Survey Report
Working with Open Data
Click on the right arrow to continue
In June 2019 I distributed a survey to companies that develop applications from open data in the European Union.
I found these companies on the EU Open Data Portal, European Data Portal, Open Data Incubator Europe (ODINE) and EU Datathon websites.
The survey’s goal was to understand more about their process and the issues they face.
Out of the 180 companies contacted, 36 completed the survey. This is what I found.
The majority of companies didn't receive external funding
Question: Have you received any funding for your project? If yes, who funded you?
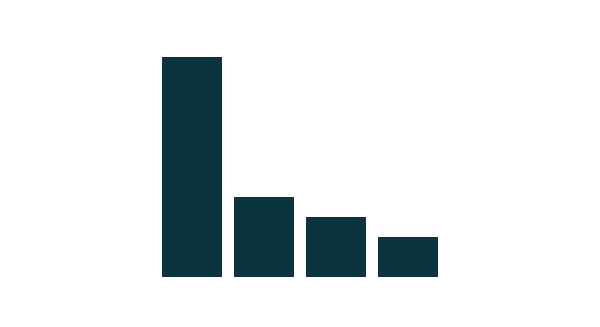
No
Funding
Private
Funding
European
Authorities
National
Authorities
22
8
6
4
Many different types of applications were developed
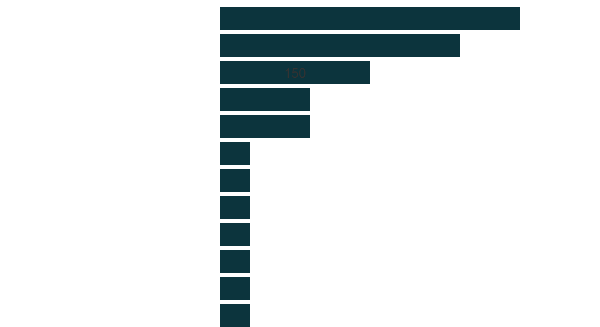
Political Activity / Public Administration Transparency
Business Opportunities, Economics and Finance
Environment and Climate Change
Data Services / API
Legal
Consumer Product Safety
Data Storytelling
Food Consumption
Internet of Things Search Engines
Language
Pharmaceutical
Web Archive
10
8
5
3
3
1
1
1
1
1
1
1
Click on the down arrow to see how companies found the data
Google is used a lot when searching for data
18 of the 36 companies surveyed already knew where to find all the data they needed. 13 out of the remaining 18 companies used Google to search for data.
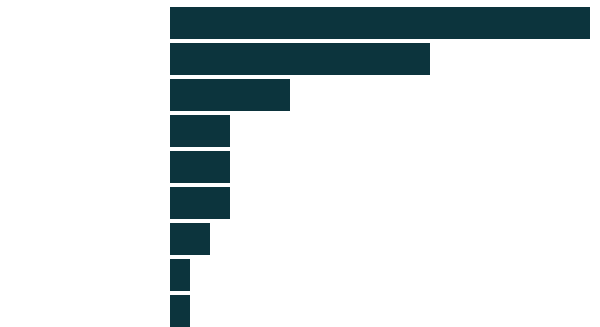
Existing Knowledge
Google Search
EU Open Data Portal
Asked Stakeholders, Experts, PA
European Data Portal
National Public Data Portals
EU Datathon Workshops
Ecosia Search
Academic Survey
21
13
6
Question: Did you know how to find the data? How did you find it?
3
3
3
2
1
1
Many different data sources were used
Click on the down arrow to see the data sources
More than 50 different data sources were mentioned by the 36 companies surveyed.
The majority of the companies used at least two data sources for their application.
National / Regional Open Data Sources [mentioned 11 times], Eurostat [7], European Central Bank [5], EUR-Lex [4], European Commission [3], European Environment Agency [3], European Parliament [3], TED [3], Transparency Register [3], Copernicus [2], CORDIS [2], EMODnet [2], Organisation for Economic Co-operation and Development [2], The World Bank [2], Wikidata [2], Alpha Vantage, CEPII, CRED EM-DAT (Emergency Events Database), Court of Justice of the EU, DGT - Translation Memory, European Chemicals Agency, European Medicines Agency, European Food Safety Authority, European Investment Bank, European Systemic Risk Board, Financial Transparency System, IATI Registry, Integrated Climate Data Center, NASA, National Oceanic and Atmospheric Administration, Our World in Data, Publications Office of the EU, Twitter, UN Comtrade, US Government, World Health Organization
Opinions about the difficulty of finding data varied...
Question: How difficult / easy was it to find the data you were looking for?
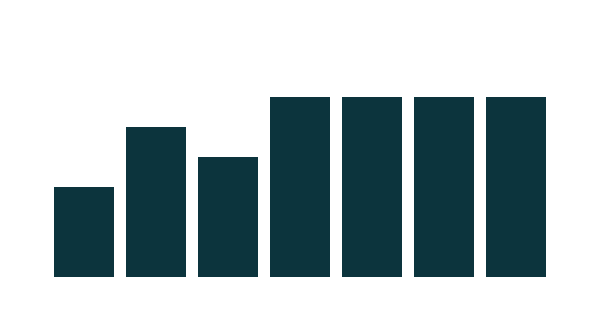
Difficult
Somewhat
Difficult
Very
Difficult
Average
Somewhat
Easy
Easy
Very
Easy
3
5
4
6
6
6
6
... and so did opinions about the quality of data
Question: How would you rate the quality of the data you found?
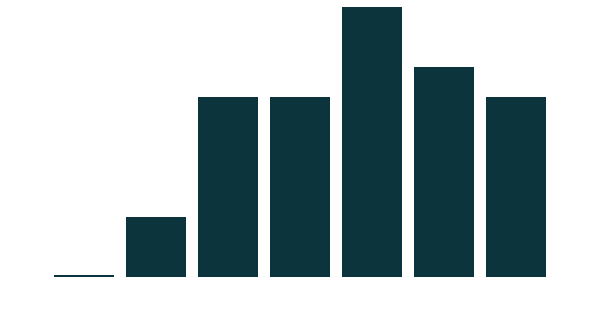
Bad
Somewhat
Bad
Very
Bad
Average
Somewhat
Good
Good
Very
Good
0
2
6
7
6
6
9
A large amount of work went into data preparation
Full processing pipeline, AI systems for data unification, Data discovery systems, Data cleaning, Data transformation, Data extrapolation, Data normalisation, Website data collection, Document transformation program, Machine-learning-processing, Editor for files and link sources, ETL data process, Data refresh, Data gathering and process, Text corpus processing, Missing data identification, Data review, Data extraction from XML, PDF parser to "read" documents and collect data in machine-readable format, Data manipulation, Data retrieval, Data analysis, Language detection, Data augmentation, Data access, Semantic descriptor linking, Streamlining of data input from multiple sources, Duplicate data removal, Data parsing, Raw data to RDF translation, Knowledge graph store, Data scraping, Data structuring, Data indexing, Data validation, Data conversion, Fuzzy string matching
This "word cloud" summarises the activities mentioned by the respondents
Difficulties were encountered when dealing with data
Unstructured data to be turned into structured data, Different kinds of data to be joined, Inconsistent data, Incomplete data, Errors in the data, Data to be turned into relevant metrics, Poorly standardised data, Reliability over time, Consistency of updates rate, Data standards and conventions changing over time, No commonality, Data to be related with geospatial structures, Fragmented data, Very different structures in each data source, Large amounts of data, Lack of metadata, Confusing metadata, No (or weak) response from data providers when suggesting improvements, Difficult to find the right (type of) data in the crammed EU Open Data Portal and other EU portals, Lack of documentation, Lack of recent data, Difficulty in combining different data sources due to inconsistencies / different granularity / different time periods covered, Difficult access to data due to lack of open data formats, Expert-level knowledge required to understand what data is available, Data to be parsed due to different standards used by data providers, Aggregating different levels of granularity, Conversion between wide and long format, Dealing with APIs, Open text fields with unstructured information, Discrepancies in data, Dealing with many different formats / protocols, Finding the data, Public Authorities not providing data although legally required to, Need of data not available with an open license
Python is king
Companies used a vast array of technologies to develop their applications, with Python being the most common.
Python [mentioned 18 times], R [8], d3.js [4], Node.js [4], PHP [4], PostgreSQL [4], Vue.js [4], Flask (Python) [3], Leaflet [3], MySQL [3], Shiny (R) [3], AngularJS [2], C [2], C# [2], C++ [2], Elasticsearch [2], ggplot2 [2], Go (Golang) [2], Java [2], MongoDB [2], NLTK (Python) [2], pandaSDMX (Python) [2], Scikit-learn (Python) [2], .NET, Amazon Aurora, Amazon Cognito, Apache Commons, AWS Lambda, Bash, Beautiful Soup (Python), CakePHP, Crossfilter (JS), Crypto (Node.js), data.table (R), dc.js, DigitalOcean, Django (Python), dplyr (R), Drupal, FNA Platform, Google Cloud Services, GraphQL, Heritrix, Hugo, JSON Hyper-Schema, Luigi (Python), lxml (Python), MariaDB, Microsoft SQL Server, Mono, Motu Client, Neo4j, NoSQL Database, NumPy (Python), OpenStreetMap, package countrycode (R), package haven (R), pdf2html, PostGIS, PostgreSQL, Power BI, QGIS, React, React Native, Redis, RocksDB, Ruby on Rails, Spring Framework, Spyder (Python), SQLite, SSDB, Tableau, Tesseract OCR, Windows Server, XGBoost
Many companies don't promote their work
Question: What are you currently doing (or have done) to promote your project to end users?
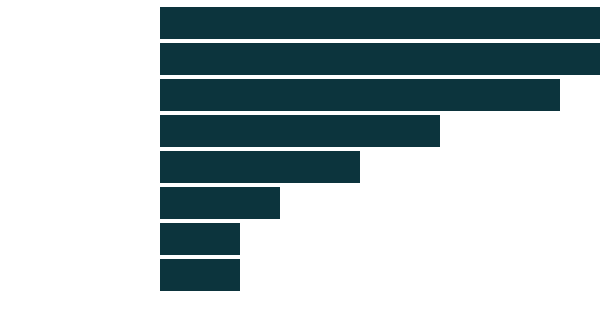
Networking / Contacting Stakeholders / Events
Nothing / Minimal Activity
Social Media
SEO
Traditional Media
Google Ads / PPC
Blog Posts
Not much, this is only an experiment
11
11
10
7
5
3
2
2
The number of end users is low for several companies
Note: these are the answers received from 16 companies. The other 20 companies surveyed either didn't know or didn't have data yet.
Question: How many end users interact with your project every month on average?
100 - 200 - 300 - 500 - 600 - 1,500 - 2,000 - 3,000 - 4,000 - 8,000 - 10,000 - 15,000 - 20,000 - 300,000 - 700,000 - 1,000,000
To conclude...
Quality and reliability of the data / Need to structure the data [mentioned 7 times], Understanding the market / Customer needs and behaviors [5], Lack of funding / Only spare time dedicated to the project [4], Deadlines [3], Large volume of data [3], Project's scope definition [2], Expertise in web design needed to be built from scratch, Building the ETL process, Clueless management, Creating an open source community, Data visualisation, Developing the database, Dispersed team, Interacting with APIs, Interpreting the data, Managing different languages, Marketing, Project maintenance, Reliability of PDF parsers, Resistance to public use of the data, Setting a mapserver's WCS supporting time dimension, Visual design and front-end
Question: What were the main difficulties / pain points you encountered when developing your project (technical issues, management issues, etc.)?
Understanding the processes and issues faced by companies working with open data is the start of the journey. Identifying what can be done to help them is the next step.
Do you have any suggestions?
What's next?
Please get in touch
hello@dvkwc.org
Working with Open Data
By dvkwc

