FACADE: A Compiler and Runtime for (Almost) Object-Bounded Big Data Applications
Authors: K. Nguyen, K. Wang, et al.
Presented by David A.N
Terminology
Big Data: voluminous and complex datasets that traditional statistical methods cannot address
We are facing a rapid growth of massive datasets (e.g, online activity, science, sensor networks)
Data
The distributed clusters are pervasive
Data
Distributed Computing

ML for analyzing complex datasets (e.g., classification, regression, collaborative filtering, clustering)
Data
Distributed Computing
Machine Learning
Machine Learning: Constructing and studying methods that learn from and make predictions on data

Machine Learning: Constructing and studying methods that learn from and make predictions on data
- Face Recognition
- Link Prediction
- Text classification
- Protein structure prediction
A Typical Supervised Learning Pipeline
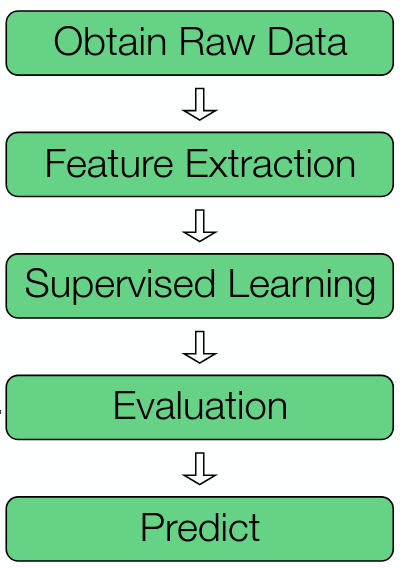
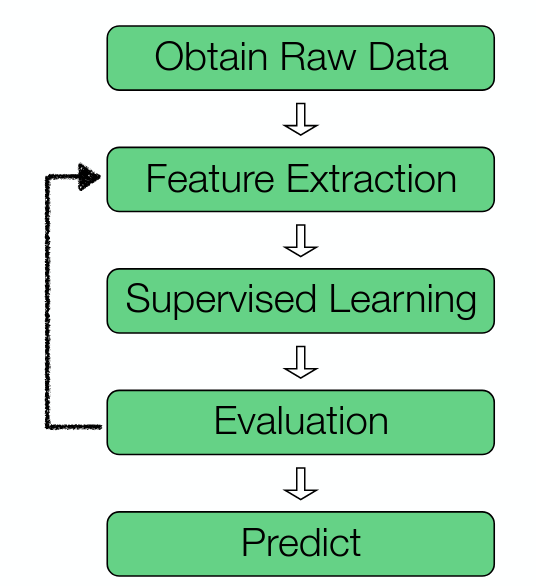
The pipeline has iterations for refining the model
Big Data needs Scalability
Data
Distributed Computing
Machine Learning
Big
Data
Big Data Problem
Data growing faster than computation s
Data growing faster than computation s
- Facebook’s daily logs: 60 TB
- 1,000 genomes project: 200 TB
- Google web index: 10+ PB
Data growing faster than computation speeds
Data growing faster than computation speeds [Moore's Law]
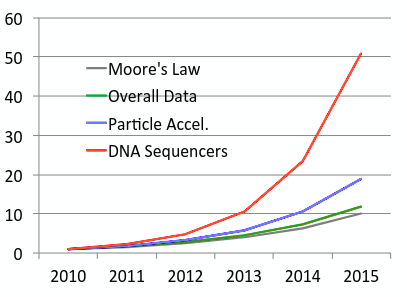
Data growing faster than computation speeds
How to handle massive data? Traditional tools (e.g., Matlab, R, Excel) do not work because they run on single machines
Data growing faster than computation speeds
More hardware to store/process modern data [scale up]
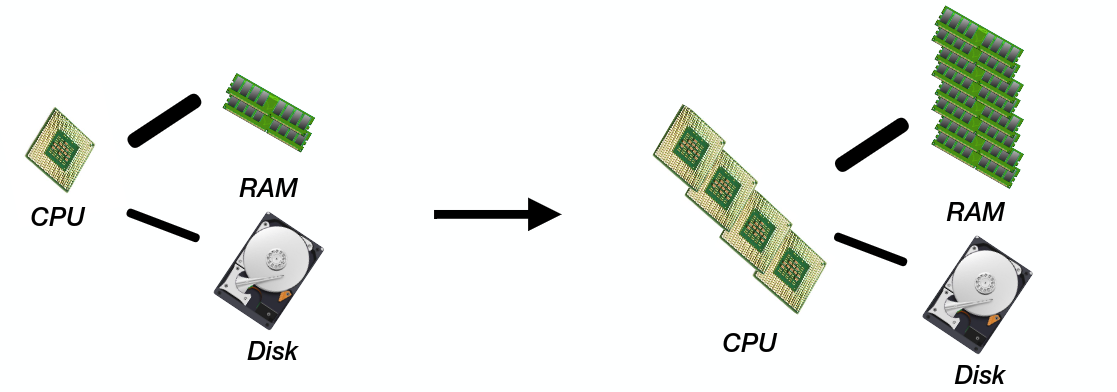
Data growing faster than computation speeds
From Scale-up (one big machine) to Scale-out (distributed) [shared-nothing architecture]
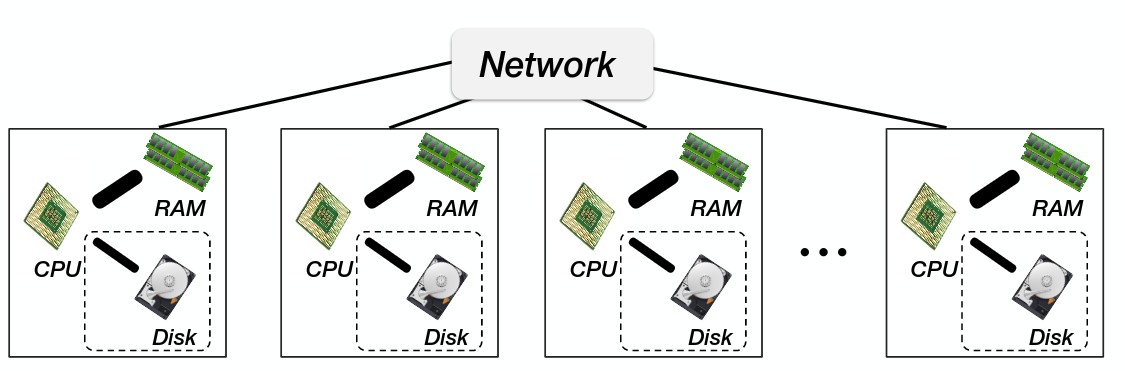
Data growing faster than computation speeds
BUT, stalling CPU speeds and storage bottlenecks
Data growing faster than computation speeds
BUT, stalling CPU speeds and storage bottlenecks
Runtime Bloat
Runtime bloat: occurs when execution time and memory consumption is high compared to what the program actually accomplishes
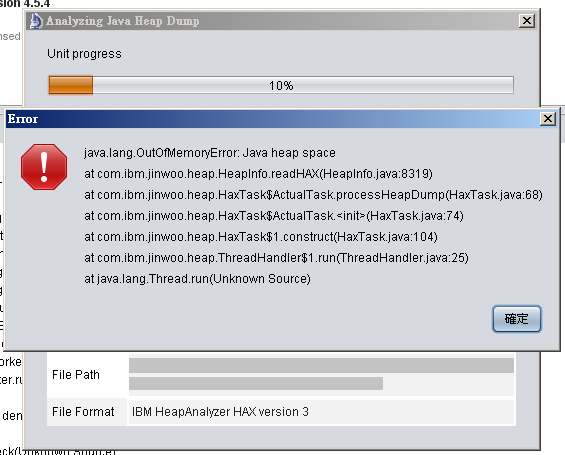
Data growing faster than computation speeds
BUT, stalling CPU speeds and storage bottlenecks
How do we split work across machines?
Big Data Example: Word Counting
Count the number of occurrences of each word in a document
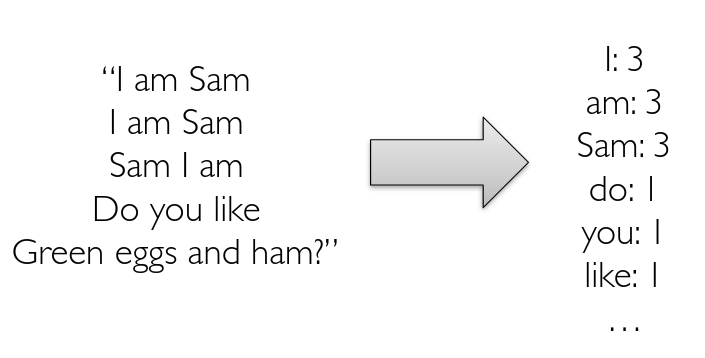
Using hash table

Using hash table

Using hash table

Using hash table

What if the document is really really big?
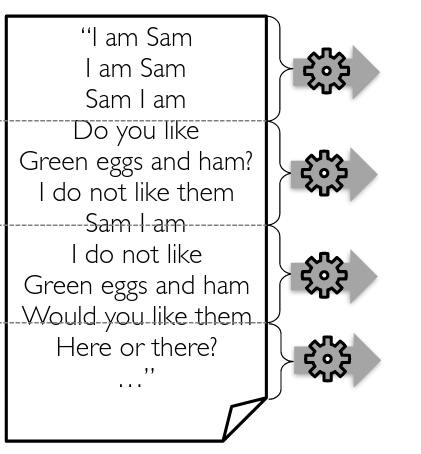
Problem?
Results have to fit on one machine
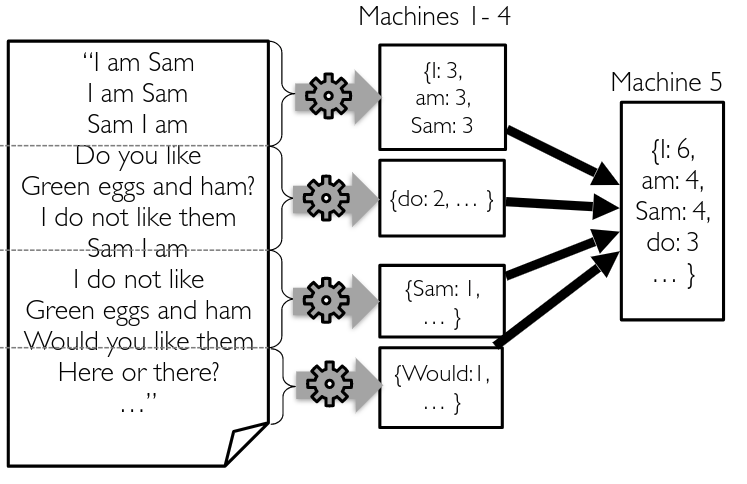
Using Divide and Conquer!
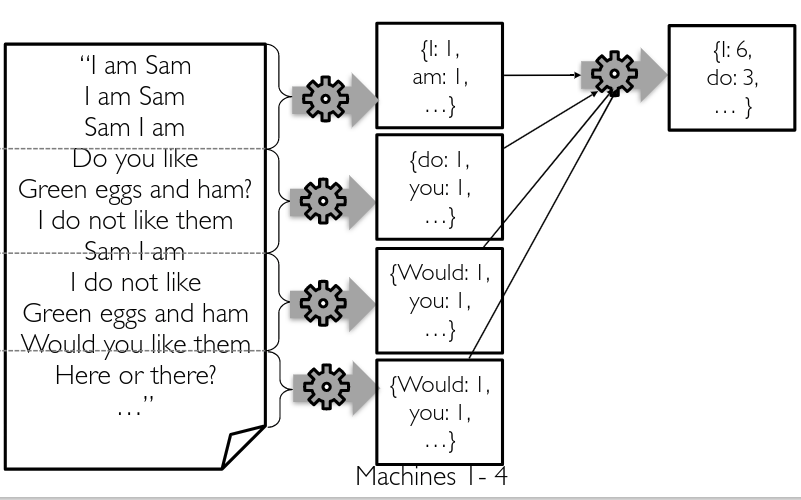
Using Divide and Conquer!
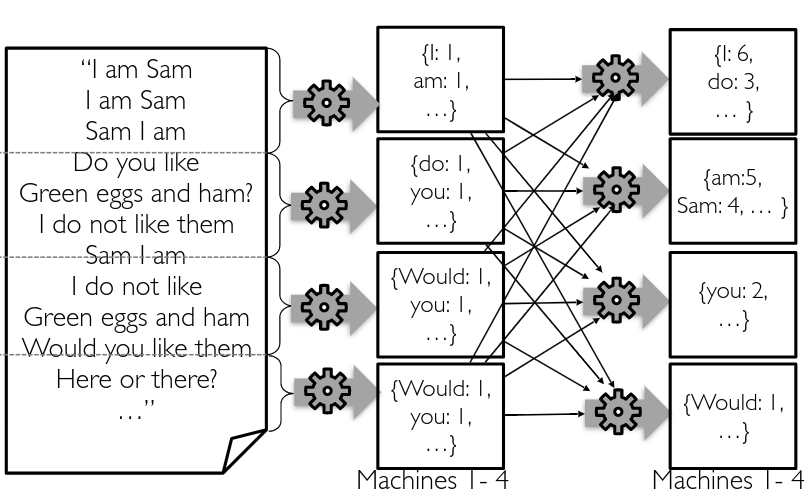
Using Divide and Conquer!
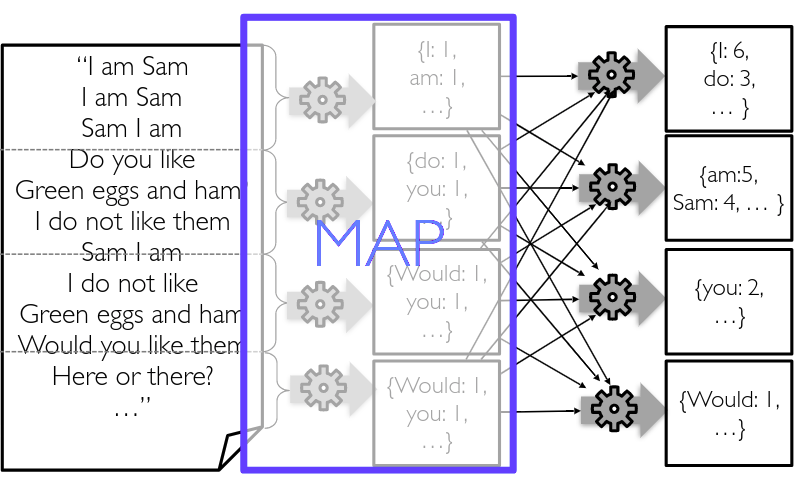
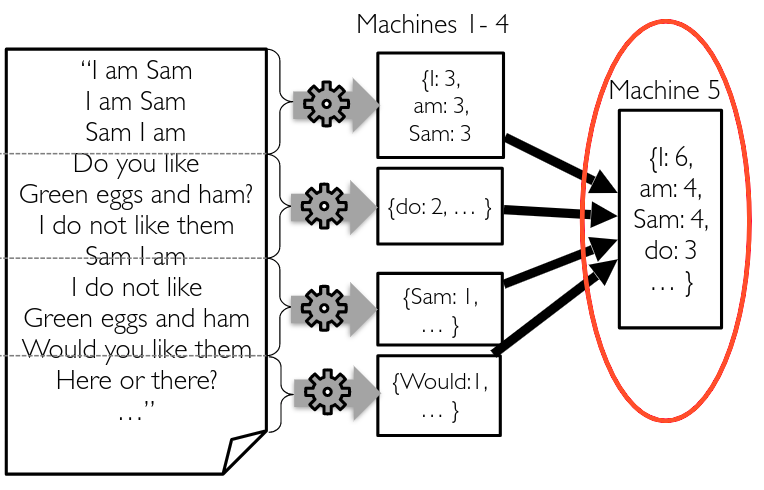
Google Map-Reduce 2004
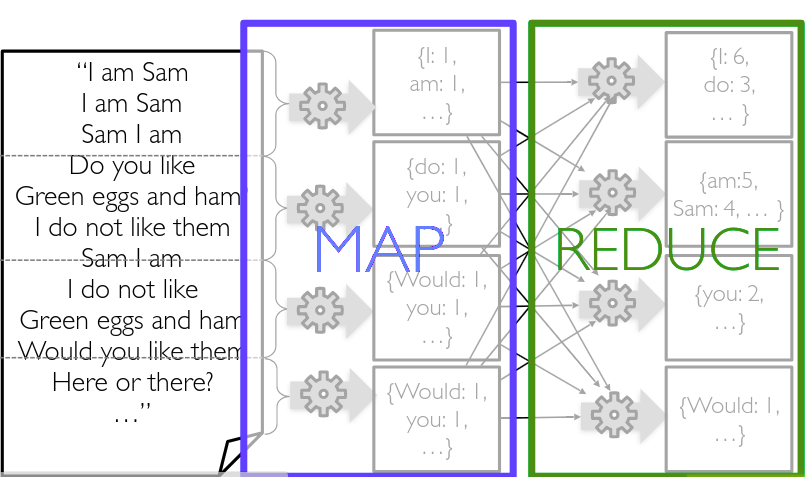
Map reduce for sorting: what word is used most?
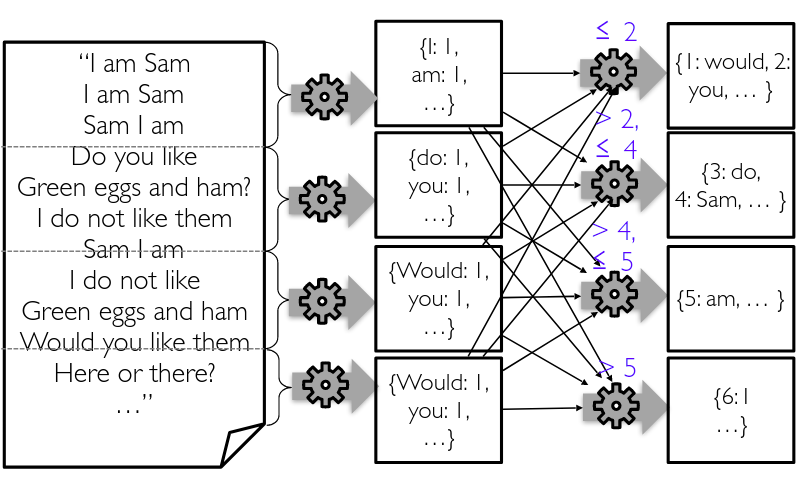
A real pipeline has several iterations jobs in a distributed execution
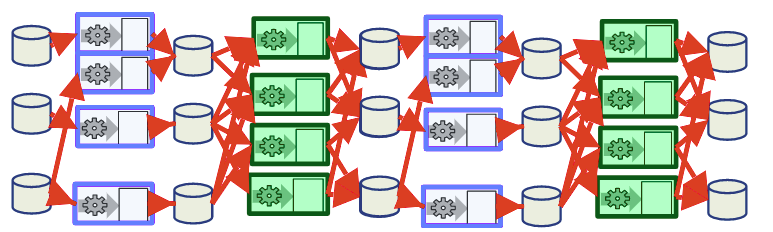
Disk I/O is very slow, then the solution is "keep more data in -memory"
Problem Statement
[of the paper]
Big Data Frameworks are written in Java and Scala because of quick development and rich community resources
Managed runtime of Java has a high cost [runtime bloat], which cannot be amortized by increasing # of data-processing machines
Excessive use of pointers and references [high space overhead] and frequent GC runs [impact scalability]
data-size < heap-size
GC time accounts for up to 50% overall execution time
FACADE as Solution
Facade can generate highly-efficient data manipulation code by automatically transforming the data path of an existing Big Data App
Data & Control
There is a boundary between the control path and the data path [breaking OOP principle]
Data
Control
Data
Control
Organizes tasks in pipelines and performs optimizations
Representation and manipulation of the data
To assess scalability the # of data objects and their references in the heap must not grow proportionally with the cardinality of the dataset
O(s)
S: cardinality of
O(s)
S: cardinality of dataset
t: # of threads
O(t)
O(s)
S: cardinality of dataset
t: # of threads
n: #data types
O(t*n)
O(s)
S: cardinality of dataset
t: # of threads
n: #data types
p: #page objects used to store data
O(t*n+p)
O(s)
Not reduced statically as n, but the size can be controlled
O(t*n+p)
Facade is a non-intrusive technique to reduce the cost of the managed runtime by limiting the # of heap objects at the compiler level
FACADE
FACADE
P
A Big-Data program P (e.g., Page Rank in GraphChi) is the input
FACADE
P
The developer must specify the # of data paths & starting-ending of iterations
Iteration info
Java Classes
FACADE
P
The output is an (almost) object-bounded program P'
Iterations
Java Classes
P'
FACADE
P
For Twitter201o graph in GraphChi: Execution is 27% faster, 26% less memory consumption, and 86% less GC time
Iterations
Java Classes
P'
Facade reduces the # of data objects, the data items are no more represented by heap objects
Managed Heap
The data items are stored in native memory
Managed Heap (bounded)
Native Memory (unbounded)
Facade reclaims [allocate] data from native memory in a time t
Managed Heap (bounded)
Native Memory (unbounded)
Facade deallocate from the heap in a iteration t+1
Managed Heap (bounded)
Native Memory (unbounded)
The FACADE
Model & Implementation
The authors propose to store data records in native memory (off-heap)
A memory page p is a fixed-length contiguous block of memory in the native memory
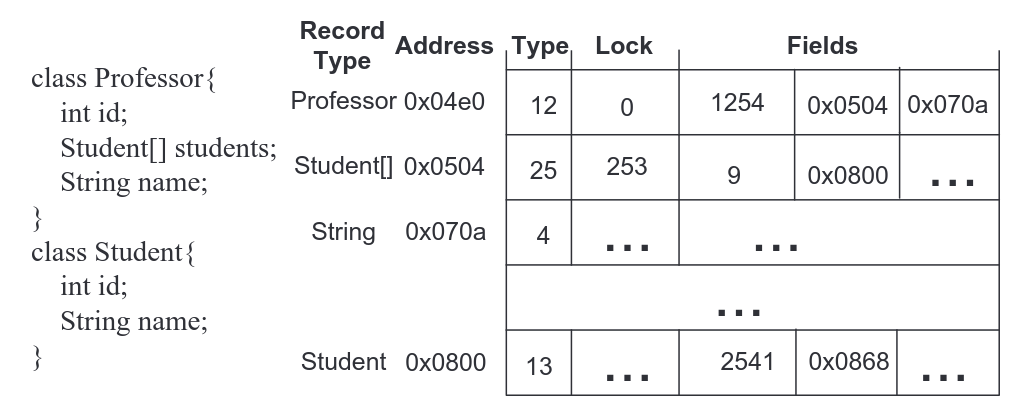
A record represents an object in P
Type of the record 2-byte used to implement method dispatch during execution of P'
Lock Field when data record is used to synchronize a block of code 2-byte
Array records and the size of the array
The actual data is stored in the record
The actual data is stored in the record
A memory address for array of students & name
The authors propose to create heap objects as facades for a data type so that they can be used for control
Transformation 1: offset to data records

Transformation 2: new method generation with changed signature
Transformation 2: retrieve the page references as a first task in the method
Transformation 3: Facade allocates space based on the student size
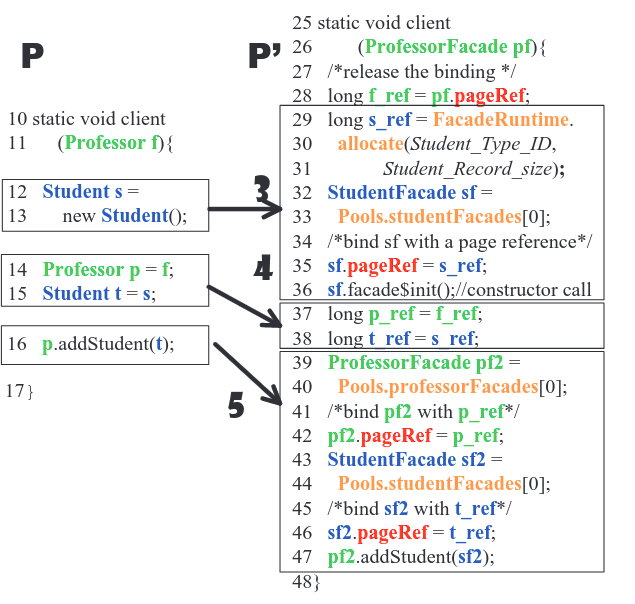
Transformation 3: Facade generates code to retrieve an available StudentFacade
Property: for any control instruction that needs a facade of a data type, all facades in the pool for the type are available to use
The number of facades of a certain type is bounded by the maximal number of arguments of the type required by a call in P
The bound determines the size of the facade pool for the type statically
The facade is available for reuse once the page reference it carries is loaded to a stack variable
Authors make "data class" assumptions for the compiler
data class
non-data class
First assumption: reference-closed-world
data class
HashMap
HashMapFacade
Second assumption: type-closed-world
data class
The class hierarchy must be data classes
The authors state three data class transformations
Class Hierarchy
Instruction
Resolving Types
Instruction Transformation: Facade performed on the control flow graph, the output of the transformation is a new CFG
Code Generation Example: Interaction Point (IP)

Instruction in P
Conditions
Code Generation in P'
Resolving Types: Facade emits a call to a method named resolve to resolve the runtime type corresponding to a page reference
resolve(aref)
Supporting Concurrency: in P' two concurrent threads may simultaneously write different page references into the same facade object [data race]
Authors solve the data race problem by implementing a special lock class and creating a new lock pool
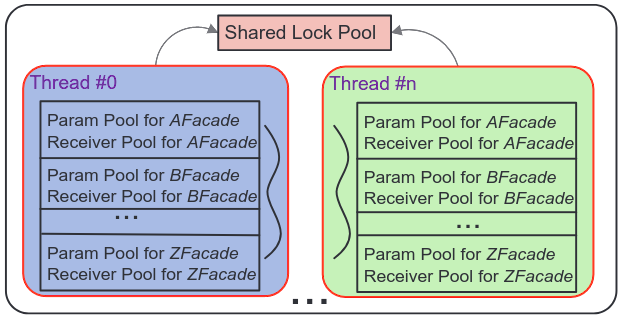
Facade associates one instance of class Pools with each thread
FACADE Evaluation
GraphChi case study: processing large graph in one machine.
Performance comparison of page rank (PG) and connected components (CC) on twitter-2010 dataset
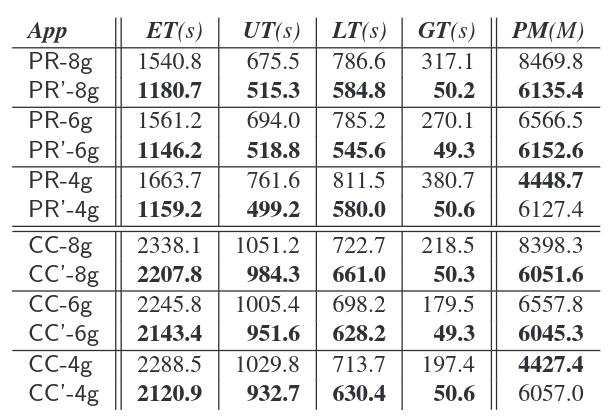
Execution Time: 26.8% for PR and 5.8% for CC performance improvements
Garbage Collection: an average of 5.1x reduction
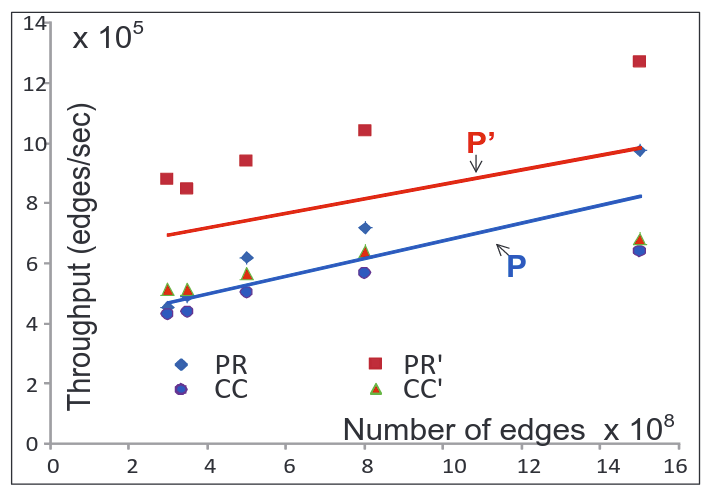
Scalability by computing throughput [number of edges processed in a second]
Hyracks Case Study: word count (WC) and external sort (ES) [shared-nothing machines]
External sort in P' is about 24.7% faster than ES
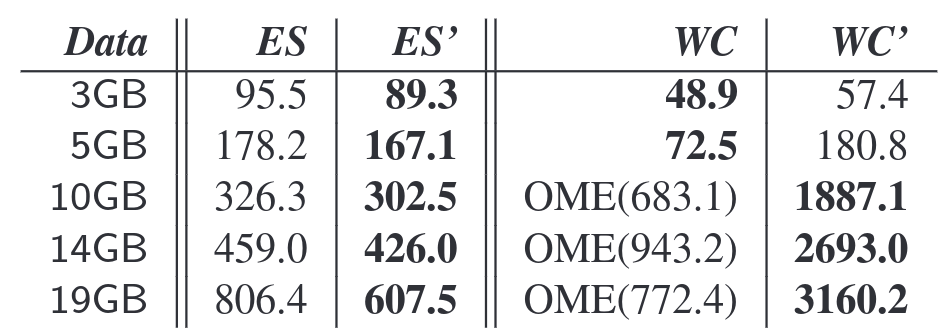
OME(n): programs runs out of memory in n seconds
My Analysis
Advantages
- Separating data from control as an efficient way of reducing heap memory
- Scalability results
- Test on different configurations: single machine, cluster, one thread, multi-thread, 3 different frameworks
Dis-Advantages
- Developers must tune:
- Starting-ending of iteration
- Data classes are sometimes ambiguous
- The approach cannot be generalized: each ml-program has different complexities
Take home message
FACADE is a compiler that accomplishes high efficiency by performing semantic-preserving transformations, but it cannot guarantee for each program to statically bound the number of heap objects due to ML complex pipelines
[compilers] Facade Presentation
By David Nader Palacio



