KubeCon 2019 Follow-up

By Corey Gale



Random Keynote Notes
- According to the Linux foundation, eBPF will be replacing iptables in Linux
- K8s is young (5 years public usage)
- Arm sponsoring CNCF
- 150B+ Arm-based chips shipped
- “Cloud Native on Arm”
- Edge-to-cloud
- New jobs board: jobs.cncf.io
- KubernetesCommunityDays.org
Random Keynote Notes Cont'
-
K8s v1.16
-
CRDs reach GA
-
Metrics overhaul
-
CSI enhancements
-
Resizing
-
Clone volumes
-
Inline volume support in beta (good for ephemeral attachments)
-
-
Ephemeral containers (alpha feature)
-
Can attach to a running pod
-
Example: tcpdump, filesystem inspection
-
Needs to be turned on
-
-
CNCF Project Updates
-
Requirements for graduation: adoption, maintainer diversity, project health
-
Vitess (graduated)
-
Cloud native DB, super scalable, reliable (5 9s)
-
35% of Slack is on Vitess, 100% by end of 2020
-
JD.com uses Vitness @ 35M QPS (30k pods, 4k keyspaces)
-
-
LinkerD (incubating)
- Canary rollout feature
- Request tracing
- Helm (incubating)
- Critical mass: 1M downloads/month, 600 contributors, 29 maintainers, 15 companies
CNCF Project Updates Cont'
-
Jaeger (graduated)
-
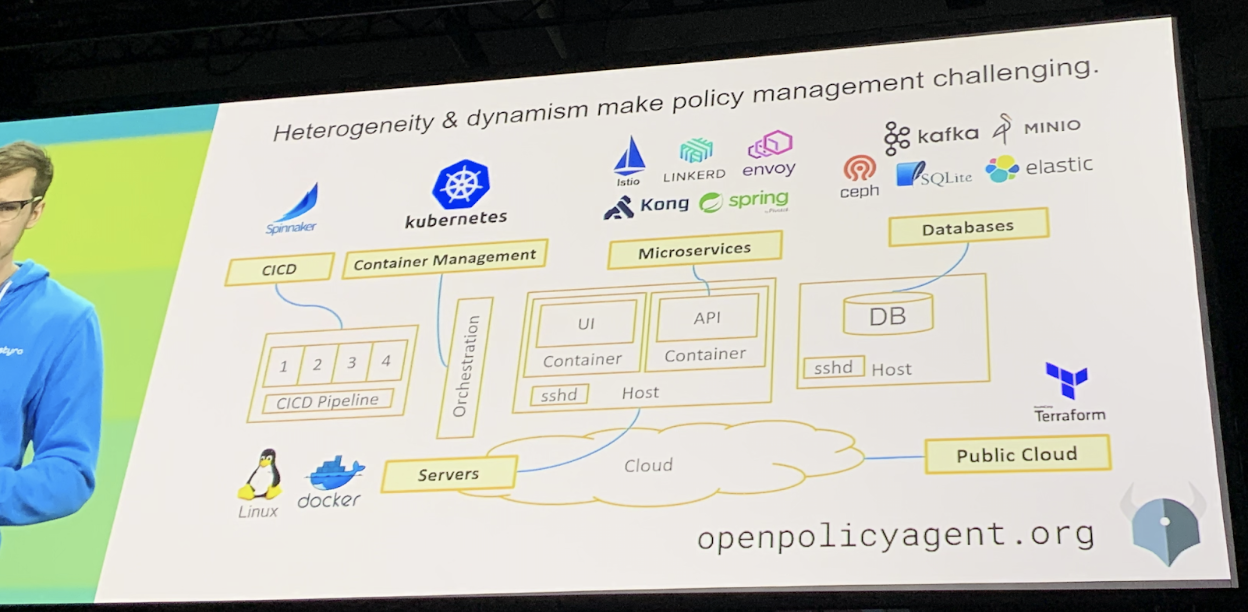
Open Policy Agent (OPA) (incubating)
-
Decouples policy definitions and environment/enforcement
-
Flexible, fine-grained control across the stack
-
Side-car or host-level daemon
-
Declarative policy language: Rego
-
-
Etcd (incubating)
-
Can now scale up to 5000 node k8s clusters
-
CNCF Project Updates Cont'
-
NATS
-
Cloud-native messaging service
-
Scalable services and streams
-
Tinder used NATS to migrate poll workloads to push
-
Added Prometheus exporters & Grafana dashboards
-
FluentD, Kafka integrations
-
Goal: connect everything
-
Low Latency Multi-cluster Networking with Kubernetes
- Lyft (talk link)
- Scale: 100+ stateless microservices, 10K+ pods
-
ML: 5k+ pods, 10k+ cores
-
Ridesharing: 100k+ containers (sidecars), 50k+ cores
-
-
Lyft CNI stack requirements: VPC native, low latency, high throughput
-
-
No overlay network, very low IPvlan overhead
-
Envoy Manager (EM): side-cars connect to EM
- Not looking to add significant features
-


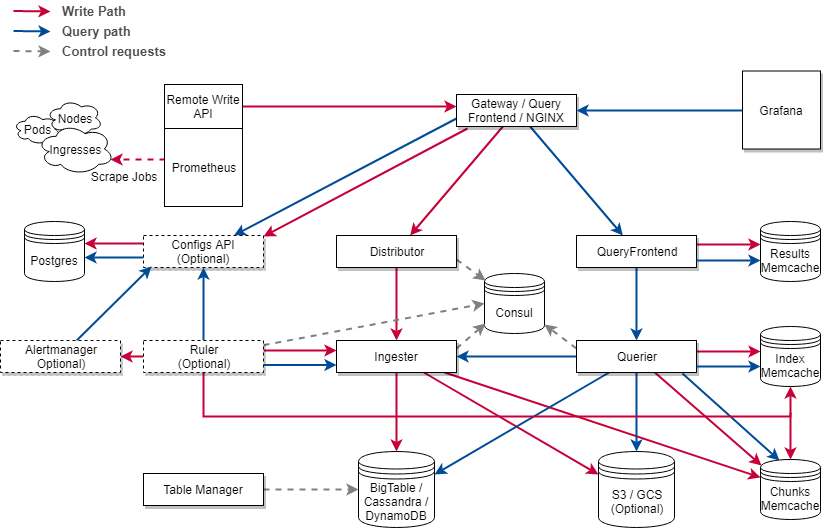
Cortex 101: Horizontally Scalable Long Term Storage for Prometheus
- Splunk (talk link)
- System: Prometheus > distributor > ingestor (talks to etcd/Consul) > store
-
Long term storage options: DynamoDB, Google Big Table, S3, Google Cloud Storage, Cassandra
-
Includes tools for auto-scaling LTS
-
What’s new?
-
Ingestors can ship blocks instead of chunks
-
Write-ahead logging for ingestors
-
- Mentioned Thanos
Towards Continuous Computer Vision Model Improvement with Kubeflow
- Snap Inc. (talk link)
- Scale: 3.5 billions snaps/day, 210 million daily active users, 600k lenses created
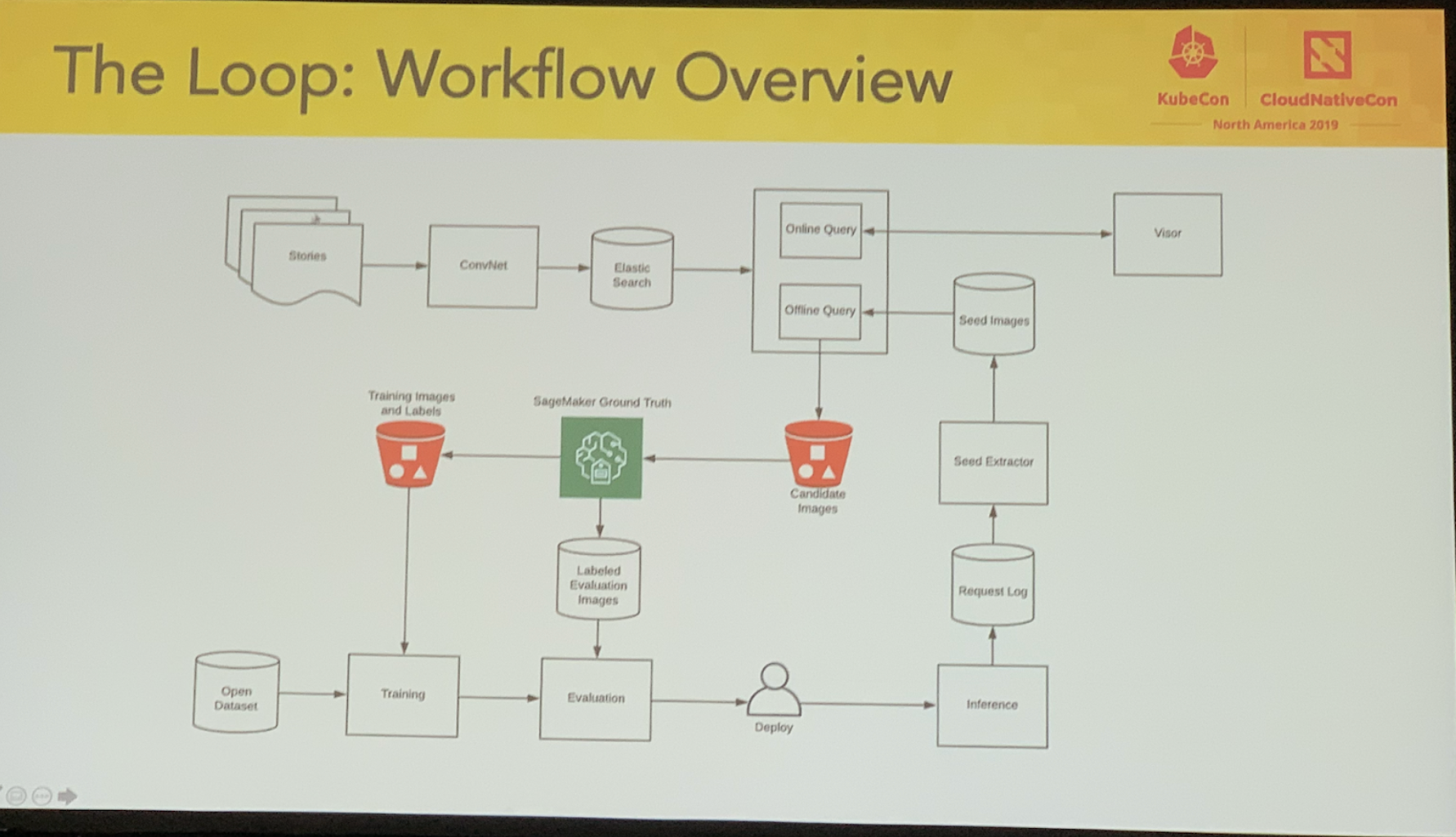
- Your model is only as good as your training data
-
Problem: we need more labeled data, but what kind of data exactly?
-
Solution: The Loop workflow (see slide shot)
-
Uses Sage Maker ground truths
-
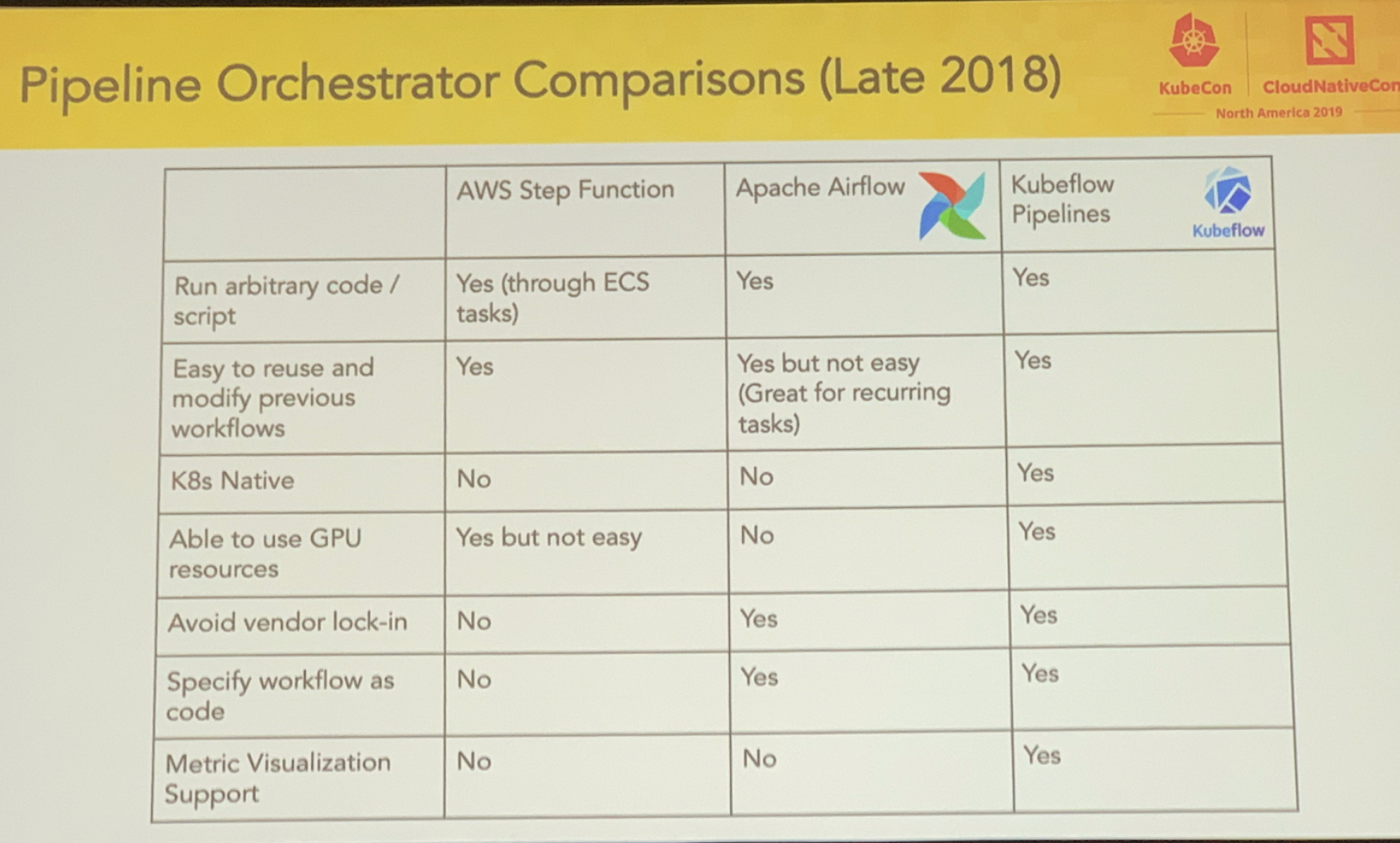
- Case study: pipeline orchestrator comparisons
Scaling Kubernetes to Thousands of Nodes Across Multiple Clusters, Calmly
- AirBnB (talk link)
- Re: cluster size: hard limit of 5000 nodes
- You can definitely probably do 2500
- “Yeah, things get a lot more difficult after 2500” - various conversations
- Alibaba recently got a 10000 node cluster working with a lot of extra work
-
Limit: etcd OOM’ing, fixed in etdc v3
-
~2300 nodes/cluster AirBnB’s max
-
Approach: workloads can be scheduled on any cluster
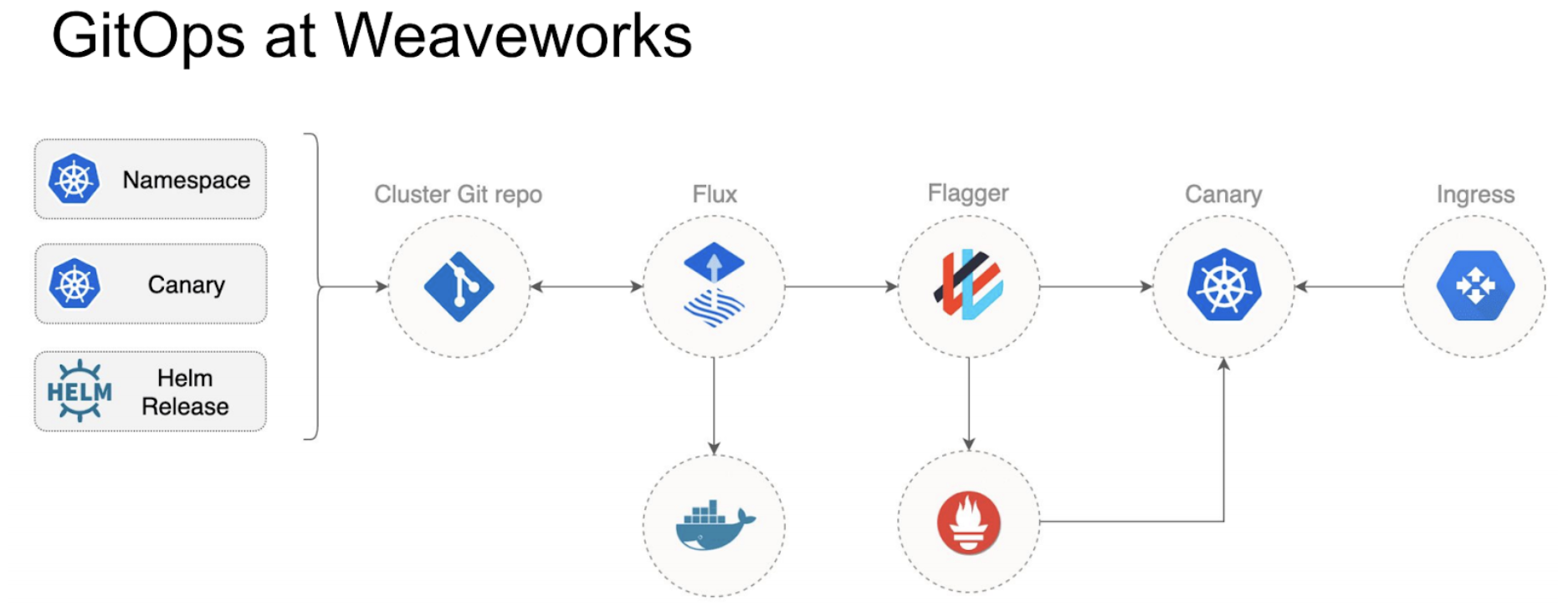
GitOps User Stories
-
Weaveworks, Intuit, Palo Alto Networks (talk link)
-
Argo Flux
-
Weaveworks-Intuit-AWS collaboration
Helm 3 Deep Dive
-
Microsoft & IBM (talk link)
-
Helm 3 announced. Major changes:
-
No more Tiller
- Chart repository: Helm Hub
-
Release "upgrade" strategy
-
Testing framework
-
Dependencies moved into manifest
-
Chart value validation
-
“3-way merge”
-
Considers old manifest, new manifest and current values (addresses manually updated values)
-
-
Releases stored as secrets in the same namespace as the release
-
Kubernetes at Reddit: Tales from Production
- Reddit (talk link)
-
Reddit scale:
-
500M+ monthly active users
-
16M+ posts, 2.8B+ votes per month
-
- Before: 1 cluster per region (3 AZs)
-
After: 1 cluster per AZ (3 clusters per region)
-
What went well:
-
Cost and latency savings from silo’d AZs.
-
Mirrored clusters have prevented outages.
-
- What didn’t:
-
More clusters, more admin overhead.
-
Other Talks I Attended
- Use Your Favorite Developer Tools in Kubernetes With Telepresence
- Improving Performance of Deep Learning Workloads With Volcano
- How Kubernetes Components Communicate Securely in Your Cluster
- The Gotchas of Zero-Downtime Traffic w/Kubernetes
- Solving Multi-Cluster Network Connectivity With Submariner
My Raw Notes
- Google Doc
- Notes for every talk I attended
- Slide decks linked when provided

Questions?
KubeCon 2019
By Corey Gale




