Adventures in Scaling Hoyle
Dustin McCraw
3/10/20
Hoyle?
Card service
for IOS and Android.

It makes a bunch of calls in parallel to Snapi so that mobile doesn't have to. Allows changes to the cards without needing to update mobile clients.
Elixir
Hoyle is written in Elixir and Phoenix.
Elixir is a dynamic, functional language designed for building scalable and maintainable applications.
- Scalability
- Functional
- Concurrency
- Fault tolerance
- Clean syntax


Uses Phoenix web framework.
- Incredibly fast (microseconds)
- Great real-time communication
The Road to 2 Million Websocket Connections in Phoenix
https://www.phoenixframework.org/blog/the-road-to-2-million-websocket-connections
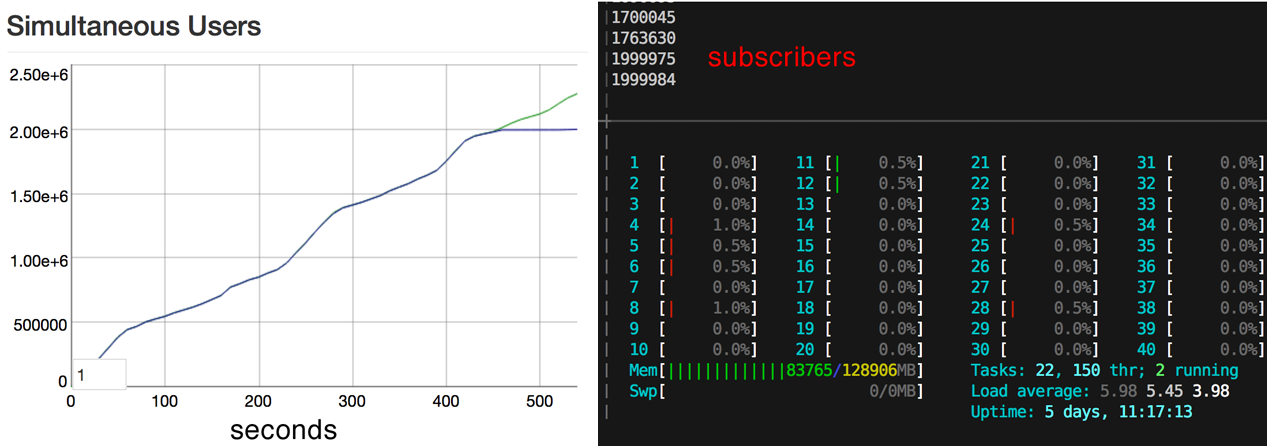
Where did this journey begin?
- We lost some strong Elixir devs.
- I heard Hoyle was costing us a bunch of money.
- I want to be an advocate for Elixir.
- Looked at DataDog and noticed we were running between 60-80 Kubernetes Pods
60-80 pods/containers?!?!?!?!?!?!?
How can this be possible with Elixir?
Kubernetes
- Pod/Container is running 1 instance of the code
- Hoyle was running on Kubernetes (Kube)
- Kube allows us to autoscale once it reaches certain cpu or memory limits both up and down
- So Kube would create/destroy pods
Kube takes care of scaling for us.
We just have to find the correct settings.
So I had to figure out what was causing it to scale to 80 pods.
Observability, Observability, observability
- Updated Spandex (DataDog client) on Hoyle
- Instantly saw very large images taking up to 2-3 seconds to serve. (multiple MB's)
- Mentioned it in #platform and Ryan W had it cached in Cloudflare in about 20 minutes.
- Also fixed a log error that was eating up log space that Paul H mentioned.
- Kube auto scaled down because we were serving those images.
Observability

Memory Leak?
- Kube was destroying containers because the pod would grow up RAM.
- Paul suggested a memory leak.
- The actor model in Elixir is great at releasing memory so the theory was it had to be code.
I found code that was setting ETS but never deleting it.
Fixed that and now Kube wasn't bringing down
pods because of memory.
But we were still running 35 pods
Elixir has it's own built in memory cache called ETS (Erlang Term Storage) so no need to bring in redis or memcache.
Idle CPU
But we were still running 35 pods
Looking over DataDog I saw 35 pods but with less than 1% CPU, basically, idling?
That's when I learned about Kube resources.
Kube Resources
You can configure what Kube uses when creating a new pod and for determining when a pod is using too many resources.
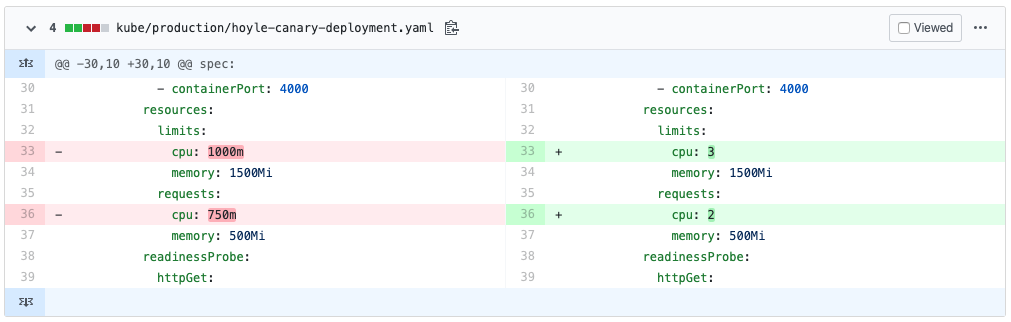
The settings on the left make sense for a Ruby app since it can't take advantage of multiple cores.
But Elixir can use all of a machines cpu's.
Kube Resources
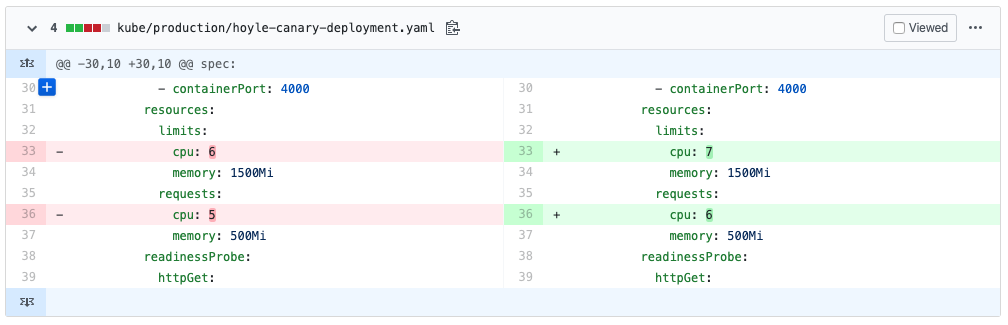
We had to limit our resources to 7 CPUs since our
Kube cluster only has 8 CPUs.
Improved Caching
By examining what was being called there was more caching we can do.
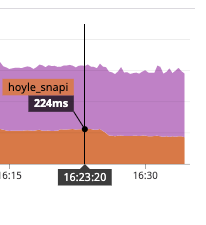
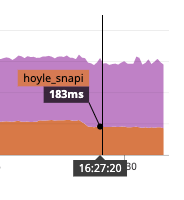
18% decrease response time
Current State
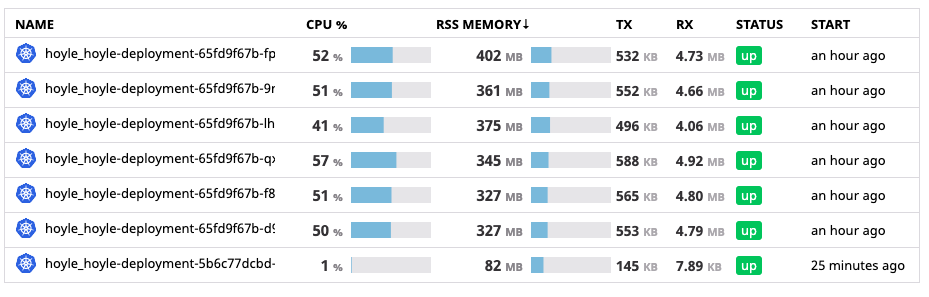
Success!!!
We auto-scale between 1 and 7 pods
depending on traffic down from 60-80.
P.S. The one on the bottom is our staging server.
Current State
At the peak, with 7 pods running:
130 requests per second
3100 requests per second to Snapi
23 Snapi calls in
600ms AVERAGE response time
Almost 1/3 of all traffic to Snapi comes from Hoyle on only 7 pods.
Future Improvements?
Use a simpler serializer format
Use the smaller json format Snapi supports, or gzip or http2
application/prs.snapi+json
More CPU's
What if we made our clusters larger? 12-16 CPU's?
BETTER CACHING
What if we have longer TTL's? specific endpoint caching?
Better observability
What's our cache hit rate?
How many times a specific card is displayed?
THANKS!
Questions?
Scaling Hoyle
By Dustin McCraw




