Topic modeling with mallet

Когда у тебя в руках молоток, все задачи кажутся гвоздями
slides.com/danilsko/mallet-2018
Пока начните скачивать
0. Подготовка
Installing mallet
Проверяем, что все работает:
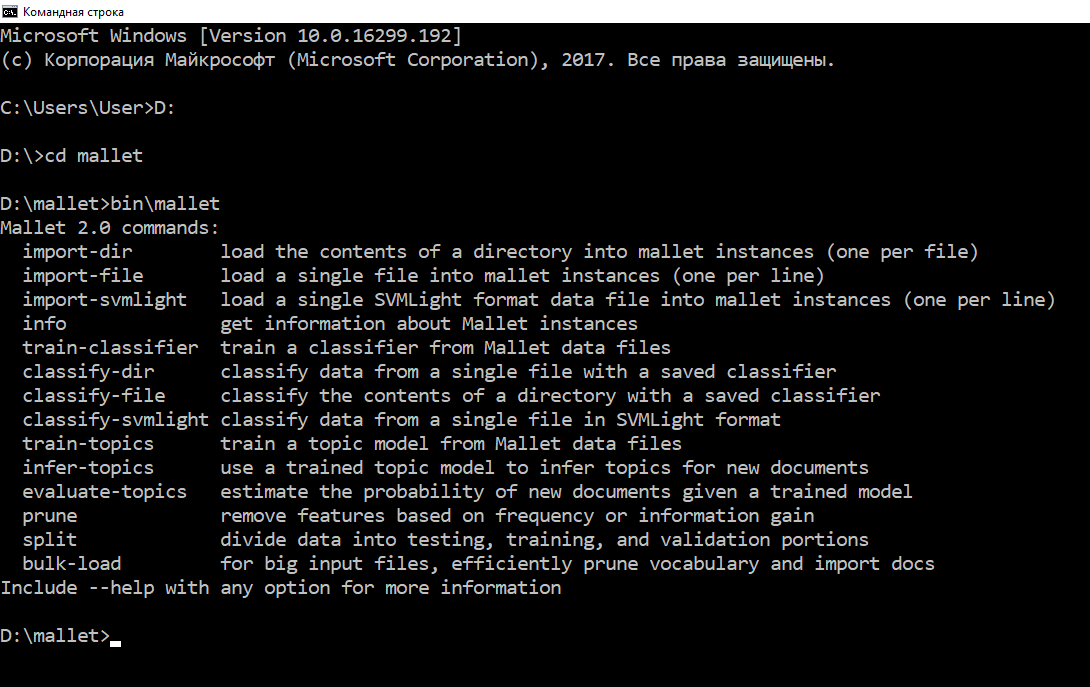
Проверяем, что все работает:
Mac/Linux:
- запускаем Terminal
- cd путь к папке mallet
- пробуем bin/mallet import-dir --help
NB: разделитель -- слэш (/) , а не бэкслэш (\)
Если непривычно работать в командной строке/терминале
1. Импорт данных
Нам понадобится команда import-dir
- load the contents of a directory into mallet instances (one per file)
-
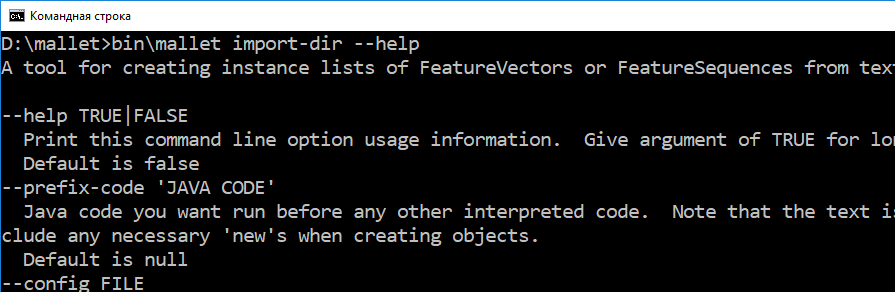
полезно уметь вызывать по любой команде хелпы:
- >bin\mallet import-dir --help
Основные параметры
- --input
- --output
Импорт данных
-
простейший импорт ( из уже готовых данных):
- >bin\mallet import-dir --input sample-data\web\en
- добавим output в формате .mallet:
- >bin\mallet import-dir --input sample-data\web\en --output tutorial.mallet
- На файл tutorial.mallet можно посмотреть в вашей рабочей папке, но увидите вы там немного
Больше параметров
- --skip-html
- --token-regex
- --remove-stopwords
- --stoplist-file
- --keep-sequence
Добавим keep-sequence
-
Нужно добавить --keep-sequence, чтобы можно было потом включить обучение (train-topics):
- >bin\mallet import-dir --input sample-data\web\en --output tutorial.mallet --keep-sequence
2. Обучение модели
(собственно тематическое моделирование)
Нам понадобится команда train-topics
- train a topic model from Mallet data files
Осн. параметры train-topics
- --input (файл в формате .mallet)
- --output-topic-keys (каждый топик в виде мешка слов)
- --num-topics (указать числом, сколько топиков вы хотите)
-
--num-top-words (сколько слов в мешке слов)
-
--output-topic-docs (распределение по документам: сколько какого топика в каком тексте)
Ваша первая модель
на sample-текстах, поставляемых с Mallet
- Просто попробовать запустить:
- >bin\mallet train-topics --input tutorial.mallet
- Добавим число топиков, вывод ключей (слов) каждой темы, вывод распределения тем по документам:
- >bin\mallet train-topics --input tutorial.mallet --output-topic-keys tutorial_keys.txt --output-doc-topics tutorial_docs.txt
Смотрим на результаты
- Открыть D:\mallet (или ту папку, в которую вы сложили mallet)
- Открыть tutorial_keys.txt (лучше при помощи Notepad++)
- Посмотрим на распределение этих топиков по документам: tutorial_docs.txt
- hint: если сделать из этого tutorial_docs.csv — его можно открыть табличным редактором типа Excel или Calc (лучше Calc)
Уберем стоп-слова
-
Надо сказать программе, какие слова убираем (параметр --stoplist-file):
-
--stoplist-file stoplists\en.txt
-
- Заново импортируем наши данные:
- > bin\mallet import-dir --input sample-data\web\en --output tutorial.mallet --keep-sequence --stoplist-file stoplists\en.txt
- И обучим модель как в прошлый раз с помощью train-topics (просто стрелочкой вверх пролистайте команды в командной строке/терминале)
3. Работа со своими данными
Загрузим что-нибудь свое:
Загрузим что-нибудь свое
- например игру престолов...
- сделаем папку 'mydata'
- bin\mallet import-dir --input mydata\ASOIAF --output tolstoy.mallet --keep-sequence
..and train the model
- bin\mallet train-topics --input asoiaf.mallet --output-topic-keys asoiaf_keys.txt --output-doc-topics
загрузим Войну и мир
Text
Removing Russian stopwords
- download stop_ru.txt
- put it to 'D:mallet\stoplists'
- add parameter
- --stoplist-file stoplists\stop_ru.txt
- bin\mallet import-dir --input our-data\writers --output writers.mallet --keep-sequence --stoplist-file stoplists\stop_ru.txt
lifehack:
-
for stopwords go to
http://www.ranks.nl/stopwords/
lifehack 2:
-
...and then you can just add more stopwords to stop_ru.txt manually!
-
just don't forget to re-import data after editing the stoplist
training on cleaner data
- bin\mallet import-dir --input our-data\tolstoy --output tolstoy.mallet --keep-sequence --stoplist-file\stop_ru.txt
- bin\mallet train-topics --input tolstoy.mallet --num-topics 4 --optimize-interval 4 --output-topic-keys tolstoy_keys.txt --output-doc-topics
What about morphology and inflection?
training on lemmatized data
- bin\mallet import-dir --input mydata\Tolstoy\lemm --output tolstoy.mallet --keep-sequence --stoplist-file\stop_ru.txt
- bin\mallet train-topics --input tolstoy.mallet --num-topics 4 --optimize-interval 4 --output-topic-keys tolstoy_keys.txt --output-doc-topics
training on lemmatized data
- для своего проекта желающие могут заказать лемматизацию у меня (skorinkin.danil@gmail.com)
- лемматизировано будет автоматически, поэтому возможны ошибки (но в целом все должно быть ок)
Годный туториал:
https://programminghistorian.org/lessons/topic-modeling-and-mallet
Mallet Hands on 2018
By danilsko



