Stylometry
quantitative authorship attribution
and beyond

Daniil Skorinkin, DH Network Potsdam
Agenda for today
1. What is Stylometry
Stylometry in a nutshell
is using frequencies of textual units to detect the 'authorial signal' in texts
(that's a narrow definition, but enough for now)
Джоан Роулинг

underlying stylometric studies is that authors have an unconscious as well as conscious aspect to their style
Encyclopaedia of Statistical Sciences
The main assumption
Basic stylometric procedure
(aka what actually happens)

Basic stylometric vizualisations
(how to show these distances)
Dimensionality reduction methods (PCA MDS tSNE etc)

Hierarchical clustering dendrograms
Weighted graphs
(Weighted networks)

Basic stylometric vizualisation
(how to show these distances)
Dimensionality reduction methods (PCA MDS tSNE etc)

Hierarchical philogenetic tree style dendrograms
Weighted graphs
(Weighted networks)
Beyond authorship
- Intra-authorial stylometry
- Style (stylochronology)
- Genres within one author (e.g. Shakespeare)
- Heteronymy
- ...
- Collaboration of authors
- Co-authorship
- Translation
- Influence of the editor
But attribution is still the main purpose
Because authorship disputes are hot topics
Presumably, each national literature has its own famous unsolved attribution case, such as the Shakespearean canon, a collection of Polish erotic poems of the 16th century ascribed to Mikołaj Sęp Szarzyński, the Russian epic poem The Tale of Igor’s Campaign, and many other.
Eder M. (2011) Style-markers in authorship attribution: A cross-language study of the authorial fingerprint.
BTW here's my favourite definition of DH:
Taking tools built by warmongers, spy agencies & investment bankers and using them to study literature, philosophy, culture and the classics
(Elijah Meeks, Stanford Digital Scholarship)
2. Does it actually work?
Yes, here is the live demo 🎥
Disclaimer
- ⚠️ Stylometric attribution is no magic or silver bullet
- ⚠️ There are many cases in which stylometry wont help detect the author
- 🟢 But at the same time modern state-of-the-art stylometry is not an ad hoc method — it works universally given certain conditions
3. How does it work?
in all their variety of material and method, have two features in common: the <...> texts they study have to be coaxed to yield numbers, and the numbers themselves have to be processed via statistics.
M. Eder, M. Kestemont, J. Rybicki. ‘Stylo’: a package for stylometric analyses
Stylometric studies
remember: texts "have to be coaxed to yield numbers"
so it's mostly about counting frequencies
- Words
- especially function words
- Lemmas
- Symbol N-grams
- Word N-grams
Less typical but still works sometimes:
- POS tags
- Syntactic structures
- Metric structures
Frequencies of
So behind this picture:
There's the frequency table:

Each text is a column
Each text is a vector
Let us simplify to just two dimensions
Let us simplify to just two dimensions
Let us simplify to just two dimensions

the 'and' axis
the 'the' axis
Now we can
measure distances between texts!
Stylometry does the same, but with many more words, not just 2. So same happens in 100/300/1000-dimensional space
Джоан Роулинг
But there are ways to compress such spaces and vizualize in 2D
But wait! These features are meaningless!!
How can they contain the 'authorial signal'?
J. F. Burrows:
Most readers and critics behave as though common prepositions, conjunctions, personal pronouns, and articles — the parts of speech which make up at least a third of fictional works in English — do not really exist. But far from being a largely inert linguistic mass which has a simple but uninteresting function, these words and their frequency of use can tell us a great deal <...>
Preface to Computation into Criticism, 1987

Burrows Delta
- State of the art in authorship attribution since 2002
- Makes use of measuring distances between vectors of N most frequent words / charcacter n-grams
- (though more complex features are also possible)
- Built into Stylo
4. Real world application showcase
Who wrote 'To Kill a Mockingbird'?
Harper Lee

Oh, Real-Lee?
The new 'old' book (2015)

Causes for suspicions (external)
- After publishing 'To kill a Mockingbird' Lee hasnt published a book in 55 years
- The manuscript was 'accidentaly found' by Lee's lawyer
- In 2015 Lee was 88, blind and severely disabled
- Alabama authorities actually did an investigation of Lee's legal capacity
- Contradicting statements regarding the manuscript
- a draft of 'To Kill a Mockingbird'
- or a separate work in the same fictional realm
Causes for suspicions (internal)
- Many deemed the 'new' work 'poor' compared to the classical 'To Kill a Mockingbird'
- Plot-wise the new text is a sequel (the main herione is an adult), though the claim was it had been written earlier
- A lot of disappointment in Atticus Finch who turns out to be kind of a racist in the 'new' book
Were the books written by one person?

Harper Lee and Truman Capote


Why Capote?
- Harper Lee's childhood friend, grew up together in the city which became the prototype for the city in 'To Kill a Mockingbird'
- prototype for one of the characters in 'To Kill a Mockingbird'
- In the time of writing 'To Kill a Mockingbird' , Capote published nothing big
- Afterwards Capote wrote his true-crime bestseller "In Cold Blood" which Lee helped to work with
- Hypotheses: then Lee thanked Capote by helping with "In Cold Blood"
This is what the stylometrists went on to test

Harper Lee homogeneity (dendrogram)
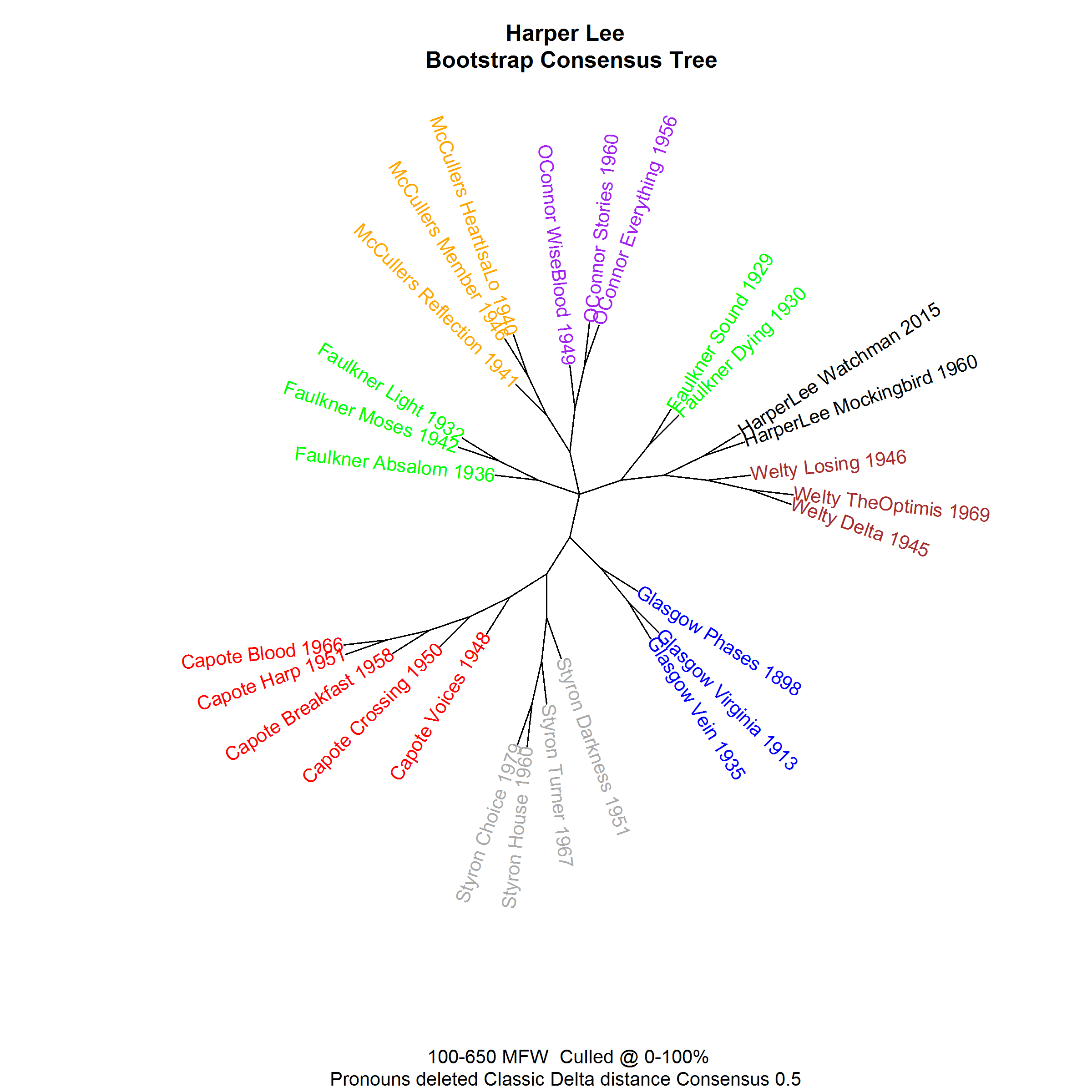
Harper Lee homogeneity (network)
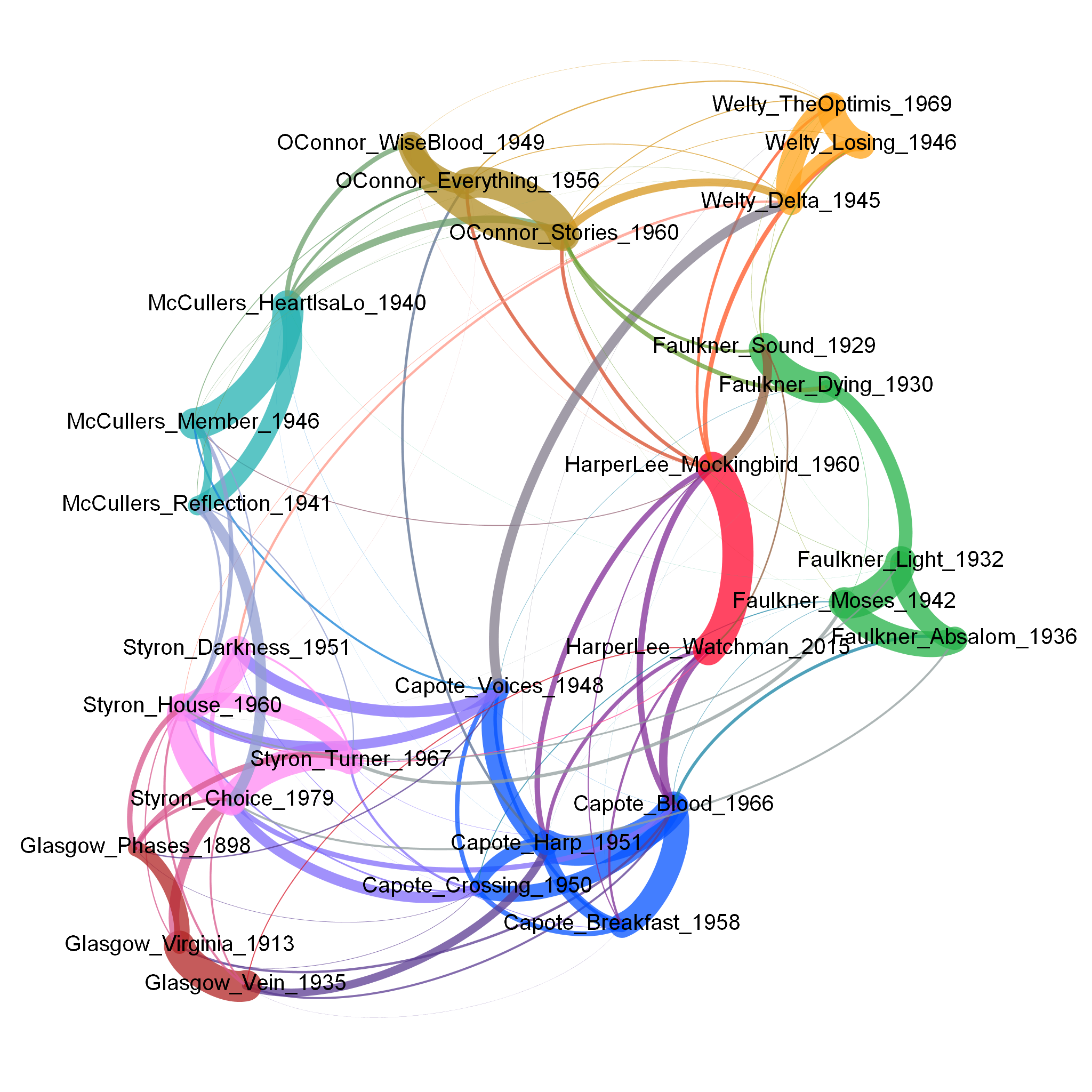
By the way we can reproduce it in stylo:
> data(lee)
> stylo(frequencies=lee)
5. Okay, Danya, enough stories, just tell us how to do it!
Stylo hands-on
6. Bonus 1: more Stylo functions
classify ()
- text classification with stylometry features
- main tool for actual authorship attribution
- employs standard machine-learning algorithms
- requires two sets of documents
- training (primary_set)
- test (secondary_set)
rolling.classify ()
- dynamic changes in the text
- text window of adjustable size

oppose ()
- contrastive analysis
- words significantly preferred/avoided
- comparison studies (e.g. male vs female styles)
- when launching with non-latin script data:
oppose(corpus.lang="Other")
Oppose

7. Bonus 2. Stylometry beyond authorship attribution
But the study of literature and authorship is not only who wrote what, and who didn’t
Maciej Eder, Jan Rybicki (2016). Go Set A Watchman while we Kill the Mockingbird in Cold Blood, with Cats and Other People
Beyond authorship
- Intra-authorial stylometry
- Style (stylochronology)
- Genres within one author (e.g. Shakespeare)
- Heteronymy
- ...
- Collaboration of authors
- Co-authorship
- Translation
- Influence of the editor
Translation
Inside Shakespeare

From French...

...to English

Collaborative translation
Night and Day
by Virginia Woolf

Anna Kołyszko -> Magda Heydel


Maciej Eder, Jan Rybicki
Some history
Quantifying style
-
1851 — A. De Morgan suggests mean word-length as an authorship feature
-
1873 — New Shakespeare Society (Furnival, Fleay et al)
-
1887 — T. Mendenhall, The Characteristic Curves of Composition, the first known work on quantitative authorship attribution

Federalist papers
- 12 disputed papers (Hamilton or Madison)
- Mosteller F., Wallace D., (1963) Inference in an Authorship Problem.
- '<...> to solve the authorship question of The Federalist papers; and to propose routine methods for solving other authorship problems'.

Mosteller, Wallace, 1963

Mosteller, Wallace, 1963
- The function words of the language appear to be a fertile source of discriminators, and luckily the high-frequency words are the strongest.
- <...>it is important to have a variety of sources of material, to allow “between writings” variability to emerge

Mosteller, Wallace, 1963
In summary, the following points are clear:
- Madison is the principal author. These data make it possible to say far more than ever before that the odds are enormously high that Madison wrote the 12 disputed papers. <...>
- <...> While choice of underlying constants (choice of prior distributions) matters, it doesn’t matter very much, once one is in the neighborhood of a distribution suggested by a fair body of data.
Cyrillic issues on Mac
- Open Terminal and execute
defaults write org.R-project.R force.LANG en_US.UTF-8
- ...or in R execute this:
>system("defaults write org.R-project.R force.LANG en_US.UTF-8")
Z-score
Text
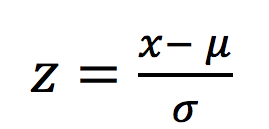
where
- x – frequency of a word
- µ - mean frequency of a word in the whole corpus (collection of texts)
- σ - standard deviation
Adversarial stylometry
- deceiving authorship detection
- countermeasures to deception
- de-anonymization
- demographics detection
-
native language identification
- ...potentially allows you to harrypoterize your fanfic =)

And even this:

Stylometry Intro HUJI-FUB
By danilsko
Stylometry Intro HUJI-FUB
Stylometry workshop Israel




