Tensorflow in action
v.3

Intro about me





Nowadays ...





And we can reach by ...
JS?


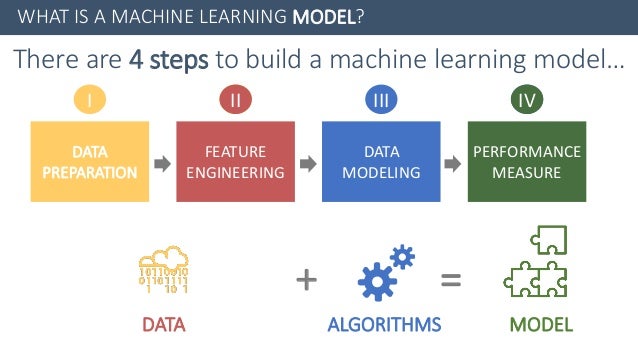
What can it do?
Run existing models
Retrain existing models
Develop ML with JavaScrip
The defence collapsed between front dev and AI
And all in real time!
-
learn from user behavior
-
adapt to user behavior
-
recommend the content
-
interact thought voice/gestues
Create smart apps that



Computer vision
The goal of computer vision
• To bridge the gap between pixels and “meaning”


Problems




Let's do it step by step
One of the solutions
Object detections
General object detection framework
Typically, there are three steps in an object detection framework.
-
Object localisation component.
-
Object classification component.
-
Overlapping boxes are combined into a single bounding box (that is, non maximum suppression).
Chronology
R-CNN -> fast R-CNN -> faster R-CNN
Problems with R-CNN
- It takes a huge amount of time to train the network as you would have to classify 2000 region proposals per image.
- It cannot be implemented in real time as it takes around 47 seconds for each test image.
- The selective search algorithm is a fixed algorithm. Therefore, no learning is happening at that stage. This could lead to the generation of bad candidate region proposals.


YOLO
Advantages and disadvantages of YOLO
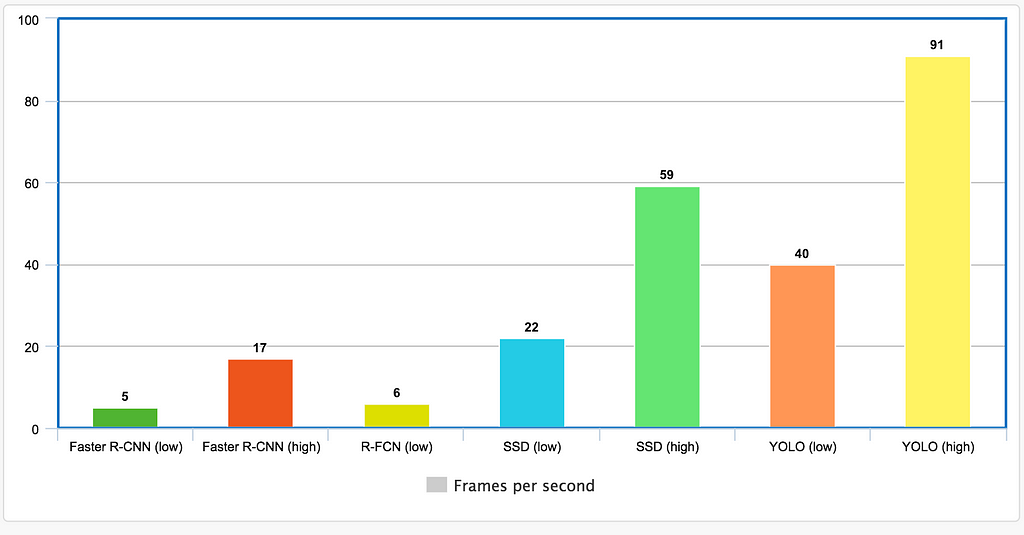
- YOLO is orders of magnitude faster(45 frames per second) than other object detection algorithms.
- The limitation of YOLO algorithm is that it struggles with small objects within the image, for example, it might have difficulties in detecting a flock of birds. This is due to the spatial constraints of the algorithm.
SSD
Advantages of SSD
- the balance between accurate and fast
Compare
accurate/fastest

I will use
-
"Common Objects in Context" dataset
-
SSD
Plan
- It requests the user's permission to use its webcam.
- If the user accepts (please do), it will fire up the webcam and consume its stream.
- 🔮 in ML
- Returns said frame.
- It loads the COCO SSD model.
- The model consumes the webcam feed, and check for objects.
- Then, it uses the model output to render the bounding boxes in the video frame.
In that time...
npm install @tensorflow/tfjs-node
npm install @tensorflow-models/coco-ssd - save
const webCamPromise = navigator.mediaDevices
.getUserMedia({
audio: false,
video: {
facingMode: "user"
}
})
.then(stream => {
window.stream = stream;
this.videoRef.current.srcObject = stream
return new Promise((resolve, reject) => {
this.videoRef.current.onloadedmetadata = () =>{
resolve();
};
});
});
detectFrame = (video, model) => {
model.detect(video).then(predictions => {
this.renderPredictions(predictions);
requestAnimationFrame(() => {
this.detectFrame(video, model);
});
});
};
const modelPromise = cocoSsd.load();
Promise.all([modelPromise, webCamPromise])
.then(values => {
this.detectFrame(this.videoRef.current,
values[0]);
})
.catch(error => {
console.error(error);
});
predictions.forEach(prediction => {
const x = prediction.bbox[0];
const y = prediction.bbox[1];
ctx.fillStyle = "#000000";
ctx.fillText(prediction.class, x, y);
});
npm install @tensorflow/tfjs-node
npm install @tensorflow-models/coco-ssd - save
npm install face-api.js
npm install p5.js
await faceapi.loadSsdMobilenetv1Model(MODEL_URL);
await faceapi.loadAgeGenderModel(MODEL_URL);
await faceapi.loadFaceExpressionModel(MODEL_URL); faceapi.detectAllFaces
(capture.id())
.withAgeAndGender()
.withFaceExpressions()
.then((data) => {
showFaceDetectionData(data);
});
if(capture.loadedmetadata) {
if (cocossdModel) {
cocossdModel
.detect(document.getElementById("video"))
.then(showCocoSSDResults)
.catch((e) => {
console.log("Exception : ", e);
});
}
}Tensorflow in action
By Khrystyna Landvytovych




