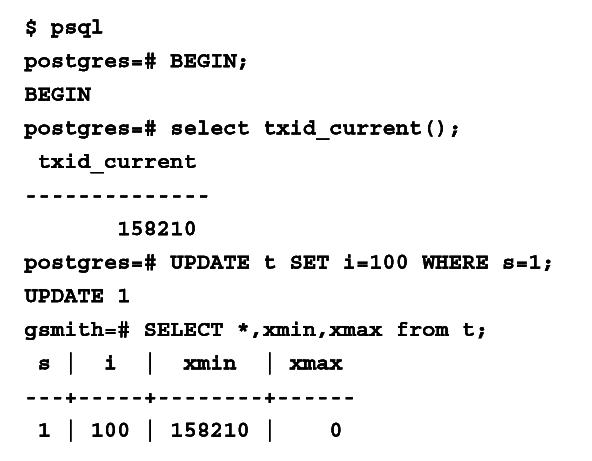

還沒 COMMIT 前另一個 client 看不到
Client 1
Client 2
你看不到我看不到你
- 一個 transaction 中的修改需要 COMMIT 其他人才看得到
- 一個 transaction 開始後就看不到別人的修改
垃圾就是這樣來的
- INSERT 或 UPDATE 後舊的不能刪掉
- DELETE 也不能真的刪掉
- 需要吸塵器 (VACUUM) 來刪
- 所以一直操作布吸塵會增加 DB 大小
那同時更新資料呢?
- UPDATE, DELETE 會 lock row,造成第二個 transaction 等待
- 若第一個 rollback,那第二個就可以順利執行,否則看 Mode
- Read Committed (default)
- Serializable

Read Commit
- 當獲得 Lock 時發現值被改了,就重跑一次
- 當前的 statement
- 使用 row 新的值
- 確定 WHERE 條件仍然符合
- 這可能造成在 transaction 中拿到新的值
- 大部分/簡單 case 可以用
- 但不是全部適用
範例
DELETE 不會生效,就算 UPDATE 之前或之後有 hits == 10
BEGIN;
UPDATE website SET hits = hits + 1;
-- run from another session: DELETE FROM website WHERE hits = 10;
COMMIT;Serializable
- 拿到 Lock 時發現值被改了,直接噴錯誤
- 應用程式只能 rollback transaction 再來一次
- 適用於
- 複雜操作
- 多 statement 的 transaction
- 整個 transaction 看到的值必須一致
ERROR: could not serialize access due to concurrent updates MVCC 的優點
- 很少的資源被 Lock
- 讀不會擋住寫
- 寫不會擋住讀
MVCC 的缺點
- 需要在背景清除垃圾
- 佔用較多硬碟空間
- 資料的可見性可能造成另外的問題
XID Wraparound
- PostgreSQL 用 32bit 來存 XID
- two billion transactions
- VACUUM 會把舊的 XID 轉換成 FrozenXID
- 總是比一般 XID 舊
- vacuum_freeze_max_age
- 多少個 transaction 要替換 XID
- autovacuum_freeze_max_age
-
多少個 transaction 要強制自動 VACUUM
-
多少個 transaction 要強制自動 VACUUM
Vacuum
功用
- 清垃圾
- UPDATE, DELETE, ROLLBACK
- 處理 XID wraparound
- 回收硬碟空間
實作方式
- 每個 row 上有 hint bits
- status flags
- committed or aborted, etc.
- 每個 transaction 都會寫 commit log
- pg_clog
- 用來核對 hint bits
- vacuum 內部用 hint bits + clog 作為輸入,
來計算可以釋放的空間
Regular Vacuum
- 掃瞄整個 table 和 index 來尋找不用的 row
- hint bits 會被上一些標記
- 並把這些 row 的空間記錄到 free space map
- 之後在配置新空間的時候就可以從 map 取用
- 不需要從 OS 配置新的空間
釋放使用的空間
- 跑 VACUUM 不一定會放出空間
- 只有當以下條件成立才會
- table 尾端的 data page 是空的或都是 free rows
- 可以獲得 table exclusive lock
- 釋放流程會把尾端可回收的 data page 都釋出
- 通常要連續 insert,delete 才做得出來
- 常常跑 VACUUM 不要讓硬碟空間變大
Full Vacuum
- 指令: VACUUM FULL
- 會強制回收硬碟空間
- 重組 disk pages,全部往前移把空隙填滿
- 回收尾部空間
- PostgreSQL 9.0 後的實作會需要複製整個表
的額外空間
HOT
- PostgreSQL 8.3 後引入 Heap Only Tuples
- UPDATE 時,新資料儘可能賽在舊資料所在
的 data block- 可以重用 index
- 避免 index bloat
- 可以針對單一 block 做 vacuum 來找空間
Cost-based Vacuum
- Vacuum 通常是耗資源操作,
所以要想辦法限制 - 根據 I/O 消耗來暫停操作
- page hit 1分 (read mem)
- page miss 10 分 (read disk)
- page dirty 20 分 (write disk)
- 超過 vacuum_cost_limit 就暫停
vacuum_cost_delay milliseconds
Autovacuum
歷史
- 7.3 開始有
- 8.3 預設啟用,可以多個 worker
監控 autovacuum
- 從 log 找
- 從 runtime stat table 找
SELECT schemaname,relname,last_autovacuum,last_autoanalyze FROM pg_stat_
all_tables;執行時間點
- XID 要發生 wraparound
- 當夠多 row 發生改變的時候
- 可以針對 table 做設定
autovacuum_vacuum_scale_factor * tuples + autovacuum_vacuum_thresholdalter table t SET (autovacuum_enabled=false);Vacuum 常見問題
應該要更常跑
- 管理員常會因為 vacuum 是重量級
操作而少跑,但通常問題的解法式多跑 - 更常跑 vacuum 的優點
- 每次要做的事比較少,速度快
- 不會出現一次執行很久的狀況
- 不會出現一次消耗大量 I/O 的狀況
- 硬碟空間比較不會被佔用
autovacuum 停用也會跑
- 強制處理 XID wraparound
- 不建議關掉 autovacuum
- 要是跑起來會超級久且消耗資源
autovacuum 記憶體不足
- 相關參數
- maintenance_work_mem
- autovacuum_max_workers
- 參數設太低會造成錯誤且效率低
- log 會有 out of memory 錯誤
- 錯誤後就要重新執行
- 可以先設個合理值,再慢慢往上調找 peak
autovacuum 遇到很多 DB
- autovacuum 預設
- 每 autovacuum_naptime 秒,跑起 worker
- 最多 autovacuum_max_workers
- 要是有超過 autovacuum_naptime 那麼多 DB,
就會一直有 worker 跑起來
autovacuum
在忙碌的 server 上不做事
-
autovacuum_vacuum_cost_delay
預設 20ms- 適合中小型系統
- 大型的 server 通常會造成 autovacuum 跟不上
- 建議調成 1ms ~ 5 ms
- 若 OS 時間精度不足,可以增加 autovacuum_cost_limit
autovacuum 吃掉太多 IO
- 跟上面 case 相反
- 可能是硬碟太爛
- 有特殊策略。例如避免尖峰時間跑 vacuum
- 可以把 autovacuum_vacuum_cost_delay
拉到 100 ms
autovacuum 被需要長時間的 transaction 卡住
- 儘量縮短 transaction 佔住的時間
SELECT procpid,current_timestamp - xact_start AS xact_runtime,current_
query FROM pg_stat_activity ORDER BY xact_start;解決零零總總問題
- 遇到要用 VACUUM FULL 回收硬碟空間
- 可以考慮 CLUSTER 重建 table
- 或是 ALTER TABLE 重寫 table
- 遇到 Index bloat
- 可以 REINDEX 重建索引
- 需要注意中間不要有 transaction 用到
舊的 index
- 總之通常解法是更常跑 vacuum
Autoanalyze
持續統計 Table 資訊
- PostgreSQL 在操作時就會記錄資訊
- 多少個 row 被新增、修改、改變
- 總共多少個 row 等
- autovacuum 只會使用/修改
- UPDATE, DELETE, ROLLBACK 的 row 資訊
- autoanalyzer 也會一起考慮
- INSERT 的 row
- 其他
Log 分析
分析 Log 會想看
- Query 怎麼執行的
- 個別 Query 跑多久
- 依據 Query 類型分類
正規化 Query Fingerprints
- 下面兩個 query log parser 可能不知道他們是一樣的
- 從 prepared statement 來看則相同
- 分析工具會使用 query normalizing 來轉成上面這個
UPDATE pgbench_accounts SET abalance = abalance + 1631 WHERE aid =
5829858;
UPDATE pgbench_accounts SET abalance = abalance + 4172 WHERE aid =
567923;UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2;pg_stat_statements
- 用來暫存 query statement 和分析的模組
- 優點: 不用額外的工具
- 缺點: 儲存的數量有上限
pgbench=# SELECT round(total_time*1000)/1000 AS total_time,query FROM pg_
stat_statements ORDER BY total_time DESC;
total_time | query
78.104 | UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE
aid = $2;
1.826 | UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE
bid = $2;
0.619 | UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE
tid = $2;pgFouine
- Query log file analyze
- PHP script/ 大多數 dist 有 pacakge
- 吃 log 檔分析。可以不用在產生 log 的
server 上執行 - 支援 syslog, CSV
- 支援 html 報表
- 支援 vacuum log 分析
還有其他分析工具
- PQA
- EPAQ
- pgsi
- mk-query-digest
pgFouine 範例
$ pgbench -T 60 -c 4 pgbench
$ pgfouine -logtype stderr -file $PGDATA/pg_log/postgresql-2010-03-28_
210540.log -top 10 -format text##### Overall statistics #####
Number of unique normalized queries: 8
Number of queries: 27,993
Total query duration: 3m52s
##### Queries by type #####
SELECT: 4666 16.7%
INSERT: 4665 16.7%
UPDATE: 13995 50.0%
##### Slowest queries #####
1) 5.37 s - END;
2) 5.26 s - END;
3) 5.26 s - END;
4) 5.25 s - END;
5) 4.97 s - UPDATE pgbench_accounts SET abalance = abalance + 1631 WHERE
aid = 5829858;
6) 4.96 s - END;
7) 4.58 s - END;pgFouine 範例
8) 3.93 s - UPDATE pgbench_accounts SET abalance = abalance + 4172 WHERE
aid = 567923;
9) 3.92 s - END;
10) 3.78 s - UPDATE pgbench_accounts SET abalance = abalance + -379 WHERE
aid = 12950248;
##### Queries that took up the most time (N) #####
1) 2m14s - 4,665 - END;
2) 1m26s - 4,665 - UPDATE pgbench_accounts SET abalance = abalance + 0
WHERE aid = 0;
3) 5.3s - 4,665 - UPDATE pgbench_tellers SET tbalance = tbalance + 0
WHERE tid = 0;
4) 2.4s - 4,665 - UPDATE pgbench_branches SET bbalance = bbalance + 0
WHERE bid = 0;
5) 1.8s - 4,665 - INSERT INTO pgbench_history (tid, bid, aid, delta,
mtime) VALUES (0, 0, 0, 0, CURRENT_TIMESTAMP);
6) 1.5s - 4,665 - SELECT abalance FROM pgbench_accounts WHERE aid = 0;
7) 0.1s - 1 - select count(*) from pgbench_branches
8) 0.0s - 1 - truncate pgbench_history總結 1
- 日常維護很花時間,但不做通常會更慘
- 建議有良好的 vacuum 實踐,不然後果
可能是需要停機修復 - 建議主動的監控分析 Log,解決各種查詢
問題,雖然可能會造成 server 負載變高
總結 2
- MVCC 會幫你處理同時讀寫問題,
但真的只能一個讀寫的時候,
還是要自己 lock 處理 - UPDATE, DELETE, ROLLBACK 會
留垃圾,要記得 vacuum 處理 - 建議使用 autovacuum 並頻繁的運行
總結 end
- 避免 VACUUM FULL,可以用
CLUSTER 或是 REINDEX - 儲存基本的 query log,趁早發現 query 問題
- 很多 log 分析工具可以幫忙!
Thank you!
然後原來這本書有簡中,請支持正版 (據說翻得不好)
PostgreSQL High Performance: Routine Maintenance
By Chieh Yu
