Brief introduction to Natural Language Processing
(NLP)
Nicolas Rochet
2022
AI
Linguistics
written language
spoken language
statistics
machine learning
NLP
Computer Science
deep learning
Definition
.... to "understand" the content of a corpus of documents
Field aiming at analyzing natural language by computer means
tweets
forum's
message
e-mails
articles
books
...
surveys
meetings
songs
speechs
recipies
conversations
Main applications
Text & speech processing
Natural Language Understanding
Lexical
semantics
Syntactic
analysis
Relational semantics
Discource
Natural Language Generation
Morphological analysis
Main applications
Natural Language Understanding
Natural Language Generation
Automatic Summarization
Dialogue management
Grammatical error correction
Machine translation
Question answering
Music generation
Text generation
Voice synthesis
Text & speech processing
Optical Character Recognition
Speech recognition
Speech segmentation
Text-to-speech
Speech-to-text
Word segmentation
Main applications
Morphological analysis
Lemmatization
Morphological segmentation
Part of speech tagging
stemming
Main applications
Syntatic
analysis
Grammar induction
Sentence parsing tree
Sentence breaking
Main applications
Lexical
semantics
Distributionnal semantics
Sentiment analysis
Named entity recognition
Terminology extraction
Word sense disambiguation
Entity linking
Main applications
Relational semantics
Relationship extraction
Semantic parsing
Main applications
Discourse
Coreference
resolution
Argument mining
Topic segmentation
Implicit semantic
role labelling
Topic segmentation
Recognizing textual entailment
Discourse analysis
Main applications
How to transform the corpus into numreical data?
Textual data
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus ac nunc tristique, maximus enim eget, sodales neque.
text 1
Aenean lobortis ornare diam, nec pellentesque odio viverra at.
text 2
Corpus
Numerical data
variables
X_1
X_2
X_3
...
...
observations
The bag-of-words representation
1. Segmenting the N-grams into tokens
2. Count the frequency of appearance of these tokens in each document
3. Apply optional normalization
Steps :
Transform a collection of documents into a table of
numerical data
(without requiring knowledge of the field studied)
Bag-of-words
Transform a collection of documents into a table of
numerical data
(without requiring knowledge of the field studied)
Result :
frequency vector of tokens
V_1
V_2
V_3
...
...
documents
Exemple de bag-of-words
1. Imaging databases can be huge
4 documents (Coelho & Richert, 2015)
2. Most imaging databases save images permanently
3. Imaging databases store images
4. Imaging databases store images. Imaging databases store images. Imaging databases store images
Counting the frequency of tokens (ngram = 1)
documents
| imaging | databases |
can |
get |
huge |
most | save |
images |
permanently |
store |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 |
|---|
| 2 |
| 3 |
| 4 |
Limitations
Some words are not intrinsically meaningful
removal of stop-words
documents
| imaging | databases |
can |
get |
huge |
most | save |
images |
permanently |
store |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 |
|---|
| 2 |
| 3 |
| 4 |
Some words have the same semantic content
stemming & lemmatization
Term Frequency -Inverse Document Frequency (TF-IDF)
The count does not take into account the total frequency of occurrence
Words and phrases context is not encoded !
Remarks about bag-of-words
Its dimensionality is
often very high
The bag-of-words data table is special:
It contains many zeros
might need to use dimensionality reduction methods after
use sparse-vector representation to save memory
Dedicated pre preocessigns
Deleting special characters
dictionary of common words
Deleting
stop-words
#$%&\'{}*+
...
the
your
is
...
Un prétraitement dédié
Stemming
keep the same morphological stem
playing, played, plays
play
Lemmatisation
keep the same semantic form
am, are, is
be
Vectorisation of tokens
Term Frequency
(TF)
Term Frequency -Inverse Document Frequency
(TF-IDF)
Creation of vectors of tokens capable of encoding the meaning contained in the documents
We count the frequency of appearance of the tokens
1-gram
2-gram
...
Tokens
We divide this frequency by the number of documents in which the token appears
databases
imaging databases
| imaging | databases |
... |
|---|---|---|
| 1 | 1 | |
| 1 | 1 | |
| 1 | 1 | |
| 1 | 1 |
documents
| 1 |
|---|
| 2 |
| 3 |
| 4 |
| imaging | databases |
... |
|---|---|---|
| 1/4 | 1/4 | |
| 1/4 | 1/4 | |
| 1/4 | 1/4 | |
| 1/4 | 1/4 |
documents
| 1 |
|---|
| 2 |
| 3 |
| 4 |
... beyond bag-of-words
Word embedding
The vectors are created by models taking into account,
for each token, the context of the other tokens
The semantic proximity between two words is captured by the distance between two encoded vectors this way
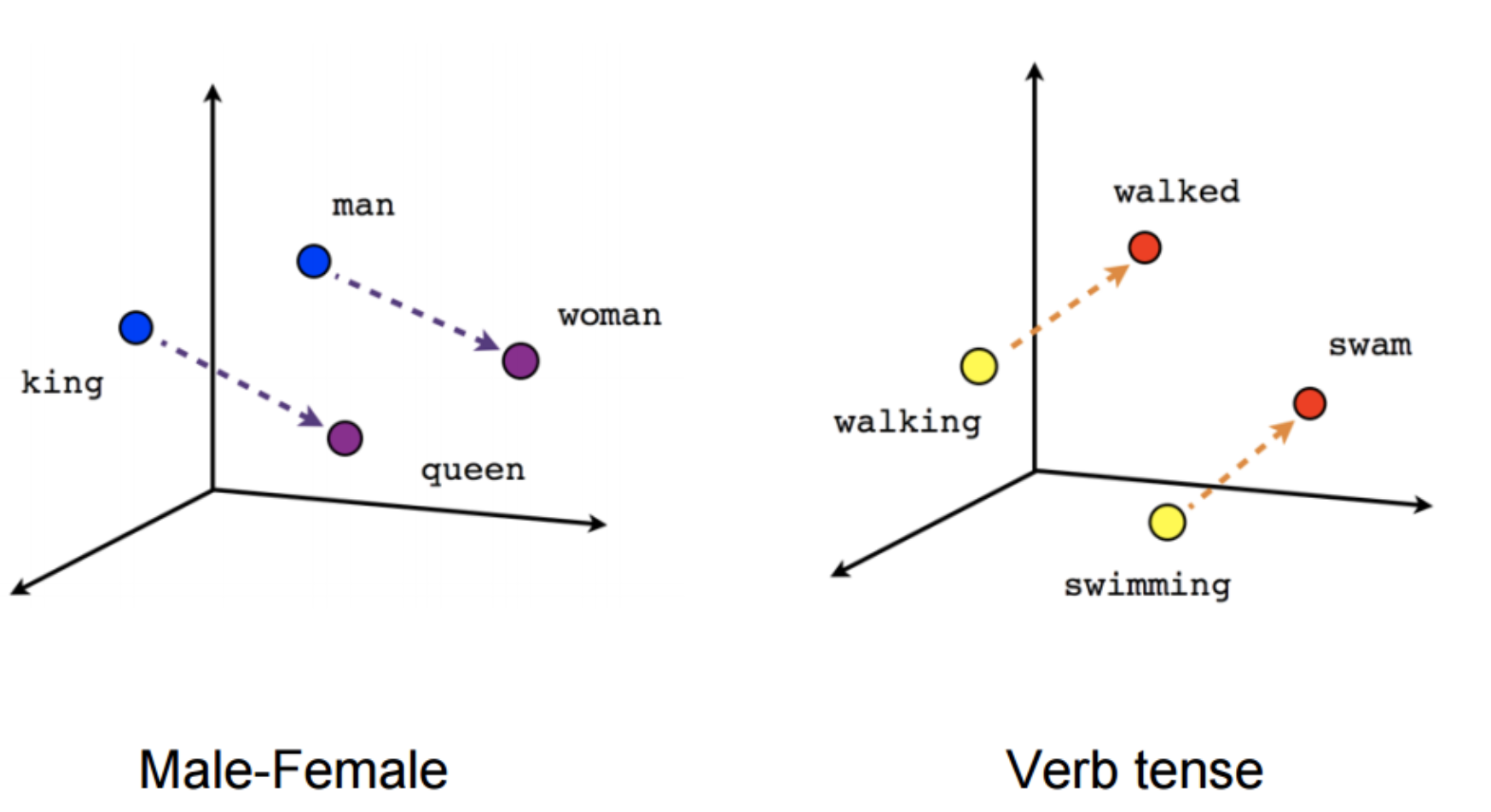
Output property
Brief intro to NLP
By Nicolas Rochet
Brief intro to NLP
Cours 2019 -2020



