深度强化学习
- 为什么要使用深度强化学习
- 深度强化学习的大致思路
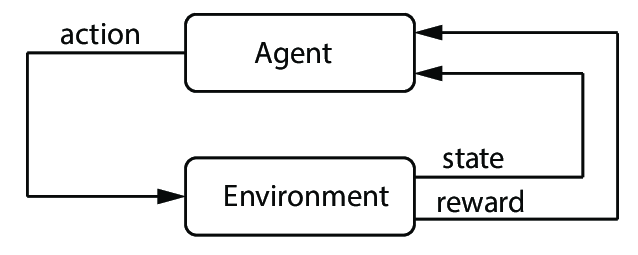
普通的强化学习,无论是基于模型的(model-based)强化学习,还是免模型的(model-free)强化学习,往往存在一张“表(table)”
为什么要使用深度强化学习(deep reinforcement learning)
这张表指示了在某种状态(state)下,该执行何种动作(action)
强化学习算法进行的过程,正是不断地更新这张"表",从而得到最佳策略(policy)的过程
在这里,我们能仅仅利用一张表来存储状态—动作对,是基于一个重要的假设:
状态是离散且有限的
为什么要使用深度强化学习(deep reinforcement learning)



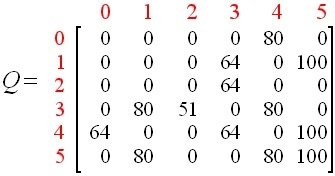
为什么要使用深度强化学习(deep reinforcement learning)
在这里,我们能仅仅利用一张表来存储状态—动作对,是基于一个重要的假设:
状态是离散且有限的
如果状态时连续或者“无限”的呢?
为什么要使用深度强化学习(deep reinforcement learning)
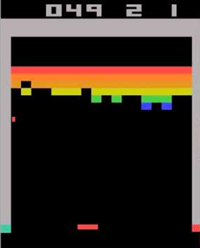
Atari游戏界面为210 × 160,仅仅假设砖块有5种颜色的话...
为什么要使用深度强化学习(deep reinforcement learning)
当状态为连续或无限的时候,使用表来存储状态-动作对已经不现实,但是如果我们能找到一个函数f,使得Q(s, a) = f(s, a),便能应对连续或无限的状态
为什么要使用深度强化学习(deep reinforcement learning)
这个“函数”便是神经网络
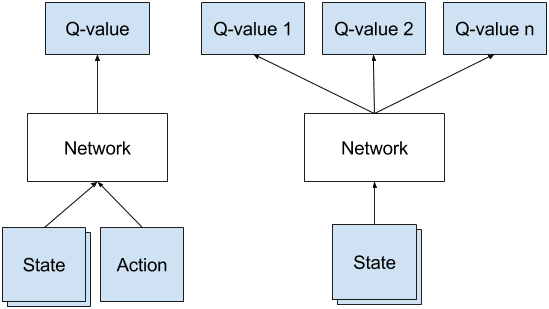
顾名思义,深度强化学习 = 深度学习 + 强化学习
深度强化学习的大致思路
神经网络擅长处理结构化的数据(比如图片、文字、声音等),故通过神经网络来拟合Q(s, a),有Q(s, a) = f(s, a, θ),其中,θ是神经网络中的参数
通过梯度下降法(在深度强化学习中又称作policy gradient),将求得的误差逆传播,从而调整参数θ
深度强化学习
By Chunxiao Ye



