Stylometrie
Kann ein anonymer Text mithilfe von Statistiken einem Autor zugeordnet werden?
Oracle Inspiration Day
Daniil Skorinkin, DH-Netzwerk Potsdam
Was vereint all diese Bücher?



Was vereint all diese Bücher?


Das wurde für diese Vorlesung mit Delta, der heutigen Standardmethode der Stylometrie, reproduziert:

Was ist Stylometrie?
Stylometrie...
beschäftigt sich damit, die Häufigkeiten bestimmter „atomarer“ Textelemente zu untersuchen, um darin das „autoriale Signal“ eines Textes zu erkennen.
(Das ist eine enge Definition – aber für den Anfang ausreichend.)
Was sind diese atomaren Textelemente?

Schauen wir uns einen Text an. Wie könnten wir ihn aufteilen?
Was sind diese atomaren Textelemente?

Wörter
Was sind diese atomaren Textelemente?

Zeichen-n-Gramme (hier n = 4)
Was sind diese atomaren Textelemente?

Wort-n-Gramme (hier n = 3)
Aber meistens … einfach Wörter!
oder manchmal normalisierte Wörter (Lemmata)

Aber meistens … einfach Wörter!
Und weil wir über Worthäufigkeiten sprechen …
...diese Wörter sind die "bedeutungslosesten"
und die der ich sie das in er nicht zu den es ein sich mit so von war aber ist auf dem wie auch als eine an daß was noch du mir wenn ihr da hatte aus nur mich im nach doch wir des um ja einen man sein ihm wieder immer vor denn für über oder einem sagte dann alles hat nun ihn einer ganz schon haben bei sind seine frau am hier meine mehr nichts jetzt etwas diese habe ihre uns waren durch alle mein dieser werden bis unter wo kann zum wird will seiner sah wurde herr...
...diese Wörter sind die "bedeutungslosesten"
the and to of a was i in he said you that it his had on at her with as for not him they she were but be have up all out is from them me been what this about into like back my there would we could one now know if their so or no do down your an did by are when who looked more over then see again time just don^t still very think got will off re go eyes than before right here get away thought i^m came too through only long way going face come some can
Könnten diese Wörter sinnvolle Merkmale für die Autorschaft sein?
Ja!
Die Häufigkeiten dieser Wörter...
the and to of a was i in he said you that it his had on at her with as for not him they she were but be have up all out is from them me been what this about into like back my there would we could one now know if their so or no do down your an did by are when who looked more over then see again time just don^t still very think got will off re go eyes than before right here get away thought i^m came too through only long way going face come some can
...waren alle 'Features' des vorherigen Experiments.
Ok, aber wie genau funktioniert das?
Springen wir für einen Moment zurück in die frühen 1960er-Jahre.
Federalist papers
- 12 umstrittene Artikel (Hamilton oder Madison)
- Mosteller, F. & Wallace, D. (1963): Inference in an Authorship Problem.
- '<...> to solve the authorship question of The Federalist papers; and to propose routine methods for solving other authorship problems'.

Word counts are the variables used for discrimination. Since the topic written about heavily influences the rate with which a word is used, care in selection of words is necessary. The filler words of the language such as an, of, and upon, and, more generally, articles, prepositions, and conjunctions provide fairly stable rates, whereas more meaningful words like war, executive, and legislature do not.
Mosteller, F. & Wallace, D. (1963): Inference in an Authorship Problem.
Mosteller, Wallace, 1963

Mosteller, Wallace, 1963
- "The function words of the language appear to be a fertile source of discriminators, and luckily the high-frequency words are the strongest".
- These data make it possible to say far more than ever before that the odds are enormously high that Madison wrote the 12 disputed papers. <...>

Mosteller, Wallace, 1963
- <...>it is important to have a variety of sources of material, to allow “between writings” variability to emerge
- While choice of underlying constants (choice of prior distributions) matters, it doesn’t matter very much, once one is in the neighborhood of a distribution suggested by a fair body of data.
- The function words of the language appear to be a fertile source of discriminators
J. F. Burrows, 1987:
Most readers and critics behave as though common prepositions, conjunctions, personal pronouns, and articles — the parts of speech which make up at least a third of fictional works in English — do not really exist. But far from being a largely inert linguistic mass which has a simple but uninteresting function, these words and their frequency of use can tell us a great deal <...>
Preface to Computation into Criticism, 1987

Im Jahr 2001 führte Burrows die Delta-Methode ein


Und das hier ist Delta:
Okay – und wie genau funktioniert das?
Offensichtlich beginnen wir mit einer Liste von Büchern...
Book A by author A (AA)
Book B by author A (BA)
Book С by author A (CA)
Book A by author B (AB)
Book B by author B (BB)
Book С by author B (CB)
Book A by author C (AC)
Book B by author C (BC)
Book С by author C (CC)
Some dubious book (??)
...und enden mit einem Hinweis auf ihre Ähnlichkeiten
??
Aber was passiert
dazwischen?
Zuerst teilen wir den gesamten Text in Wörter und erstellen eine Häufigkeitstabelle

Jedes Buch ist eine geordnete Spalte von Häufigkeiten
Jedes Buch ist ein Vektor
Reduzieren wir das zunächst auf zwei Dimensionen:
Wir behalten nur „the“ und „a“. Jetzt haben wir zweidimensionale Vektoren.

die 'and'-Achse
die 'the'-Achse
Jetzt können wir
'Abstände' zwischen Texten messen!
Die Stylometrie macht dasselbe – nur mit viel mehr Wörtern, nicht nur mit zwei. Dasselbe geschieht also in einem 100-, 300- oder 1000-dimensionalen Raum.
the
and
of
to
Und die Entdeckung, die Burrows machte – und die seitdem viele andere bestätigt haben – lautet: Im Allgemeinen sind die Abstände zwischen Texten desselben Autors deutlich kleiner, fast unabhängig vom Inhalt.
Джоан Роулинг

Es gibt Methoden, solche multidimensionalen Räume zu komprimieren und die Ähnlichkeiten in 2D zu visualisieren
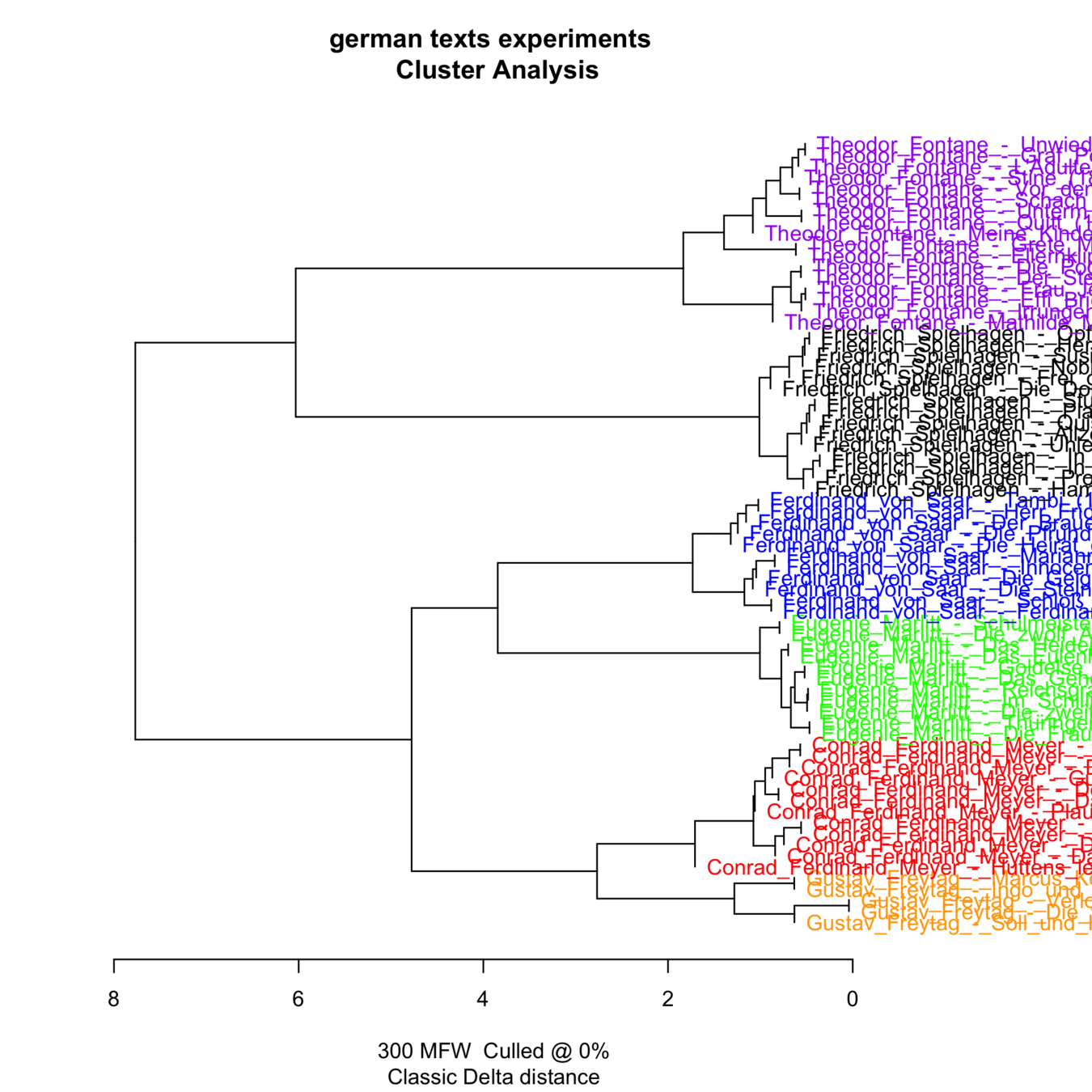
Aber die hierarchische Clusteranalyse mit einem Dendrogramm ist viel populärer
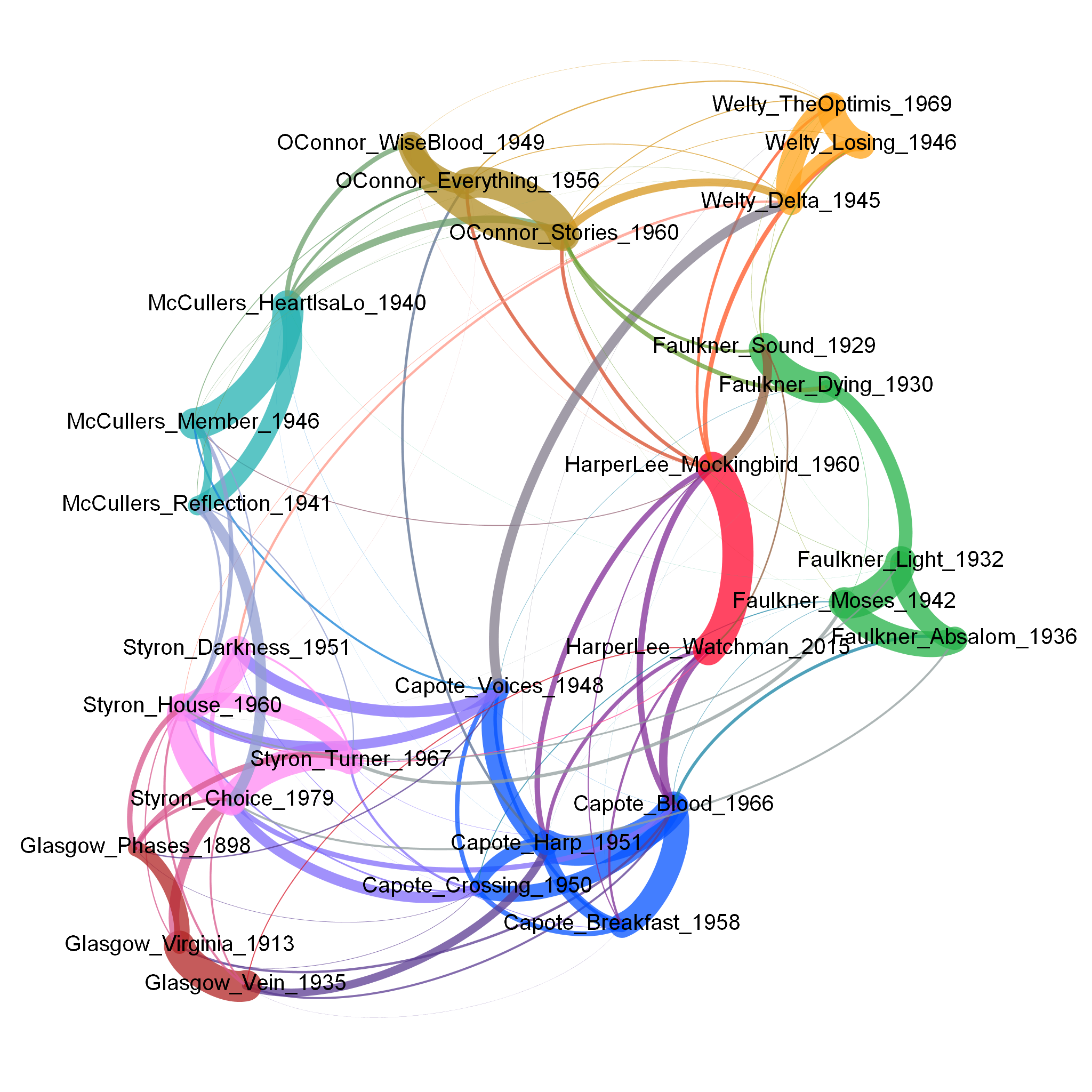
Eine weitere beliebte Option ist ein Netzwerk (ein Graph) der stilometrischen Nähe

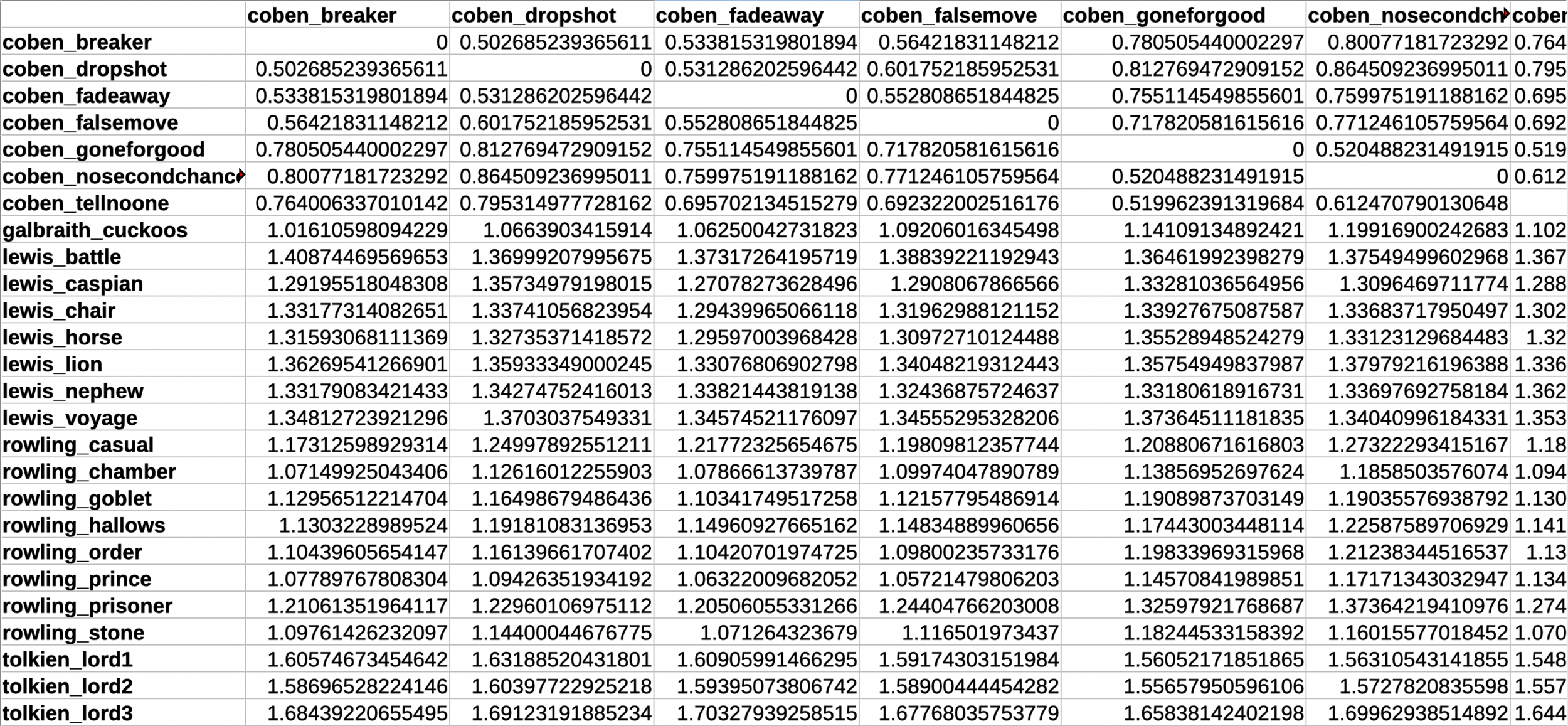
Und wir können uns jederzeit die tatsächliche geometrische Distanztabelle ansehen
Okay, aber ist das wirklich eine universelle Methode, um Autorschaft zu erkennen?
Ja, aber
- ⚠️ Stilometrische Autorschaftszuschreibung ist keine Magie und kein 'Allheilmittel'.
⚠️ Es gibt viele Fälle, in denen die Stylometrie nicht hilft, den Autor zu identifizieren.
🟢 Gleichzeitig ist die moderne Stylometrie keine Ad-hoc-Methode – sie funktioniert universell, sofern bestimmte Bedingungen erfüllt sind.
Deutsche Romane
Russische Romane Romane:
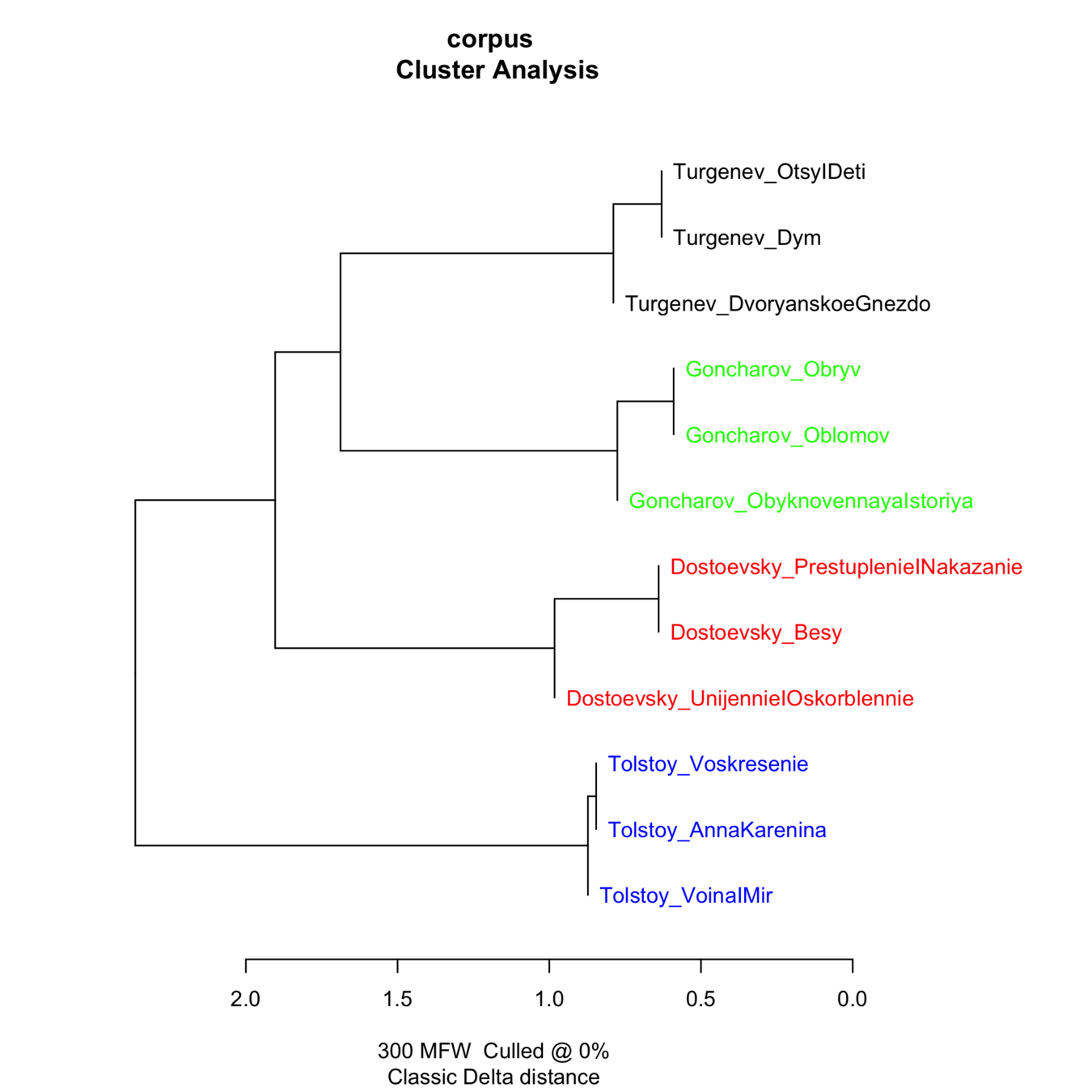
Armenische Texte

Chinesische Texte

Grenzen der Stylometrie
Die Textlänge
It becomes quite obvious that samples shorter than 5000 words provide a poor "guessing", because they can be immensely affected by random noise. Below the size of 3000 words, the obtained results are simply disastrous. Other analyzed corpora showed that the critical point of attributive success could be found between 5000 and 10000 words per sample (and there was no significant difference between inflected and non-inflected languages).
Eder, M. (2015). Does size matter? Authorship attribution, small samples, big problem.
Digital Scholarship in the Humanities.
Unterschiede im Genre (oder allgemeiner: im Texttyp) sowie zeitliche Distanz können die Ergebnisse des autorialen Signals verfälschen.
"Not unexpectedly, it works least well with texts of a genre uncharacteristic of their author and, in one case, with texts far separated in time across a long literary career. Its possible use for other classificatory tasks has not yet been investigated".
John Burrows, ‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship, Literary and Linguistic Computing, Volume 17, Issue 3, September 2002, Pages 267–287, https://doi.org/10.1093/llc/17.3.267
ein späteres und „ehrlicheres“ Rowling-Experiment
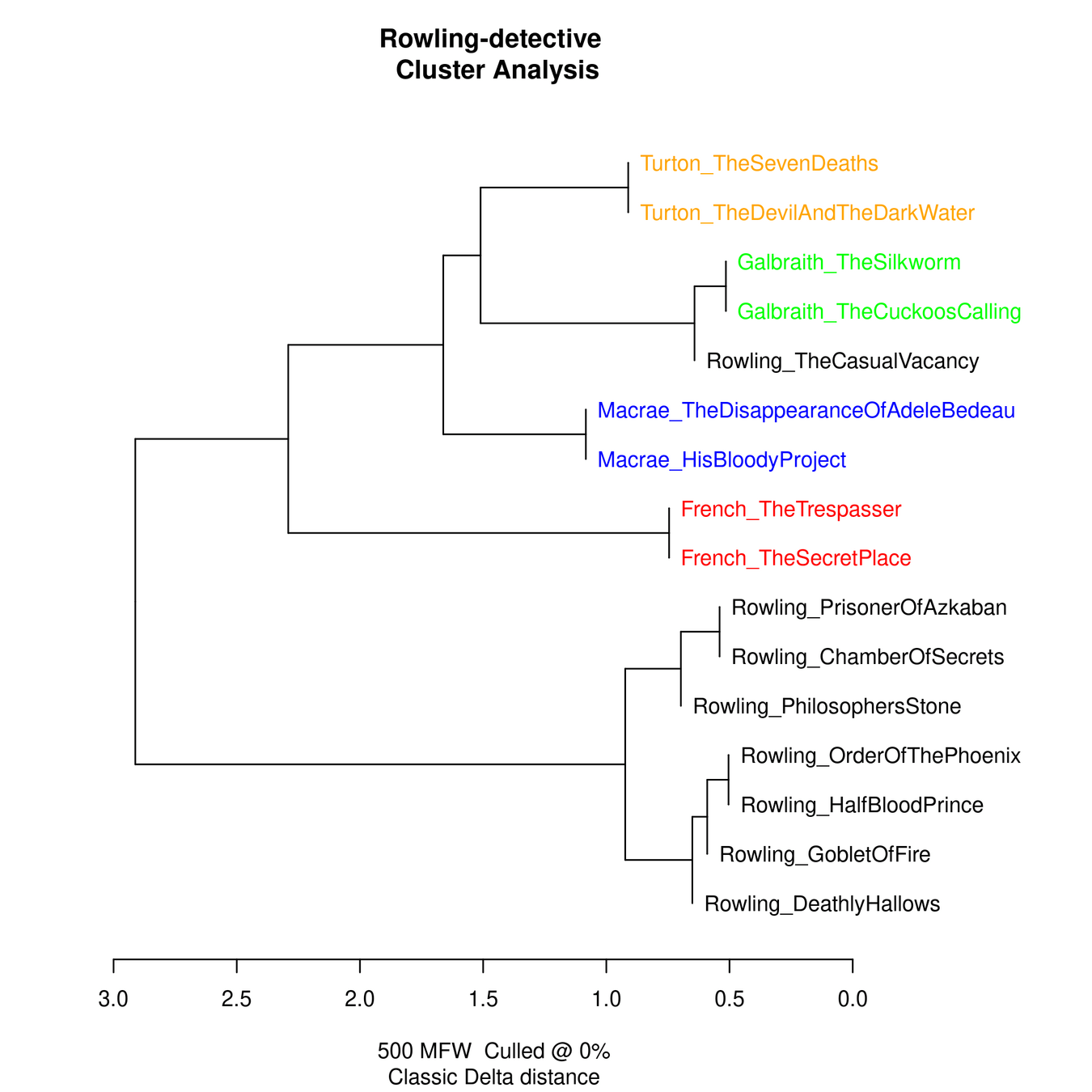
Orekhov, B. (2024) ‘Does Burrows’ Delta really confirm that Rowling and Galbraith are the same author?’ https://arxiv.org/abs/2407.10301
Aber am wichtigsten ist das Fehlen einer ausreichenden Zahl „zweifelsfrei authentischer“ Texte bei vielen realen Autorschaftsproblemen
Kehren wir nun endlich zu Elena Ferrante zurück


- Die Bücher von Elena Ferrante erscheinen seit 1992.
In den 2000er-Jahren wurde Ferrante sehr populär – zunächst in den USA, dann auch in Italien. - 2005 verglich der Journalist Luigi Galella einen Roman von Ferrante mit einem Werk des Schriftstellers Domenico Starnone und stellte textuelle Ähnlichkeiten fest.
- 2006 veröffentlichte derselbe Journalist gemeinsam mit dem Physiker Vittorio Loreto eine quantitative Untersuchung der Werke von Ferrante, Starnone und weiteren italienischen Autor:innen – erneut lag Starnone stilometrisch am nächsten.
- 2016 schließlich untersuchte der Journalist Claudio Gatti die Finanzströme des Verlags E/O – und wies auf die Übersetzerin Anita Raja hin.


Ein Netzwerk stilometrischer Ähnlichkeiten für 150 Texte zeitgenössischer italienischer Autorinnen und Autoren.



In der Zwischenzeit gingen andere Forscher:innen andere Wege …
Blended Authorship Attribution: Unmasking Elena Ferrante Combining Different Author Profling Methods (G. Mikros):
all profling results were highly accurate (over 90%) indicating that the person behind Ferrante is a male, aged over 60, from the region Campania and the town Saviano. The combination of these characteristics indicate a single candidate (among the authors of our corpus), Domenico Starnone.


Die meisten Spuren führten zu Starnone.

Und nur einige wenige Spuren führten zu Raja

Aber sie gehören tatsächlich zum selben Haushalt! (Das erklärt auch die „Geldfluss“-Spur zu Raja.)
P.S. Stylometrie jenseits der Autorschaft
-
Zusammenarbeit von Autorinnen und Autoren
– Koautorenschaft
– Übersetzung
– Einfluss der Redaktion / des Herausgebers -
Intraautoriale Stylometrie
– Früher vs. später Stil (Stylochronologie)
– Verschiedene Genres bei einem Autor (z. B. Shakespeare)
– Heteronymie (wenn Autor:innen es schaffen, die Stylometrie „auszutricksen“)
Vielen Dank für Ihre Aufmerksamkeit
"I think we should lock linguists and philologists in a room and not let them leave it until they explain what is happening"
(Jan Rybicki, at the DH 2019 Conference, Utrecht)
Stylometry beyond authorship attribution
But the study of literature and authorship is not only who wrote what, and who didn’t
Maciej Eder, Jan Rybicki (2016). Go Set A Watchman while we Kill the Mockingbird in Cold Blood, with Cats and Other People
Translation
Inside Shakespeare

From French...

...to English

Collaborative translation
Night and day by Virginia Wolfand its polish translation

Anna Kołyszko -> Magda Heydel


Maciej Eder, Jan Rybicki
Stylometrie und Shakespeare
Shakespeare

...und Marlowe

Henry VI: rolling stylometry


Z-score
Text
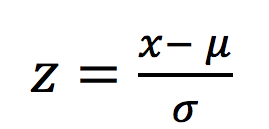
where
- x – frequency of a word
- µ - mean frequency of a word in the whole corpus (collection of texts)
- σ - standard deviation
Because authorship disputes are hot topics
Presumably, each national literature has its own famous unsolved attribution case, such as the Shakespearean canon, a collection of Polish erotic poems of the 16th century ascribed to Mikołaj Sęp Szarzyński, the Russian epic poem The Tale of Igor’s Campaign, and many other.
Eder M. (2011) Style-markers in authorship attribution: A cross-language study of the authorial fingerprint.
3. How does it work?
in all their variety of material and method, have two features in common: the <...> texts they study have to be coaxed to yield numbers, and the numbers themselves have to be processed via statistics.
M. Eder, M. Kestemont, J. Rybicki. ‘Stylo’: a package for stylometric analyses
Stylometric studies
remember: texts "have to be coaxed to yield numbers"
so it's mostly about counting frequencies
- Words
- especially function words
- Lemmas
- Symbol N-grams
- Word N-grams
Less typical but still works sometimes:
- POS tags
- Syntactic structures
- Metric structures
Frequencies of
But wait! These features are meaningless!!
How can they contain the 'authorial signal'?
Burrows Delta
- State of the art in authorship attribution since 2002
- Makes use of measuring distances between vectors of N most frequent words / charcacter n-grams
- (though more complex features are also possible)
- Built into Stylo
4. Real world application showcase
Who wrote 'To Kill a Mockingbird'?
Harper Lee

Oh, Real-Lee?
The new 'old' book (2015)

Causes for suspicions (external)
- After publishing 'To kill a Mockingbird' Lee hasnt published a book in 55 years
- The manuscript was 'accidentaly found' by Lee's lawyer
- In 2015 Lee was 88, blind and severely disabled
- Alabama authorities actually did an investigation of Lee's legal capacity
- Contradicting statements regarding the manuscript
- a draft of 'To Kill a Mockingbird'
- or a separate work in the same fictional realm
Causes for suspicions (internal)
- Many deemed the 'new' work 'poor' compared to the classical 'To Kill a Mockingbird'
- Plot-wise the new text is a sequel (the main herione is an adult), though the claim was it had been written earlier
- A lot of disappointment in Atticus Finch who turns out to be kind of a racist in the 'new' book
Were the books written by one person?

Harper Lee and Truman Capote


Why Capote?
- Harper Lee's childhood friend, grew up together in the city which became the prototype for the city in 'To Kill a Mockingbird'
- prototype for one of the characters in 'To Kill a Mockingbird'
- In the time of writing 'To Kill a Mockingbird' , Capote published nothing big
- Afterwards Capote wrote his true-crime bestseller "In Cold Blood" which Lee helped to work with
- Hypotheses: then Lee thanked Capote by helping with "In Cold Blood"
This is what the stylometrists went on to test

Harper Lee homogeneity (dendrogram)
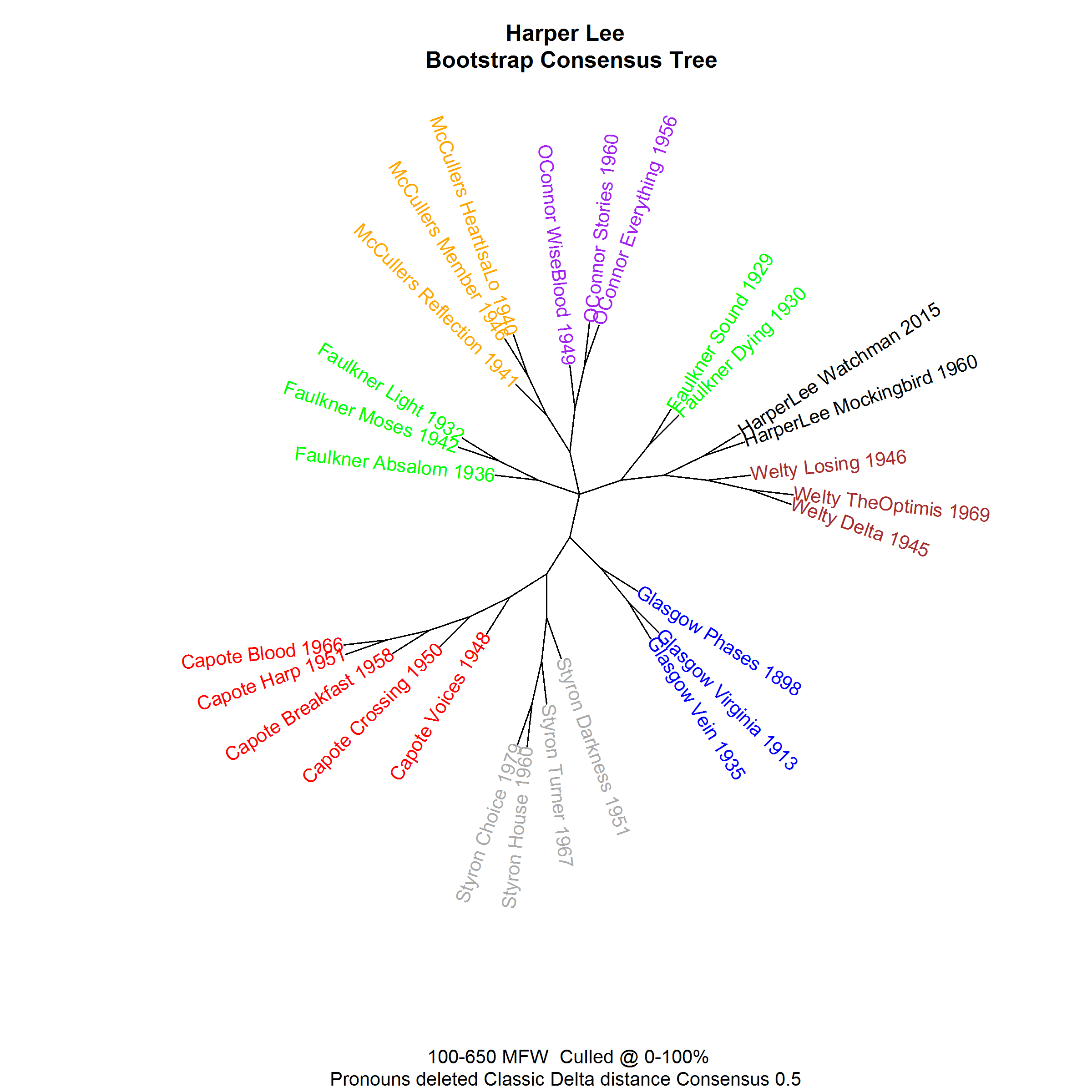
Harper Lee homogeneity (network)
By the way we can reproduce it in stylo:
> data(lee)
> stylo(frequencies=lee)
5. Okay, Danya, enough stories, just tell us how to do it!
Stylo hands-on
6. Bonus 1: more Stylo functions
classify ()
- text classification with stylometry features
- main tool for actual authorship attribution
- employs standard machine-learning algorithms
- requires two sets of documents
- training (primary_set)
- test (secondary_set)
rolling.classify ()
- dynamic changes in the text
- text window of adjustable size

oppose ()
- contrastive analysis
- words significantly preferred/avoided
- comparison studies (e.g. male vs female styles)
- when launching with non-latin script data:
oppose(corpus.lang="Other")
Oppose

Some history
Quantifying style
-
1851 — A. De Morgan suggests mean word-length as an authorship feature
-
1873 — New Shakespeare Society (Furnival, Fleay et al)
-
1887 — T. Mendenhall, The Characteristic Curves of Composition, the first known work on quantitative authorship attribution

Cyrillic issues on Mac
- Open Terminal and execute
defaults write org.R-project.R force.LANG en_US.UTF-8
- ...or in R execute this:
>system("defaults write org.R-project.R force.LANG en_US.UTF-8")
Adversarial stylometry
- deceiving authorship detection
- countermeasures to deception
- de-anonymization
- demographics detection
-
native language identification
- ...potentially allows you to harrypoterize your fanfic =)

And even this:

Agenda for today
We start with a list of books
- Book A by author A (AA)
- Book B by author A (BA)
- Book С by author A (CA)
- Book A by author B (AA)
- Book B by author B (BB)
- Book С by author B (CB)
- Some dubious book
Stylometrie Oracle
By danilsko
Stylometrie Oracle
Stylometrie Oracle




