Data Analysis for Machine Learning Systems Design
Cristina Morariu
PhD, PMP, Mo2
AGENDA
Types of Machine Learning
Today's Environment
Data Analysis and Adjustments
Evaluating a Learning Algorithm
Useful Resources and Conclusions
Let me introduce myself...
PMP since 2009
PhD in Systems Engineering since 2013
Mother of Two
Passionate about AI
Proud founder of the SV AI Community
Today's Environment
“ML is a core, transformative way by which we’re rethinking how we’re doing everything”
Sundar Pichai, Google
“AI is the new electricity. Just as electricity transformed many industries roughly 100 years ago, AI will also now change nearly every major industry — healthcare, transportation, entertainment, manufacturing — enriching the lives of countless people.”
Andrew Ng, Standford
Machine Learning
Arthur Samuel (1959): Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
Tom Mitchell (1998): Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Supervised Learning
Supervised learning is the machine learning task of inferring a function from labeled training data.
The training data consist of a set of training examples. Each example is a pair consisting of an input object (typically a vector) and a desired output value.
Supervised Learning
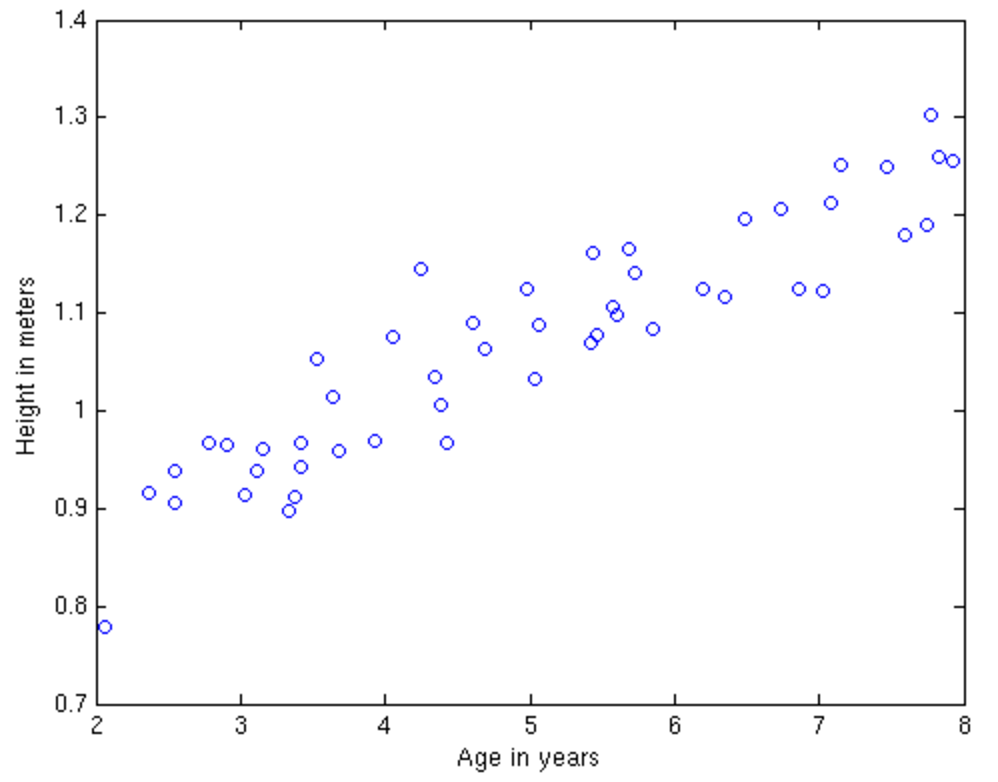

Regression
(Linear Regression)
Classification
(Logistic Regression)
Unsupervised Learning
Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses.
One of the widely used unsupervised machine learning algorithms is K-means, that splits the data in K clusters.
Unsupervised Learning
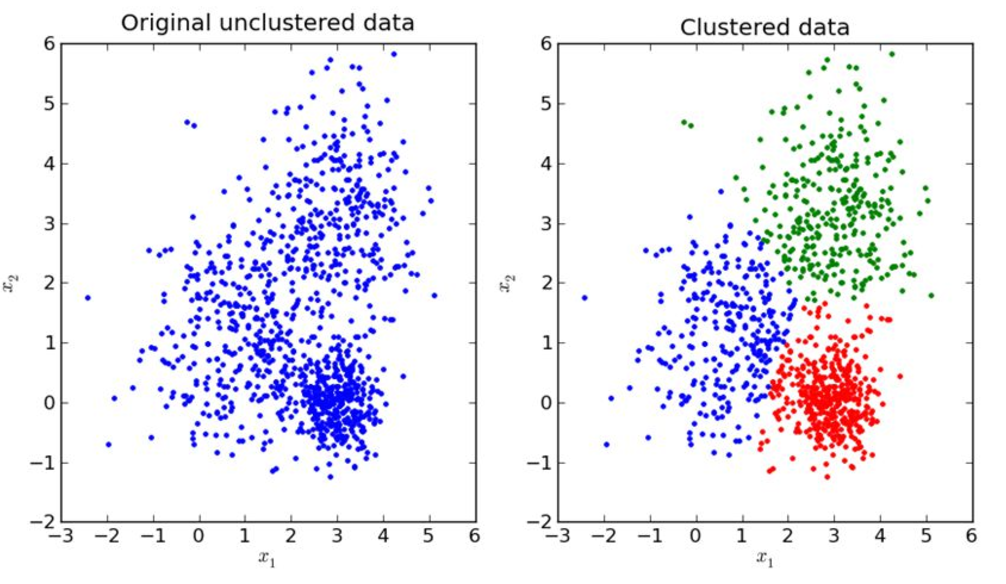
Input:
K - number of clusters
Training set
Random initialise K cluster centroids u1, u2, ... uk
Repeat {
for i=1 to m
c(i) := index(from 1 to K) of cluster centroid to x(i)
for k=1 to K
uk := average (mean) of points assigned to cluster k
}Feature Scaling
Usage:
In gradient descent algorithms decreases the time to run (to find the local minimum)
in Principal Component Analysis must be done before running the algorithm
size = 0 - 2000 sqm x1=size(sqm)/2000
rooms = 0 - 10 x2=number of rooms/10
Mean Normalization
The objective of mean normalisation is to get the mean close to 0.
x1= (x1-mean value)/range
range=max-min
-0.5<=x<=0.5
Features Selection
Improving the prediction performance
Faster and more cost effective predictors
Better understanding of the underlying process
Too many features
Independence of the features
Redundant features
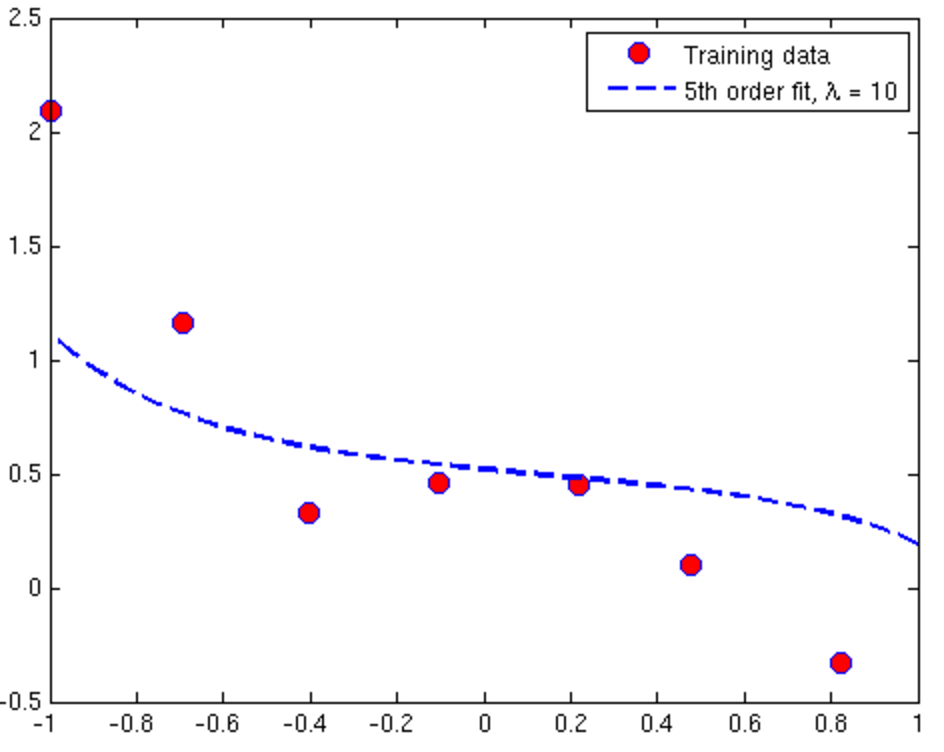
Overfitting and Underfitting in Linear Regression
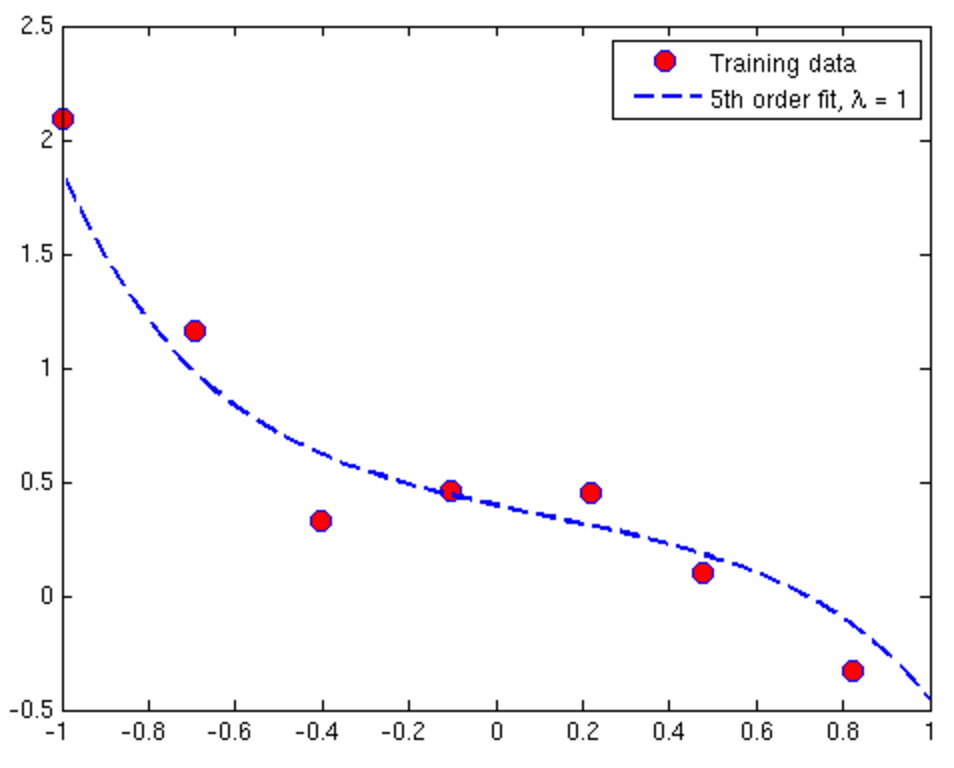
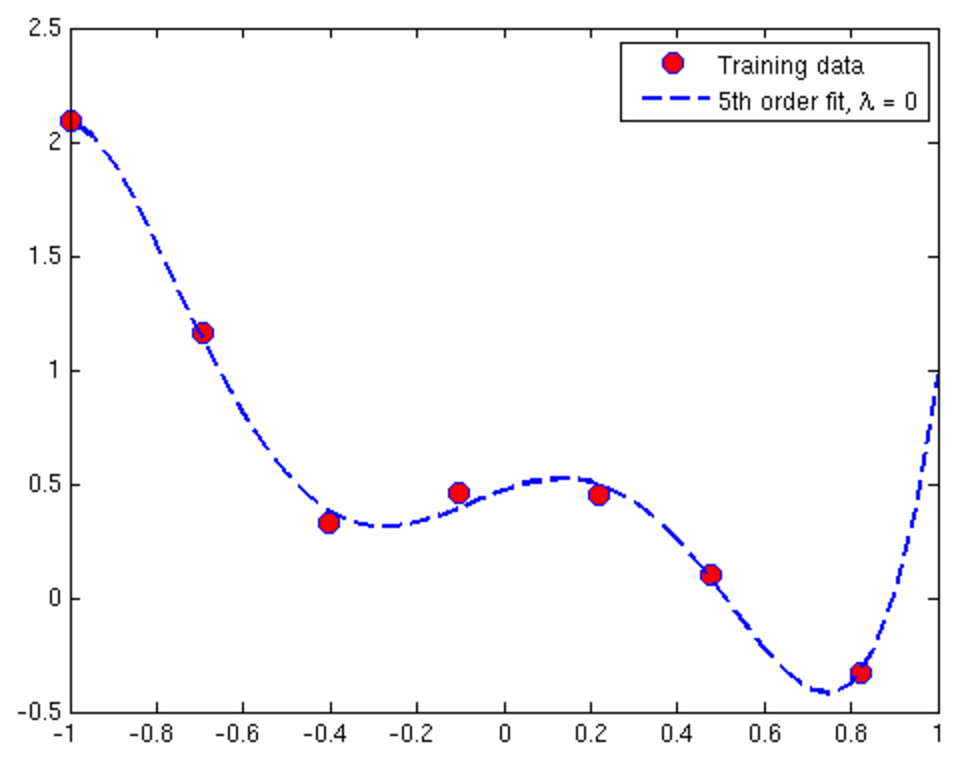
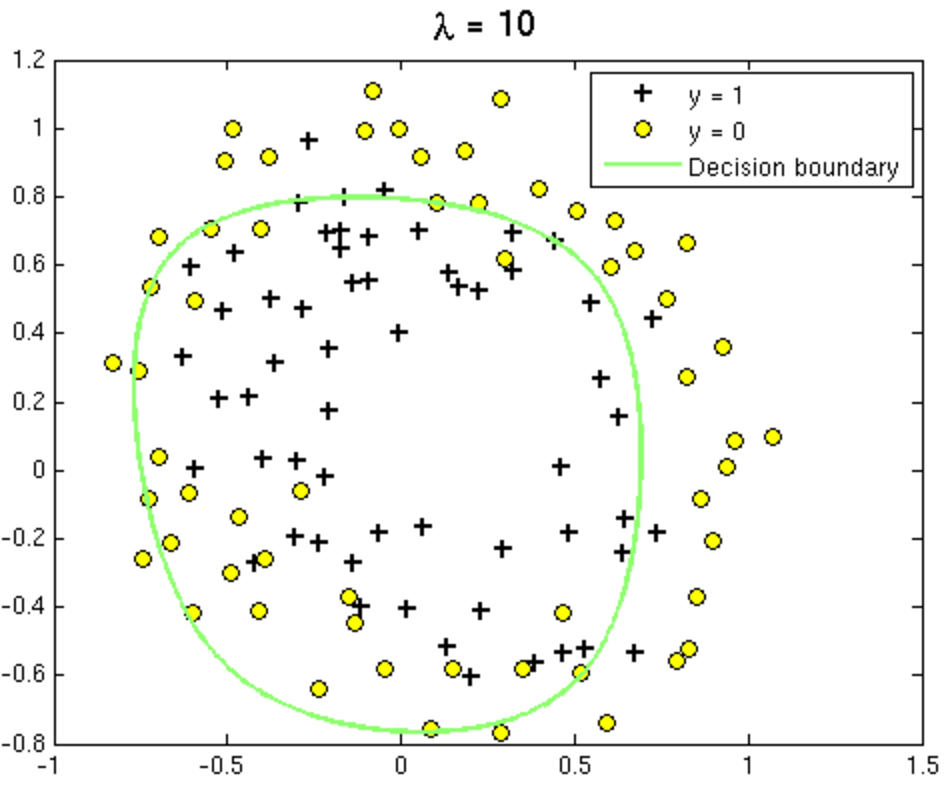
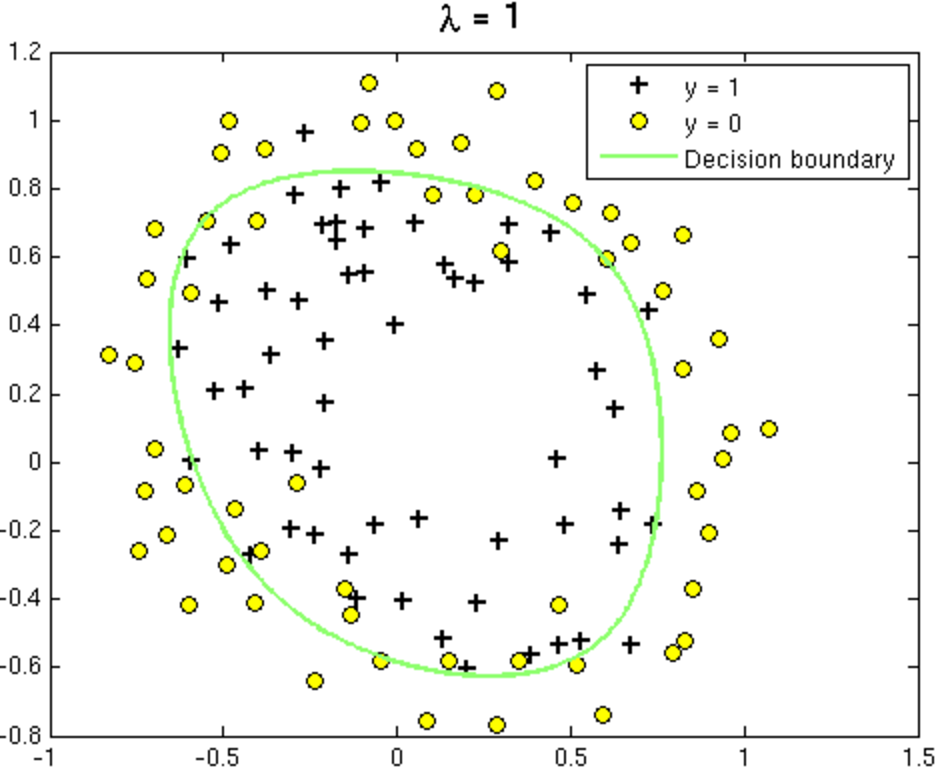
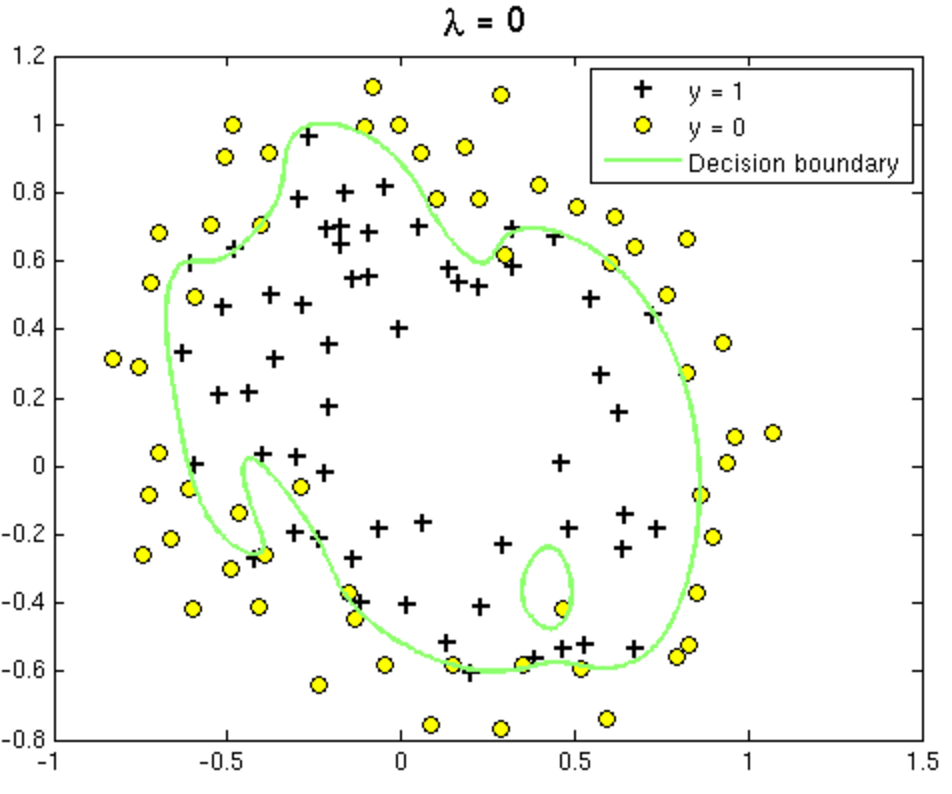
Overfitting and Underfitting in Logistic Regression
Corrective measures
Overfitting situation (High Variance)
- Get more training examples
- Try smaller set of features
- Try increasing Λ, the regularisation parameter
Underfitting situation (High Bias)
- Getting additional features
- Adding polynomial features
- Try decreasing Λ
Selecting & Evaluating Your Hypothesis
Training/ Test datasets (70/30)
1. Learn parameters using training data
2. Compute test error
Training/ Validation/ Test datasets (60/20/20)
1. Learn parameters using training data for different hypothesis
2. Choose the hypothesis with the lowest validation error
3. Test the chosen hypothesis using the test dataset
Conclusion
Before choosing an algorithm make sure:
- you have a clearly defined problem you want to resolve
- you understand your dataset
Useful materials
Thank you!
cristina.morariu@softvision.ro
morariu-cristina


Code Camp - Data Analysis
By Cristina Morariu

