Multimodal Pretraining for Scientific Data
Towards Large Data Models for Astrophysics

Francois Lanusse

Not what I'm going to talk about...



Accepted at NeurIPS 2024 🎉




- 1000 images each night, 15 TB/night for 10 years
- 18,000 square degrees, observed once every few days
- Tens of billions of objects, each one observed ∼1000 times
SDSS
Image credit: Peter Melchior
DES
Image credit: Peter Melchior
Image credit: Peter Melchior
HSC (proxy for LSST)
The Deep Learning Boom in Astrophysics
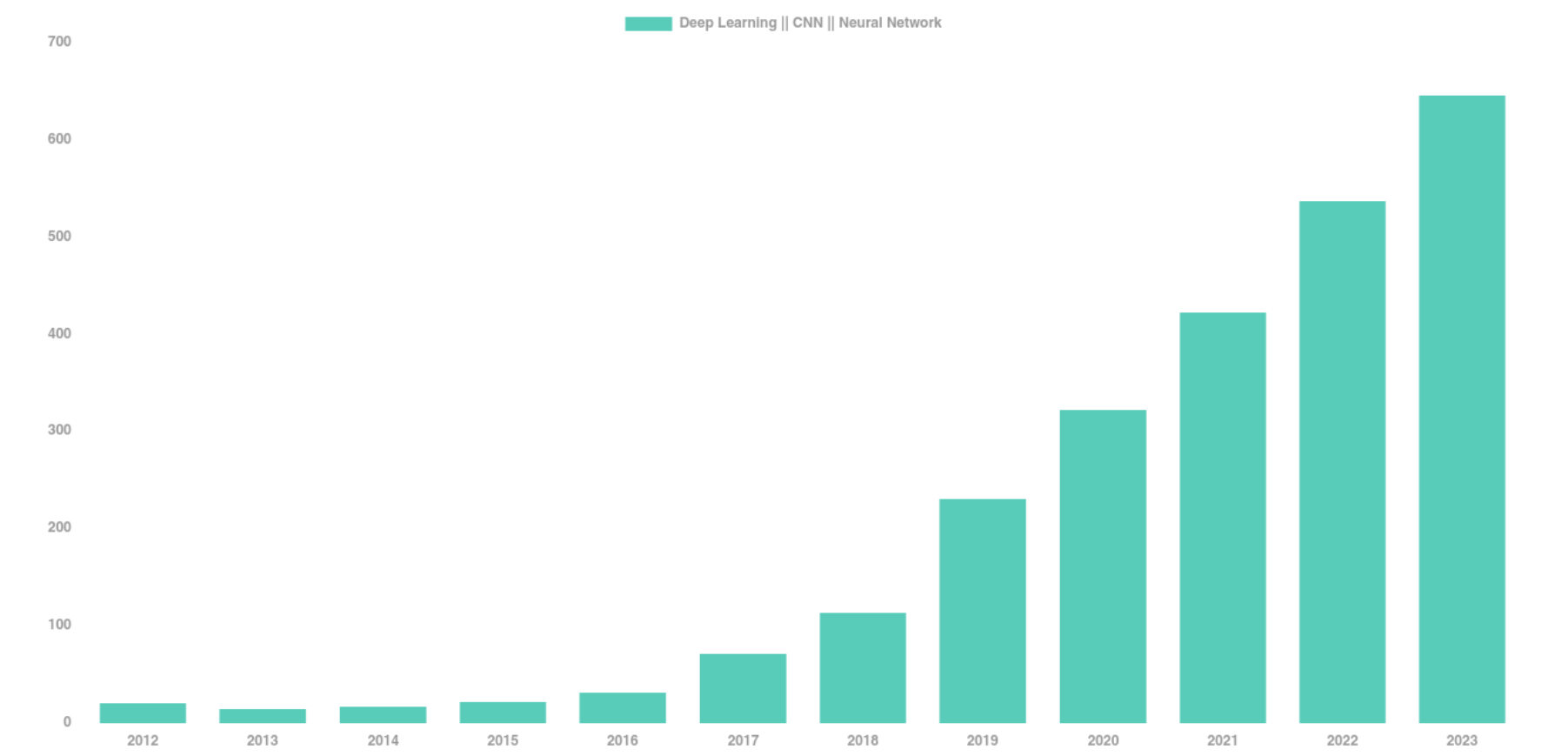
astro-ph abstracts mentioning Deep Learning, CNN, or Neural Networks
The vast majority of these results has relied on supervised learning and networks trained from scratch.
The Limits of Traditional Deep Learning
-
Limited Supervised Training Data
- Rare or novel objects have by definition few labeled examples
- In Simulation Based Inference (SBI), training a neural compression model requires many simulations
- Rare or novel objects have by definition few labeled examples
-
Limited Reusability
- Existing models are trained supervised on a specific task, and specific data.
=> Limits in practice the ease of using deep learning for analysis and discovery
Meanwhile, in Computer Science...
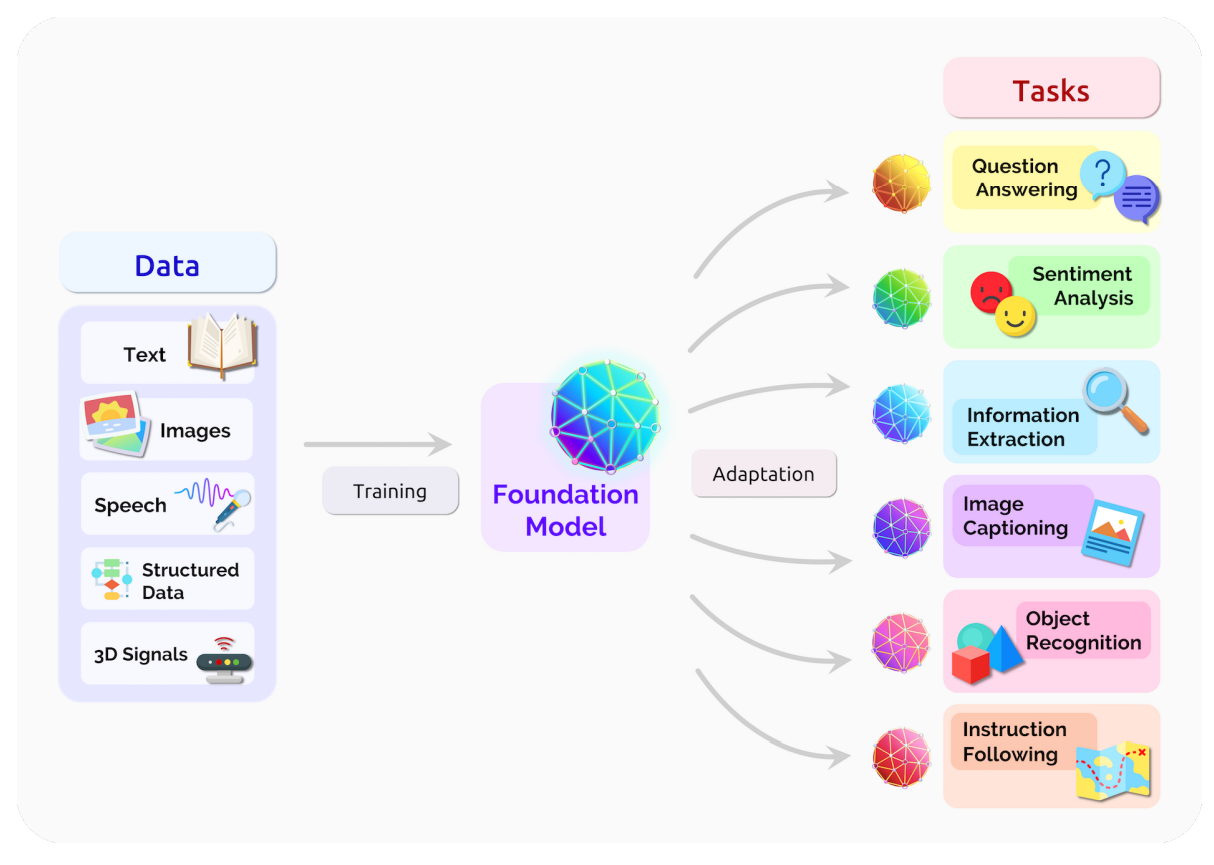
The Rise of The Foundation Model Paradigm
-
Foundation Model approach
- Pretrain models on pretext tasks, without supervision, on very large scale datasets.
- Adapt pretrained models to downstream tasks.
- Combine pretrained modules in more complex systems.
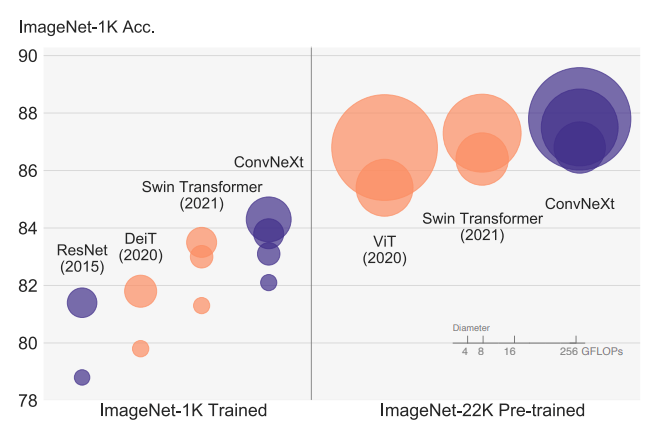
The Advantage of Scale of Data and Compute
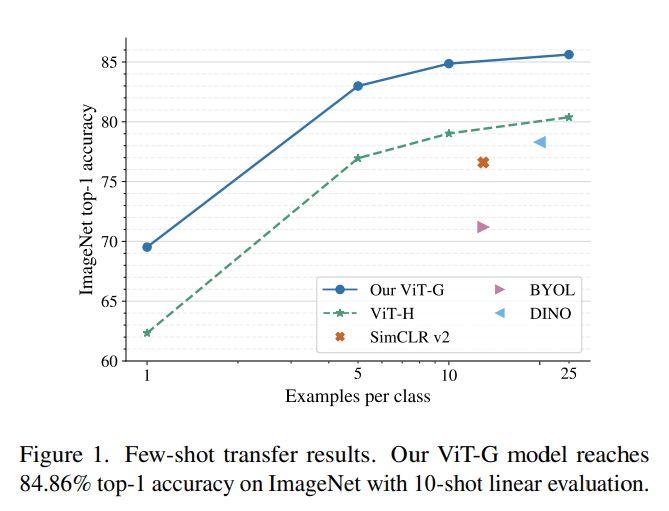
Linearly Accessible Information
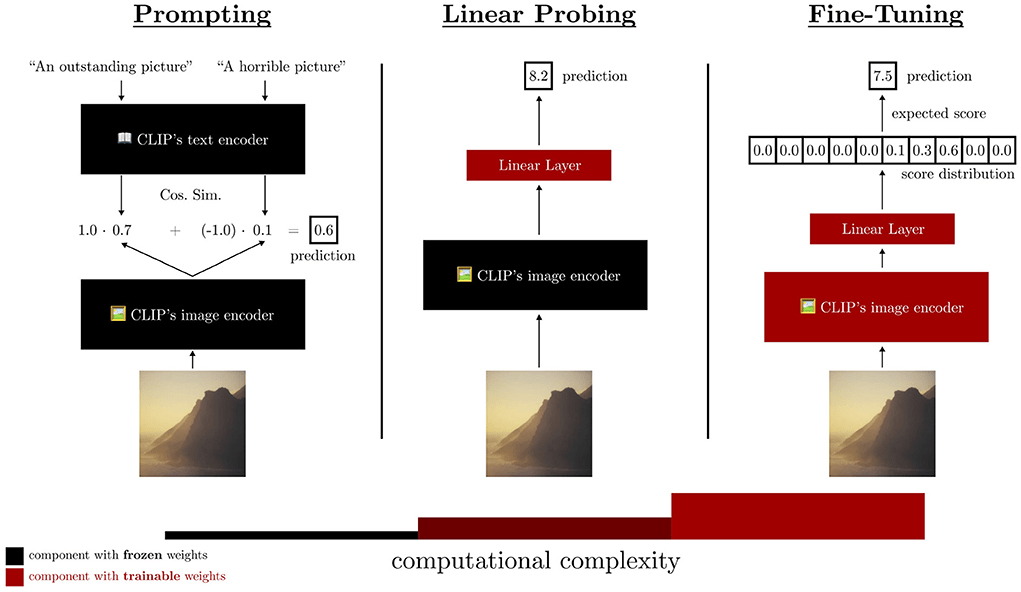
- Backbone of modern architectures embed input images as vectors in where d can typically be between 512 to 2048.
- Linear probing refers to training a single matrix to adapt this vector representation to the desired downstream task.
\mathbb{R}^{d}
Can we translate these innovations into a similar paradigm shift in deep learning for scientific applications?
Polymathic





|
Colm-Cille
Caulfield University of Cambridge
|
Leslie
Greengard Flatiron Institute
New York University |
David Ha Sakana AI |
Yann LeCun Meta AI New York University |
|---|---|---|---|
|
Stephane
Mallat École Normale Supérieure
Collège de France Flatiron Institute |
David
Spergel Simons Foundation |
Olga Troyanskaya Flatiron Institute Princeton University |
Laure
Zanna New York University
|
SCIENTIFIC ADVISORY GROUP















The Data Diversity Challenge
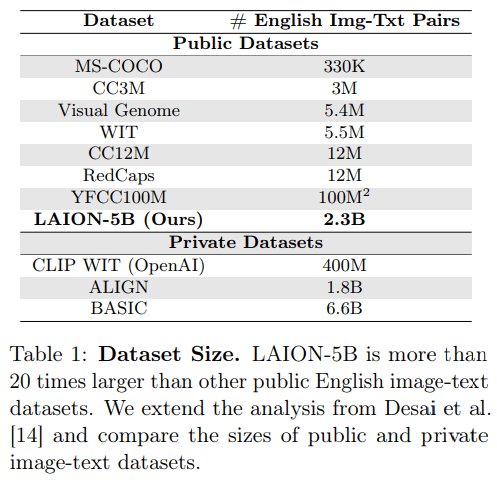
- Success of recent foundation models is driven by large corpora of uniform data (e.g LAION 5B).
- Scientific data comes with many additional challenges:
- Metadata matters
- Wide variety of measurements/observations

Credit: Melchior et al. 2021


Credit:DESI collaboration/DESI Legacy Imaging Surveys/LBNL/DOE & KPNO/CTIO/NOIRLab/NSF/AURA/unWISE
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
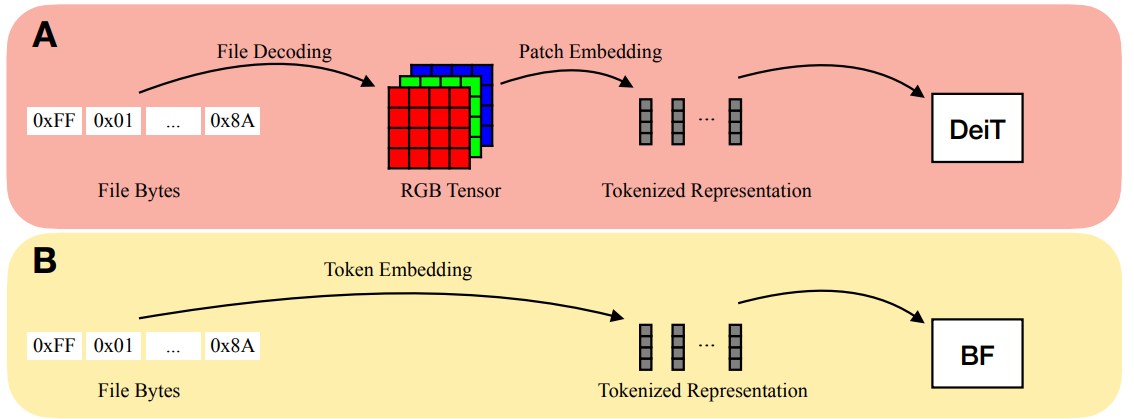
Bytes Are All You Need (Horton et al. 2023)
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
Bytes Are All You Need (Horton et al. 2023)
AstroCLIP
AstroCLIP
Cross-Modal Pre-Training for Astronomical Foundation Models

Project led by Francois Lanusse, Liam Parker, Leopoldo Sarra, Siavash Golkar, Miles Cranmer
Accepted contribution at the NeurIPS 2023 AI4Science Workshop
Published in the Monthly Notices of Royal Astronomical Society





What is CLIP?
Contrastive Language Image Pretraining (CLIP)
(Radford et al. 2021)
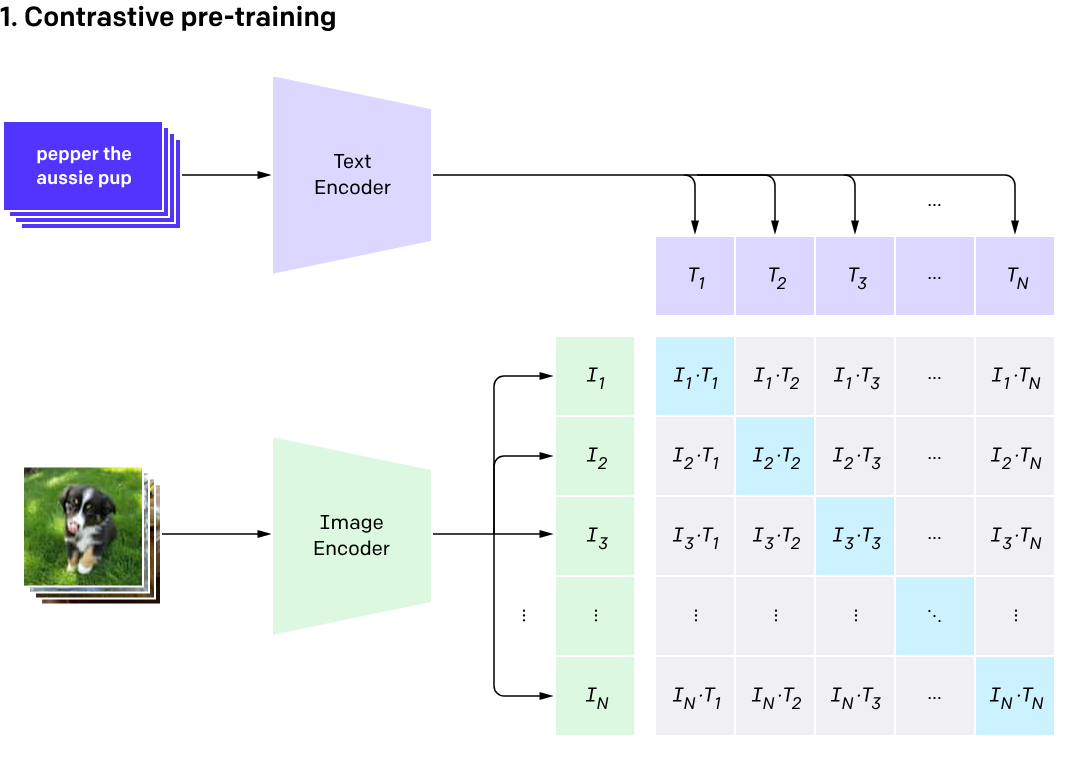
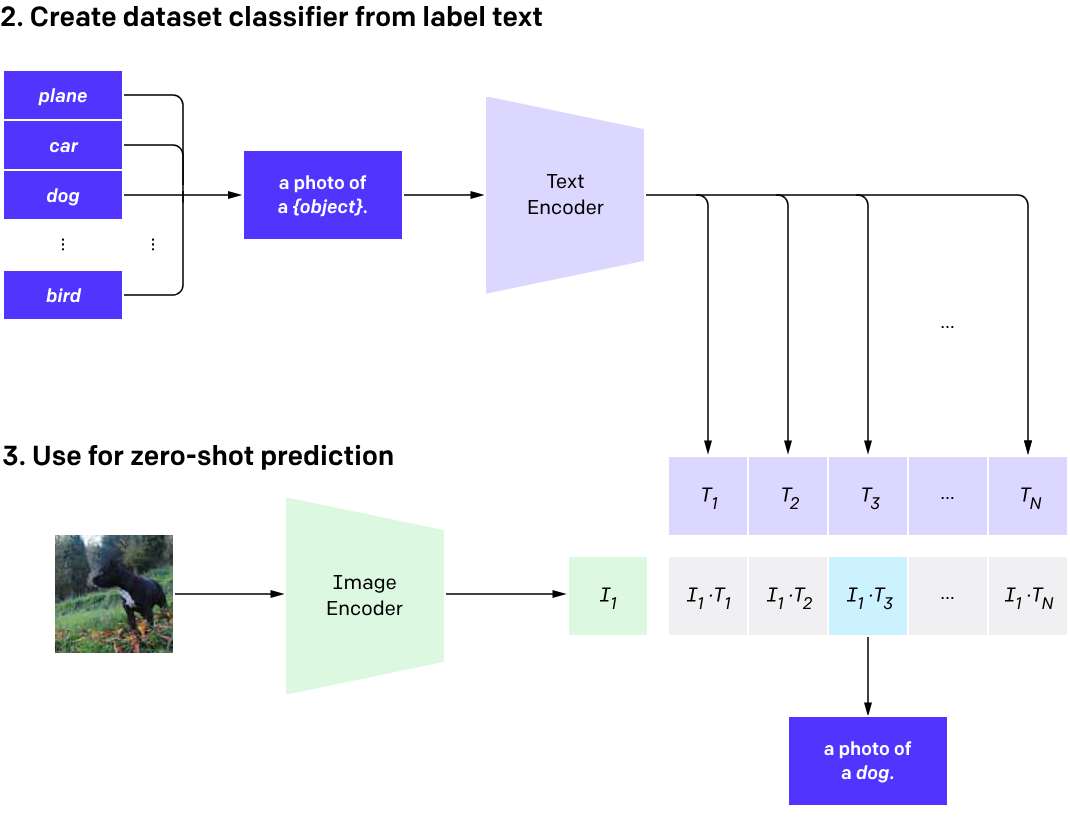
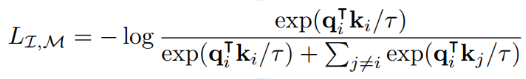
One model, many downstream applications!
Flamingo: a Visual Language Model for Few-Shot Learning (Alayrac et al. 2022)


Hierarchical Text-Conditional Image Generation with CLIP Latents (Ramesh et al. 2022)
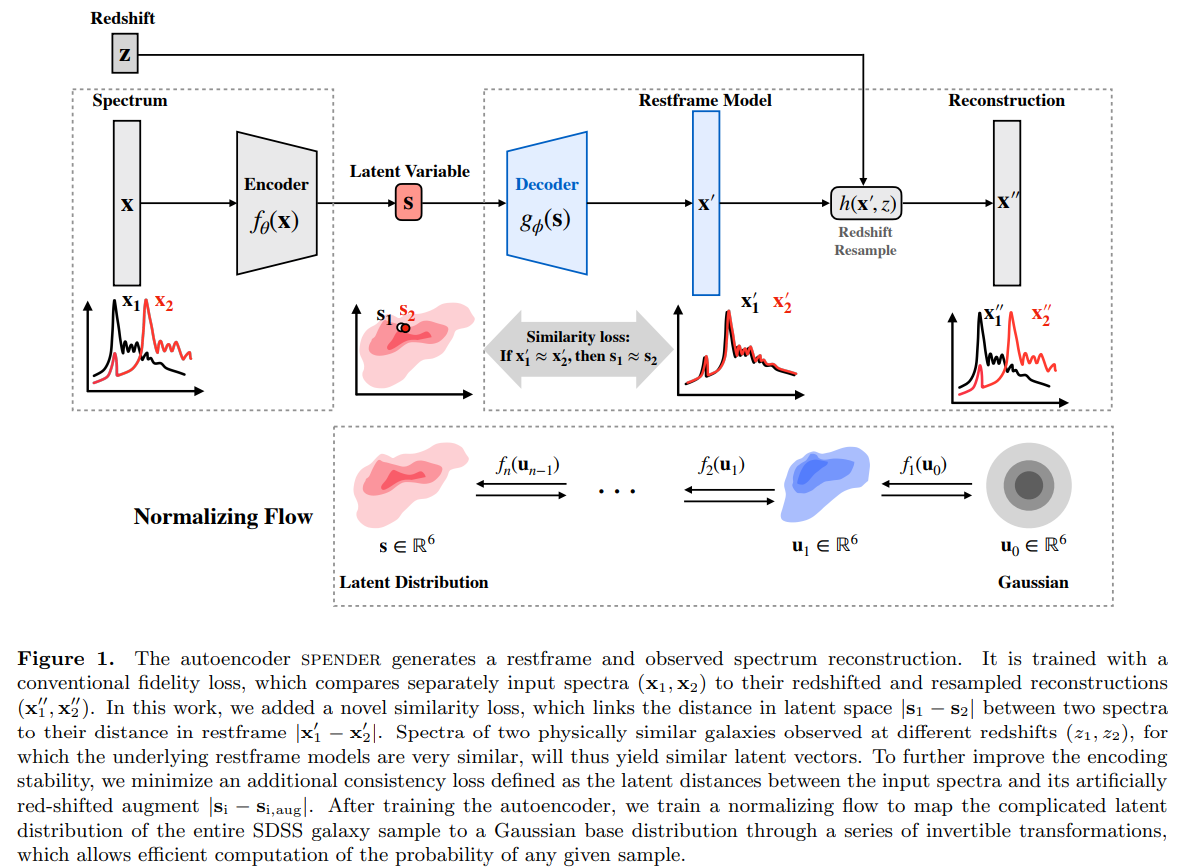
The AstroCLIP approach
- We use spectra and multi-band images as our two different views for the same underlying object.
- DESI Legacy Surveys (g,r,z) images, and DESI EDR galaxy spectra.
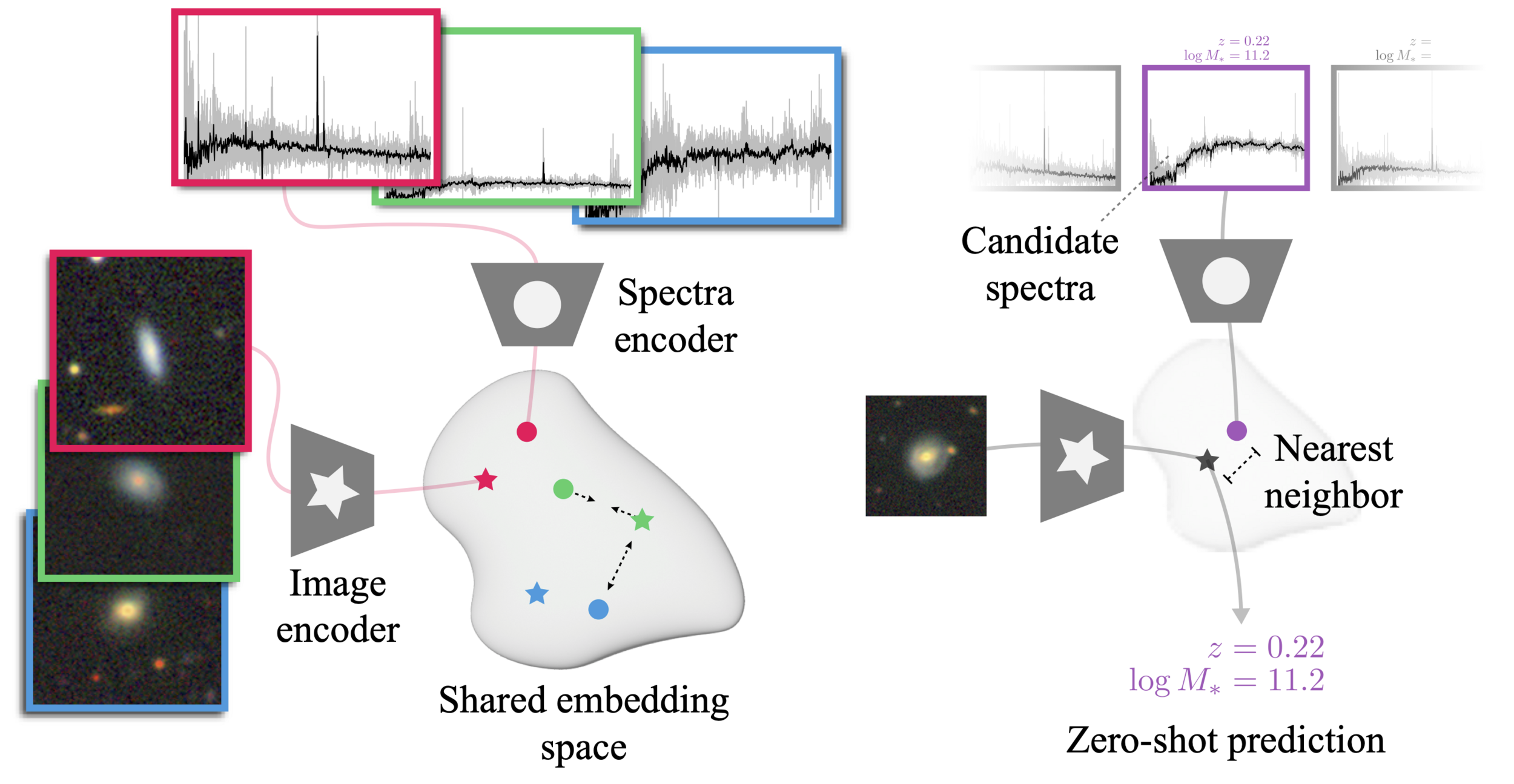

Cosine similarity search
The Information Point of View
- The InfoNCE loss is a lower bound on the Mutual Information between modalities
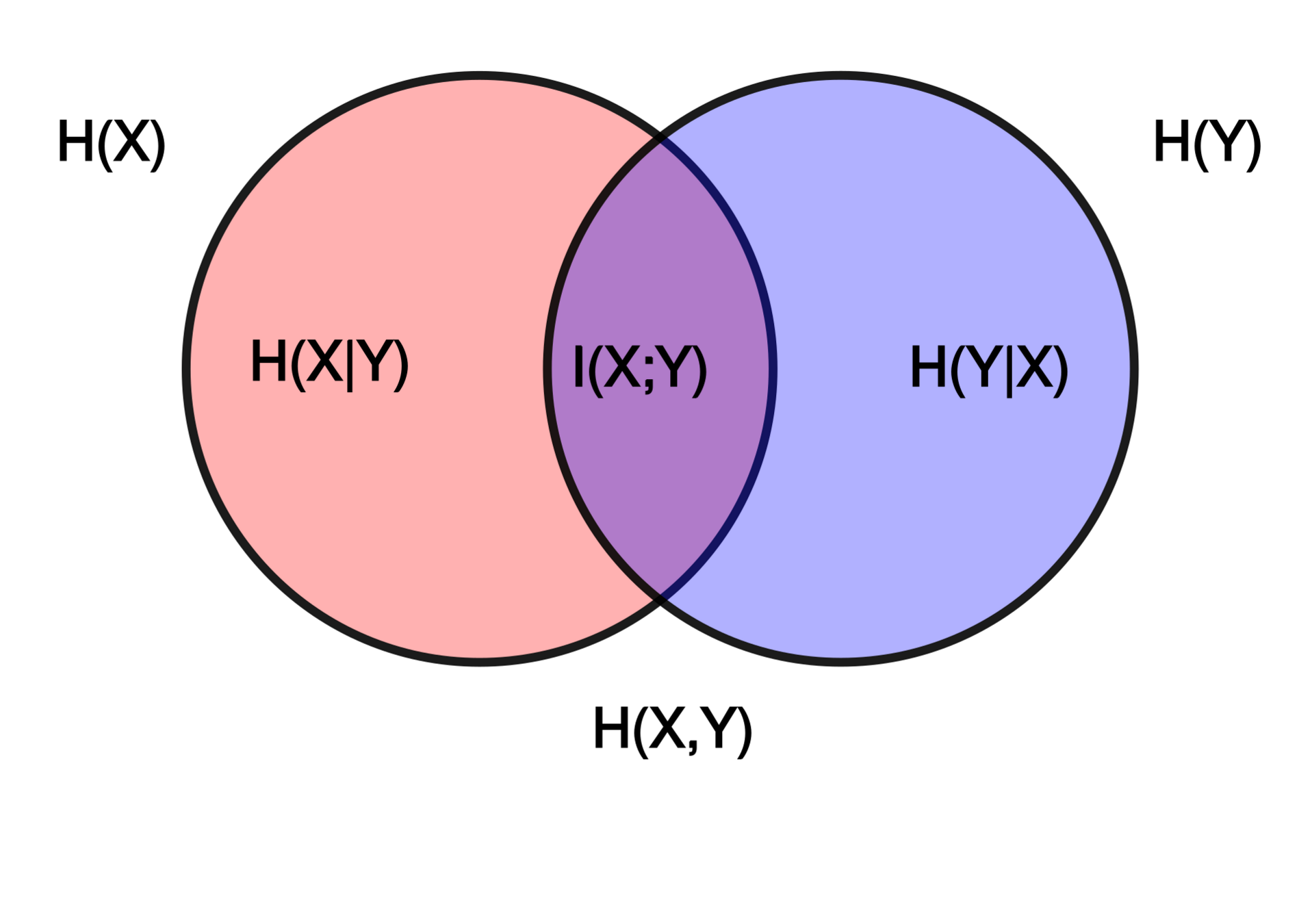
Shared physical information about galaxies between images and spectra
=> We are building summary statistics for the physical parameters describing an object in a completely data driven way
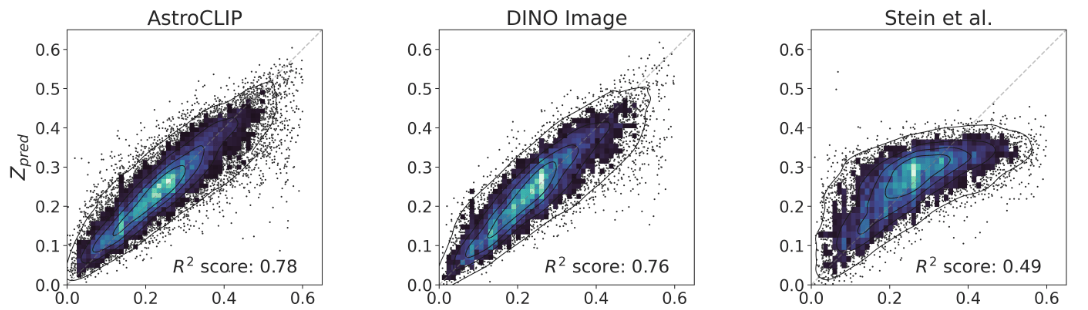
- Redshift Estimation From Images
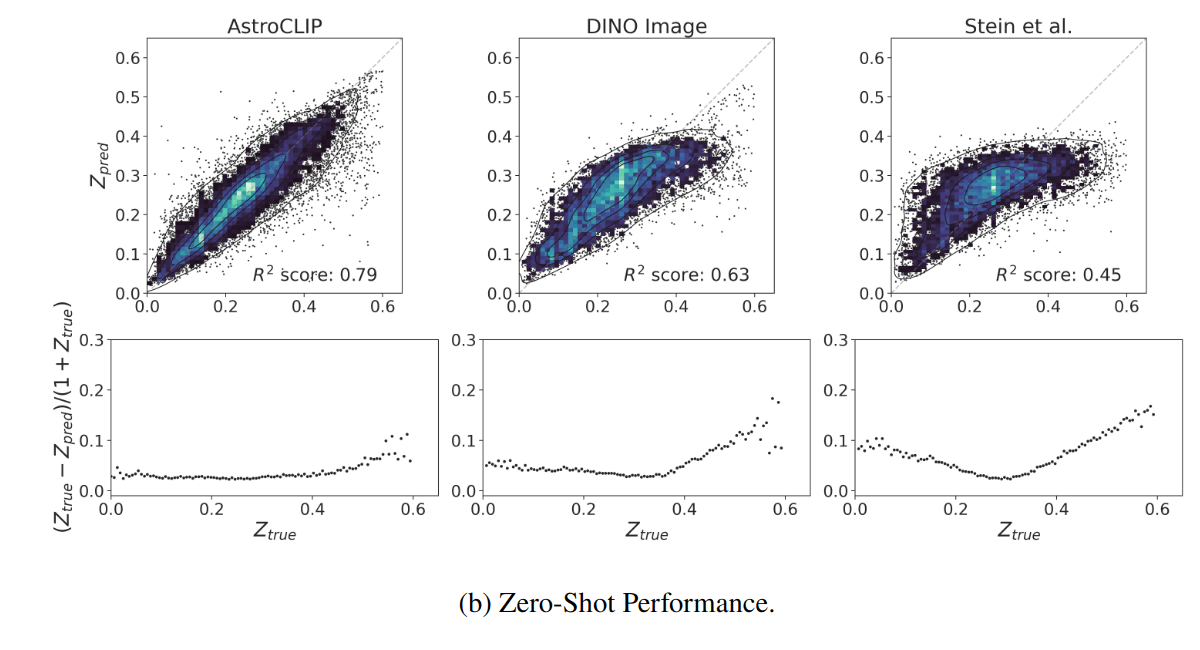
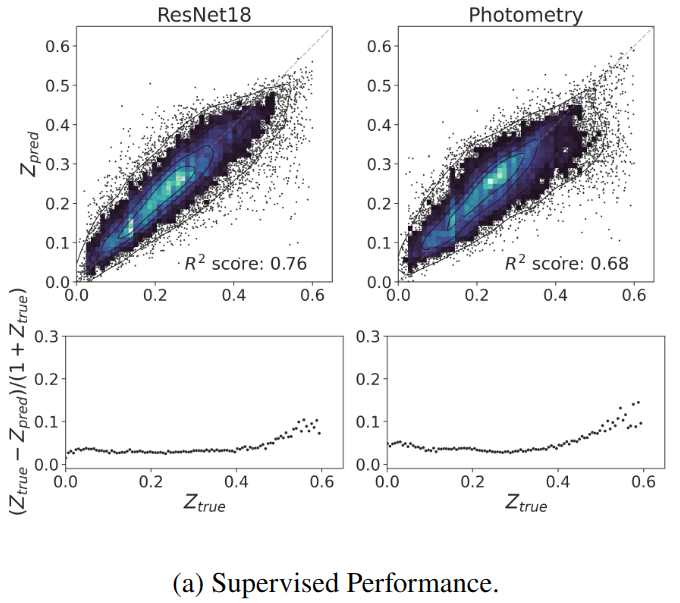
Supervised baseline
z_{true}
z_{true}
z_{true}
z_{true}
z_{true}
z_{true}
z_{true}
z_{true}
- Zero-shot prediction
- k-NN regression
- Few-shot prediction
- MLP head trained on top of frozen backbone
Evaluation of the model: Parameter Inference
- Galaxy Physical Property Estimation from Images and Spectra
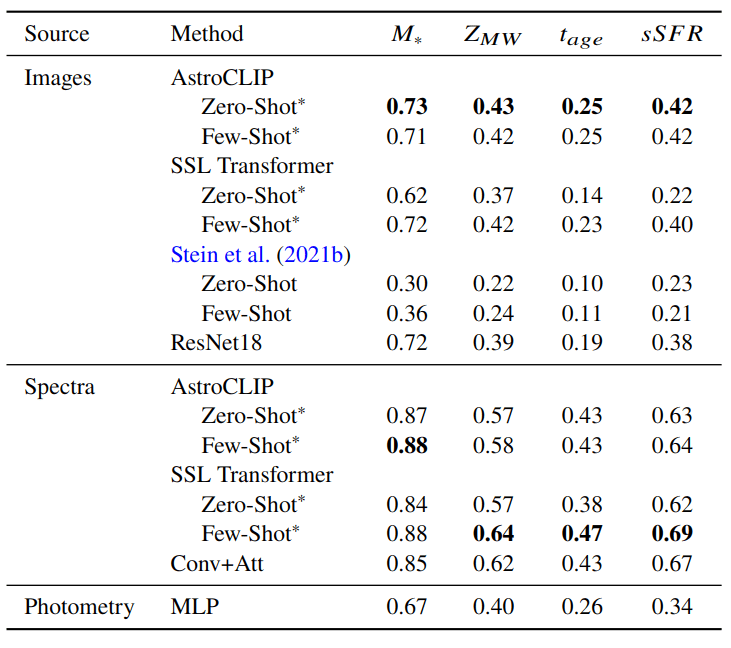
We use estimates of galaxy properties from the PROVABGS catalog (Hahn et al. 2023) (Bayesian spectral energy distribution (SED) modeling of DESI spectroscopy and photometry method)
R^2
of regression

Negative Log Likelihood of Neural Posterior Inference
- Galaxy Morphology Classification
Classification Accuracy
We test a galaxy morphology classification task using as labels the GZ-5 dataset (Walmsley et al. 2021)


The AstroCLIP Model (v2, Parker et al. in prep.)
- For images, we use a ViT-L Transformer (300M).
- For spectra, we use a decoder only Transformer working at the level of spectral patches.
DiNOv2 (Oquab et al. 2023) Image Pretraining
- Common practice for SOTA CLIP models is to initially pretrain the image encoder before CLIP alignment
- We adopt the DiNOv2 state of the art Self-Supervised Learning model for the initial large scale training of the model.
- We pretrain the DiNOv2 model on ~70 million postage stamps from DECaLS


PCA of patch features
Dense Semantic Segmentation
Dense Depth Estimation
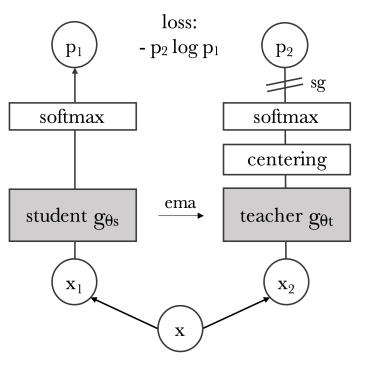
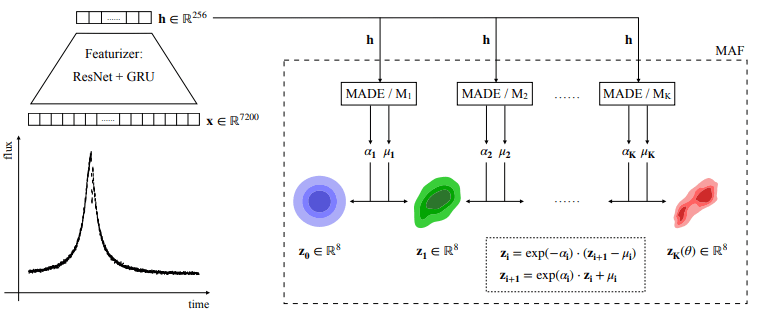
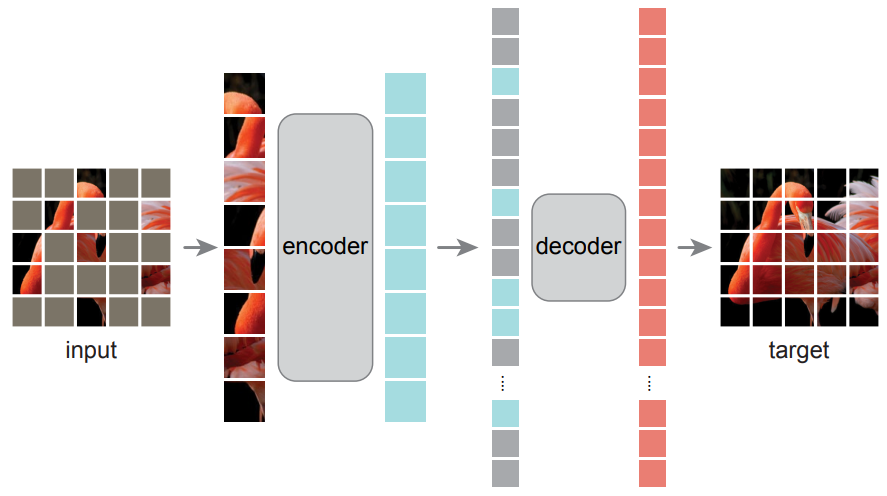
Spectrum Transformer Pretraining by Masked Modeling

- To pretrain the spectrum embedder, we use a simple Masked Image Modeling strategy
\mathcal{L}_{\textrm{MM}} = \frac{1}{NK} \sum_{j=1}^K \sum_{i=1}^N \textbf{m}_i \cdot (\textbf{x}_{i} - \hat{\textbf{x}}_{i})^2,
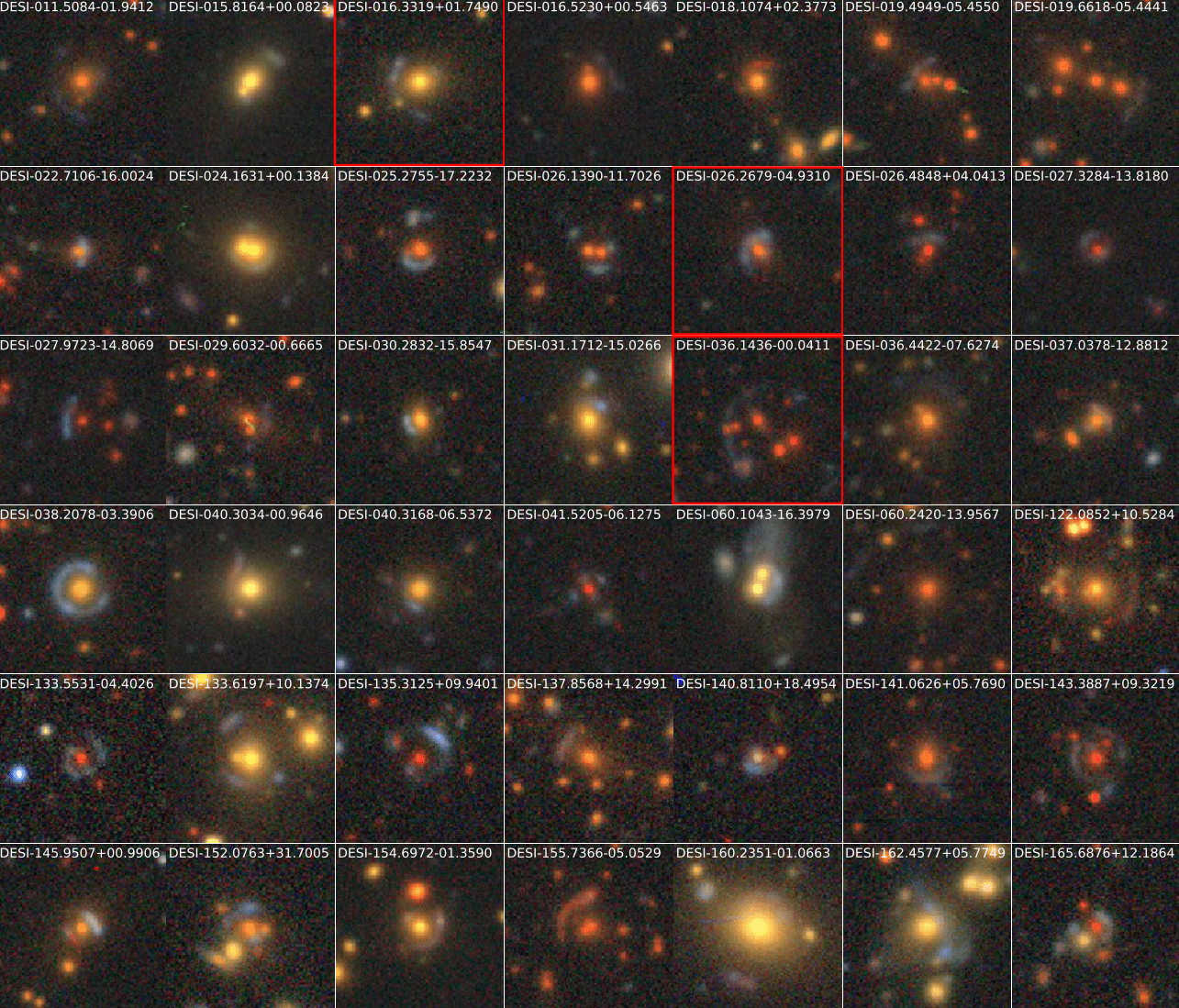
Detecting Galaxy Tidal Features Using Self-Supervised Representation Learning

Project led by Alice Desmons, Francois Lanusse, Sarah Brough





Evaluation of the model: Similarity Search
- Cross-Modal similarity search


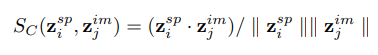

Image Similarity
Spectral Similarity

Image-Spectral Similarity
What This New Paradigm Could Mean for Us Astrophysicists
-
Never have to retrain my own neural networks from scratch
-
Existing pre-trained models would already be near optimal, no matter the task at hand
-
Existing pre-trained models would already be near optimal, no matter the task at hand
- Practical large scale Deep Learning even in very few example regime
-
Searching for very rare objects in large surveys like Euclid or LSST becomes possible
-
Searching for very rare objects in large surveys like Euclid or LSST becomes possible
- If the information is embedded in a space where it becomes linearly accessible, very simple analysis tools are enough for downstream analysis
- In the future, survey pipelines may add vector embedding of detected objects into catalogs, these would be enough for most tasks, without the need to go back to pixels
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
Bytes Are All You Need (Horton et al. 2023)
AstroCLIP
Towards Large Multi-Modal Observational Models
Most General
Most Specific
Independent models for every type of observation
Single model capable of processing all types of observations
Bytes Are All You Need (Horton et al. 2023)
AstroCLIP
"Massively Multi-Modal Large Data Model for Astrophysics"
Towards Massively Multimodal Large Data Models for Astrophysics

New Generation of Token-Based Multimodal Models
Flamingo: a Visual Language Model for Few-Shot Learning (Alayrac et al. 2022)

Chameleon: Mixed-Modal Early-Fusion Foundation Models (Chameleon team, 2024)
All-to-All Foundation Models


Why Is It Interesting to Us?

Galaxy Image Segmentation
Walsmley & Spindler (2023)

Galaxy Image Deblending

=> Foundation Models that build a deep understanding of the data at the pixel level.
Going Further: Data Collection and Curation
- Development of large models requires access to "web scale" datasets
- Astrophysics generates large amounts of publicly available data,
-
BUT, data is usually not stored or structured in an ML friendly way.
-
BUT, data is usually not stored or structured in an ML friendly way.
- Accessing and using scientific data requires significant expertise, for each dataset.
Credit: Melchior et al. 2021
The MultiModal Universe Project
- Goal: Assemble the first large-scale multi-modal dataset for machine learning in astrophysics.
-
Main pillars:
- Engage with a broad community of AI+Astro experts.
- Adopt standardized conventions for storing and accessing data and metadata through mainstream tools (e.g. Hugging Face Datasets).
- Target large astronomical surveys, varied types of instruments, many different astrophysics sub-fields.



Multiband images from Legacy Survey



=> Official release October 2024
Accepted at NeurIPS 2024 🎉
Scientific Data Tokenization




Input
Reconstructed
Our strategy:
- Develop modality specific but universal tokenizers, i.e. a single model to embed all type of astronomical images
- This requires specific innovations to take into account the metadata of observations.
Example of strategy to embed different bands
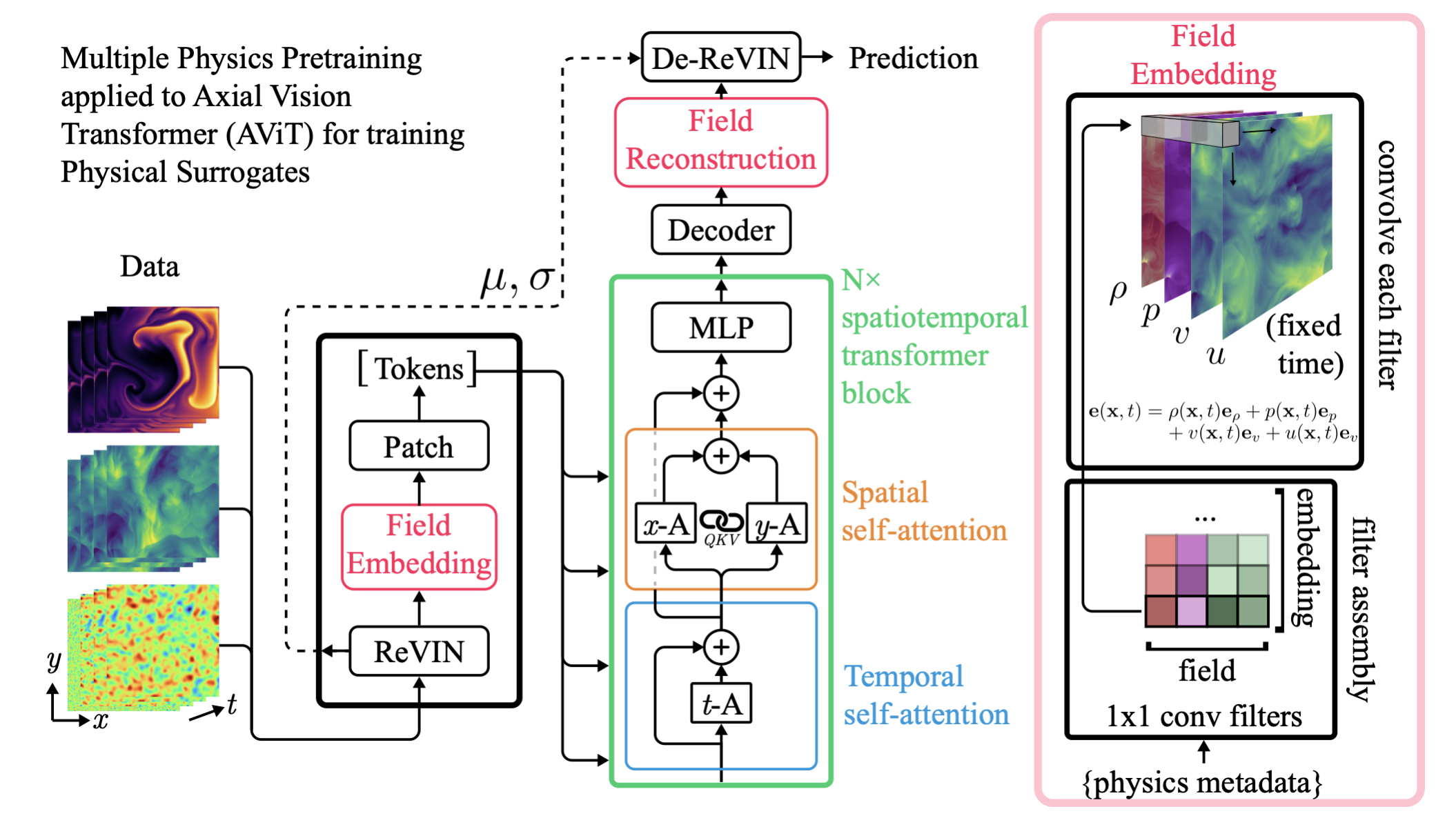
Field Embedding Strategy Developed for Multiple Physics Pretraining (McCabe et al. 2023)

Next Step: Any-to-Any Modeling on Scientific Data

- Learns the joint and all conditional distributions of provided modalities:
- Can be further fine-tuned to build specialist models for news tasks.
\forall m,n \quad p(x_m | x_n)


Jean Zay engineering team visiting Flatiron for a hackathon
MPP
Multiple Physics Pretraining for Physical Surrogate Models

Project led by Michael McCabe, Bruno Régaldo, Liam Parker, Ruben Ohana, Miles Cranmer
Best paper award at the NeurIPS 2023 AI4Science Workshop, accepted at NeurIPS 2024





Physical Systems from PDEBench
Navier-Stokes
Incompressible
Compressible
Shallow Water
Diffusion-Reaction
Takamoto et al. 2022
Can we improve performance of surrogate models by pretraining on large quantities of easily simulatable systems?
Compositionality and Pretraining


MPP (Multi-Physics Pretraining): a single model for varied systems
Experiment 1: Performance on Pretraining Tasks

Context size: 16 frames

Experiment 2: Transfer


Compressible Navier-Stokes
M = 0.1
M = 1.0
Going further
- Methodology improvements for long roll out predictions.
- Larger and more diverse datasets

PDEBench


The Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning
- 55B tokens from 3M frames
=> First ImageNet scale dataset for fluids
-
18 subsets spanning problems in astro, bio, aerospace, chemistry, atmospheric science, and more.
- Simple self-documented HDF5 files, with pytorch readers provided.
=> Available in October 2024
Accepted at NeurIPS 2024 🎉

- Next year we are focusing on scaling up (more domains, more data, larger models) and developing the next generation of our models.
-
We are hiring!
- Postdoctoral positions
- Research engineer positions

Follow us online!
Thank you for listening!
Multimodal PreTraining for Scientific Data - Paris, Oct 24
By eiffl




