Flat files and relational databases


what we're talking about
- what's a flat file?
- what's a relational database?
- so what?
- other database types?
| last | first | birth | death | title | pub_year | publisher | pub_loc |
|---|---|---|---|---|---|---|---|
| Twain | Mark | 1835 | 1910 | Huckleberry Finn | 1986 | Penguin USA | New York |
| Twain | Mark | 1835 | 1910 | Tom Sawyer | 1987 | Viking | New York |
| Rothfuss | Patrick | 1973 | The Name of the Wind | 2007 | DAW Books | New York | |
| Lorde | Audre | 1934 | 1992 | Sister Outsider | 1984 | Crossing Press | New York |
| Mann | Thomas | 1875 | 1955 | Death in Venice |
1989 | Penguin | New York |
| Cather | Willa | 1873 | 1947 | O Pioneers! | 1992 | Vintage | New York |
| Cather | Willa | 1873 | 1947 | My Ántonia | 1999 | Penguin | New York |
a spreadsheet
the same spreadsheet
last,first,birth,death,title,pub_year,publisher,pub_loc\nTwain,Mark,1835,1910,Huckleberry Finn,1986,Penguin,New York\nTwain,Mark,1835,1910,Tom Sawyer,1987,Viking,New York\nRothfuss,Patrick,1973,,The Name of the Wind,2007,DAW Books,New York\nLorde,Audre,1934,1992,Sister Outsider,1984,Crossing Press,New York\nMann,Thomas,1875,1955,Death in Venice,1989,Penguin,New York\nCather,Willa,1873,1947,O Pioneers!,1992,Vintage,New York\nCather,Willa,1873,1947,My Ántonia,1999,Penguin,New York
what are the types of things we have?
- Authors
- Works
- Publishers
Authors
- last name
- first name
- date of birth
- date of death
Works
- title
- publication date
Publishers
- name
- city
Authors
- last name
- first name
- date of birth
- date of death
Works
- title
- publication date
Publishers
- name
- city
entity relationship diagram
Authors
- last name
- first name
- date of birth
- date of death
Works
- title
- publication date
Publishers
- name
- city
written by
published by
published
entity relationship diagram
Authors
- last name
- first name
- date of birth
- date of death
Works
- title
- publication date
Publishers
- name
- city
written by
published by
published
entity relationship diagram
many
many
one
How do we link these tables?
primary keys
and
foreign keys
| author_id | last | first | birth | death |
|---|---|---|---|---|
| 1 | Twain | Mark | 1835 | 1910 |
| 2 | Rothfuss | Patrick | 1973 | NULL |
| 3 | Lorde | Audre | 1934 | 1992 |
| 4 | Mann | Thomas | 1975 | 1995 |
| 5 | Cather | Willa | 1873 | 1947 |
| work_id | title | pub_year | author_id |
|---|---|---|---|
| 1 | Huckleberry Finn | 1986 | 1 |
| 2 | Tom Sawyer | 1987 | 1 |
| 3 | The Name of the Wind | 2007 | 2 |
| 4 | Sister Outsider | 1984 | 3 |
| 5 | Death in Venice | 1989 | 4 |
| 5 | O Pioneers! | 1992 | 5 |
| 7 | My Ántonia | 1999 | 5 |
primary keys
and
foreign keys
| pub_id | name | loc |
|---|---|---|
| 1 | Penguin | New York |
| 2 | Viking | New York |
| 3 | DAW Books | New York |
| 4 | Crossing Press | New York |
| 5 | Vintage | New York |
redundant information!
| pub_id | name | loc_id |
|---|---|---|
| 1 | Penguin | 1 |
| 2 | Viking | 1 |
| 3 | DAW Books | 1 |
| 4 | Crossing Press | 1 |
| 5 | Vintage | 1 |
+
| loc_id | location |
|---|---|
| 1 | New York |
| pub_id | name | loc |
|---|---|---|
| 1 | Penguin | New York |
| 2 | Viking | New York |
| 3 | DAW Books | New York |
| 4 | Crossing Press | New York |
| 5 | Vintage | New York |
redundant information!
| pub_id | name | loc_id |
|---|---|---|
| 1 | Penguin | 1 |
| 2 | Viking | 1 |
| 3 | DAW Books | 1 |
| 4 | Crossing Press | 1 |
| 5 | Vintage | 1 |
+
| loc_id | location |
|---|---|
| 1 | New York |
Now we could use our "locations" table again, for instance if we wanted to add information on birth city to the authors table!
what about SQL?


so what?
- more tool agnostic
- simple to use
- easy to share
- can get unwieldy
- difficult to add new types of information
flat files
- require coding and development
- fast
- allow for more interaction
- multi-user, multi-access
- easy to add new types of information
- more difficult to share
relational databases
so what?

so what?
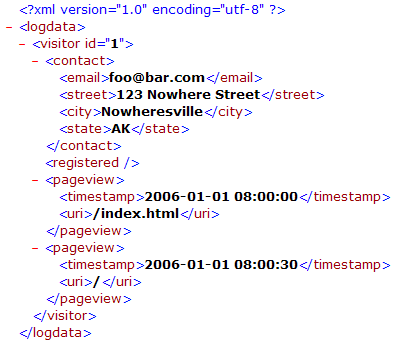
xml
tidy data
-
Each variable forms a column.
-
Each observation forms a row.
-
Each type of observational unit forms a table.
so what?
Hadley Wickham, "Tidy Data":
https://cran.r-project.org/web/packages/tidyr/vignettes/tidy-data.html
even textual data can be tidy!
so what?
Julia Silge and David Robinson, Text Mining with R: A Tidy Approach:
https://www.tidytextmining.com/
## # A tibble: 725,055 x 4
## book linenumber chapter word
## <fct> <int> <int> <chr>
## 1 Sense & Sensibility 1 0 sense
## 2 Sense & Sensibility 1 0 and
## 3 Sense & Sensibility 1 0 sensibility
## 4 Sense & Sensibility 3 0 by
## 5 Sense & Sensibility 3 0 jane
## 6 Sense & Sensibility 3 0 austen
## 7 Sense & Sensibility 5 0 1811
## 8 Sense & Sensibility 10 1 chapter
## 9 Sense & Sensibility 10 1 1
## 10 Sense & Sensibility 13 1 the
## # ... with 725,045 more rows-
what are your relationships?
-
how will you filter the data?
-
how will you sort the data?
-
how often will the data be updated?
-
who will do this updating?
-
-
how will you share this data?
-
through a website?
-
raw data?
-
both?
-
so what?
references
-
relational database example adapted from:
-
A Companion to Digital Humanities, ed. Susan Schreibman, Ray Siemens, John Unsworth. Oxford: Blackwell, 2004.
http://www.digitalhumanities.org/companion/
-
-
wordpress structure image from
http://web-profile.net/wp-content/uploads/wordpress_db_schema.png -
xml image fromhttps://marketing.adobe.com/resources/help/en_US/insight/dataset/c_xml_dec_grps.html
Flat files and relational databases
By Ryan Clement
Flat files and relational databases
For the first Digital Fluencies Lunch with Middlebury's Digital Liberal Arts initiative.




