Apache Spark
La introducción que no encontré ni en stackoverflow

Software Engineer @

Disclaimer:
Todo lo que se cuente aquí es fruto de la experiencia personal (y espero que transferible) de un NO-experto en la materia.
Si escucháis alguna tontería no dejéis de corregirla, please!
¿Introducción? al Big Data
Sistema que manipula grandes conjuntos de datos.
¿Qué es?
* No sabría deciros cuantos "peta gigos" son gran conjunto de datos
- captura*
almacenado- búsqueda
- análisis
visualización
Dificultades
- Batch
- Streaming ¿real time?
Aproximaciones
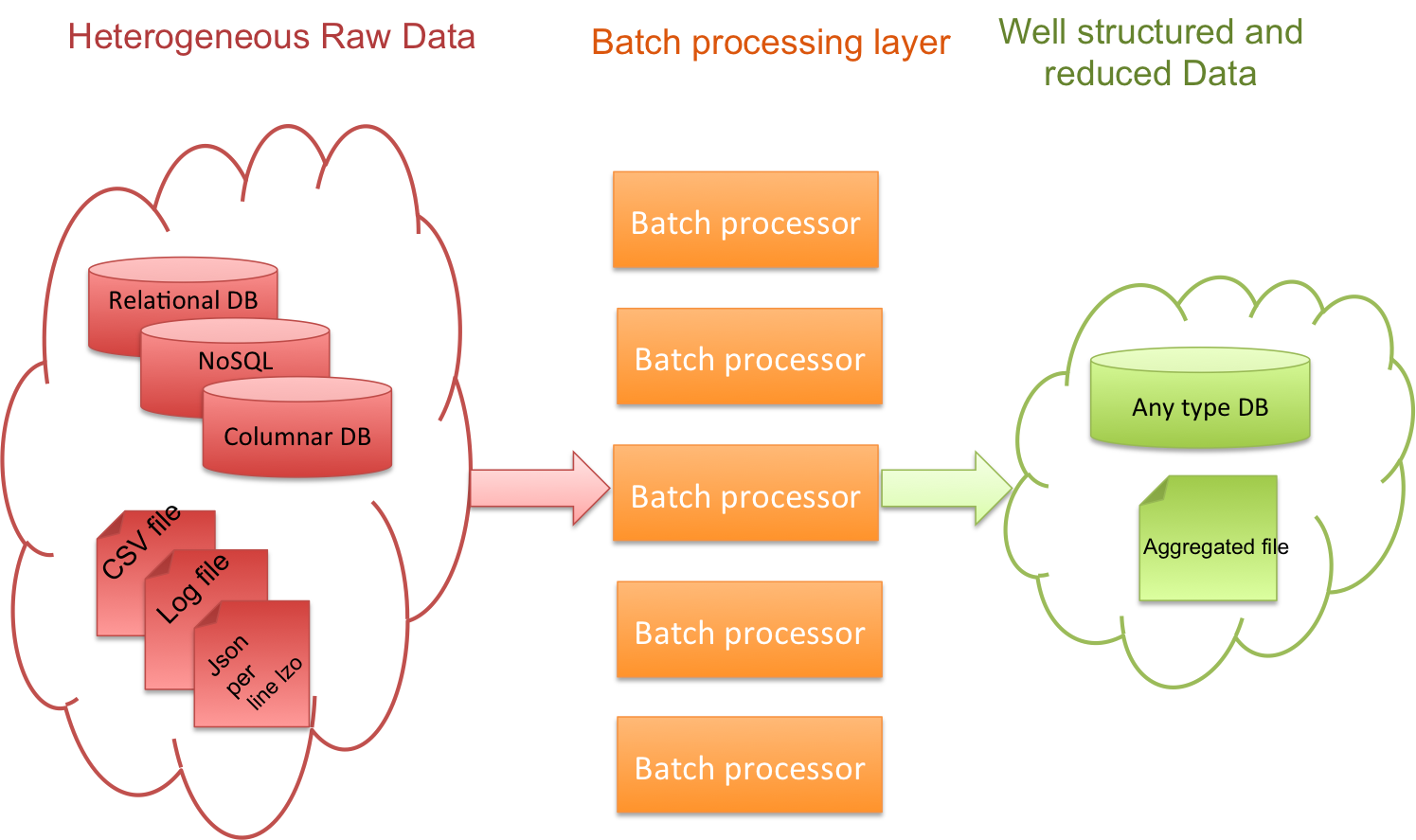
Batch
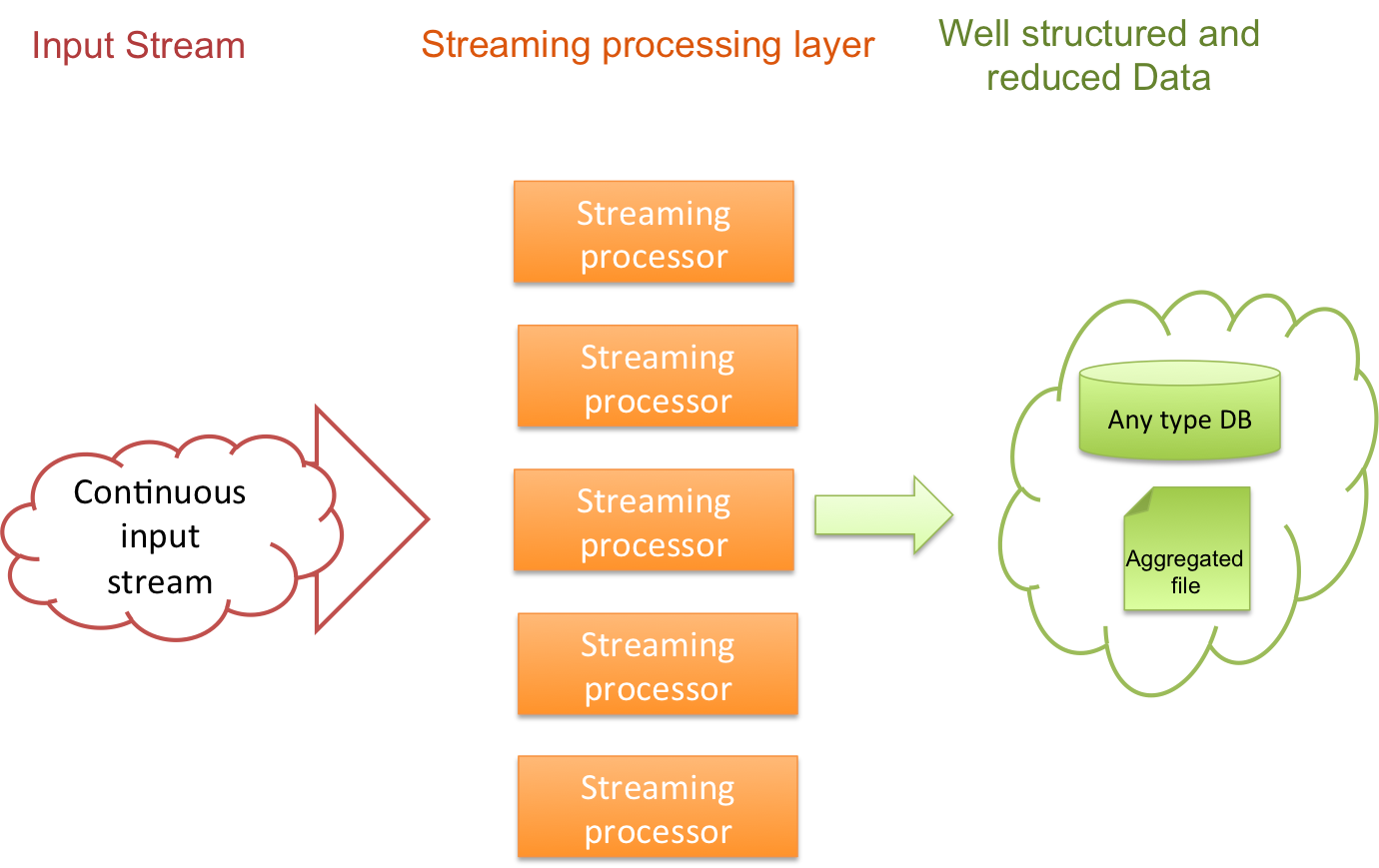
Streaming
Casos de uso
Streaming
- Ingesta de contenido
- Agregación de datos
Batch
- Análisis de logs
- Búsqueda de datos antiguos
- Agregado de distintas fuentes
- ...
Apache Spark
Introducción
Evolución natural de Apache Hadoop
- Juego de operaciones más rico
- Aprovecha la memoria RAM para almacenar datos
Filosofía
Llevar el programa al dato* en lugar de traer el dato al programa
* como veremos en los ejemplos, esto tiene consecuencias en nuestra forma de programar
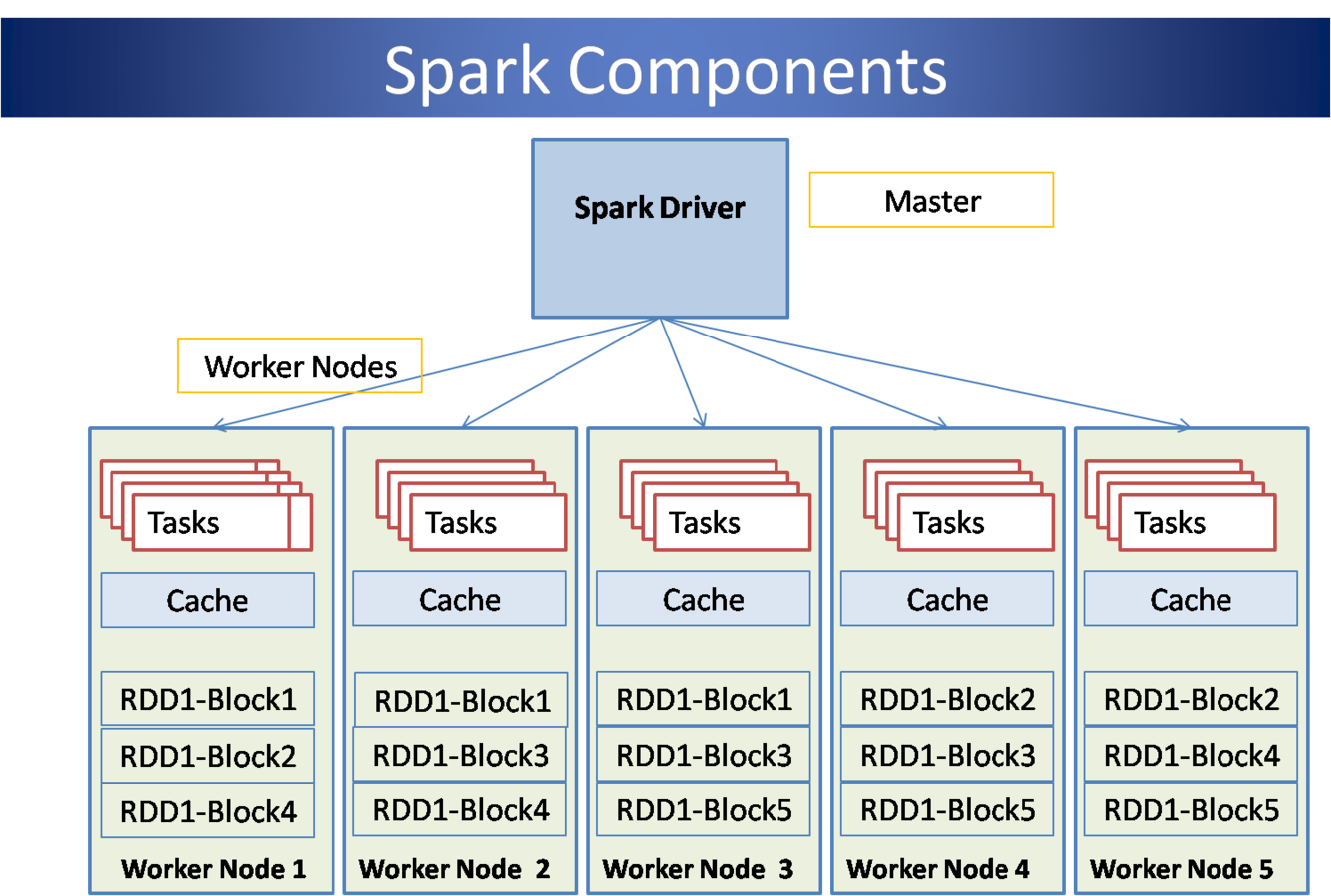
Conceptos básicos
- RDD
- Driver
- Worker
- Resource manager
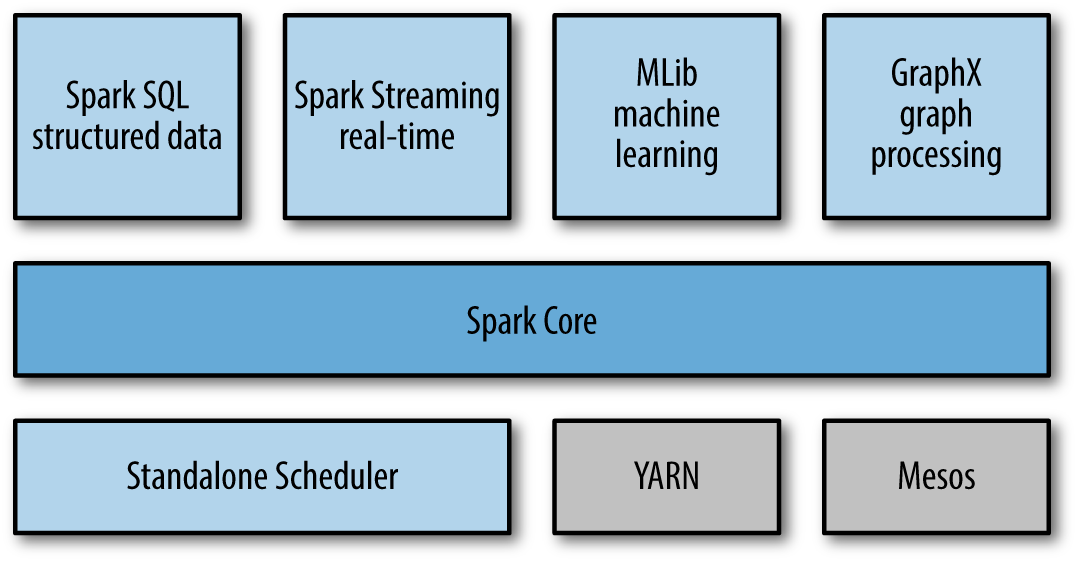
Stack
RDD
- Operaciones
- Acciones
Resource Manager
- Yarn
- Mesos
- SSH
Spark & Hadoop
- HDFS
- Yarn
- Código
http://spideropsnet.com/site1/blog/2014/12/09/igniting-the-spark/
RDDs
Transformaciones
- map
- filter
- flapMap
- sample
- union* concat
- intersection
- distinct
- join
- cartesian
- ...






Images © by Martin Fowler
Acciones
- reduce
- collect
- count
- first
- take
- takeSample
- saveAsTextFile
- saveAsObjectFile
- foreach
KeyValue RDD
Transformaciones:
- groupByKey
- reduceByKey
- aggregateByKey
- combineKey
- mapValues
- keys
- values
- sortByKeys
- substracByKey
Acciones:
- countByKey
- collectAsMap
- lookup
Particionado
- cogroup
- groupWith
- join
- groupByKey
- reduceByKey
- combineByKey
- lookup
- ...
A picar...
Primer paso
Hello spark-shell
git checkout step1
Segundo paso
- Cómo es un proyecto Spark
- La cache
- Diferencias entre transformación y acción
git checkout step2
- Cómo se planifica la ejecución de las tareas
git checkout step2
Tercer paso
- Extraer lógica de RDDs a servicios
- Test automáticos
git checkout step3
Cuarto paso
- Delegar en colaboradores (problemas de serialización)
git checkout setp4
- Solucinar el problema de serialización (diferentes estrategias)
git checkout setp4
Quinto paso
A jugar
git checkout step5a, 5b, 5c, 5d, ...5g

Sexto paso
El API de Hadoop para leer ficheros
git checkout step6
Septimo paso
Trabajando con datos estructurados:
- CSV
- JSON
git checkout step7a, 7b
Último paso
Spark SQL
Preguntas?
Gracias!
Intro Spark
By Sergio Arroyo
Intro Spark
La introducción que no encontré ni en stackoverflow

