AstroCLIP
Cross-Modal Pre-Training for Astronomical Foundation Models

Francois Lanusse
Simons Foundation/CNRS
work in collaboration with Liam Parker, Siavash Golkar, Miles Cranmer
The Data Diversity Challenge
- Success of recent foundation models is driven by large corpora of uniform data (e.g LAION 5B).
- Scientific data comes with many additional challenges:
- Metadata matters
- Wide variety of measurements/observations

Credit: Melchior et al. 2021


Credit:DESI collaboration/DESI Legacy Imaging Surveys/LBNL/DOE & KPNO/CTIO/NOIRLab/NSF/AURA/unWISE
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
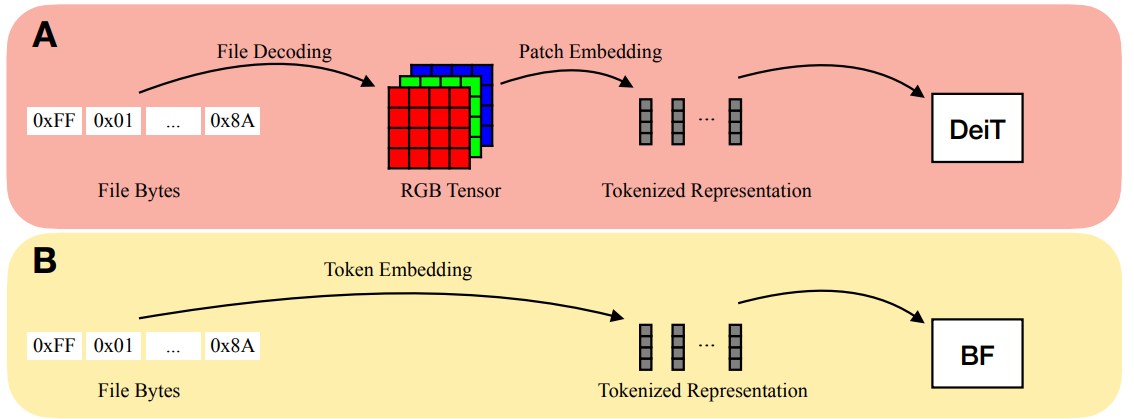
Bytes Are All You Need (Horton et al. 2023)
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
Bytes Are All You Need (Horton et al. 2023)
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
Bytes Are All You Need (Horton et al. 2023)
AstroCLIP
What is CLIP?
Contrastive Language Image Pretraining (CLIP)
(Radford et al. 2021)
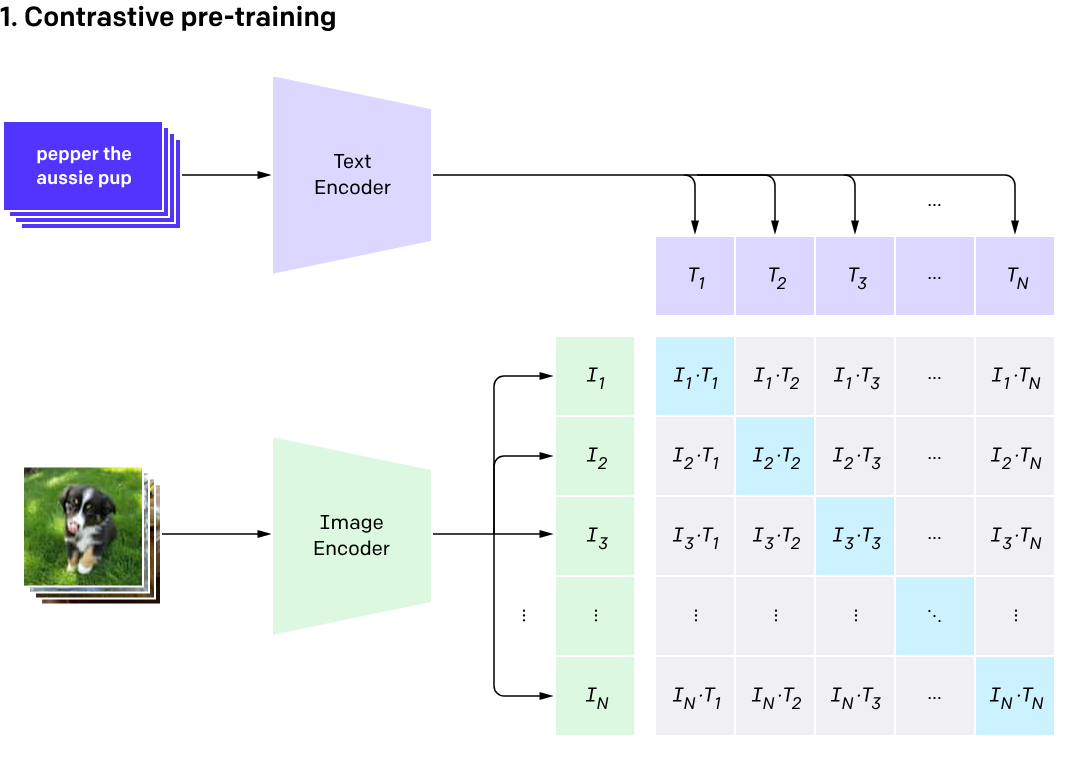
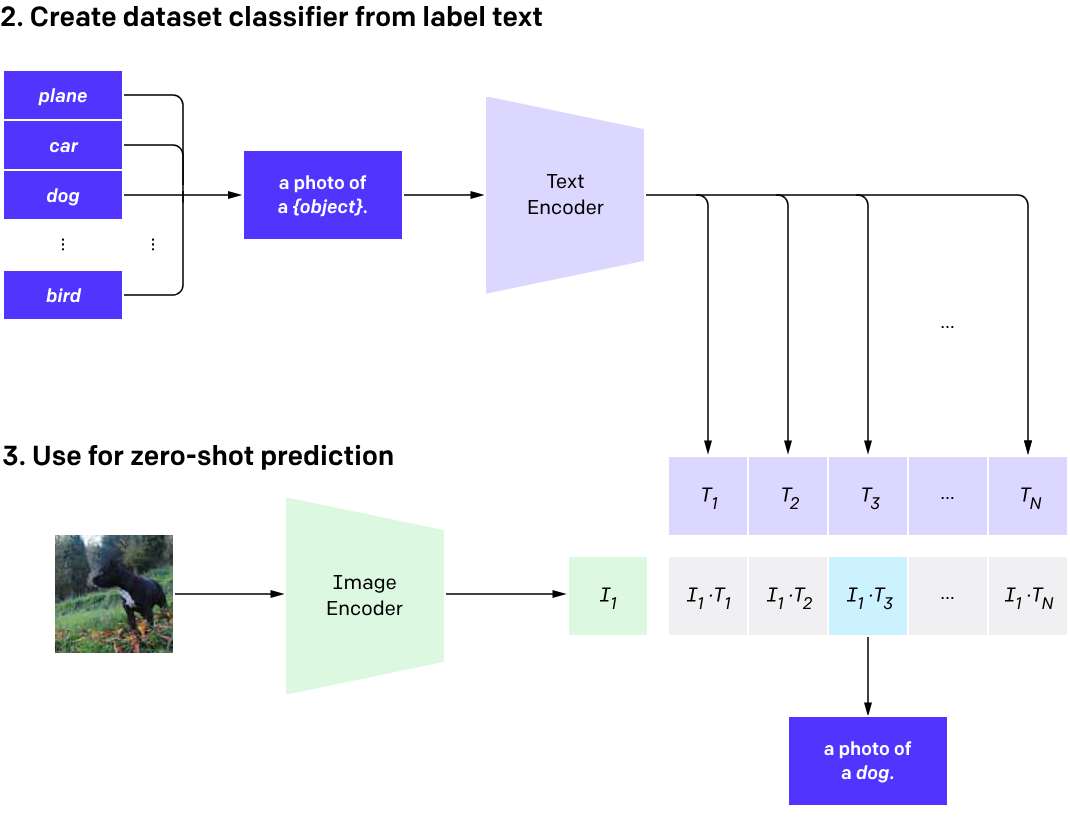
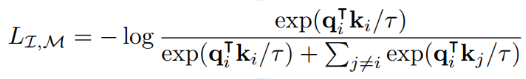
One model, many downstream applications!
Flamingo: a Visual Language Model for Few-Shot Learning (Alayrac et al. 2022)


Hierarchical Text-Conditional Image Generation with CLIP Latents (Ramesh et al. 2022)
What can this do
for us?
- Strategy to build general purpose "Foundation Models" (i.e. models not particularly built for a specific application, but that can serve as powerful baseline for downstream applications)
Deep Representation Learning In Astrophysics
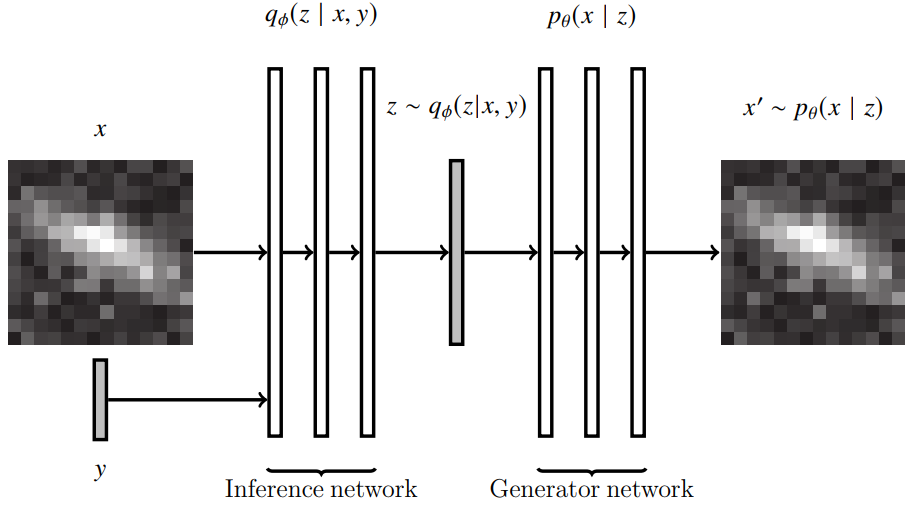
Most works so far have relied on (Variational) Auto-Encoders

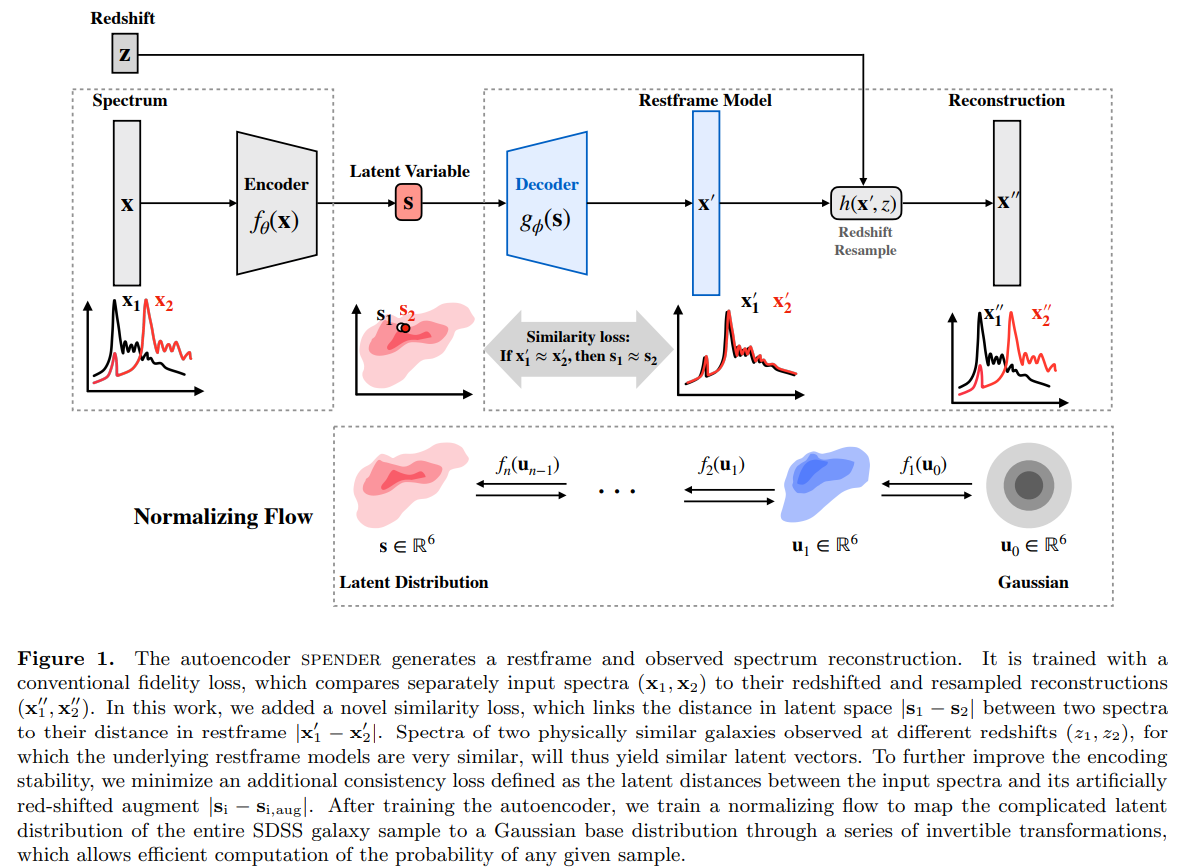
Autoencoding Galaxy Spectra II: Redshift Invariance and Outlier Detection (Liang et al. 2023)
A few comments on this approach
- Building an informative latent space relies on introducing an arbitrary information bottleneck:
- Too big, no structure emerges
- Too small, information is lost
- There is no constraint that the latent space should be well behaved
- Many ad-hoc schemes exist such as beta-VAE to force disentanglement
- Many ad-hoc schemes exist such as beta-VAE to force disentanglement
- More philosophically, this is a generative modeling approach
- We don't necessarily need to reconstruct a full observation to extract useful information about it.
Contrastive Self-Supervised Learning

Self-Supervised similarity search for large scientific datasets (Stein et al. 2021)
Example of Science Application: Identifying Galaxy Tidal Features

The AstroCLIP approach
- We use spectra and multi-band images as our two different views for the same underlying object.
- DESI Legacy Surveys (g,r,z) images, and DESI EDR galaxy spectra.
- Once trained, we can do example retrieval by nearest neighbor search.
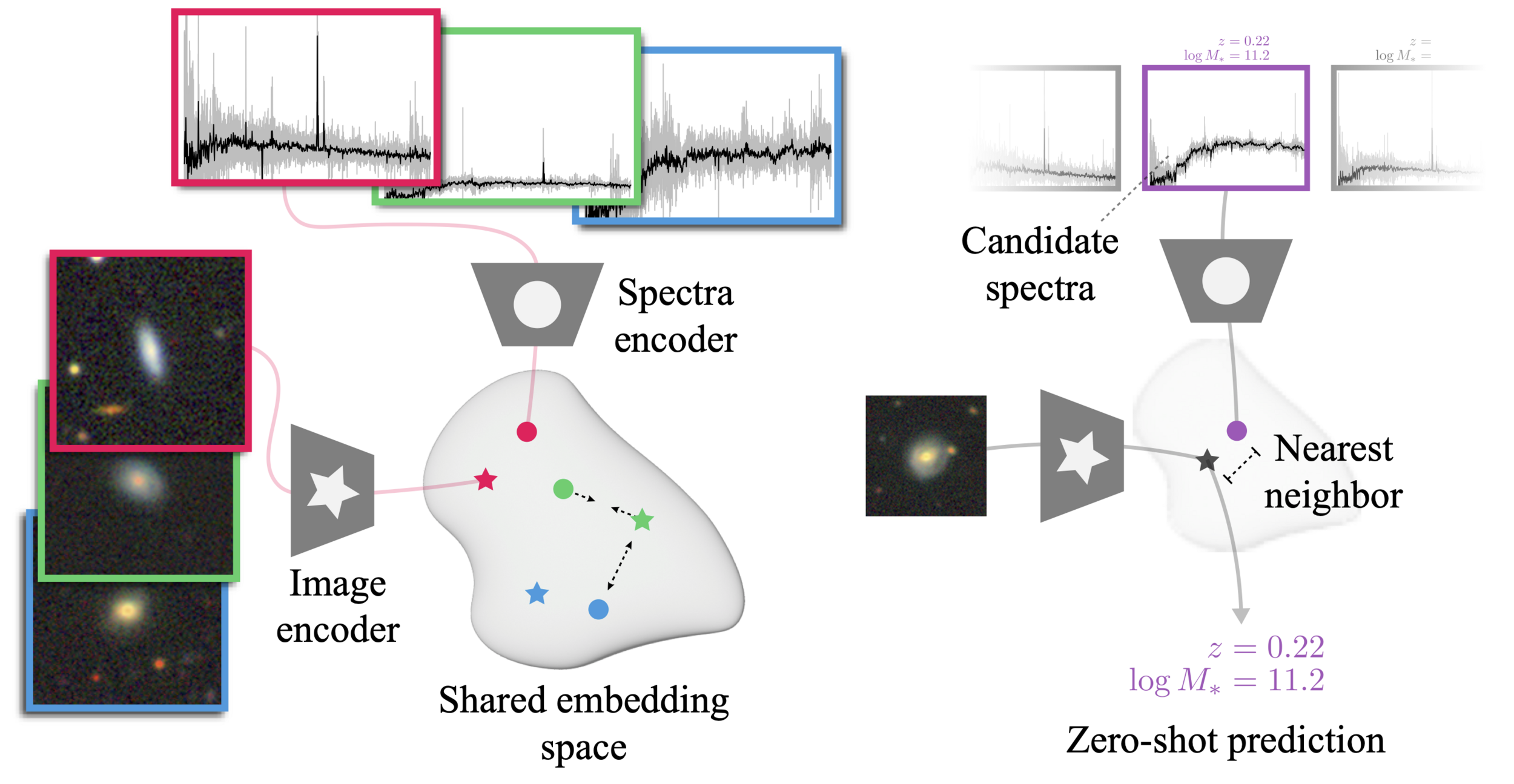


The Information Point of View
- The InfoNCE loss is a lower bound on the Mutual Information between modalities
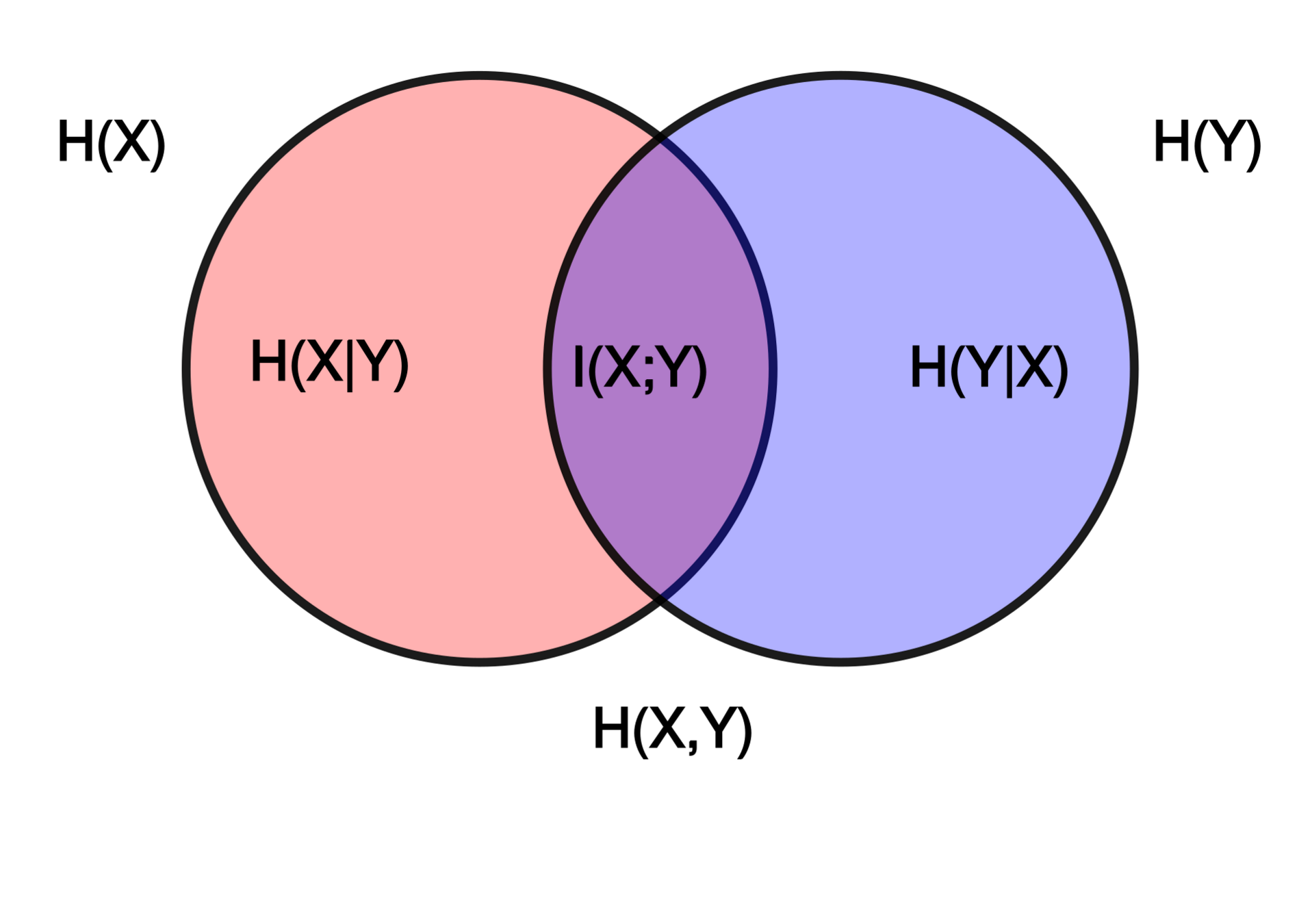
Shared physical information about galaxies between images and spectra
Visualizing properties of this embedding space

More examples of retrieval


Image Similarity
Spectral Similarity

Image-Spectral Similarity
Testing Structure of Embedding Space by k-NN Regression






Comparison to image-only SSL (from Stein et al. 2021)


How it works
We take a two steps approach:
- Build self-supervised model separately for images and spectra
- Images: Start from pre-trained ResNet 50 from Stein et al. (2021)
- Spectra: Pretrain by mask modeling a GPT-2 like transformer on spectra
- Train an embedding module on top of each backbone under InfoNCE loss
- Images: Simple MLP
- Spectra: Cross-attention module

What comes next!
- Idea of finding a common shared representation diverse observational modalities
- Next steps would be, embedded data from different instruments, different filters, etc... to build a universal embedding for types of galaxy observations
- Next steps would be, embedded data from different instruments, different filters, etc... to build a universal embedding for types of galaxy observations
- These pretrained models will act as strong off-the-shelf model for many downstream tasks:
- Never need to train your own CNN anymore
AstroCLIP
By eiffl




