Apache Spark
Lightning-fast cluster computing
What is spark:
is a fast and general engine for large-scale data processing
When to use it:
- When you have terabytes/petabytes of data
- When your algorithms work in cycles
- When you need support for live data processing
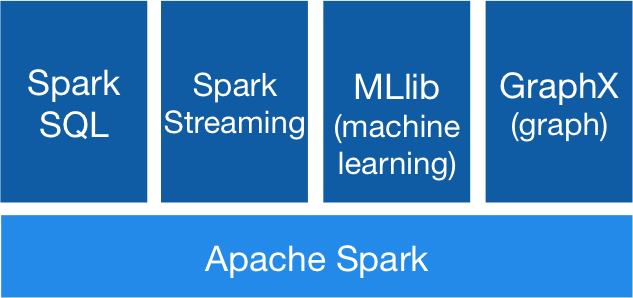
Spark modules
- Spark streaming:
Can receive live data, divide it into batches and generate the results, works with Kafka, Flumes, Hadoop - Spark Sql:
Offers a abstraction for sql table or other data sources:
DataFrames, we can run sql commands on the or work as RDD's - Mlib- machine learning, random data generation....
- GraphX - introduces a new abstraction on top of RDD: Graph
as well a wide list of algorithms and builders for graphs. - Bagel : google's implementations of graphs - will be merged with graphX
Module's
RDD Spark's most important abstraction
(Resilient distributed datasets)
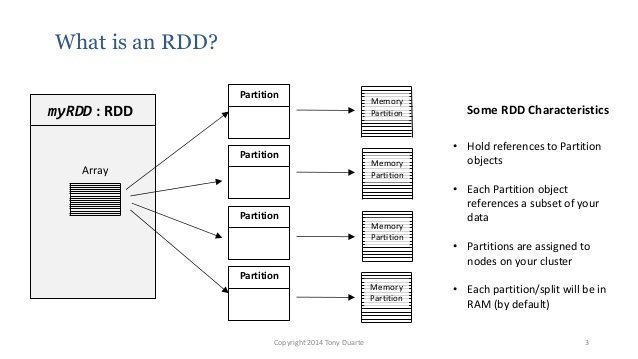
Fault tolerant thanks to lineage!!
2 types of operations that can be applied on RDD's
- Actions: that returns values
reduce, collect, count... - Transformations: that returns another RDD
map, reduceByKey, filter...
Some operations trigger a shuffle task.
That needs to reorganize the data on nodes(really expensive it involves I/O and networking.
(join, cogroup, all by key operations)
All function passed to operations should be commutative and associative!!!!
Important notes:
- All operations are lazy
- We can persist the data in memory
- Don't use state from the scope of the program(broadcast and accumulator variables)
- Data is saved on disk in hdfs or others formats.
- We can use checkpoints that save on disk/memory , spark checks if the data is not on disk or in memory and only after that generates the rdd.
- Computations are made on different nodes, the work is divided in tasks(for each partition 1 task) each task has it's own JVM jobs.
Apache Spark
By Corneliu Caraman



