Exploration vs. Exploitation
Q-learning
Алгоритм
- Инициализируем \(Q(s, a) = 0\) для всех \(s, a\)
- Взаимодействуем со средой:
- \( a^* = \arg\max_a Q(s, a) \)
- \( s', r = \text{СРЕДА}(s, a^*) \)
- \(Q(s, a^*) := r + \gamma \max_{a'} Q(s', a') \)
- \( s \leftarrow s' \)
- \( a^* = \arg\max_a Q(s, a) \)
выбираем действие
применяем его в среде
обновляем Q-функцию
why exploration is needed?
Давайте научим робота идти вперед
x
0
r_t = x_{t+1} - x_t
Оценка \(Q\)-функции:
Q(s_0, a=\text{УПАСТЬ}) = 0
Q(s_0, a=\text{ШАГНУТЬ}) = 0
\arg\max_aQ(s_0, a) = \text{УПАСТЬ}
\Delta x
Q(s_0, a=\text{УПАСТЬ}) = \Delta x
Решение: с вероятностью \(\epsilon\) делаем случайное действие
Иначе, жадное( \epsilon \)
Exploration vs. Exploitation dilemma
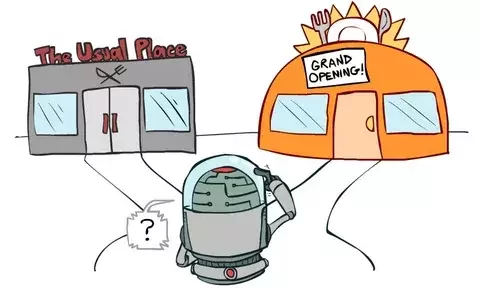

1. Add something to reward


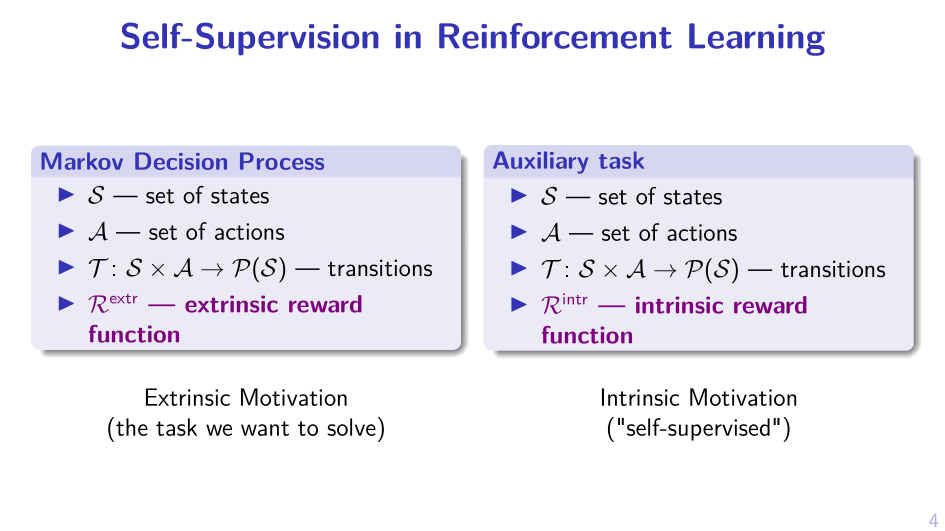

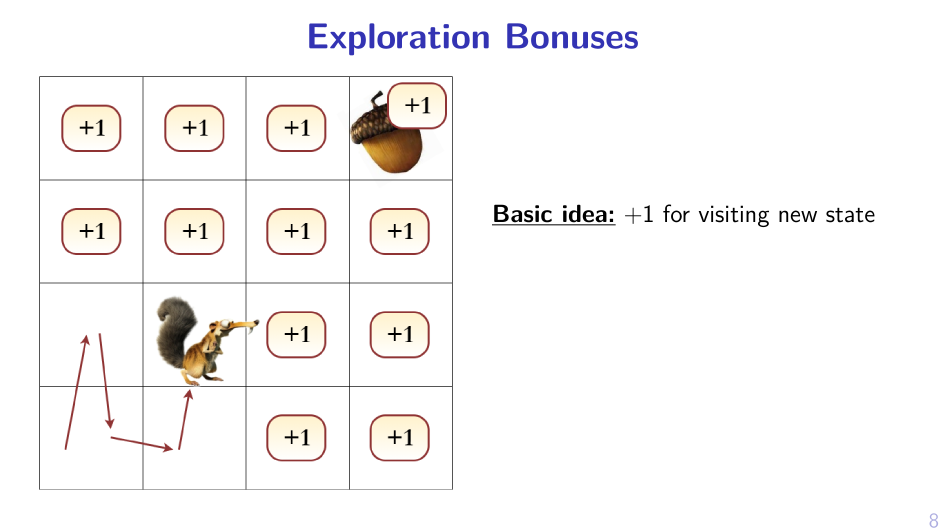
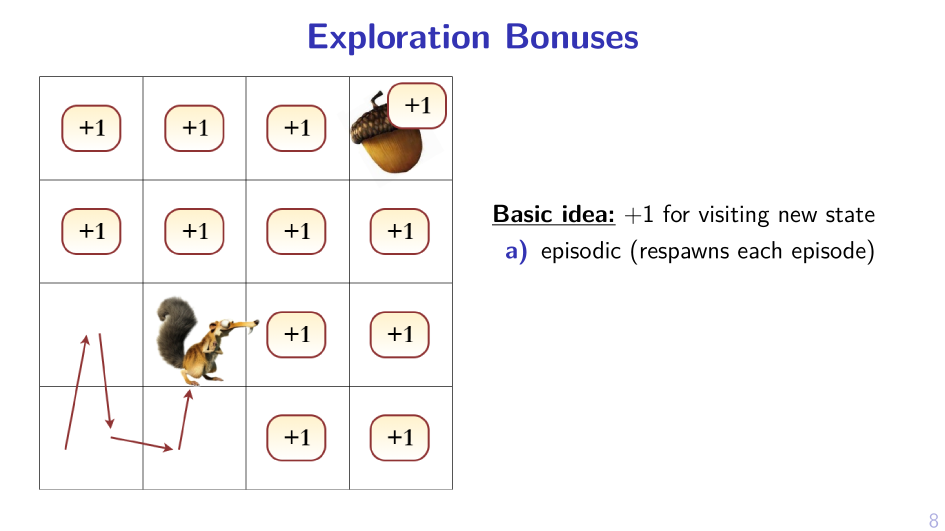
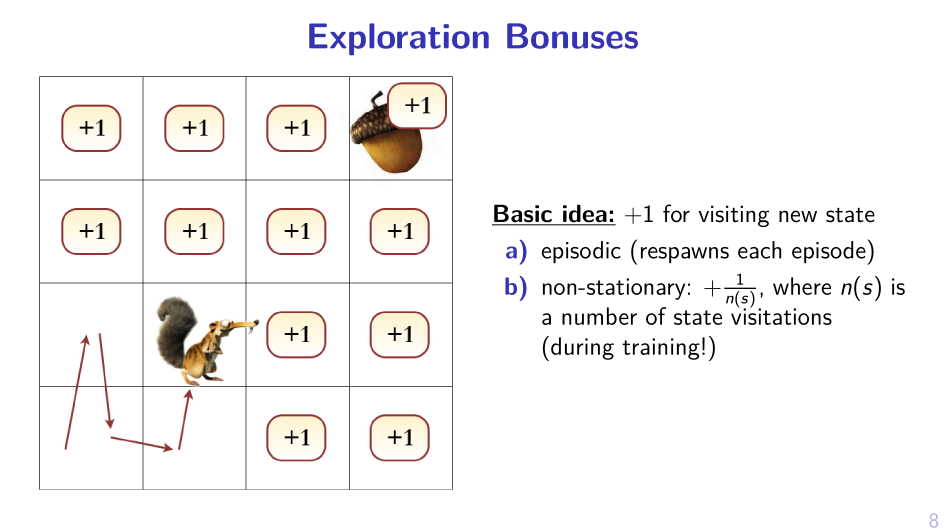
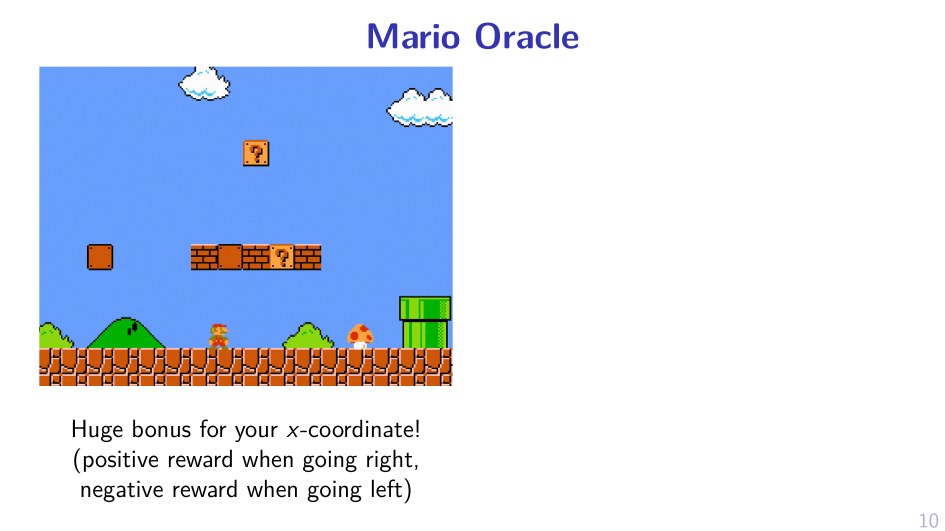


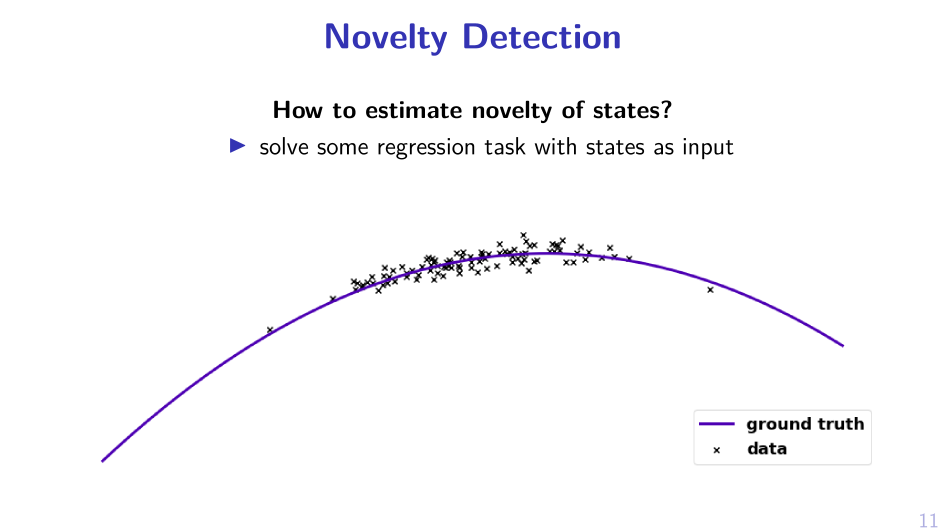
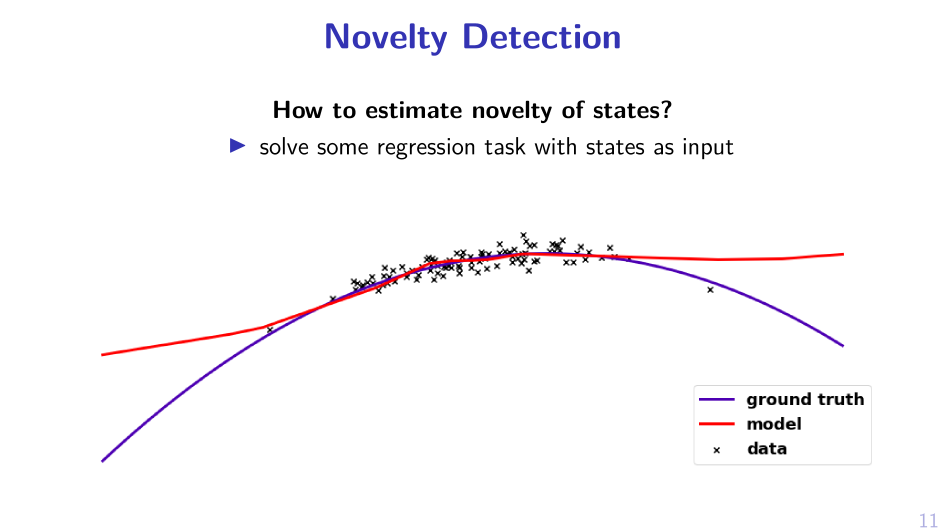





















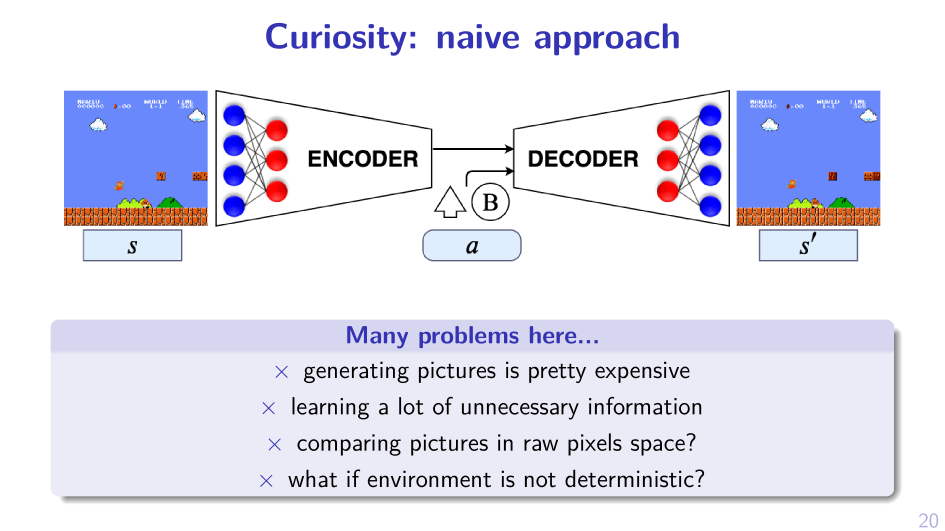
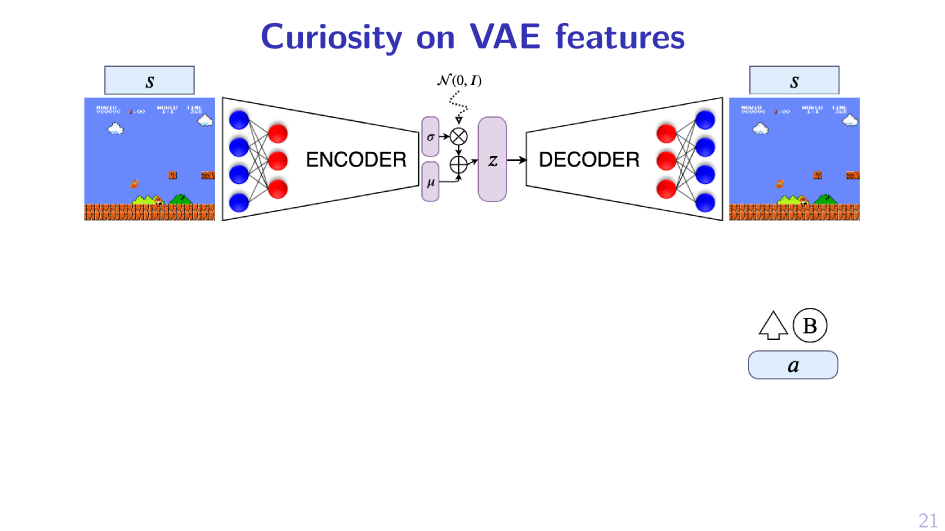
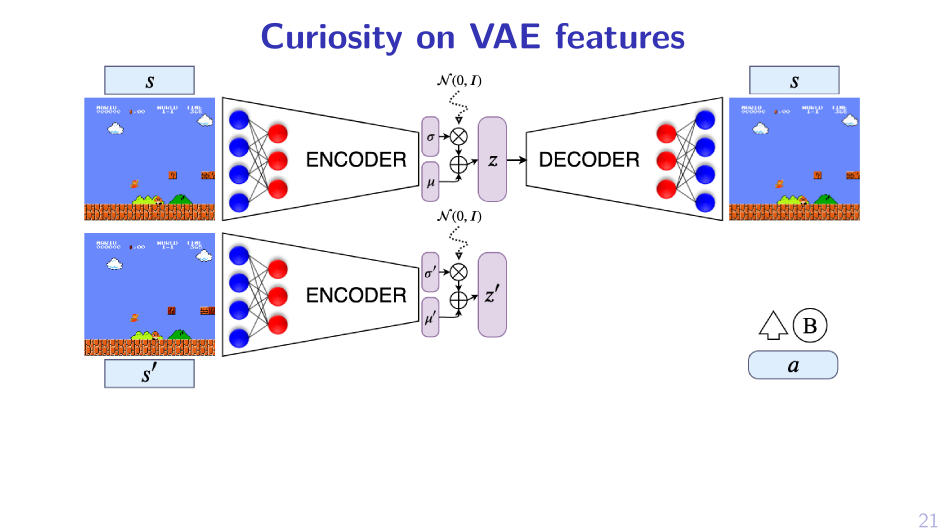
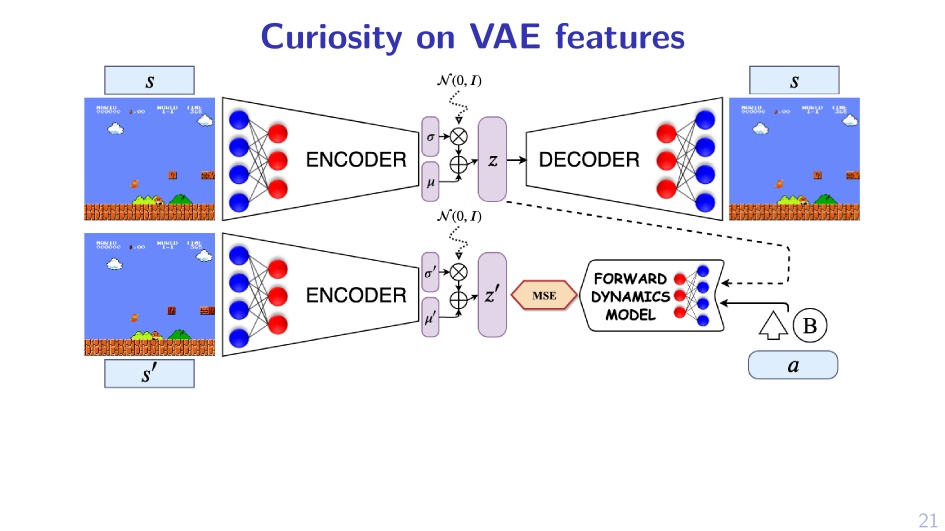
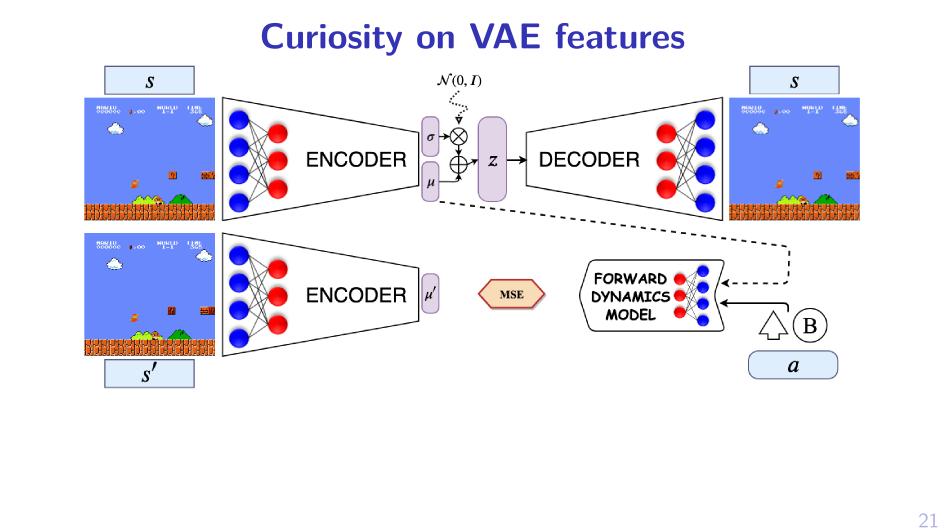
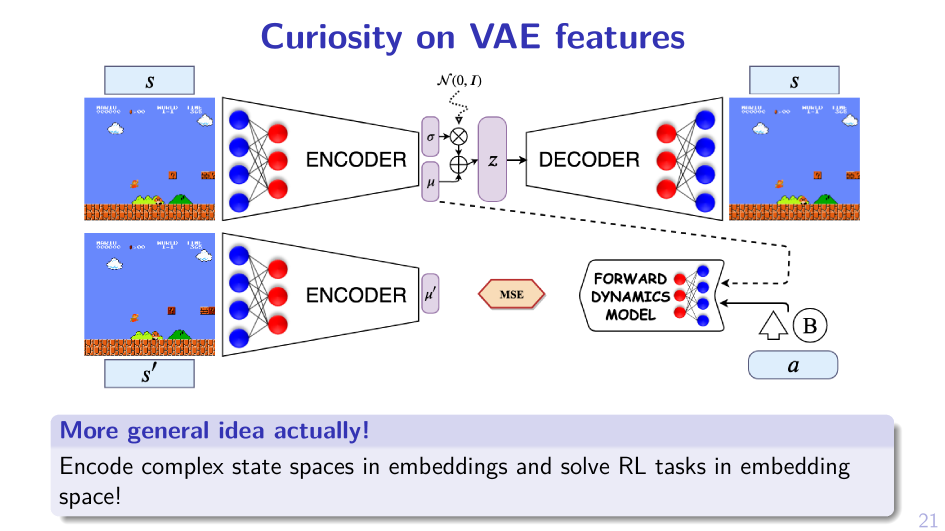










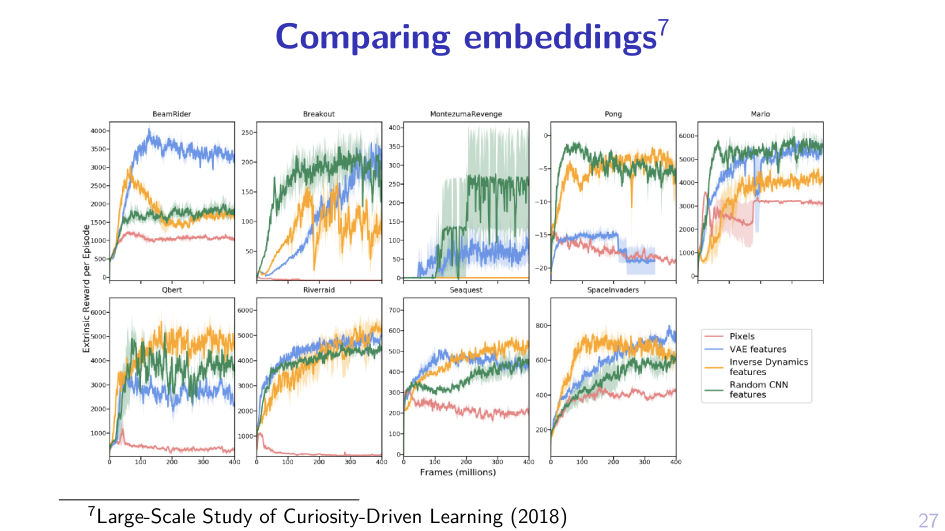


2. Sample MPD, act greedy in it
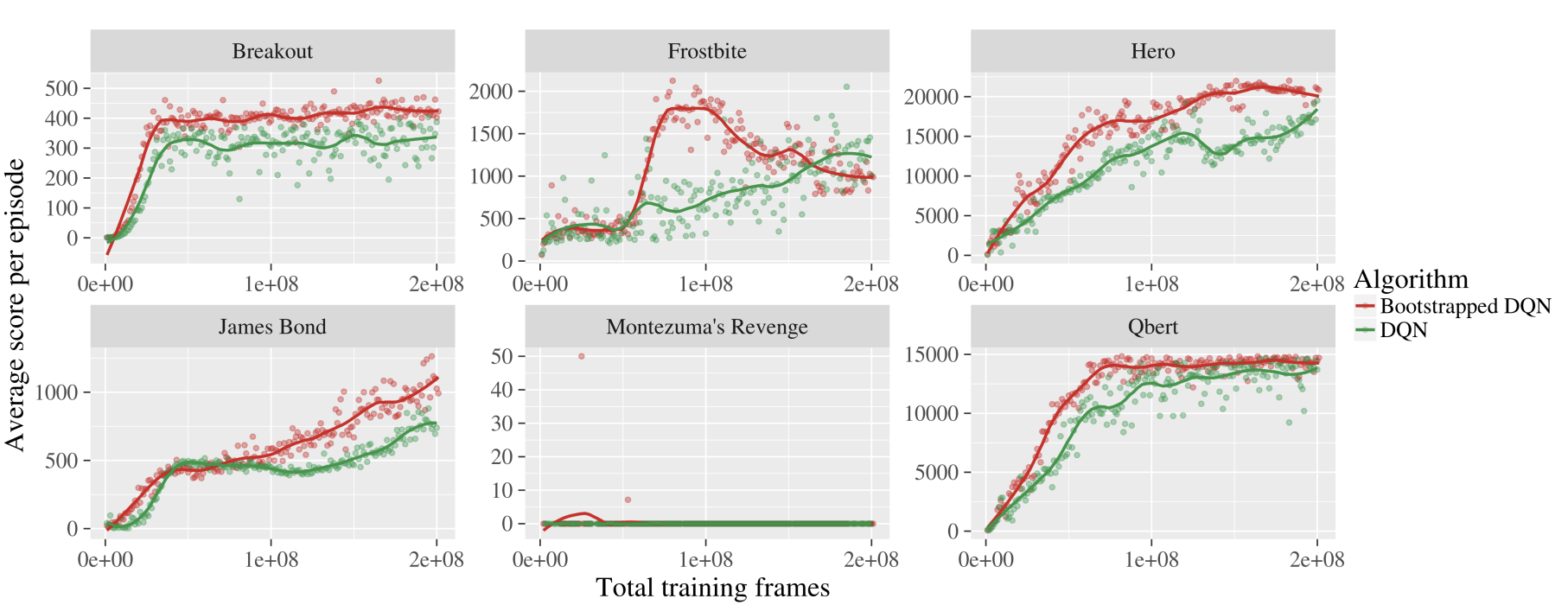
Bootstrapped DQN
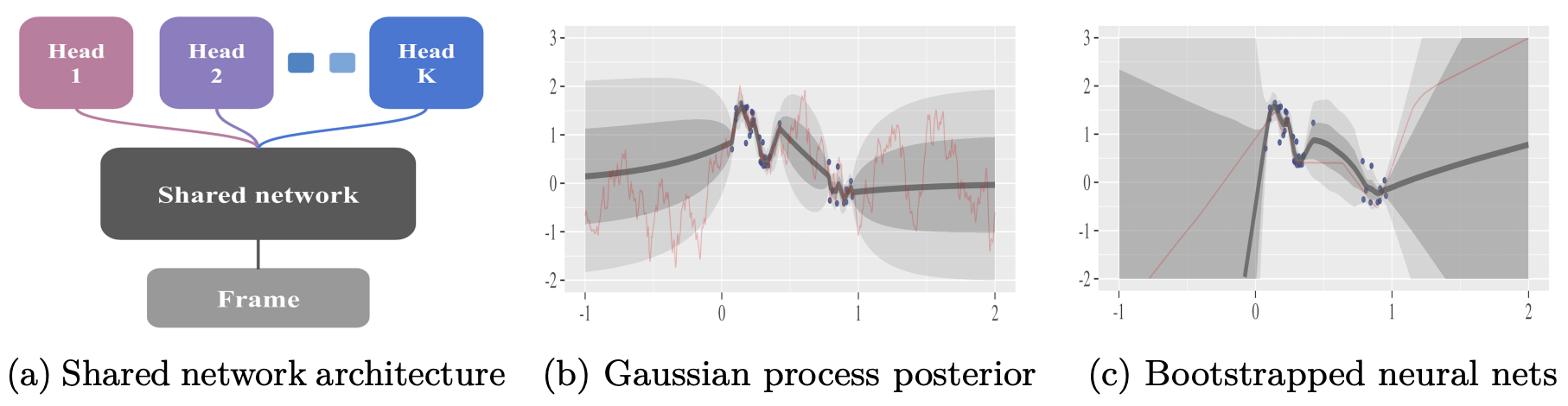
Bootstrapped DQN

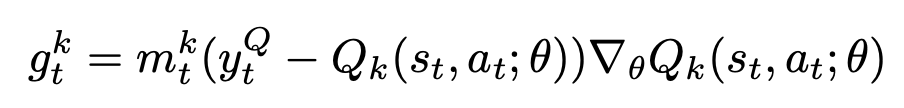
Gradient for the k'th head:
Bootstrapped DQN
Exploration vs. Exploitation
By cydoroga




