
cjtsai
失蹤的c++殭屍
cjtsai
這我高一的照片...
何謂字串演算法
滾來滾去的雜湊
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | sum |
|---|---|---|---|---|---|---|---|---|---|
| char | c | k | e | f | g | i | s | c | X |
| toi | 3 | 11 | 5 | 6 | 7 | 9 | 19 | 3 | X |
| p的冪次 | 10460353203 | 387420489 | 14348907 | 531441 | 19683 | 729 | 27 | 1 | X |
| 乘起來 | 31381059609 | 4261625379 | 71744535 | 3188646 | 137781 | 6561 | 513 | 3 | 35717763027 |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | sum |
|---|---|---|---|---|---|---|---|---|---|
| char | c | k | e | f | g | i | s | c | X |
| toi | 3 | 11 | 5 | 6 | 7 | 9 | 19 | 3 | X |
| p的冪次 | 10460353203 | 387420489 | 14348907 | 531441 | 19683 | 729 | 27 | 1 | X |
| 乘起來 | 31381059609 | 4261625379 | 71744535 | 3188646 | 137781 | 6561 | 513 | 3 | 35717763027 |
| i | 0 | 1 | 2 | 3 | sum |
|---|---|---|---|---|---|
| char | k | e | f | g | X |
| toi | 11 | 5 | 6 | 7 | X |
| p的冪次 | 19683 | 729 | 27 | 1 | X |
| 乘起來 | 216513 | 3645 | 162 | 7 | 220327 |
| 原本的hash值 | 4261625379 | 71744535 | 3188646 | 137781 | 4336696341 |
| 除19683 | 216513 | 3645 | 162 | 7 | 220327 |
挖 是對的欸 廢話 不然我來搞笑的嗎
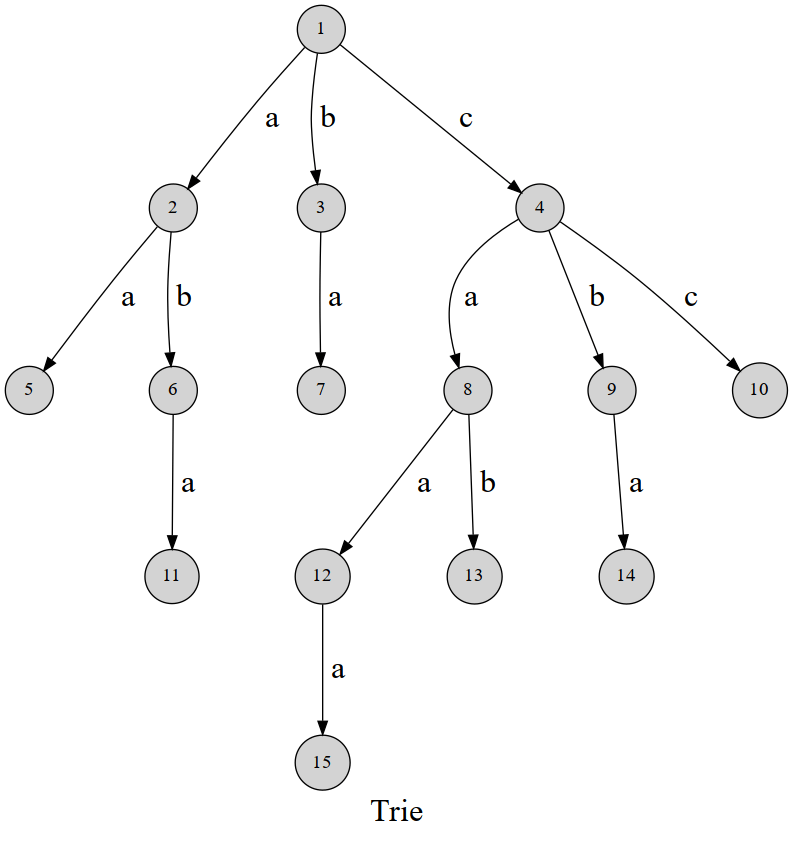
畢竟算是一棵樹對吧
| 1 | ∅ |
| 2 | a |
| 3 | b |
| 4 | c |
| 5 | aa |
| 6 | ab |
| 7 | ba |
| 8 | ca |
| 9 | cb |
| 10 | cc |
| 11 | aba |
| 12 | caa |
| 13 | cab |
| 14 | cba |
| 15 | caaa |
struct Trie{
Trie* c[26];//看你下面有幾種字元,也可以是不定長度的
int cnt=0; //為了儲存這個節點有幾個字是結尾在這裡的
Trie():cnt(0){
memset(c, 0, sizeof(c));
}
};
trie* root = new trie();
void insert(string s){
trie* tmp = root;
for(int i=s.size()-1; i>=0; i--){
if(!tmp->c[(s[i]-'a')]){
tmp->c[(s[i]-'a')] = new trie();
}
tmp=tmp->c[(s[i]-'a')];
}tmp->cnt++;
}bool query(string s){
trie* tmp =root;
for(int i=0; i<s.size(); i++){
int eee=s[i]-'a';
if(tmp->c[eee]){
tmp=tmp->c[eee];
}else{
return false;
}if(tmp->cnt&&i==s.size()-1){
return true;
}
}
return false;
}
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define modd 1000000007
vector<int> dp(100007, 0);
struct trie{
trie* c[26];
int cnt=0;
trie(){
memset(c, 0, sizeof(c));
}
};
trie* root = new trie();
void insert(string s){
trie* tmp = root;
for(int i=s.size()-1; i>=0; i--){
if(!tmp->c[(s[i]-'a')]){
tmp->c[(s[i]-'a')] = new trie();
}
tmp=tmp->c[(s[i]-'a')];
}tmp->cnt++;
}
string ans;
void query(int e){
trie* tmp =root;
int tpe=e;
while(tpe>=0){
int eee=ans[tpe]-'a';
if(tmp->c[eee]){
tmp=tmp->c[eee];
}else{
break;
}if(tmp->cnt){
dp[tpe]+=dp[e+1];
dp[tpe]%=modd;
}tpe--;
}
}
signed main(){
cin>>ans;
int n;cin>>n;
for(int i=0; i<n; i++){
string t;cin>>t;
insert(t);
}
dp[ans.size()]=1;
for(int i=ans.size()-1; i>=0; i--){
query(i);
}cout<<dp[0];
}
SHARE CODE TO OTHERS今天時間蠻多的
大家現在去想辦法AC他
Knuth–Morris–Pratt 就三個人名
vector<int> prefix_function(string s) {
int n = (int)s.length();
vector<int> pi(n);
for (int i = 1; i < n; i++) {
int j = pi[i - 1];
while (j > 0 && s[i] != s[j]) j = pi[j - 1];
if (s[i] == s[j]) j++;
pi[i] = j;
}
return pi;
}aka Gusfield Algorithm
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 1 | 0 | 3 | ? |
|---|
2
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | ? |
|---|
| X | 2 | 1 | 0 | 3 | 4 |
|---|
vector<int> z_build(string S) {
int n=S.size();
vector<int> Z(n);
Z[0] = 0;
int bst = 0;
for(int i = 1; i<n; i++) {
if(Z[bst] + bst < i) Z[i] = 0;
else Z[i] = min(Z[bst]+bst-i, Z[i-bst]);
while(S[Z[i]] == S[i+Z[i]]) Z[i]++;
if(Z[i] + i > Z[bst] + bst) bst = i;
}
return Z;
}做...不...完...
有興趣的自己去學
我會去講課 如果沒有被取消的話
我做完發現這頁幾乎沒用
因為坐在這邊的建北電資的只剩一個沒報 不急 就是你
for CKEFGISC
By cjtsai




