Surviving System Design Interviews
Agenda
-
How System Design Interviews Work
-
What interviewers really evaluate
-
Core technical concepts
-
The 4-step framework
-
Communication tips
-
-
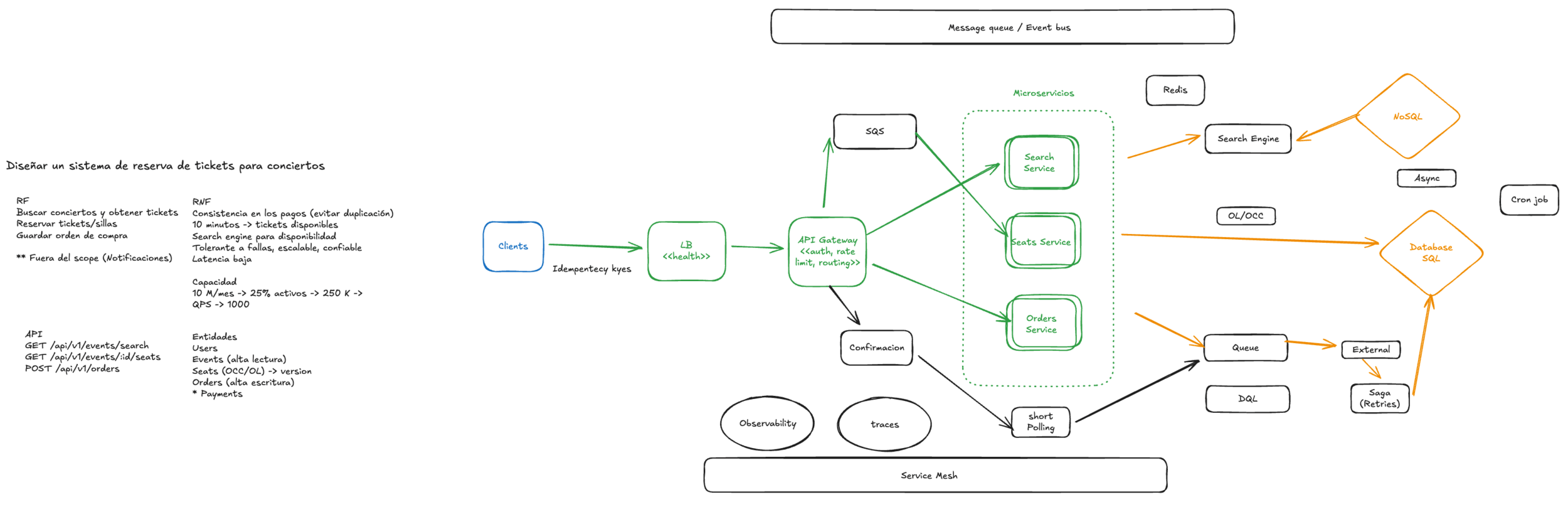
Ticketmaster: Concert booking/Flight booking system
How System Design Interviews Work

What You Must Demonstrate
- Requirements: scope, constraints, NFRs, edge cases
- Architecture: components + data flows + bottlenecks
- Data: models, indexes, consistency, transactions
- Scale: caching, sharding, async, capacity thinking
- Reliability: retries, idempotency, fallbacks, observability
What Interviewers Evaluate
| They Evaluate | They Look For |
|---|---|
| Problem-Solving | Structured thinking, clarifying questions |
| Technical Depth | Trade-offs, not just buzzwords |
| Communication | Clear explanations, diagrams |
| Trade-off Analysis | Pros and cons of decisions |
It's Not About the "Perfect" Solution
Core Concepts (Beginners)
REST API Basics
POST /bookings → Create
GET /bookings/:id → Read
PUT /bookings/:id → Update
DELETE /bookings/:id → Delete
Status Codes:
- 200 OK | 201 Created | 400 Bad Request | 404 Not Found | 500 Internal Server Error
Caching
Why Cache?
- Reduce database load
- Faster responses
- Handle traffic spikes
Where?
- Redis/Memcached (most common)
- CDN (static files)
- Application memory
Load Balancing
┌─────────────┐
│Load Balancer│
└──────┬──────┘
┌─────────┼─────────┐
▼ ▼ ▼
┌───────┐ ┌───────┐ ┌───────┐
│Server1│ │Server2│ │Server3│
└───────┘ └───────┘ └───────┘
Strategies:
- Round Robin - Equal distribution
- Least Connections - To least busy
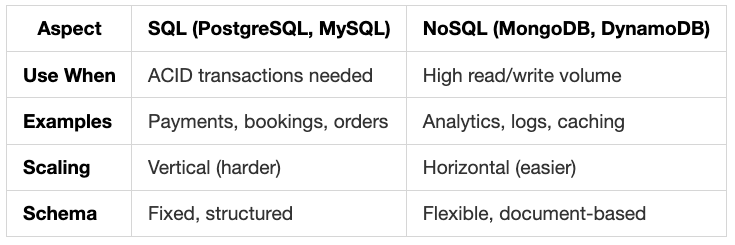
Databases: SQL vs NoSQL
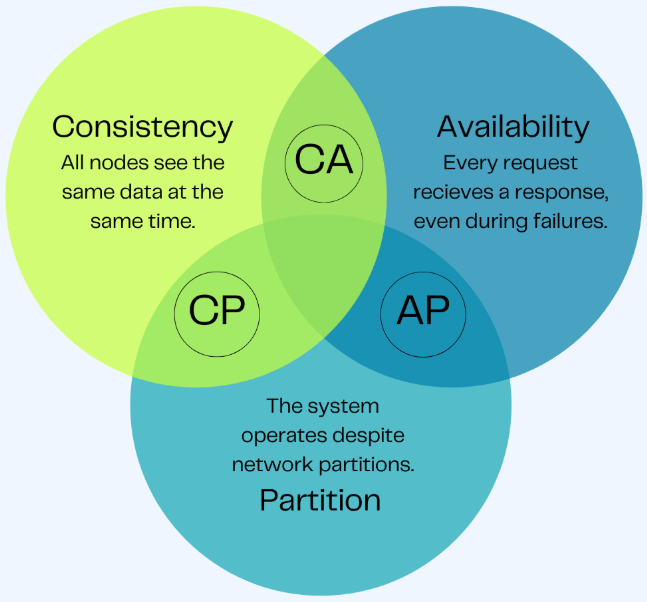
CAP Theorem
In distributed systems, choose two of three: Consistency, Availability, Partition Tolerance.
Advanced Concepts (Experts)
CAP Theorem
Interview Quote: "For payments, I choose CP (PostgreSQL) - better an error than a duplicate charge. For the activity feed, AP (Cassandra) is fine - users tolerate stale data."
| Choice | Prioritizes | Best For | Examples |
|---|---|---|---|
| CP | Consistency | Payments, bookings | PostgreSQL, MongoDB |
| AP | Availability | Feeds, caching | Cassandra, DynamoDB |
Since network partitions are unavoidable, the real choice is:
Concurrency
| Technique | Use When | Example |
|---|---|---|
| Idempotency Keys | Retries possible | Payments |
| Optimistic Locking | Low contention | Seat booking |
| Pessimistic Locking | High contention | Inventory |
Code Example:
UPDATE seats SET status = 'booked', version = version + 1
WHERE seat_id = 123 AND version = 5;
Partitioning - Single Database
- Horizontal: Split rows across tables (e.g., orders_2023, orders_2024)
- Vertical: Split columns (e.g., user_profile vs user_settings)
Trade-off: "Sharding adds complexity but unlocks write scalability beyond replicas."
Sharding - Multiple Databases
- User-based: Users 1-1M → Shard 1, Users 1M-2M → Shard 2
- Region-based: US users → US datacenter, EU users → EU datacenter
Trade-off: "Sharding adds complexity but unlocks write scalability beyond replicas."
Sharding & Partitioning
| Partitioning | Sharding |
|---|---|
| Same database | Different databases |
| Simpler queries | Complex cross-shard queries |
| Limited scale | Massive scale |
CQRS (Command Query Responsibility Segregation)
┌─────────────┐ ┌─────────────────┐
│ WRITES │────▶│ Write Database │
│ (Commands) │ │ (PostgreSQL) │
└─────────────┘ └────────┬────────┘
│ Sync
┌─────────────┐ ┌────────▼────────┐
│ READS │◀────│ Read Database │
│ (Queries) │ │ (Elasticsearch)│
└─────────────┘ └─────────────────┘Use When: Read patterns differ significantly from write patterns.
Event Sourcing
Store events, not state:
Event 1: SeatReserved { seat_id: 123, user_id: 456 }
Event 2: PaymentProcessed { booking_id: 789 }
Event 3: BookingConfirmed { booking_id: 789 }
- Complete audit trail (compliance, debugging)
- Can replay to any point in time
- Natural fit for distributed systems
Interview Tip: "For audit requirements, I would use event sourcing."
Service Mesh
Infrastructure layer for microservices:
| Feature | Benefit |
|---|---|
| mTLS | Secure service-to-service communication |
| Retries/Timeouts | Automatic resilience |
| Observability | Distributed tracing, metrics |
| Traffic control | Canary deployments, A/B testing |
Interview Tip: "For microservices communication, a service mesh handles cross-cutting concerns."
Resilience
Circuit Breaker:
- CLOSED → requests pass
- OPEN → requests fail fast
- HALF-OPEN → test recovery
Dead Letter Queue:
- Failed messages → separate queue
- Manual review or retry later
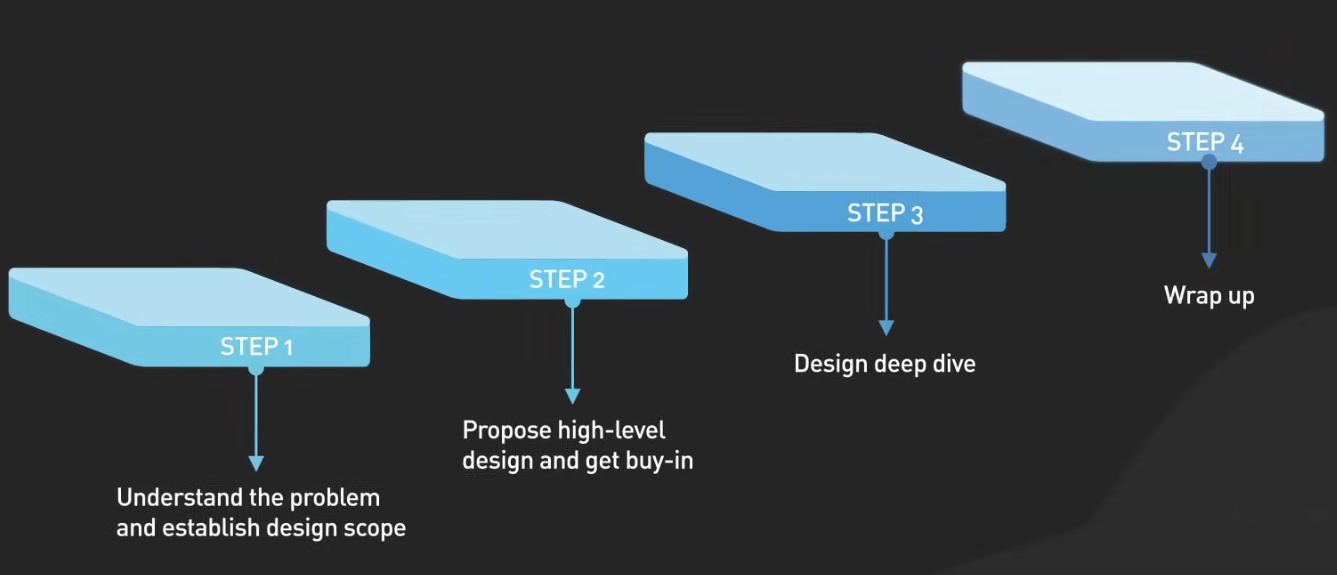
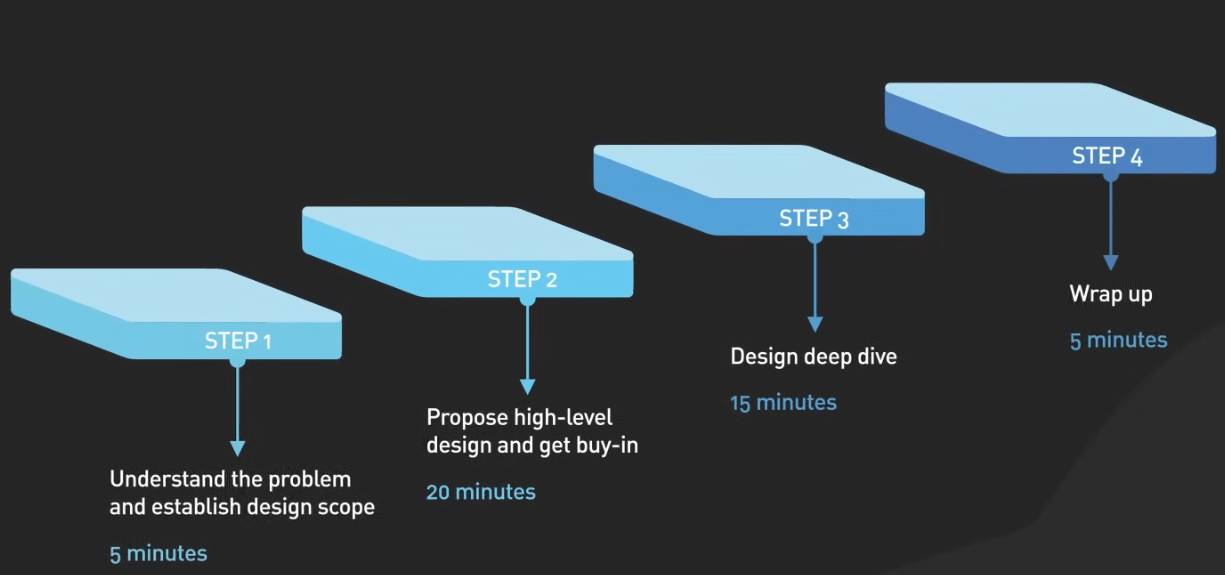
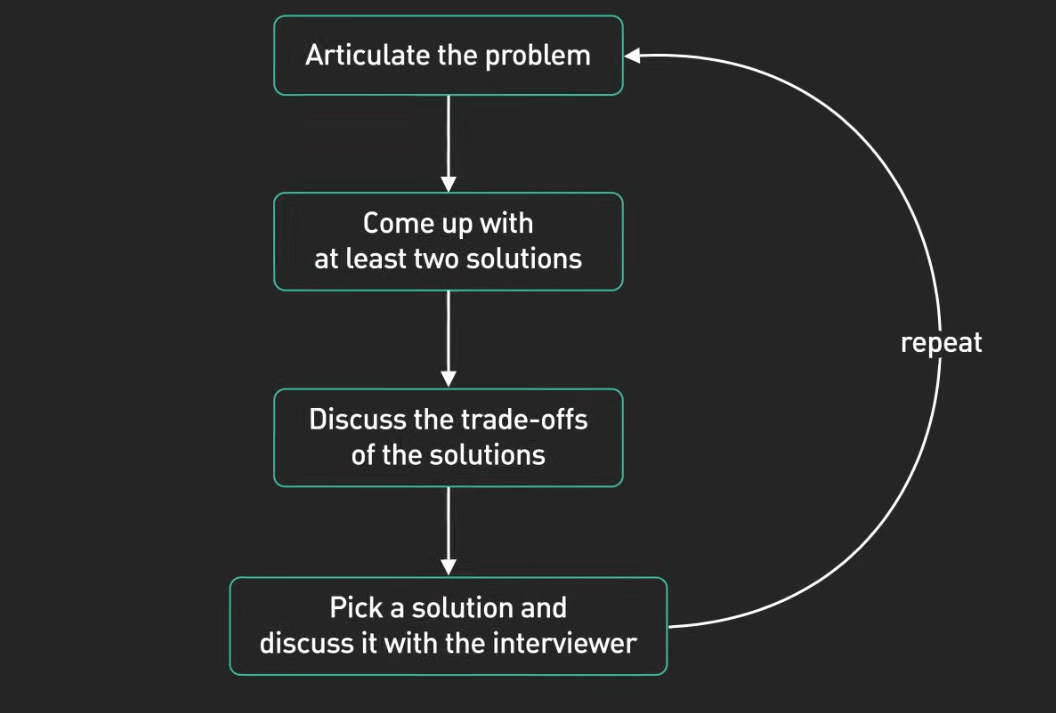
The Interview Framework
1. Requirements 2. High-Level 3. Deep Dive 4. Scale
(5 min) (10 min) (15-20 min) (10 min)
│ │ │ │
▼ ▼ ▼ ▼
Clarify Big Picture Database Bottlenecks
Constraints Diagram API 1M+ users
Step 1 - Clarify Requirements
Functional: What should it do?
- "Can users search by location?"
- "Do we need a seat map?"
Non-Functional: How well?
- "How many users? 1K? 1M?"
- "What latency is acceptable?"
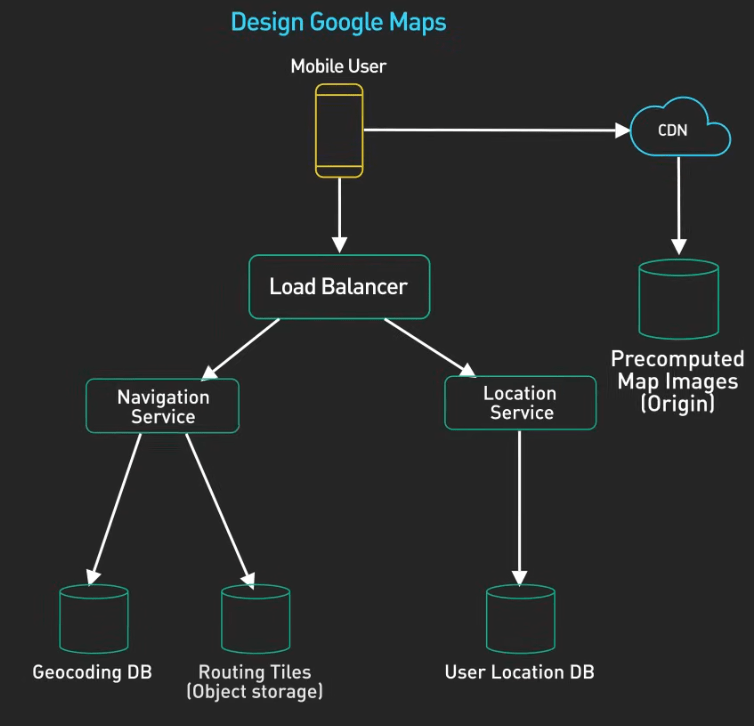
Step 2 - High-Level Design
Content:
User → Load Balancer → API Gateway → Services → Database
│
Cache
Include:
- Client/User
- Load Balancer
- API Gateway
- Core Services
- Database + Cache
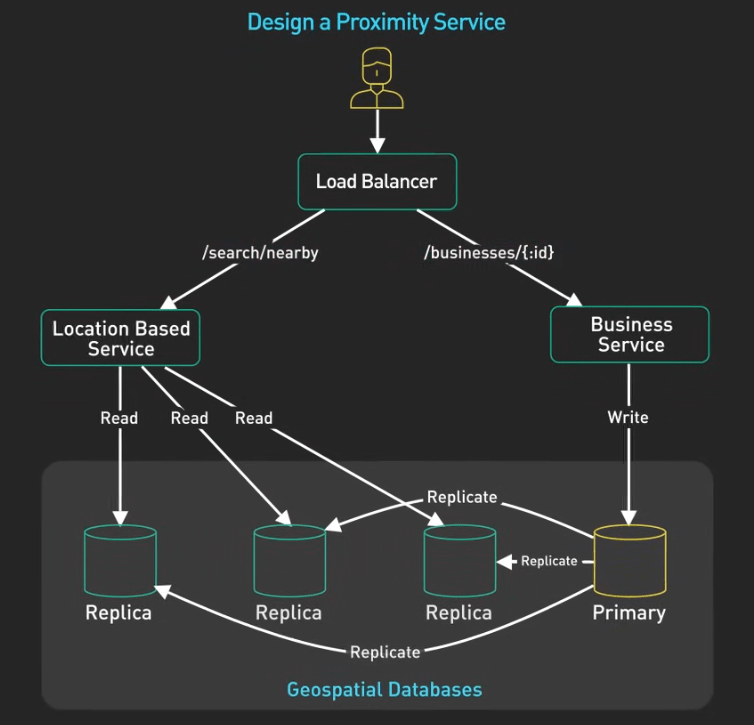
Step 3 - Deep Dive
Database Design
- Schema, indexes, replication
API Design
- Key endpoints, error handling
Critical Path
- The most important user journey
- "What happens when user clicks Book?"
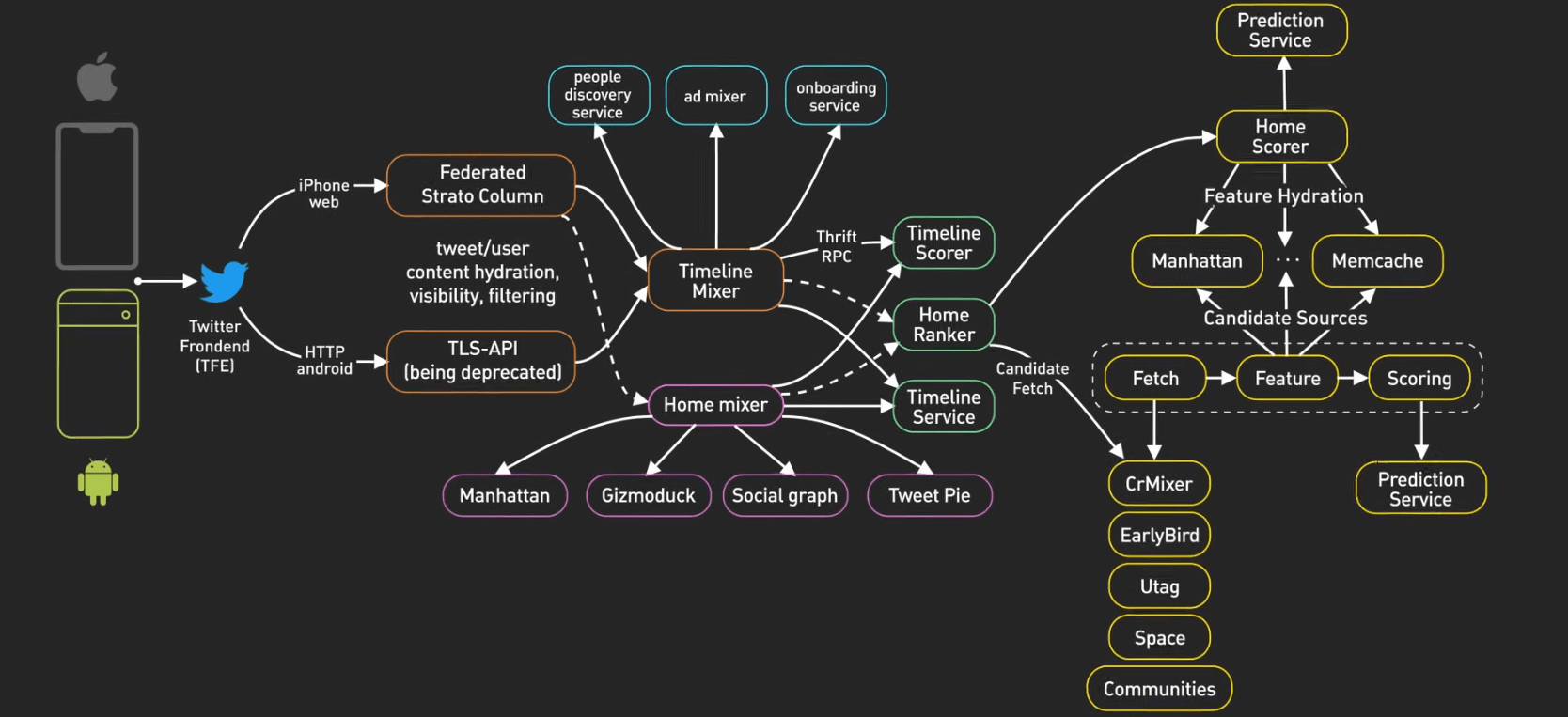
Step 4 - Scale and Bottlenecks
Identify Bottlenecks:
- "What if 1M users hit ticket drop?"
- "How to prevent overselling?"
Strategies:
- Horizontal scaling
- Read replicas
- Caching layers
- Queue-based processing
- Sharding
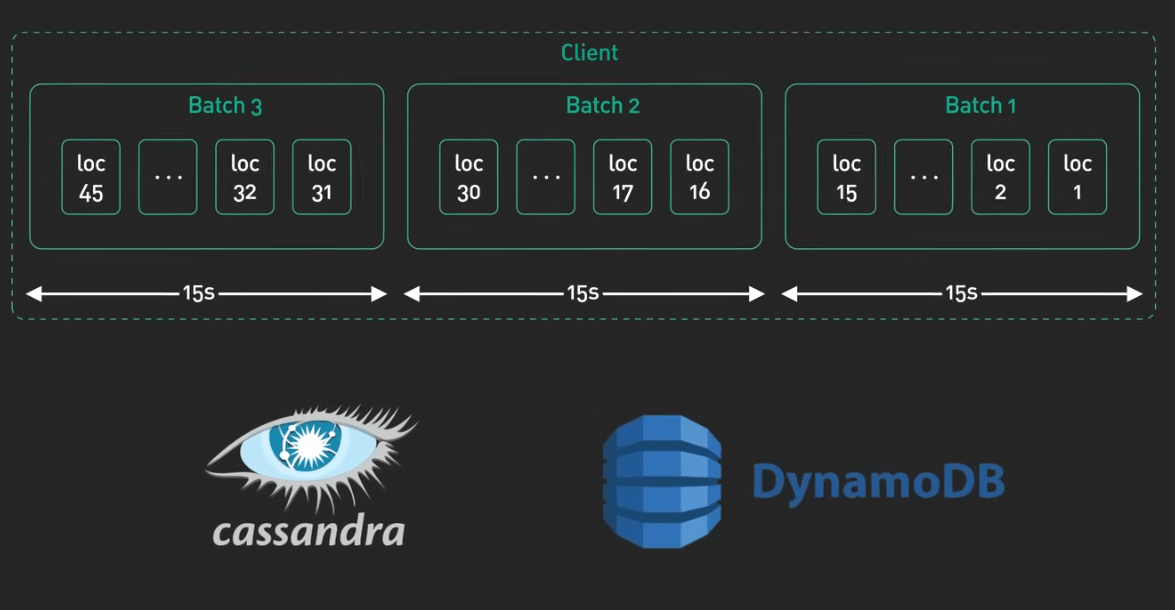
Communication Tips
✅ Do:
- Lead with overview, then zoom in
- Think aloud - share reasoning
- Acknowledge trade-offs
- Use simple left-to-right diagrams
❌ Don't:
- Jump to database schema first
- Stay silent while thinking
- Ignore interviewer hints
- Draw complex nested diagrams
Surviving System Design Interviews
By Andrés Santos




