Anime Recommendation
Data Source
- From Kaggle Anime Recommendations Database
- Recommendation data from 76,000 users at myanimelist.net
- https://www.kaggle.com/CooperUnion/anime-recommendations-database
- with Two files : anime.csv rating.csv
Data Source
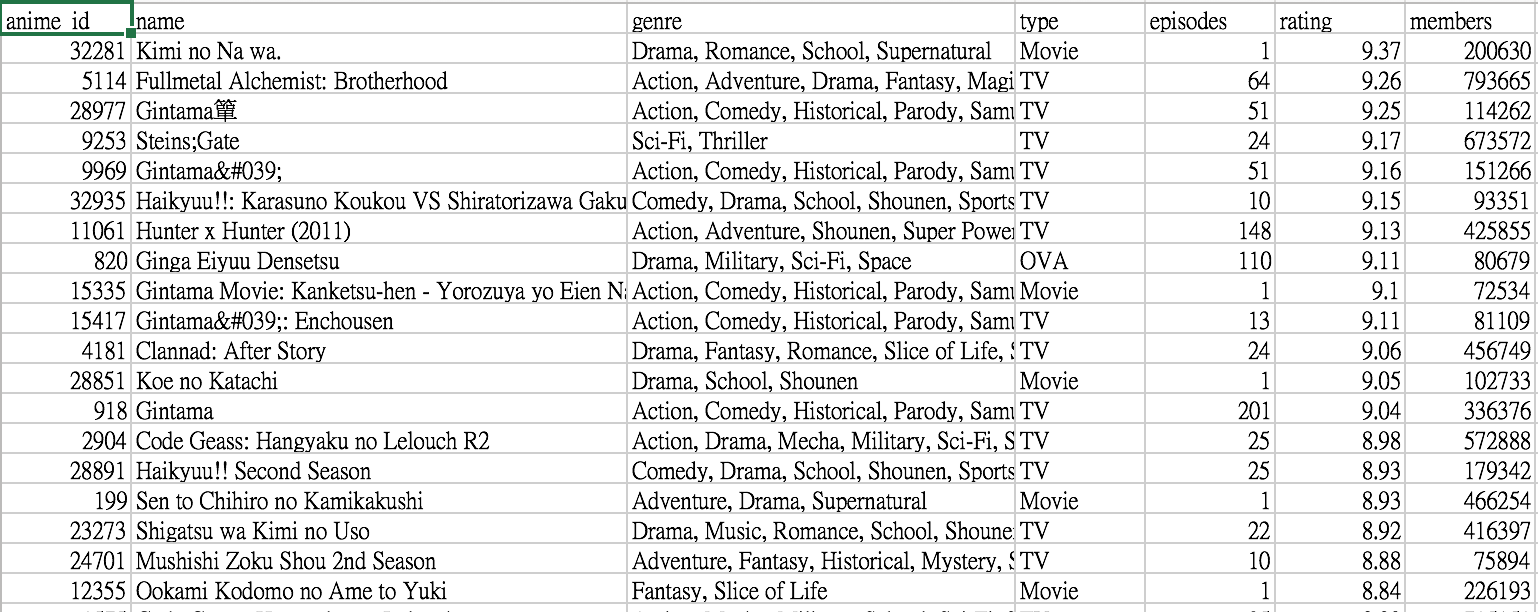
anime.csv
Data Source
anime.csv
- anime_id - myanimelist.net's unique id identifying an anime.
- genre - comma separated list of genres for this anime.
- rating - average rating out of 10 for this anime.
Data Source
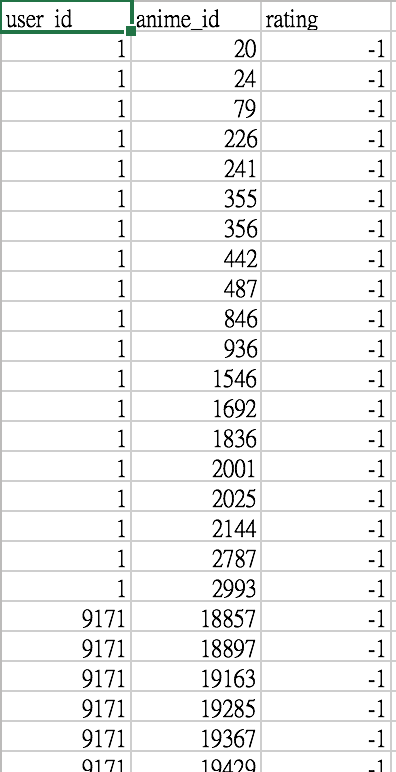
rating.csv
Data Source
rating.csv
- user_id - non identifiable randomly generated user id.
- anime_id - the anime that this user has rated.
- rating - rating out of 10 this user has assigned (-1 if the user watched it but didn't assign a rating).
Data Visualization
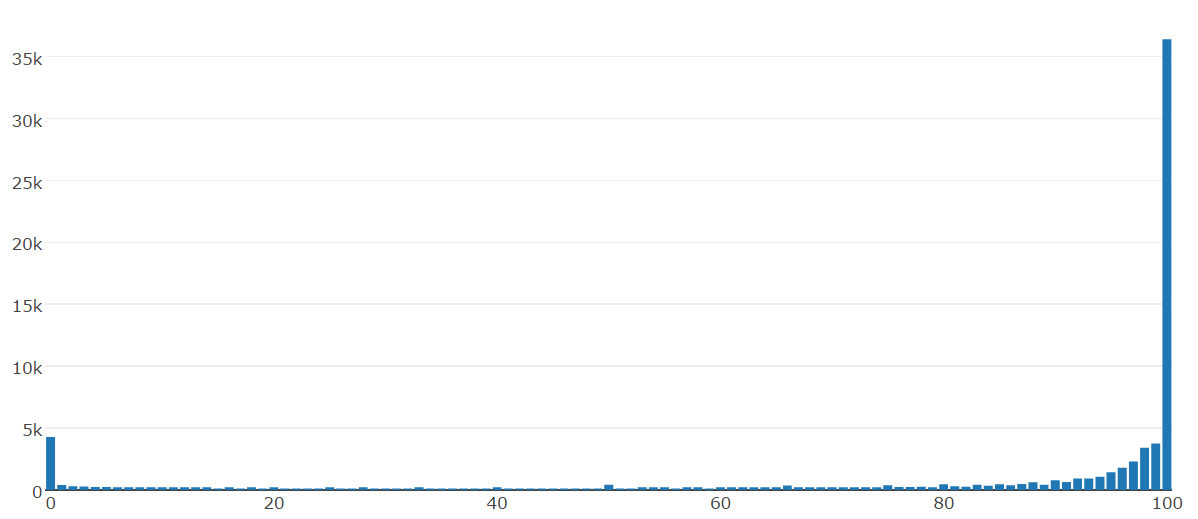
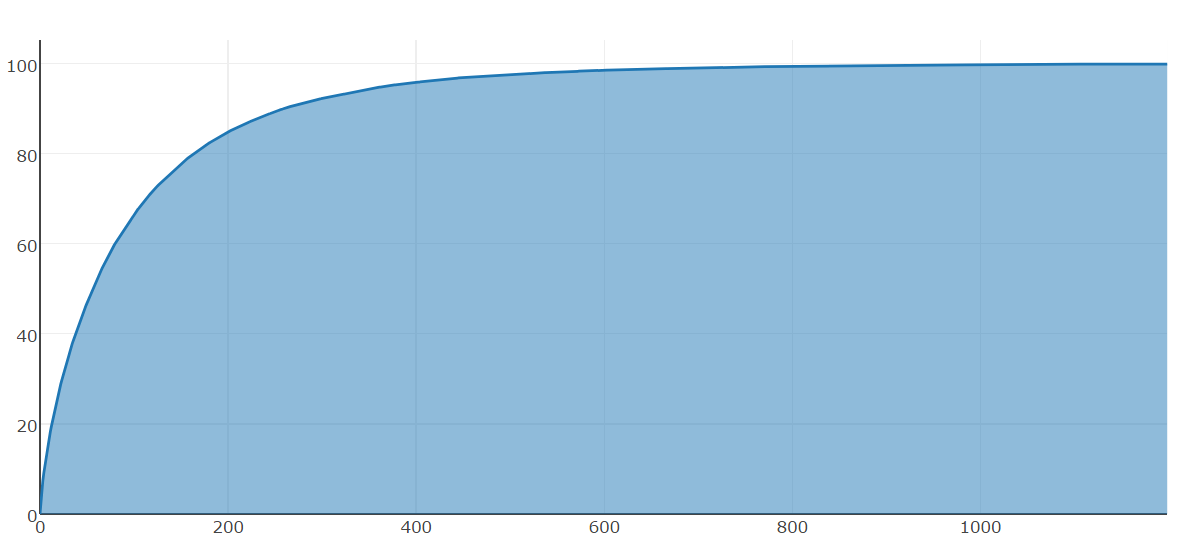
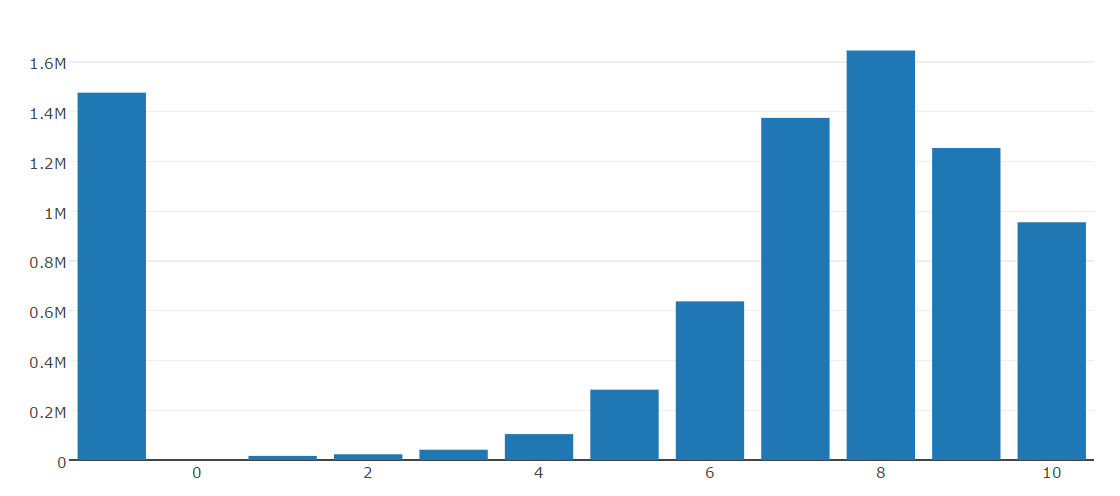
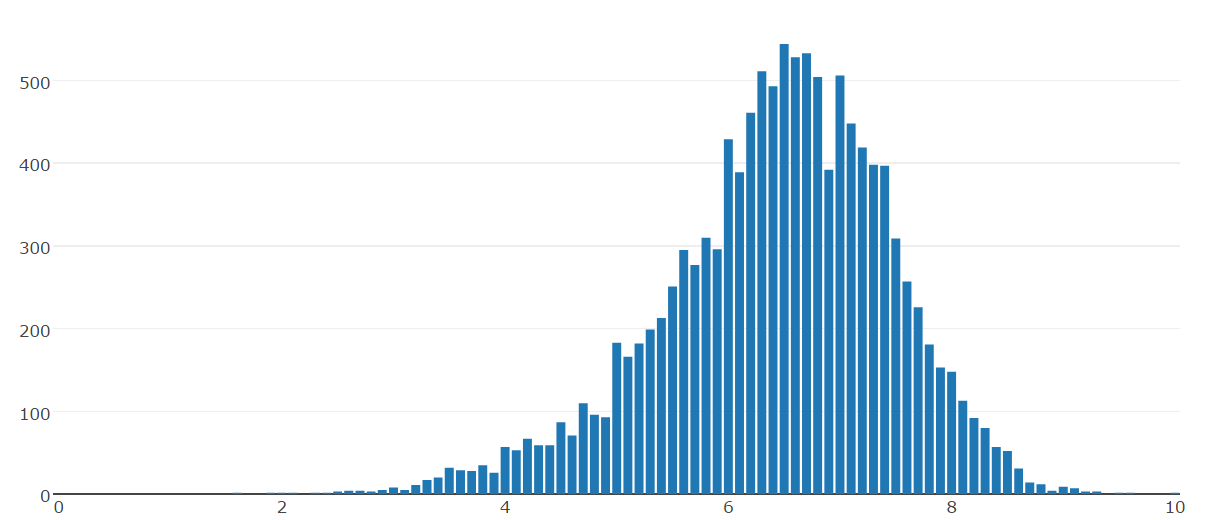
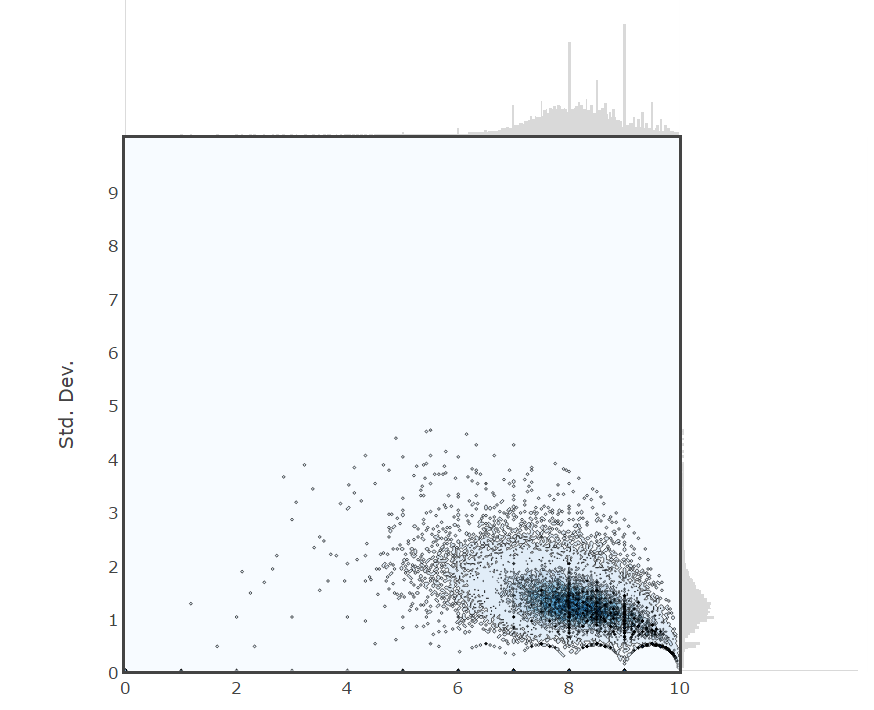
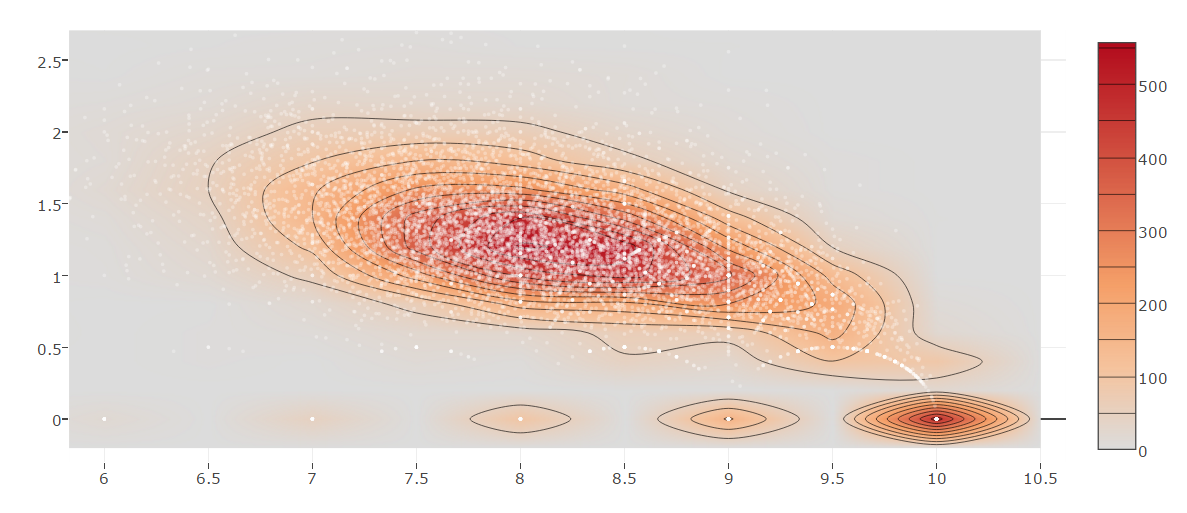
Data Preprocessing
- There are 41 kinds of genres for all animes.
- For each anime, we create a 41 * 1 vector to represent.
- And for each user, we create a 41 * 1 vector from the ratings.
Data Preprocessing
How to deal with the missing values?
for each user, replace -1 with
5 (If there are no ratings from this user)
10 - average rating from this user (otherwise)
Data Preprocessing
User Instance
{\sum anime\_vector * rating}\ ./ \ {\sum anime\_vector}
Evaluation
NDCG@50
CG
- Cumulative Gain
- Example:
gain = {3, 5, 9, 6}
CG = 3 + 5 + 9 + 6 = 23
DCG
- Discounted Cumulative Gain
- Example:
gain = {3, 5, 9, 6}
DCG = 3 / lg(2) + 5 / lg(3) + 9 / lg(4) + 6 / lg(5) = 13.24
NDCG@k
- Normalized Discounted Cumulative Gain
- k: number of items in DCG
- NDCG = DCG / iDCG
- iDCG: ideal DCG
- Example:
gain = {3, 5, 9, 6}
DCG = 3 / lg(2) + 5 / lg(3) + 9 / lg(4) + 6 / lg(5) = 13.24
iDCG = 9 / lg(2) + 6 / lg(3) + 5 / lg(4) + 3 / lg(5) = 16.58
NDCG@4 = 13.24 / 16.58 = 0.80
Pros & Cons
- Offline: needless of user response
- Relevance could be any real number (in contrast to MAP which only allows binary relevance)
- The returning value itself is nontrivial and thus can only be used to distinguish between models.
Usage
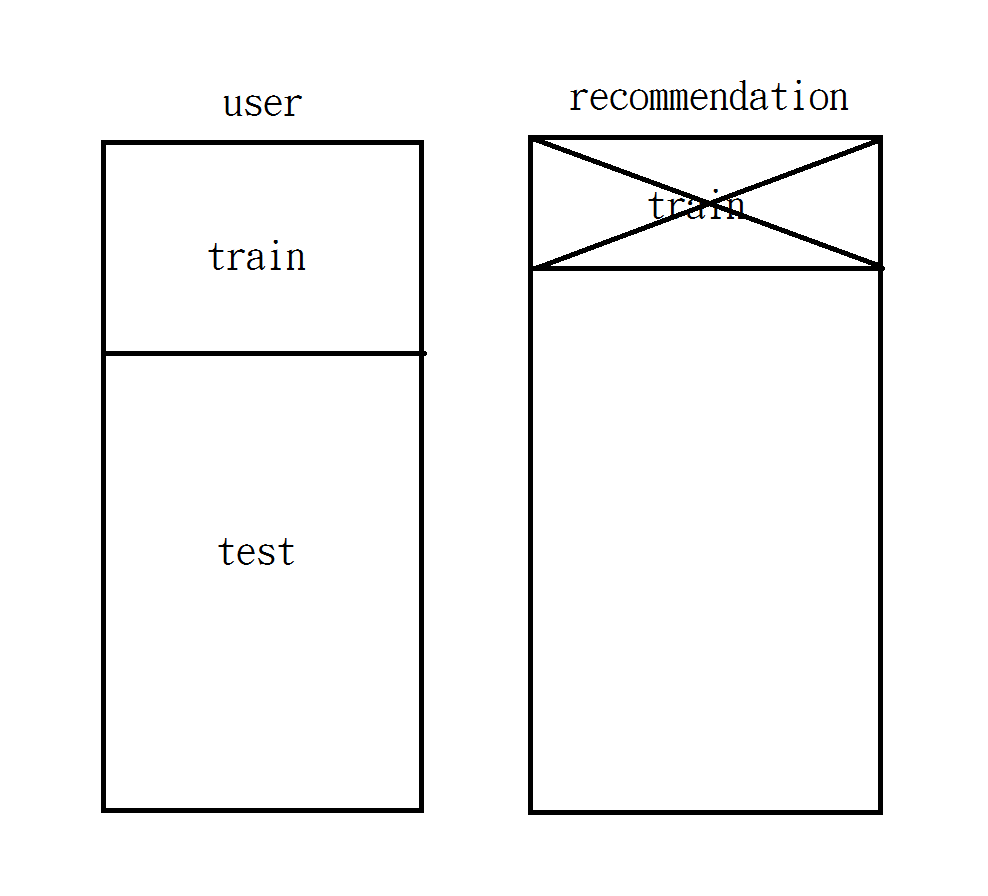
Reference
- https://www.microsoft.com/en-us/research/publication/evaluating-recommender-systems/
Model
Model 1: KNN
- Put anime vector to build a k-d tree
- Fit user vector with k-d tree with cosine distance
- Recommend some nearest animes
Model 2: Anime Clustering
- Group animes into several clusters
- Fit user instance into one of the clusters
- Recommend animes in that cluster with high rating
Model 3: User Clustering
- Group users into several clusters
- Fit user instance into one of the clusters
- Recommend animes in that cluster with high rating
Machine Learning
By deror1869107




