Transfer & Multitask
Advanced RL, Spring 2020
Dmitry Nikulin | 30 April

Spinning Up Key Papers
Multitask
Transfer
Learn task A, then use that to learn task B faster.
- Task Embeddings
- sim2real: MATL
- Too Many GPUs: Progressive Networks, PathNet
Multitask
Multitask
But what are we talking about, exactly?



Example tasks
- Move robotic hand into a particular position
- Drive to a particular point
- Solve an Atari game
Formal definition
based on http://arxiv.org/abs/1910.10897
- Learn a single task-conditioned policy \( \pi \left( a \mid s, \tau \right) \), ...
- where \( \tau \) is an encoding of a task ...
- from a distribution \( \tau \sim p( \mathcal{T} ) \) ...
- and the task is defined by its own discount function \( \gamma_{\tau}(s) \) and reward function \( R_{\tau}(s, a, s') \).
- Policy \( \pi \) should maximize average expected return:
- \( \mathbb{E}_{\tau \sim p( \mathcal{T} )} \left[ \mathbb{E}_{s_0, \pi} \left[ \sum\limits_{t=0}^T \left( \prod\limits_{t'=0}^{t-1} \gamma_\tau \left( s_{t'} \right) \right) R_{\tau}(s_t, a_t, s_{t + 1}) \right] \right] \).
(see next slide for why we vary \( \gamma \))
Special case: reaching goal state
Reach state \( g \):
\[ \begin{aligned} R_g(s, a, s') &= \mathbb{I} \left[ s' = g \right] \\ \gamma_g(s) &= 0.99 \cdot \mathbb{I} \left[ s \neq g \right] \end{aligned} \]
i.e. \( g \) becomes a pseudo-terminal state.
(this is pretty much the only case where \( \gamma \) is non-constant)
Benchmarks
(or lack thereof)
Benchmarks
There is no standard benchmark in Multitask/Transfer.
Each paper rolls out their own evaluation.




Benchmarks
Discrete actions: train a single agent to play multiple Atari games (select those where your results are most convincing).
Optionally: a Quake 3 fork.
Benchmarks
- Continuous actions: multiple attempts, most recent one is MetaWorld.
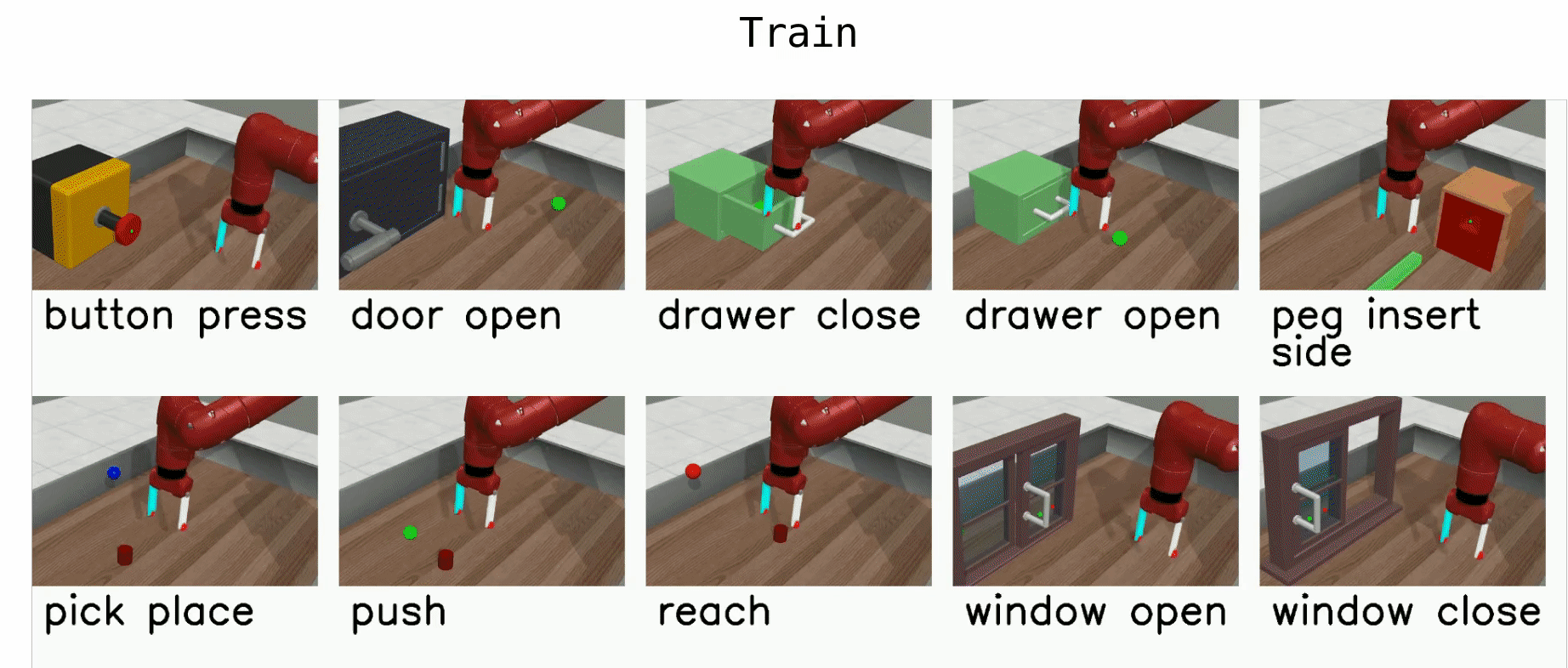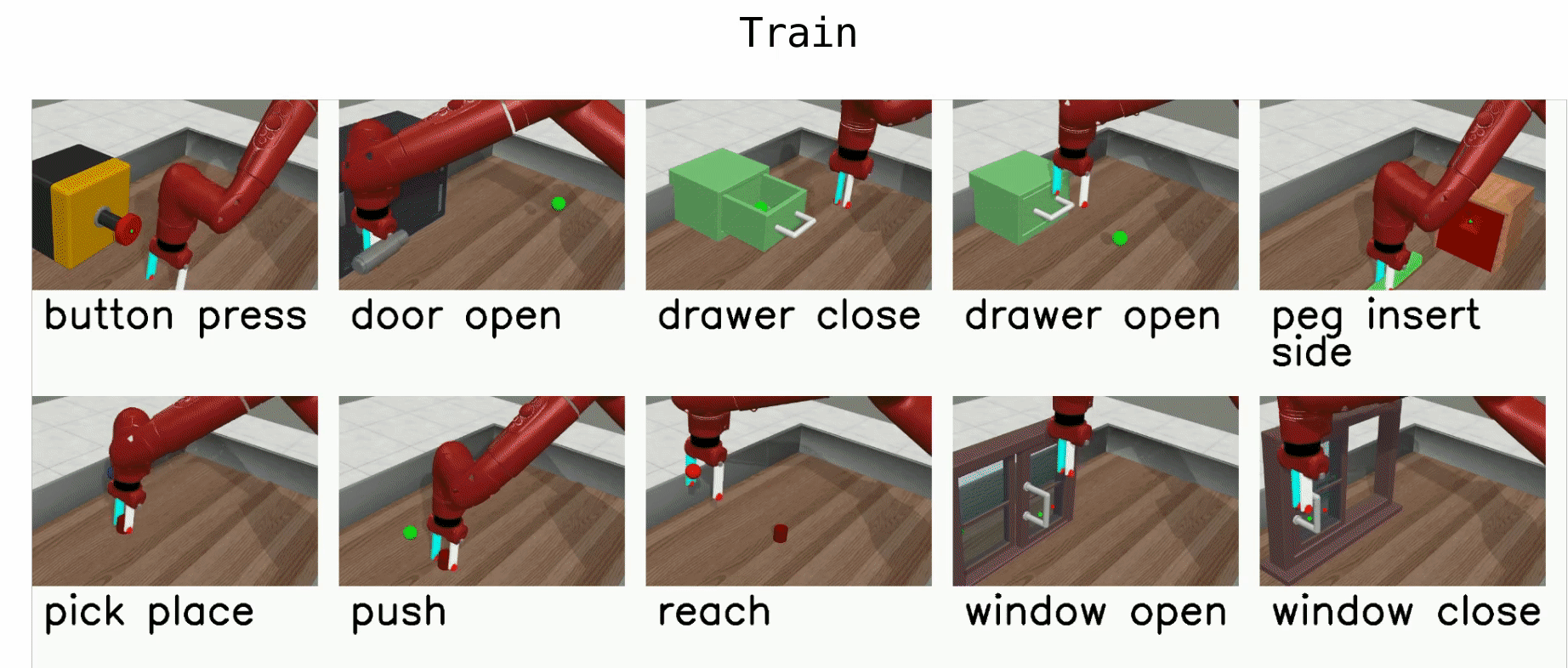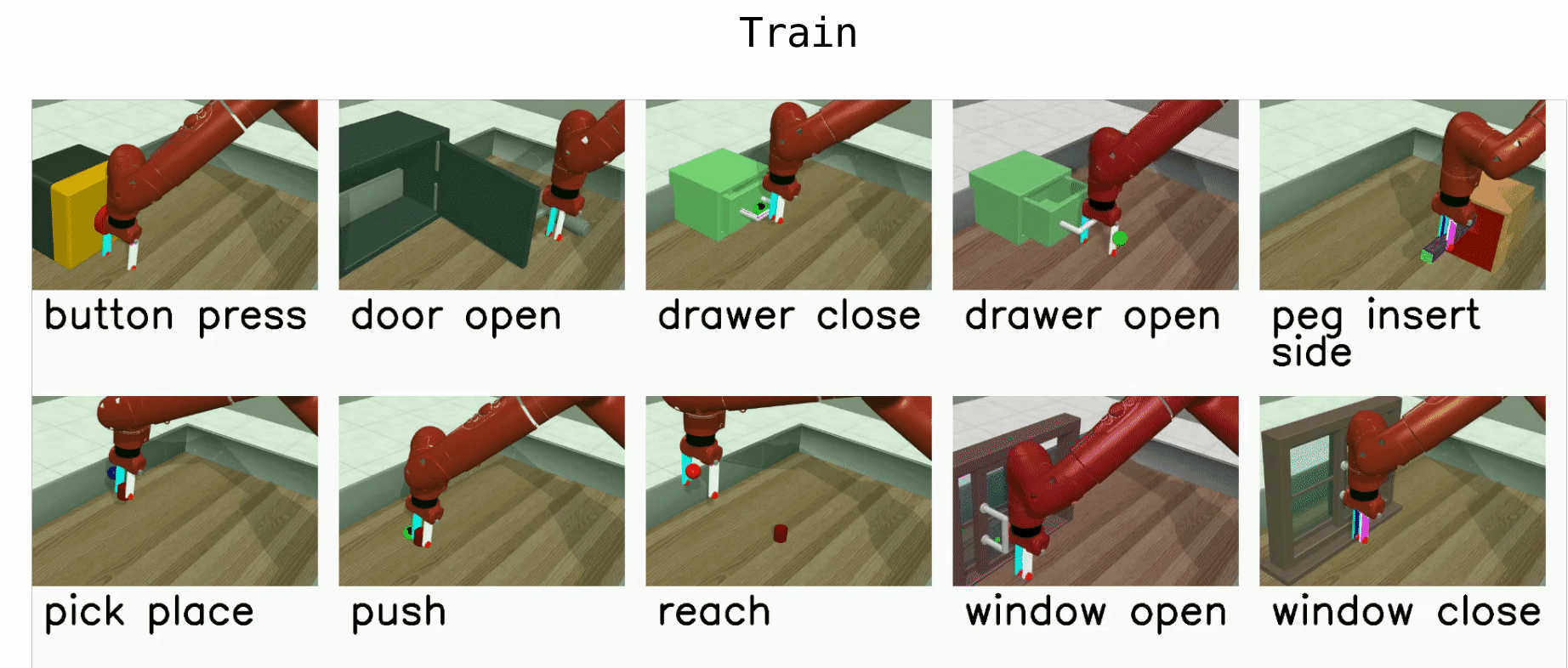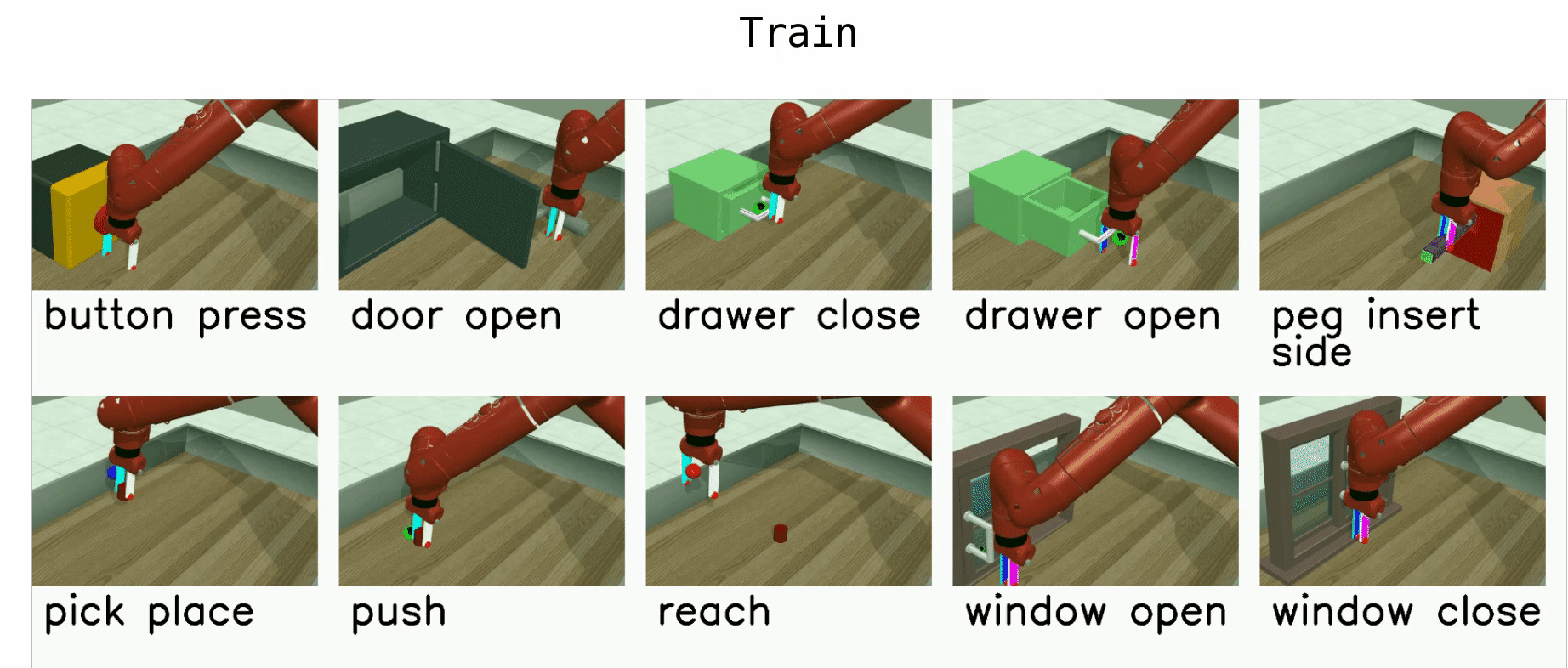
Yu et al. (Stanford & co), CoRL 2019, 263 GitHub stars
Meta-world
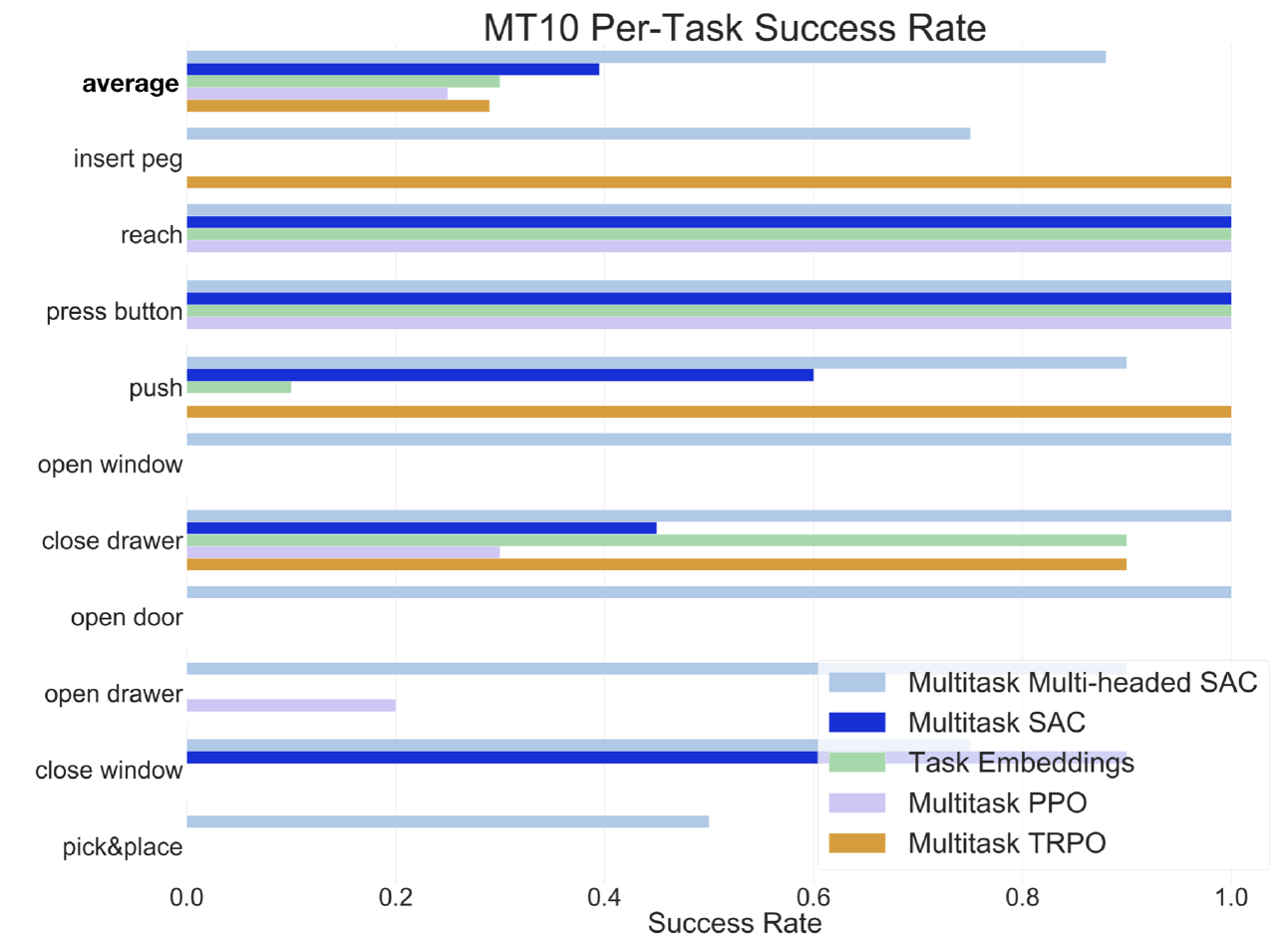
Multitask
finally, SpinUp papers
Universal Value Function Approximators
- Introduce definitions that inspired a previous section;
- Train \( V(s, g; \theta) \) and \( Q(s, a, g; \theta) \) via off-policy Q-learning.
But:
- They train a bunch of different networks \( Q_g(s, a; \theta_g) \) ("Horde architecture") and then distill them into one \( Q(s, a, g; \theta) \)
- They do distillation via rank-n matrix factorization
- 🚲 Evaluation on toy environments (custom gridworlds), and one experiment on MsPacman
Schaul et al. (DeepMind), ICML 2015, 319 citations
Hindsight Experience Replay
Andrychowicz et al. (OpenAI), NIPS 2017, 512 citations
Motivating example:
- States: \(N\)-bit vector
- Actions: flip \(k\)-th bit
- Reward: \( R(s, a, s') = \mathbb{I}\left[ s' = g \right] \)
- Agent receives \(g\) as input.
tl;dr: very large state space with very sparse rewards, but easy to solve once we figure it out.
Hindsight Experience Replay
- Policy \( \pi \) takes goal \( g \) as input
- Tuple \( (s_t, g, a_t, r_t, s_{t + 1}) \) goes in the replay buffer
- But we put there \( (s_t, s_T, a_t, r_t, s_{t + 1}) \) as well (\( s_T \) is the final state in a trajectory)
- Can also put \( (s_t, s_{t'}, a_t, r_t, s_{t + 1}) \) for several random \( t' > t \) (works better)
- Train any off-policy algorithm on that replay buffer
Hindsight Experience Replay
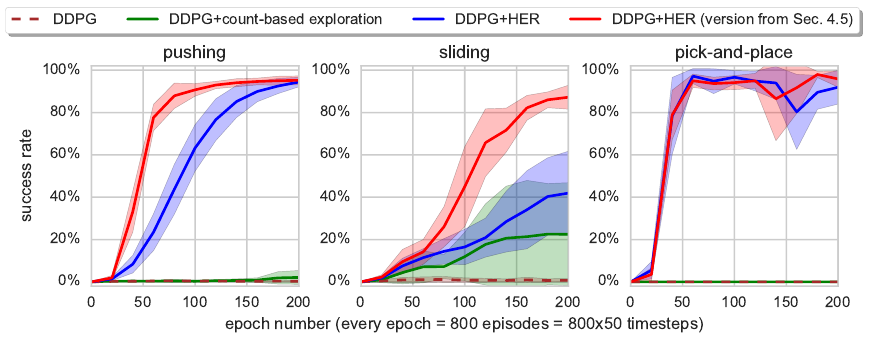
🚲 Evaluation: custom robotic arm manipulation environment based on MuJoCo
Hindsight Experience Replay
Intentional-Unintentional Agent
Cabi et al. (DeepMind), CoRL 2017, 17 citations
tl;dr: train a bunch of DDPG instances in parallel on one stream of experience while executing one of the policies being trained.
(intentional = behavioral policy, unintentional = other policies)
Intentional-Unintentional Agent
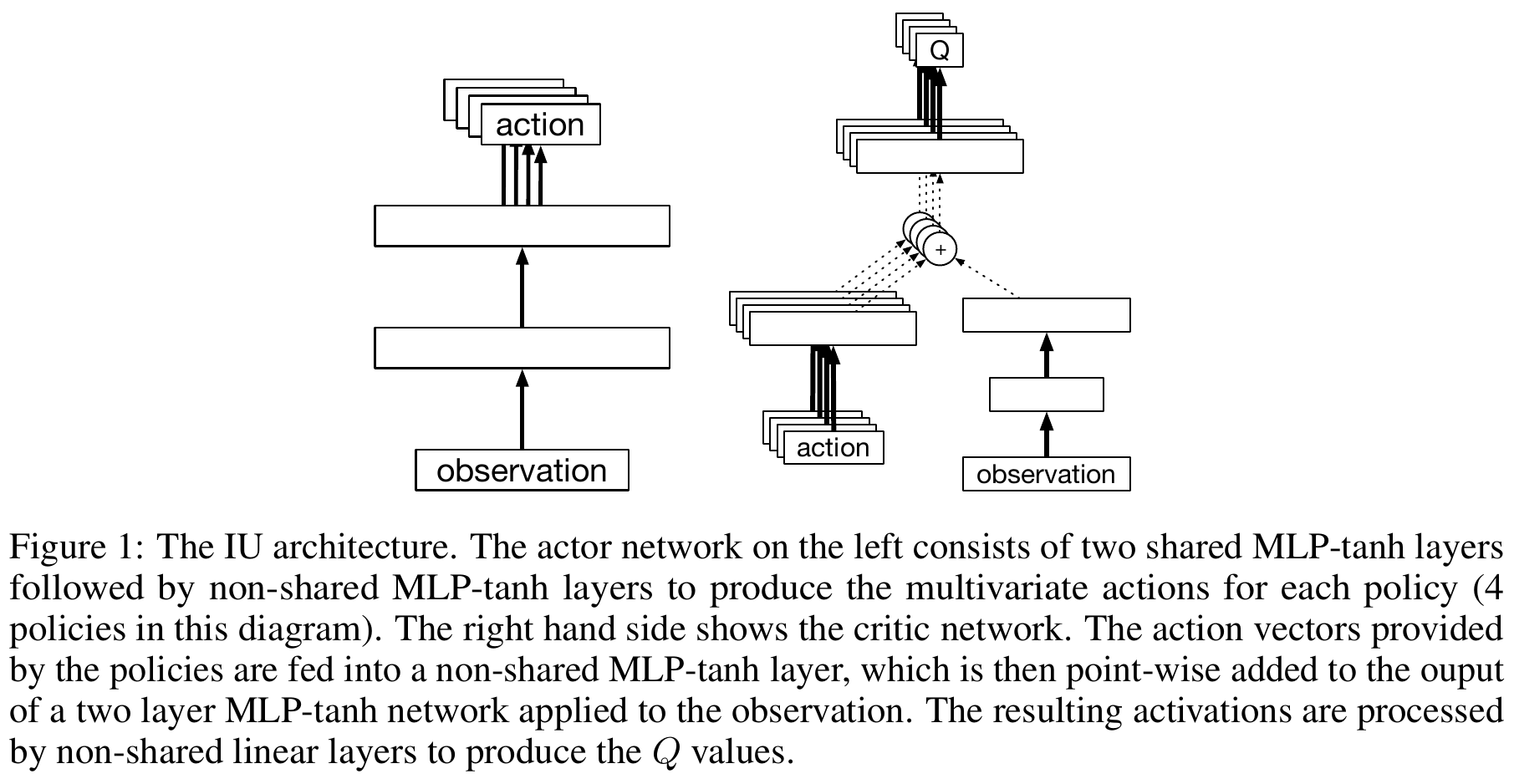
Intentional-Unintentional Agent
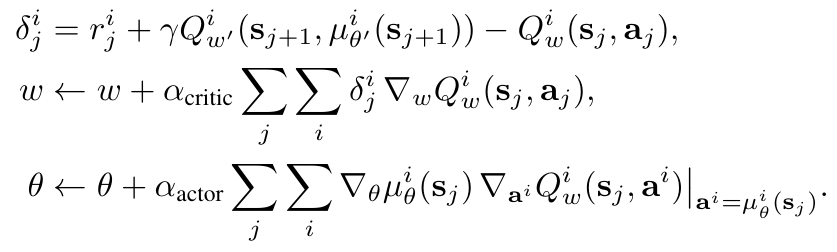
\( \theta \) — actor parameters
\( w \) — critic parameters (\( w' \) — target network)
\( i \) — index of a policy that solves \(i\)-th task
\( j \) — timestep
Intentional-Unintentional Agent
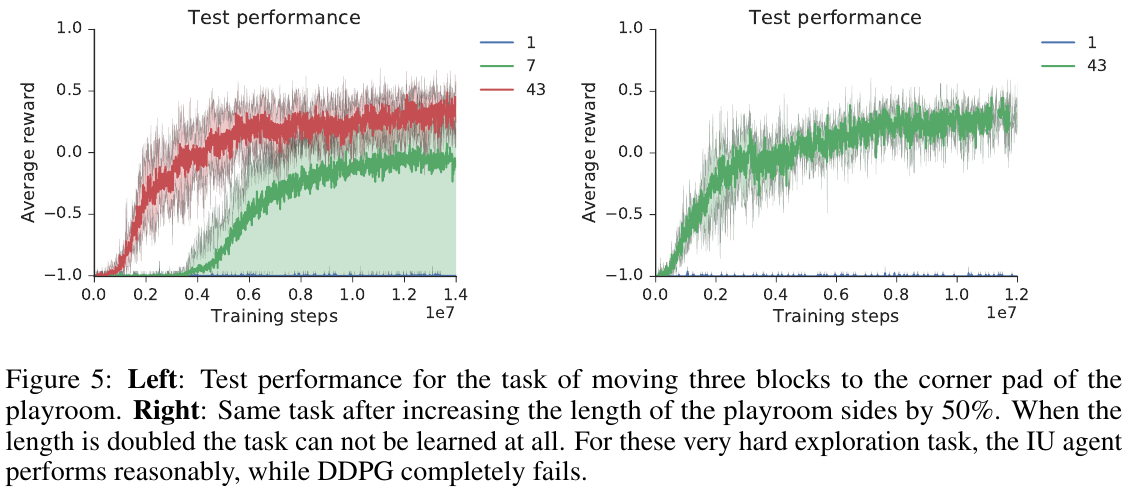
🚲 Evaluation:
- Custom environment based on MuJoCo
- Comparison only with plain DDPG
- \( \approx 10^7 \) training steps
- Up to 43 tasks
Example tasks:
- Bring red object near blue one
- Put green object in the corner

Intentional-Unintentional Agent
Results:
- More tasks = better performance of each task, up to a limit
- Making the hardest task intentional (behavioral) works best
UNREAL
- "Reinforcement Learning with Unsupervised Auxiliary Tasks"
- UNsupervised REinforcement and Auxiliary Learning
- Not really multitask: all auxiliary tasks are only used to improve performance on the main task
Jaderberg et al. (DeepMind), ICLR 2017, 508 citations
UNREAL
Train an A3C agent with a bunch of synthetic goals optimized via Q-learning:
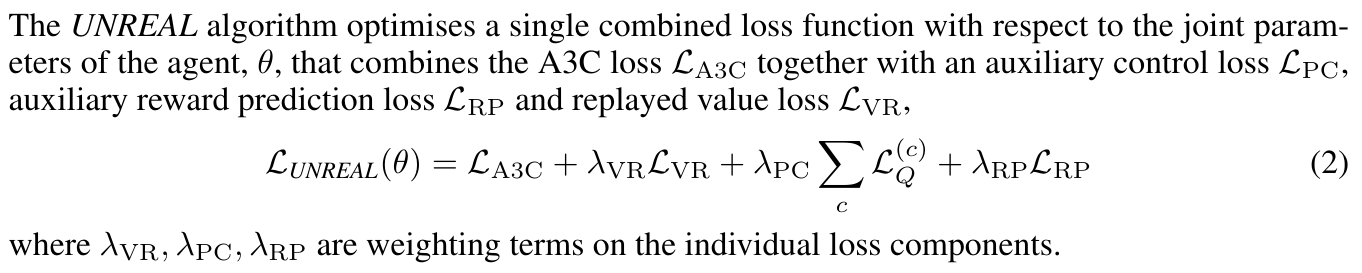
UNREAL
Auxiliary control tasks:
- Pixel changes: which action will produce maximal change in pixel intensity in this region of the input?
- Network features: which action will maximally activate a specific hidden layer?
UNREAL
Auxiliary reward prediction:
- Given \( k \) input frames, what will be the next reward?
- Classification: zero/positive/negative
- Train on replay buffer with a skewed distribution
(\( \mathbb{P}(r \neq 0) = \frac 1 2 \))
UNREAL
Auxiliary value function replay:
- just train A3C value function on replay buffer
UNREAL
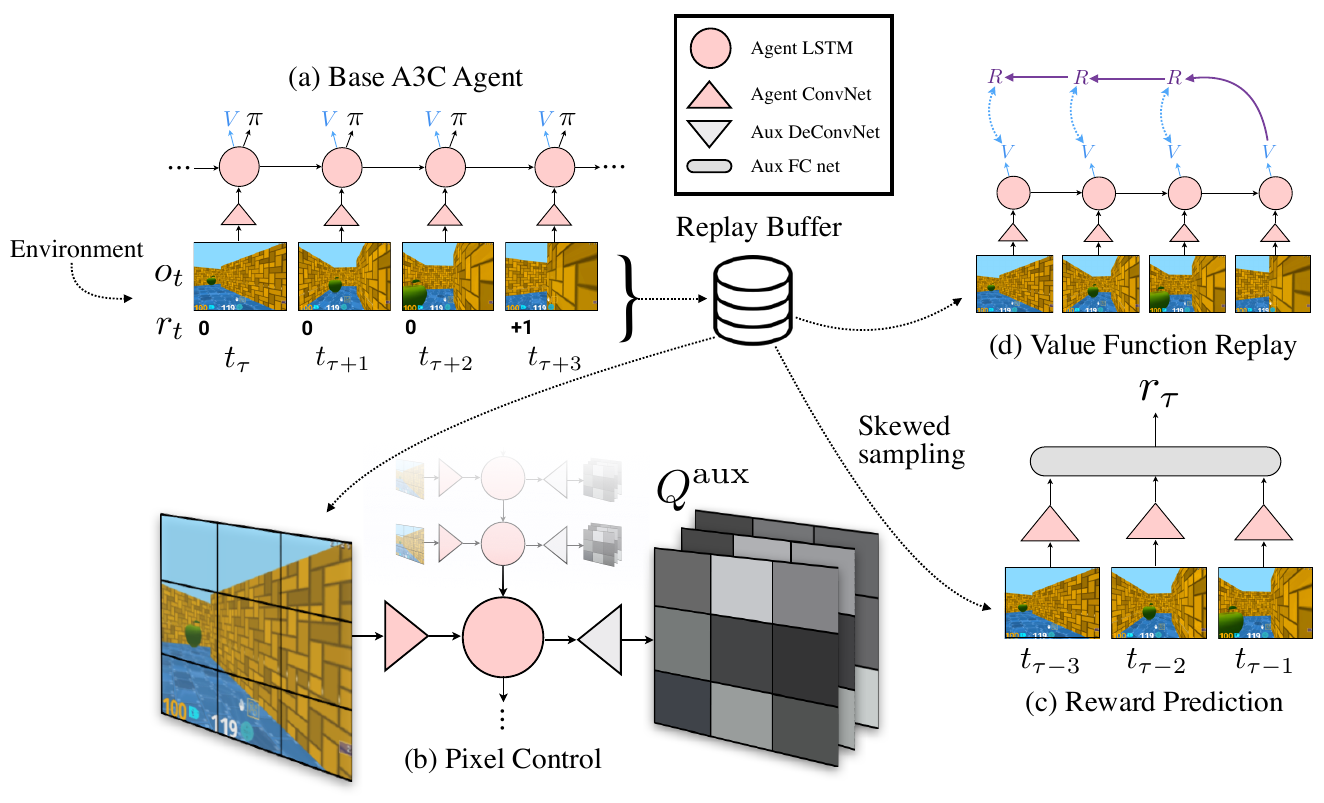
another illustration: https://github.com/miyosuda/unreal
UNREAL
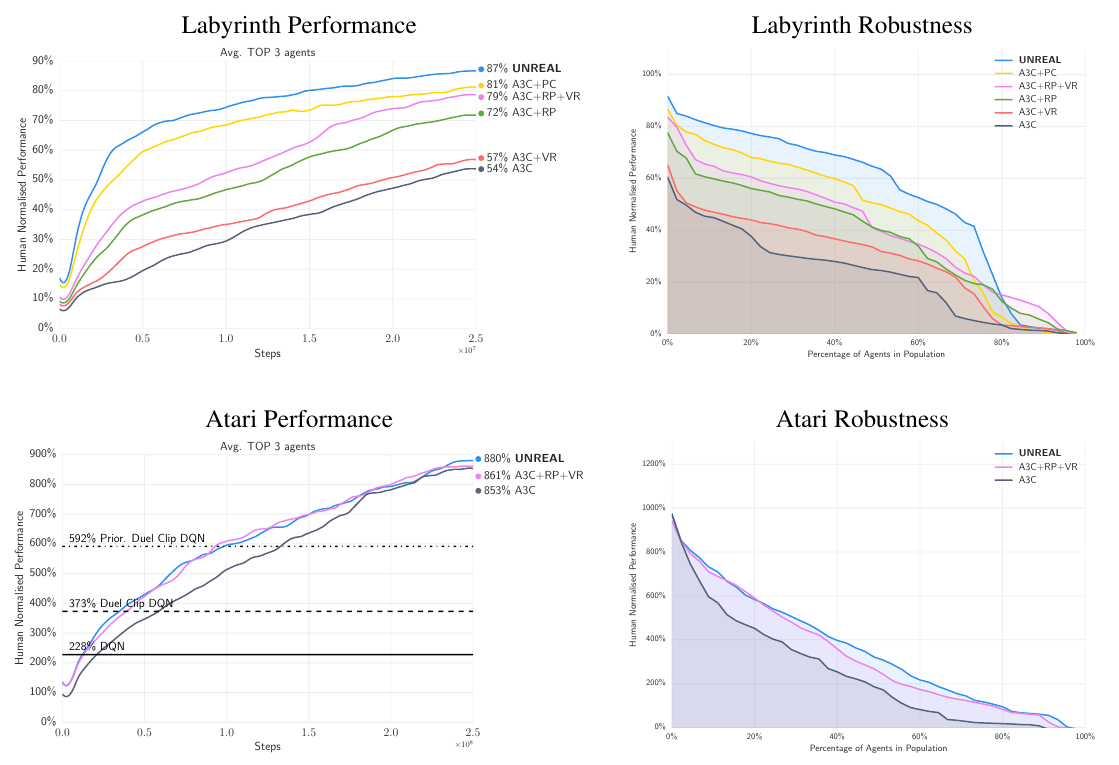
UNREAL
Transfer
Mutual Alignment Transfer Learning
Wulfmeier et al. (BAIR), CoRL 2017, 27 citations
- Suppose we have a simulator that is really good at reproducing states (i.e. sensor readings), but not environments dynamics.
- We can use a discriminator to make the simulator policy \( \pi_{sim} \) learn to produce the same trajectories as \( \pi_{real} \) using different actions.
- \( \pi_{sim} \) will be effectively a generator, and the whole thing will be a GAN.
Mutual Alignment Transfer Learning
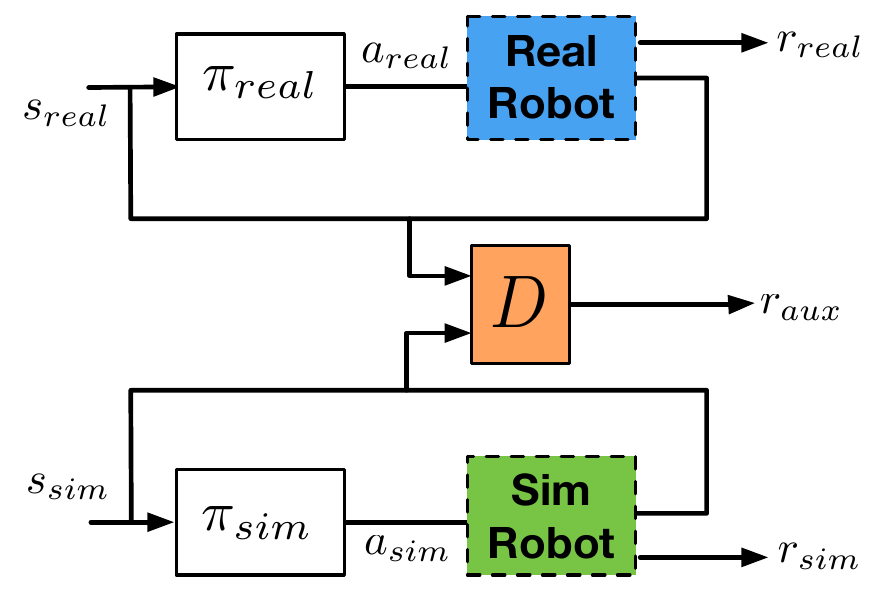
Mutual Alignment Transfer Learning
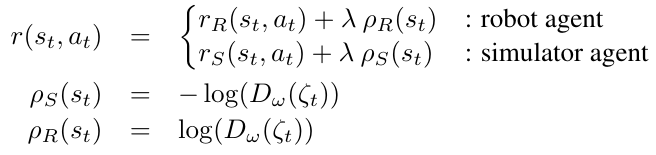
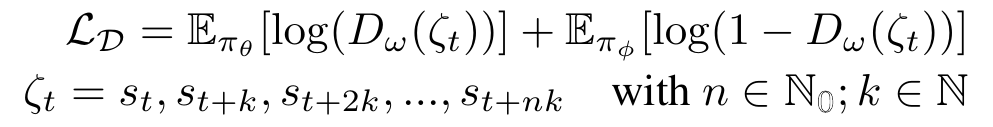
Mutual Alignment Transfer Learning

Mutual Alignment Transfer Learning
🚲 Evaluation: transfer between two different simulators.

Mutual Alignment Transfer Learning
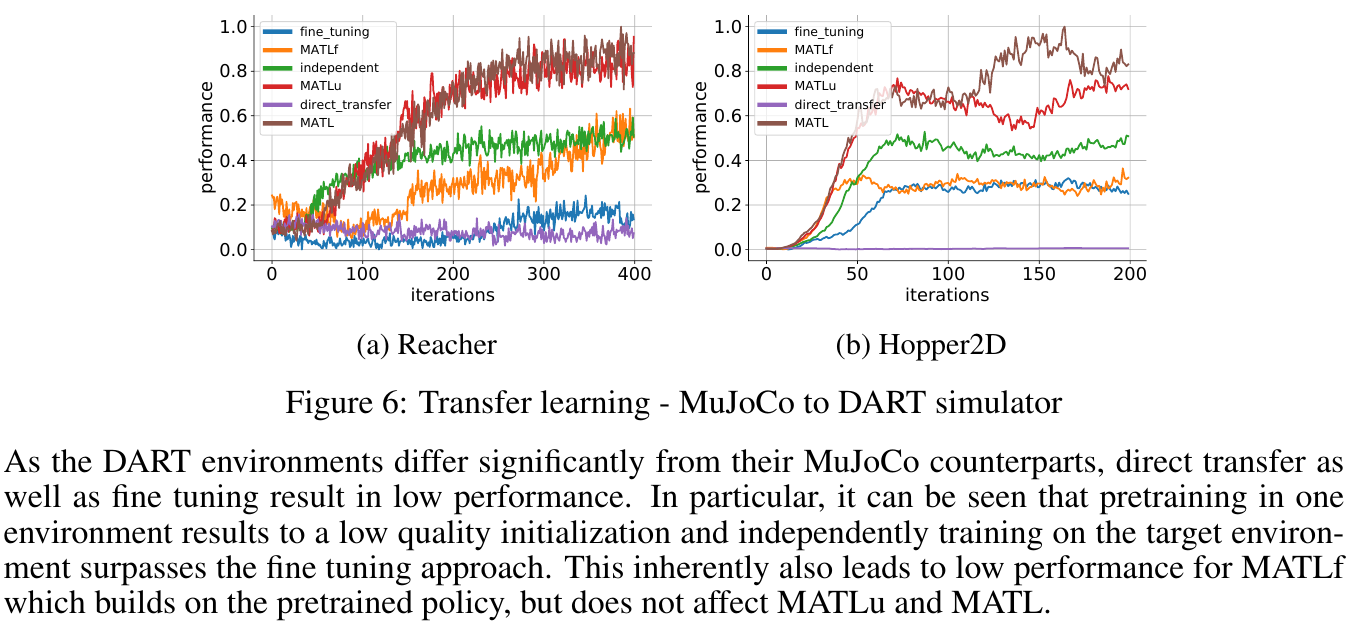
Embedding Space for Robot Skills
Hausman et al. (DeepMind), ICLR 2018, 76 citations
- For each task \( \tau \) (e.g., one-hot encoded), we can learn a distribution of embeddings \( p_\phi \left( z \mid \tau \right) \), ...
- a task embedding-conditioned policy \( \pi_\theta \left( a \mid s_i, z \right) \), ...
- and a distribution \( q_\psi \left( z \mid a, s_i^H \right) \) that identifies task embeddings based on a trajectory segment \( s_i^H = \left[ s_{i - H}, \ldots, s_i \right] \).
Embedding Space for Robot Skills
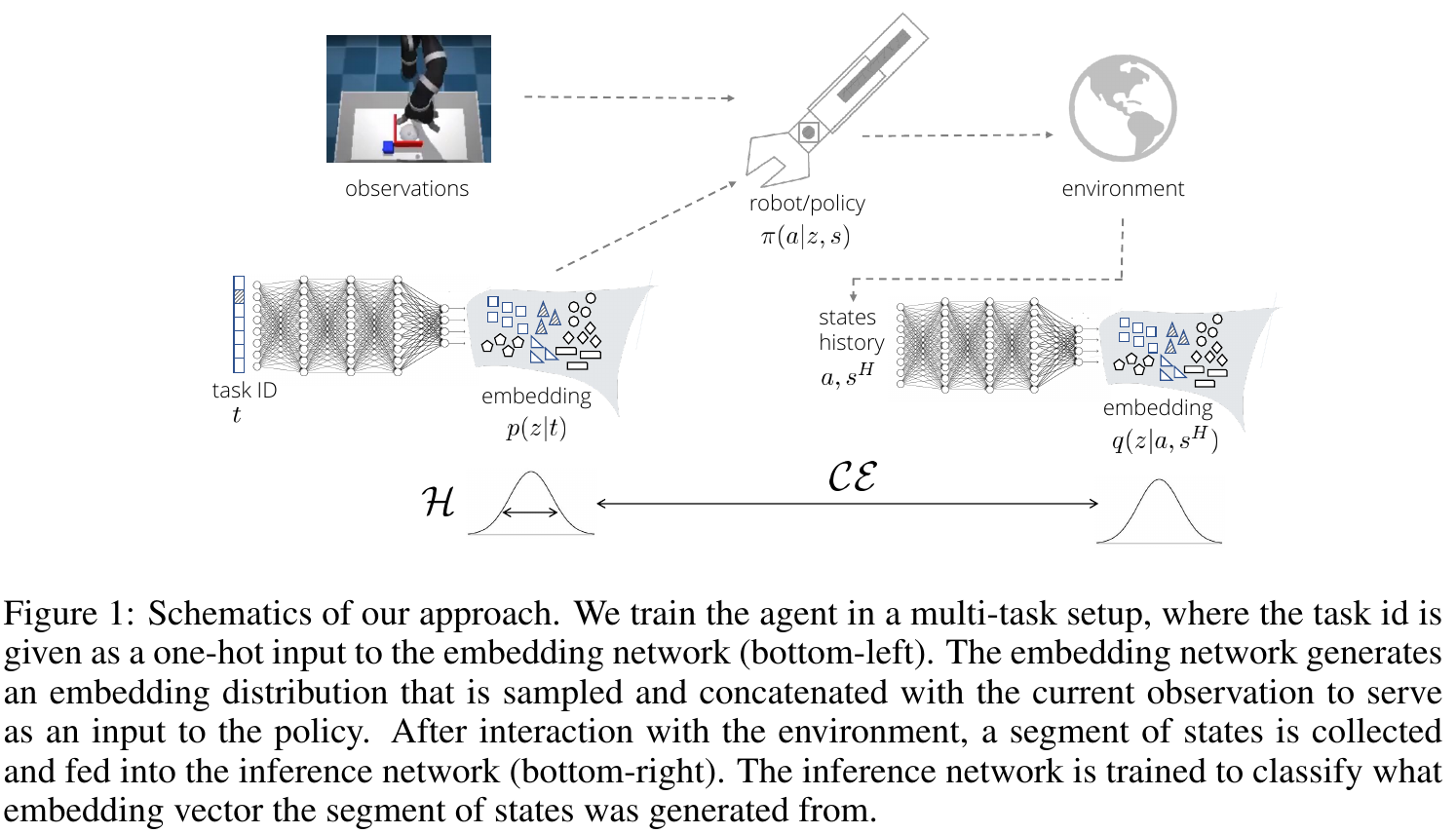
Embedding Space for Robot Skills
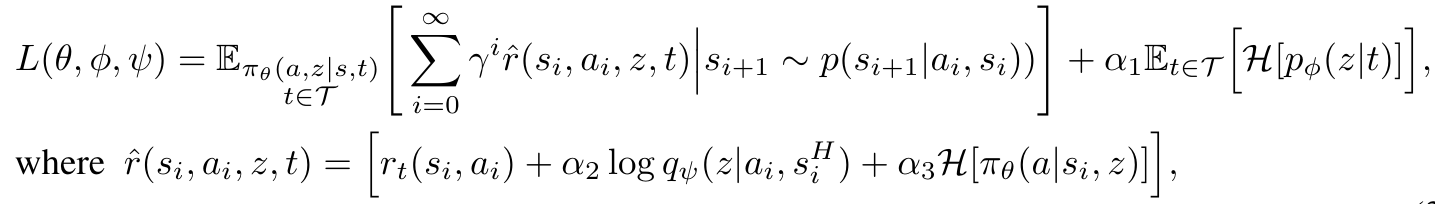
In training, the following is maximized:
env. reward
log-likelihood of true \( z \)
policy entropy
embedding entropy
(this is actually maximization of a lower bound on return of an entropy-regularized policy via variational inference)
Embedding Space for Robot Skills
For \( p_\phi \) and \( \pi_\theta \), this is done by learning a function \( Q_\varphi^\pi \) on the replay buffer with an off-policy correction:
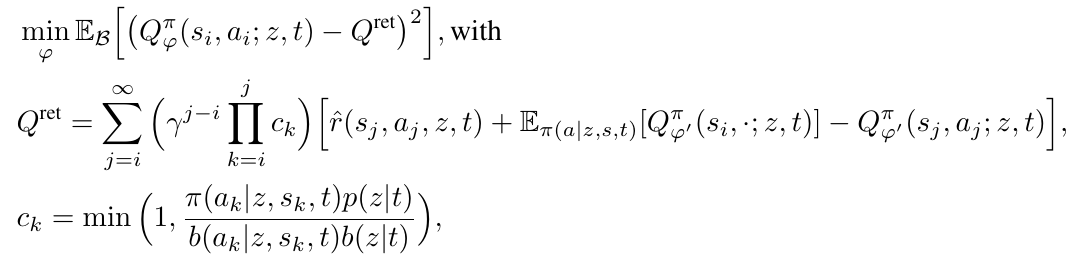
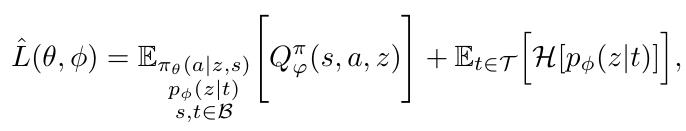
and then maximizing:
Embedding Space for Robot Skills
For \( q_\psi \) (inference network), we maximize:
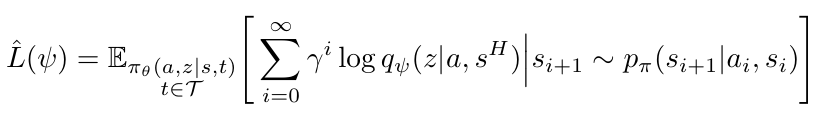
This is supervised learning, done offline, using the replay buffer.
Embedding Space for Robot Skills
The term for log-likelihood of true \( z \) in agent's reward helps generate more diverse trajectories:
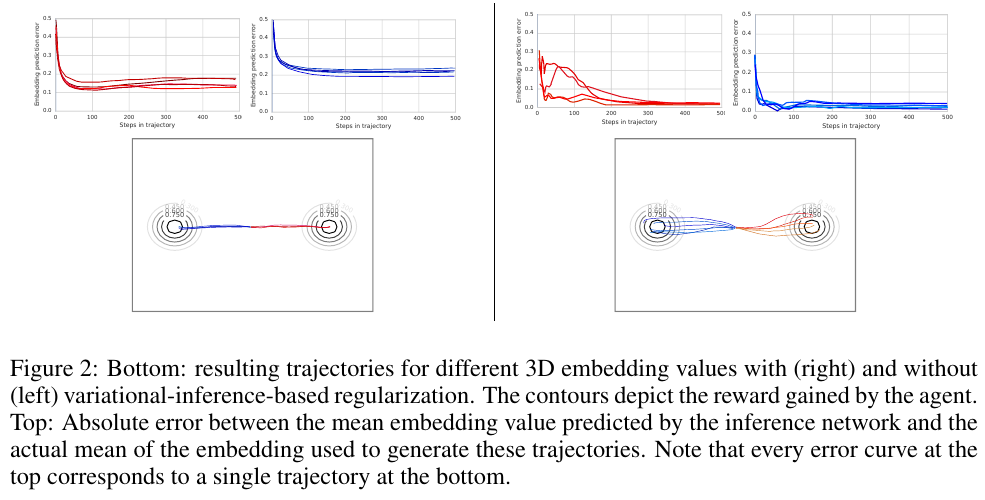
Embedding Space for Robot Skills
🚲 Evaluation: transfer learning for robotic manipulation.
- Multiple target tasks, like moving a block that is attached to a spring over a wall to a goal position (while stretching the spring).
- Pretraining on related but different tasks, like bringing a block attached to a spring to a goal position (no wall).
- Then transfer to target task, freezing the policy network \( \pi_\theta \) and only training* a new task-embedding network \(z = f_\vartheta(t)\).
* text actually says "state-embedding network \( z = f_\vartheta(x) \)", but this seems to be a mistake
Embedding Space for Robot Skills
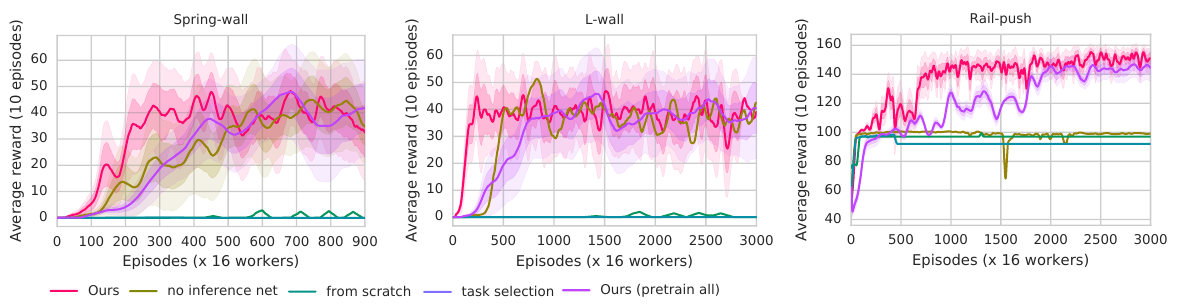
- from scratch = no transfer
- task selection = no \( z \), policy receives \( t \) directly
- pretrain all = pre-training on all auxiliary tasks for all environments, not just the target one
Progressive Neural Networks
Rusu et al. (DeepMind), arXiv 2016, 592 citations
- Train a network to do a task
- Freeze its weights
- Train a second network to do another task, using hidden activations of the first network as input for the second one
Progressive Neural Networks
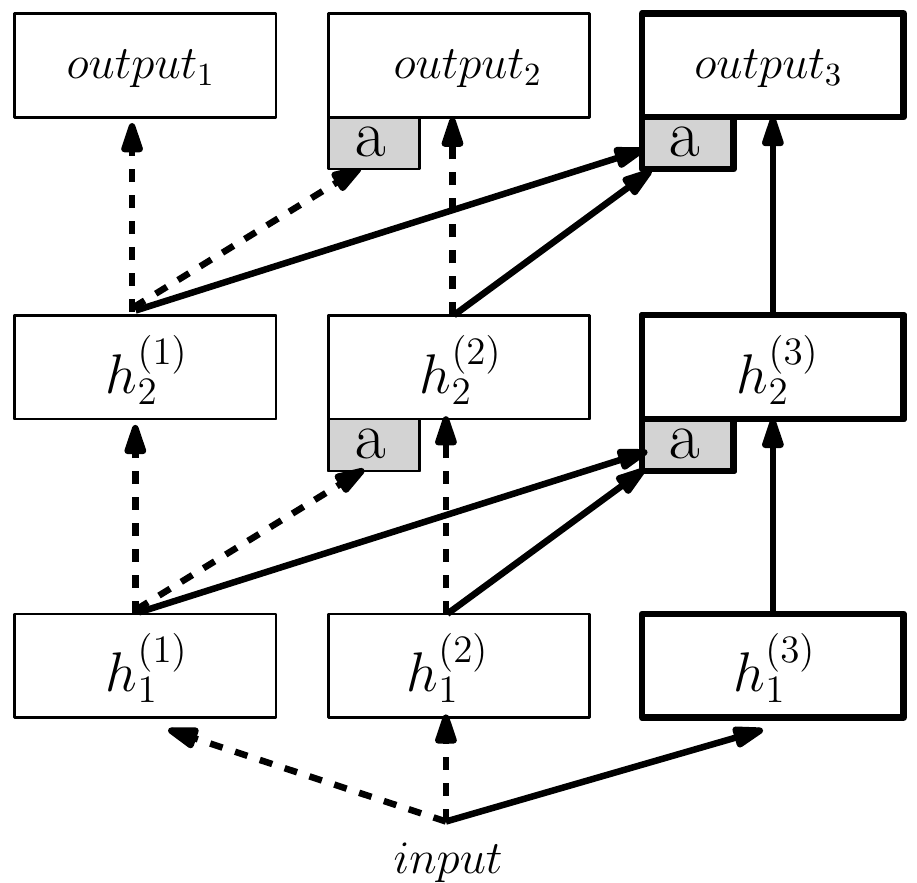
\( h_i^{(k)} = \operatorname{ReLU} \left( W_i^{(k)} h_{i-1}^{(k)} + \sum_{j = 1}^{k - 1} \operatorname{MLP}_i^{(k:j)} \left( h^{(j)}_{i - 1} \right) \right) \), where
\(i\) — layer index
\(j, k\) — column indices
\( \operatorname{MLP}_i^{(k:j)} \left( h^{(j)}_{i - 1} \right) = U_i^{(k:j)} \sigma \left( P_i^{(k:j)} \alpha_{i - 1}^{(j)} h^{(j)}_{i - 1} \right) \)
\( W_i^{(k)} \), \( U_i^{(k:j)} \) — linear layers
\( P_i^{(k:j)} \) — projection matrix
\( \alpha_{i - 1}^{(j)} \) — learnable scalar
\( \sigma \) — some nonlinearity
Progressive Neural Networks

Evaluation baselines:
- Train from scratch
- Finetune last layer
- Finetune all layers
- Random frozen first column
Progressive Neural Networks
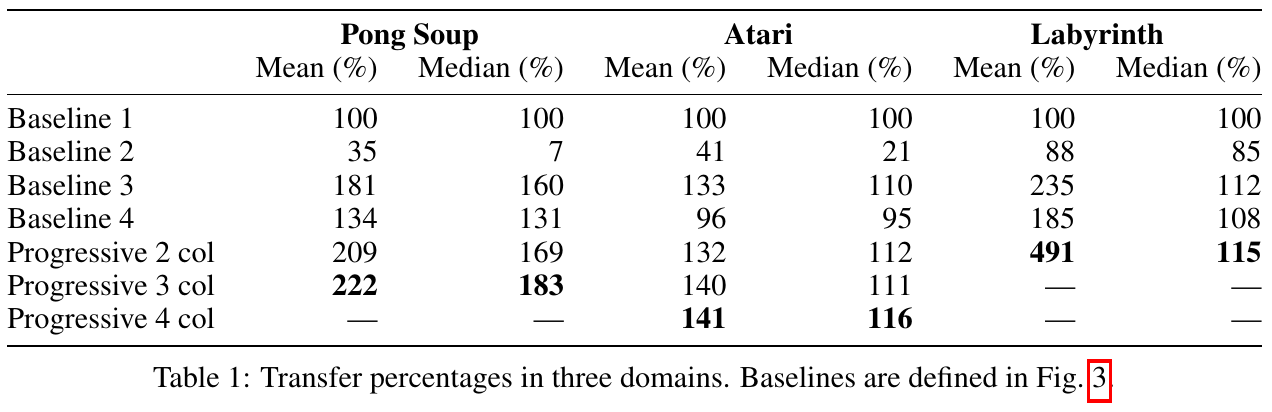
Progressive Neural Networks
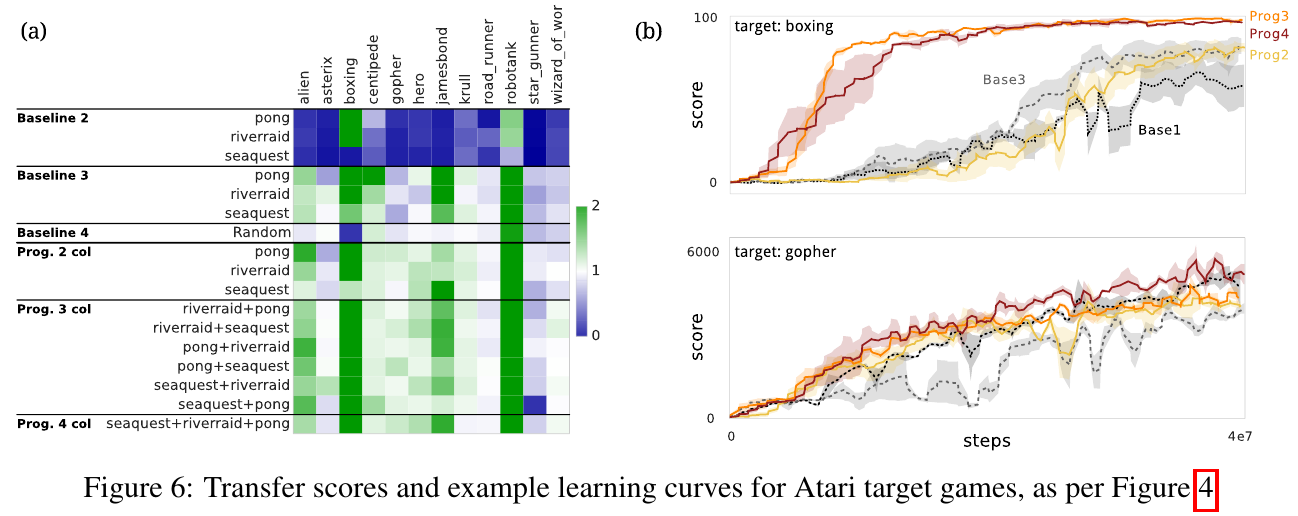
Progressive Neural Networks
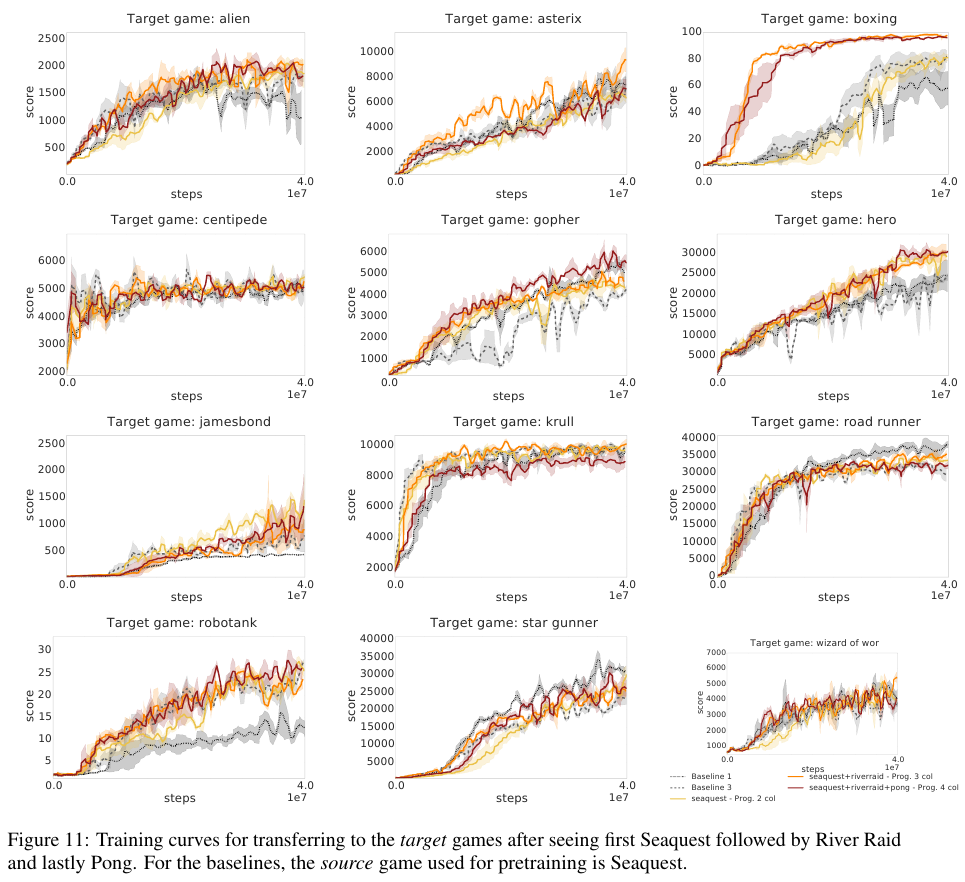

PathNet
Fernando et al. (DeepMind), arXiv 2017, 263 citations
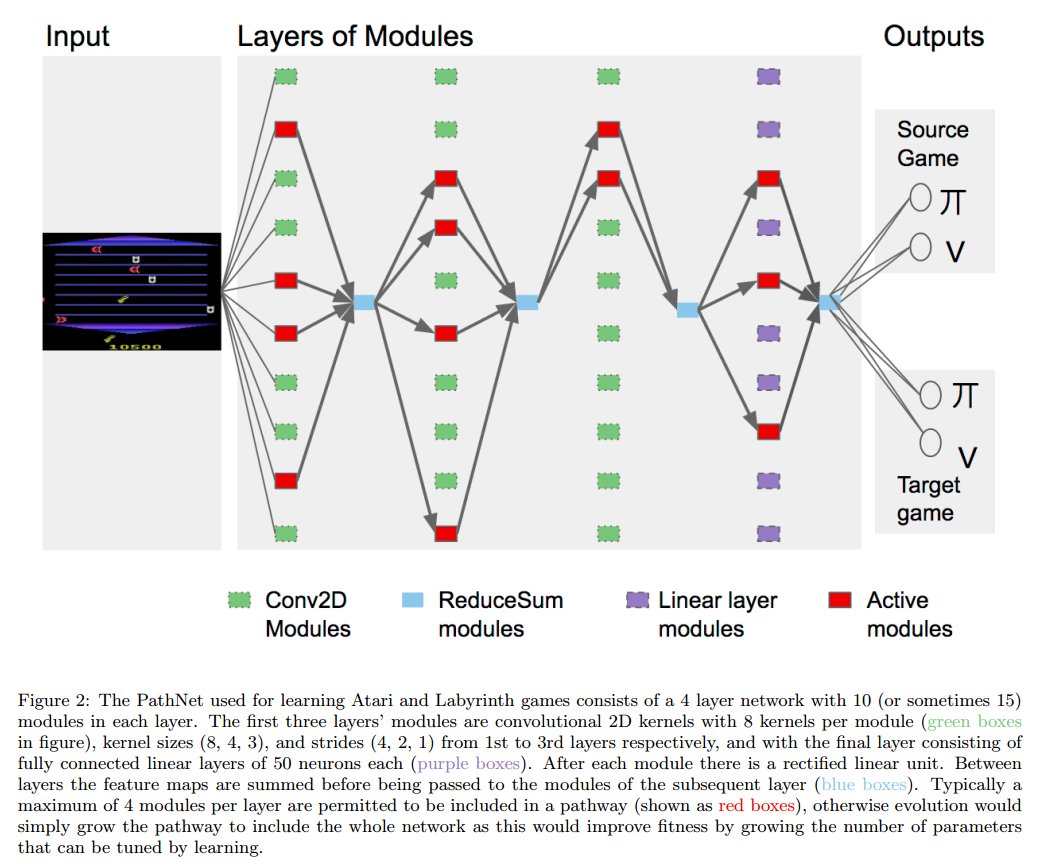
PathNet
Architecture:
- \( L \) layers, \( M \) modules in each, each module is a small network
- Pathway = a set of "active" modules in each layer (at most \( N \) in each layer, typically \( N = 3 \) or \( 4 \))
- Different pathways can (and do) share layers
- Outputs of modules are summed between layers
- Final layer is not shared between tasks
PathNet
Training:
- Spawn a bunch of workers, train them for \( T \) epochs
- Fitness = average reward during training
- Once \( T \) epochs are complete, worker writes its own fitness to a shared array and compares it to \( B \) other fitness values
- If there is a larger fitness value, worker's pathway is overwritten with winner's weights with mutation
After training, winning pathway's weights are frozen before starting to train for another task. Other weights are reinitialized.
PathNet
PathNet
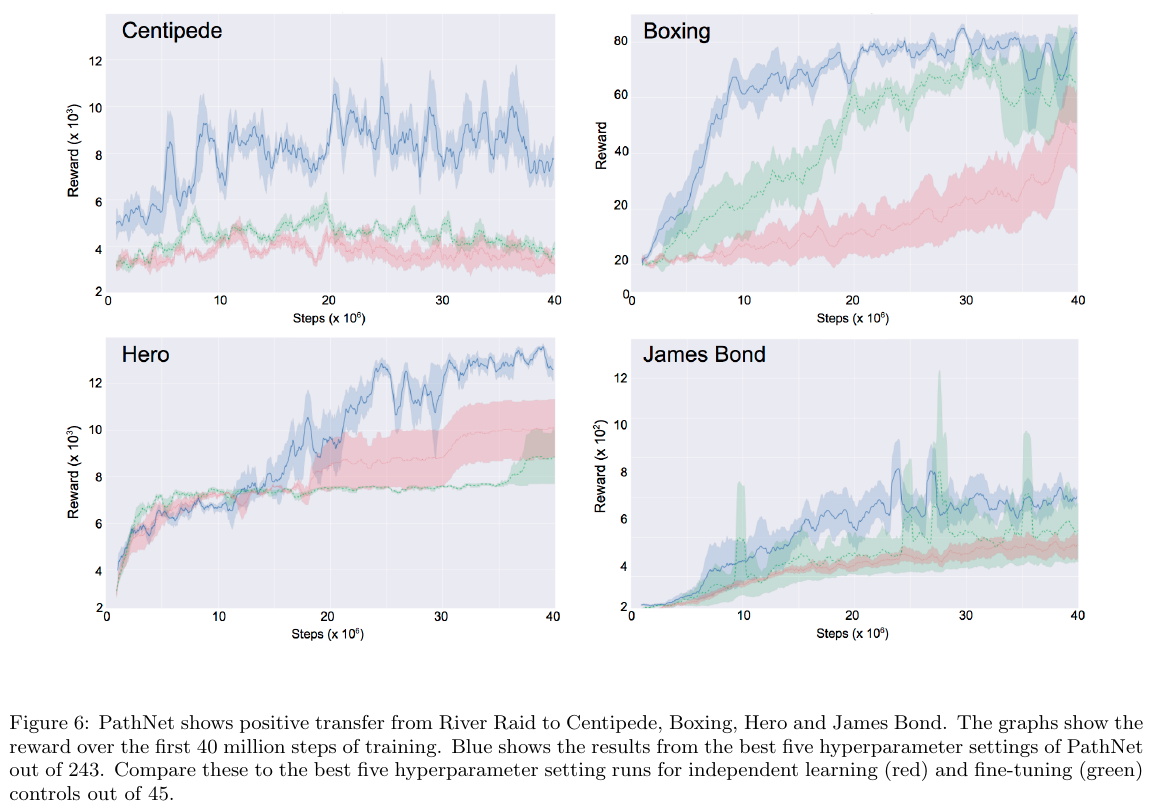
PathNet
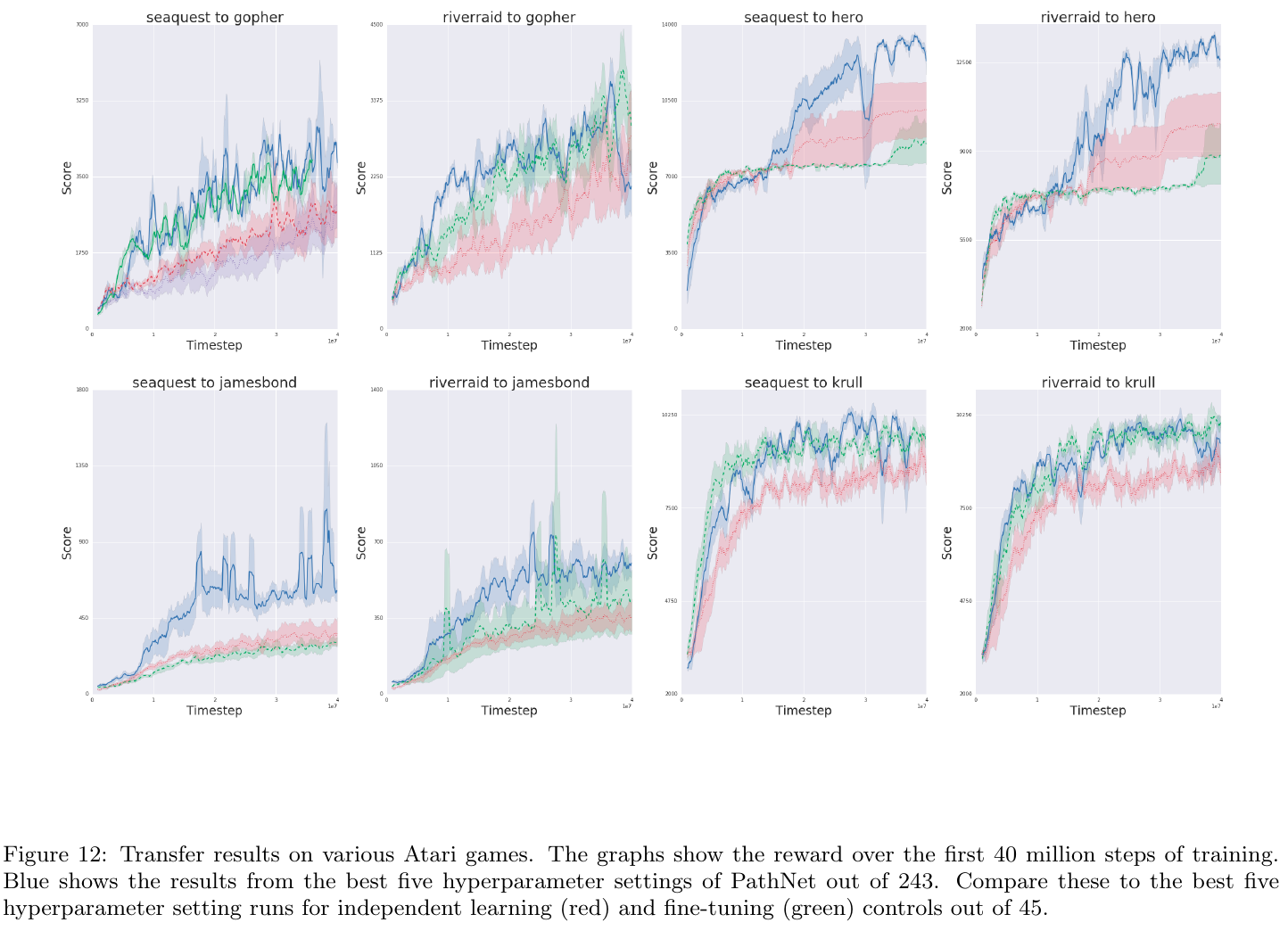
PathNet
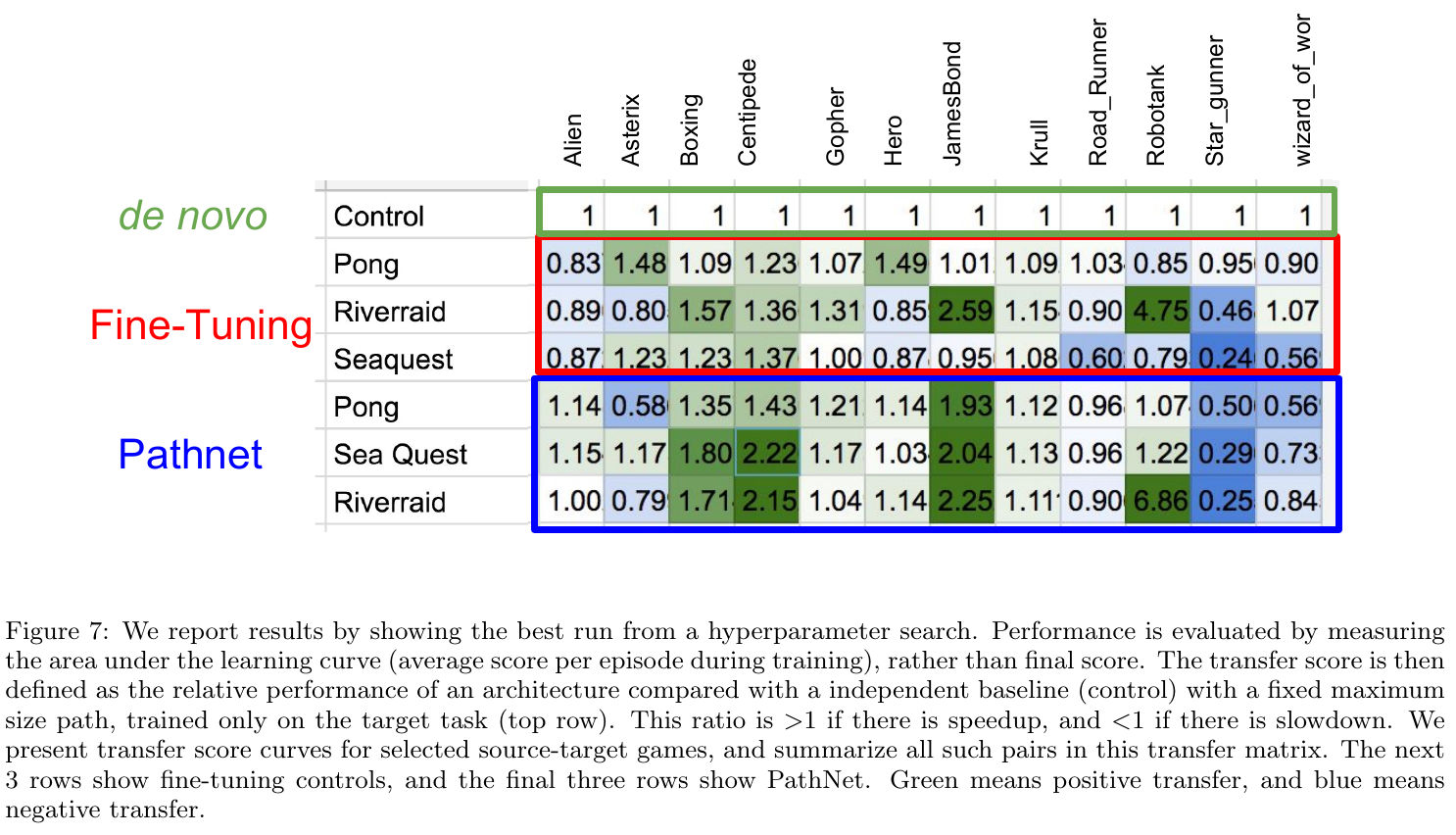
PathNet
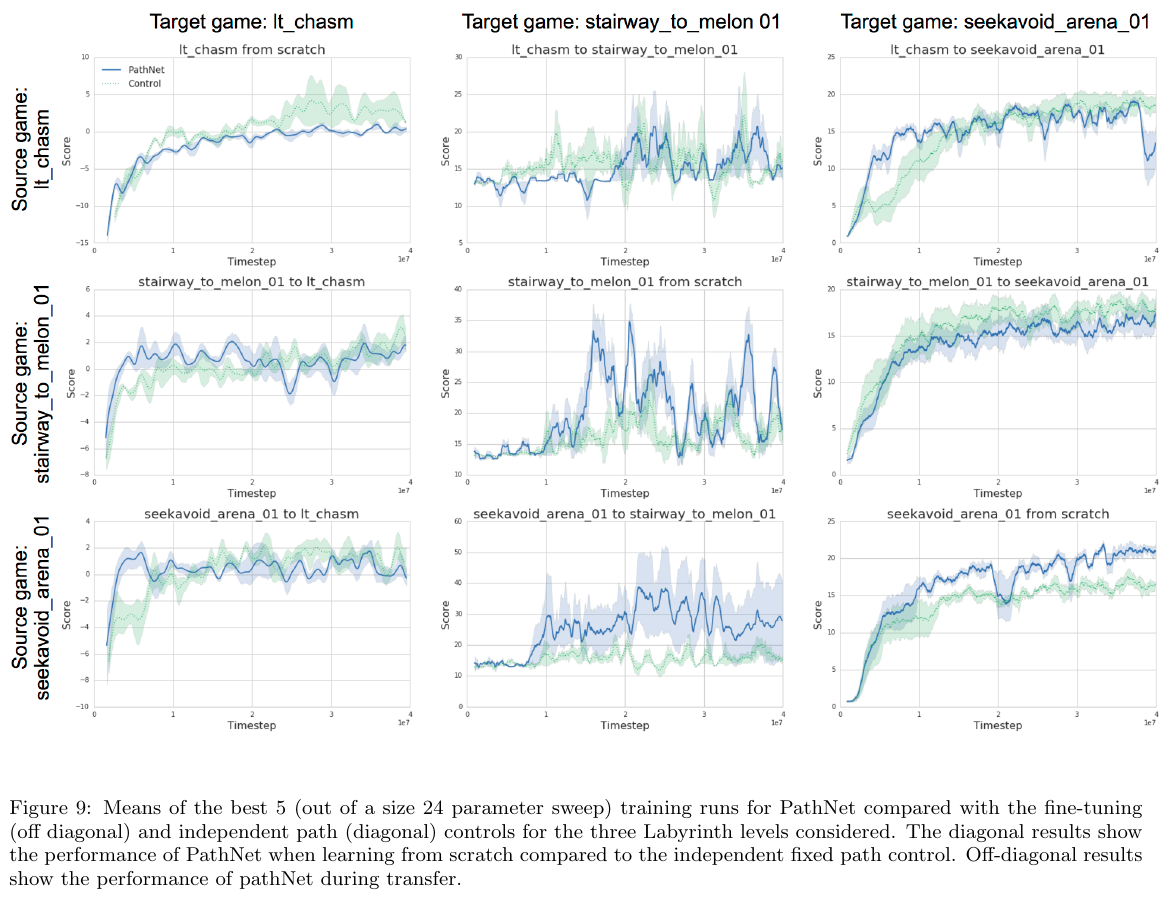
PathNet

Not covered
- All 57 Atari games with one network: https://arxiv.org/abs/1809.04474
- Policy distillation: https://t.me/adv_topics_in_rl_ru_2020/909
Thank you! Questions?
Transfer & Multi-Task: Advanced RL @ YSDA, Spring 2020
By dniku
