GPUs For All (Astrophysicists)!
DAp GPU Half Day, March 29th, 2023

Francois Lanusse, @EiffL






Intel Alder Lake i5 CPU
6 Cores
NVIDIA GeForce RTX 3090 GPU
10,496 CUDA Cores

Connection to the CPU
Streaming Multi Processor
(128 cores)
High Speed GPU Memory
Fast Interconnect with other GPUs


What is the difference between CPU and GPU cores?
- CPU cores are independent, full-featured, with complex instruction sets
- GPU cores not-independent, simpler instruction-set
- All cores in a "warp" execute the same instruction at the same time!
- Single Instruction Multiple Data (SIMD) parallelism
Where GPUs excel
Computer Graphics
Deep Learning

High Performance Computing
Why are GPUs so good for Deep Learning?
-
Simple computations: Neural networks, at the end of the day, only compute very simple linear algebra operations.
- Batch processing: Training neural networks requires computing their loss function over a very large number of examples, which can be processed by "batches".

Attention layer
cornerstone of ChatGPT

Main technical takeaways
- Typically a GPU is a discrete accelerator optimized for parallel processing
- Used by the CPU to offload compute-intensive tasks
- Used by the CPU to offload compute-intensive tasks
- Each GPU has its own memory (distinct from the main system RAM)
- You cannot program a GPU in the same way as you program a CPU!

Illustration of one node of the Perlmutter Supercomputer (NERSC)
Why are we talking about GPUs today?
The road towards exascale!
NERSC 9 system: Perlmutter
- 1536 GPU nodes, each one with 4x NVIDIA A100 (40GB)
- High performance HPE/Cray Slingshot interconnect
- Ranks in top 10 most powerful systems in the world (oct. 2022: 93.75 PFlop/s)


=> GPUs are becoming essential for HPC, and key to reaching exascale!
- More and more computing centers will have GPU nodes

GPU Programming is Becoming Increasingly Easy!
- In 2012, Deep Learning started to boom, in part thanks to being able to run neural networks on GPUs
- Many frameworks have emerged to implement neural networks:
- Caffe (2012-2017)
- Theano (2007-2020)
- Caffe2 (2017-2018)
- CNTK (2016-2019)
- TensorFlow (2015-present)
- PyTorch (2016-present)
- JAX (2018-present)


=> Modern Deep Learning Frameworks look like normal Python but execute code on GPU!
- Can be used to perform all kinds of computing
Different ways to code on GPU
- If you are an HPC specialist and you care about performance (see Arnaud and Maxime's Dyablo talk)
- The artisanal way (back in my days!): coding GPU kernels in CUDA C/C++/Fortran
- The modern way: back-end agnostic higher level C++ frameworks like Kokkos
- If you are a computing-savvy astrophysicist, looking for performance, but want to code in Python as much as possible
- Numpy, Scipy -> Cupy
- Scikit-learn -> RAPIDS CuML
- If you are an astrophysicist who wants to use GPUs
but not after each millisecond and profit from
autodiff (see Denise's and Benjamin's talks)

JAX: NumPy + Autograd + XLA
- JAX uses the NumPy API
=> You can copy/paste existing code, works pretty much out of the box
- JAX is a successor of autograd
=> You can transform any function to get forward or backward automatic derivatives (grad, jacobians, hessians, etc)
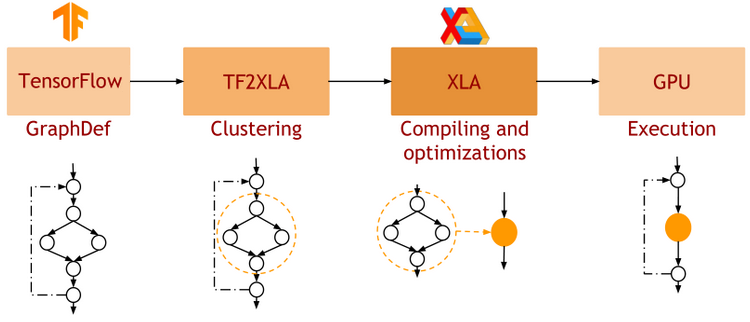
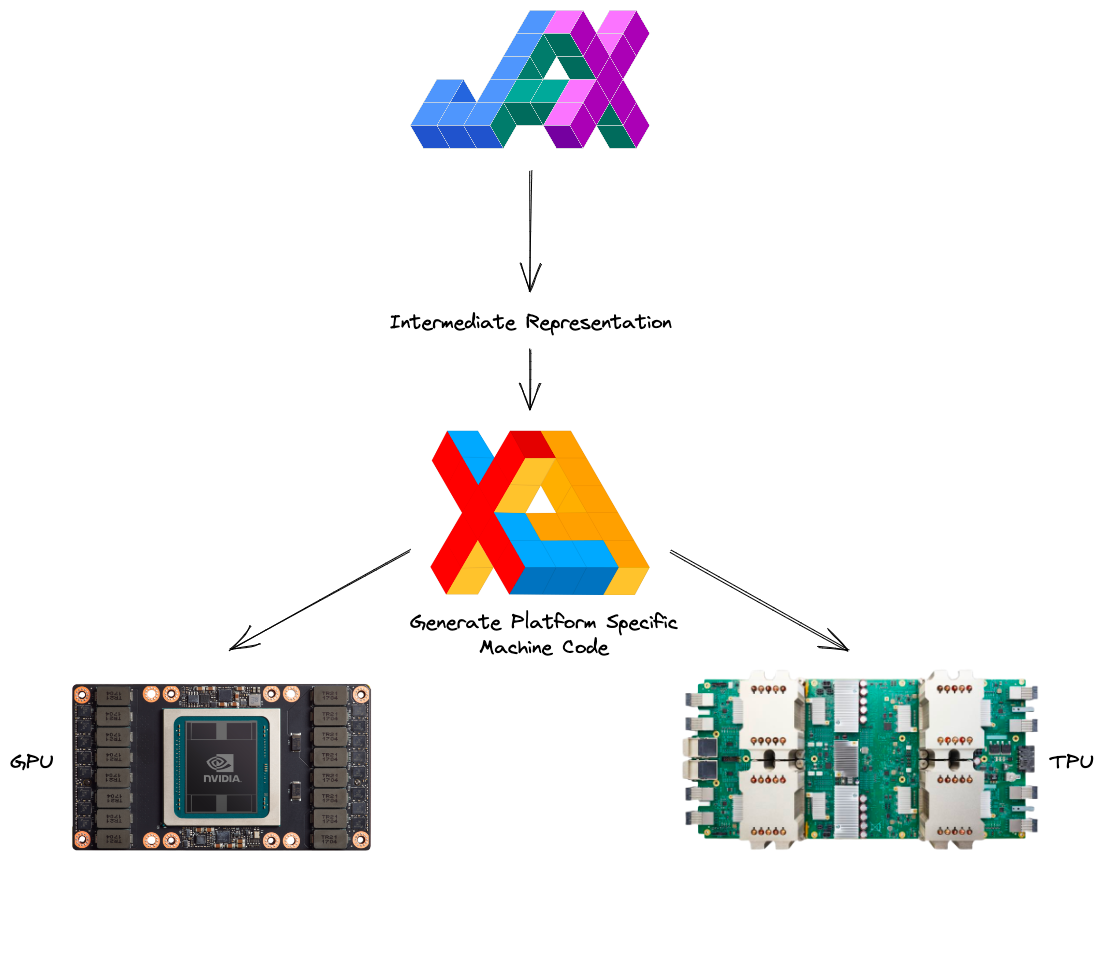
- JAX uses XLA as a backend
=> Same framework as used by TensorFlow (transparently supports CPU, GPU, TPU execution)
import jax.numpy as np
m = np.eye(10) # Some matrix
def my_func(x):
return m.dot(x).sum()
x = np.linspace(0,1,10)
y = my_func(x)from jax import grad
df_dx = grad(my_func)
y = df_dx(x)
MPI4JAX - Zero-copy MPI communication of JAX arrays
-
In a nutshell, provides a JAX wrapper around MPI primitives
-
Compiled against MPI4PY, rely on CUDA-aware MPI for GPUDirect RDMA
- Primitives can be included directly in jitted code!
-
Compiled against MPI4PY, rely on CUDA-aware MPI for GPUDirect RDMA

from mpi4py import MPI
import jax
import jax.numpy as jnp
import mpi4jax
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
@jax.jit
def foo(arr):
arr = arr + rank
arr_sum, _ = mpi4jax.allreduce(arr, op=MPI.SUM, comm=comm)
return arr_sum
a = jnp.zeros((3, 3))
result = foo(a)
if rank == 0:
print(result)This code is executed on all processes, each one has a single GPU

mpirun -n 4 python myapp.py
Find out more on the MPI4JAX doc: https://mpi4jax.readthedocs.io/en/latest/shallow-water.html
- Example of a physical nonlinear shallow-water model distributed on 4 GPUs (Hafner & Vincentini, 2021)
- MPI is used to ensure proper boundary conditions between processes by performing a halo exchange
Examples of Applications
The near future: native SPMD in XLA
- JAX relies on the XLA (Accelerated Linear Algebra) library for compiling and executing jitted code.
- Around 2021-2022, support for low-level collective operations as been added to XLA, with NCCL as a backend on GPU clusters \o/
=> JAX is technically natively parallelisable through XLA communication primitives on machines like Jean Zay.
JAX API is still in flux, but it's going to be awesome

Example: jax-cosmo, GPU Accelerated Cosmology Library
- Looks like simple Python/NumPy code, precisely compute cosmological predictions for weak lensing and galaxy clustering.
- Because it is coded in JAX you can:
- Run transparently on CPU/GPU/TPU
- Run large "batches" of computations in parallel
- Access gradients of cosmological likelihoods (useful for advanced MCMC samplers)
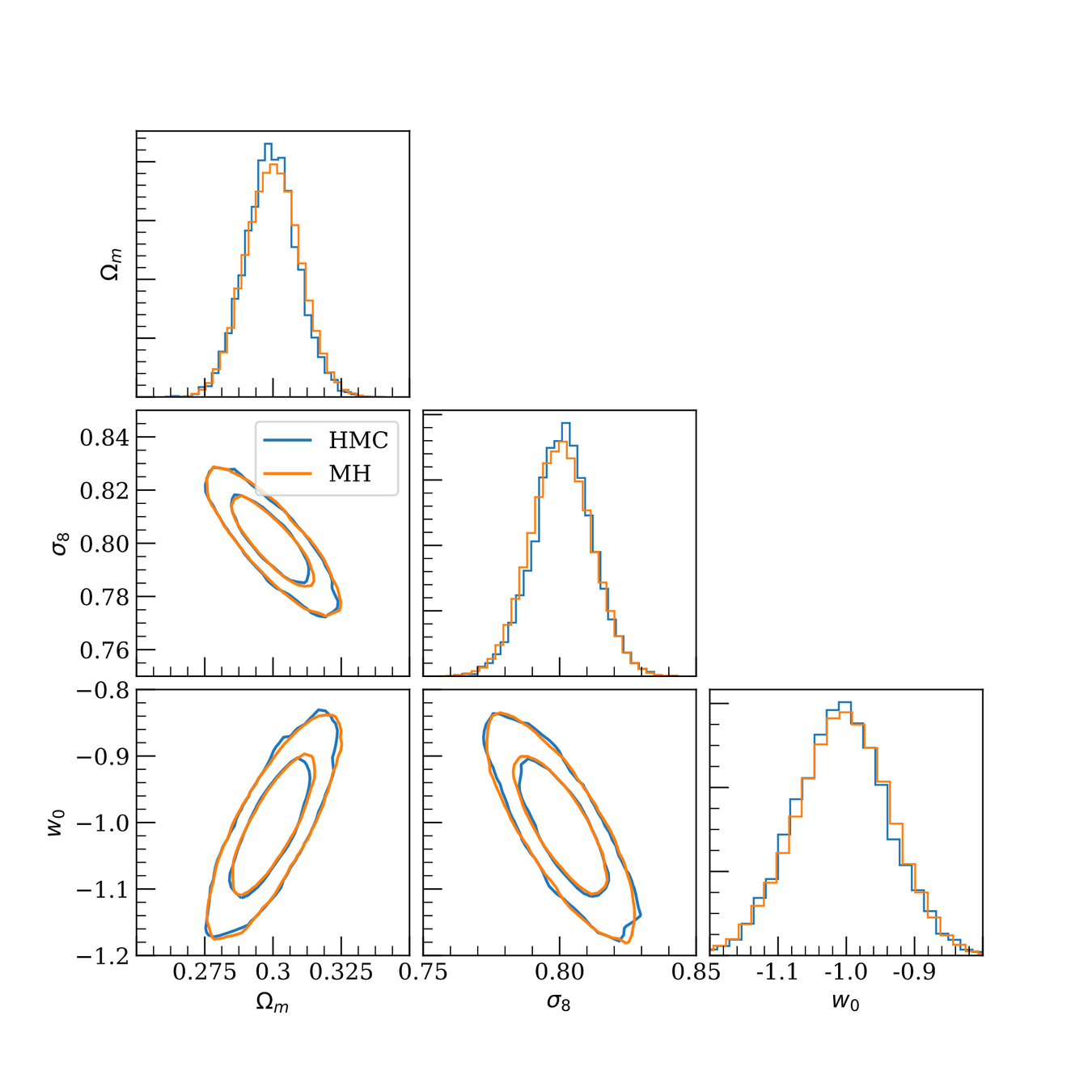
DES Y1 3x2pt posterior, jax-cosmo HMC vs Cobaya MH
(credit: Joe Zuntz)
def log_posterior( theta ):
return gaussian_likelihood( theta ) + log_prior(theta)
score = jax.grad(log_posterior)(theta)Example: FlowPM, distributed GPU accelerated cosmological N-body solver
- High Performance Particle-Mesh N-body solver written in TensorFlow. Validated against reference FastPM.
- Supports distribution over multiple GPUs, tested on up to 256 GPUs on Jean-Zay
- Direct GPU-to-GPU communications through NCCL
- Direct GPU-to-GPU communications through NCCL
- See Denise's talk for applications
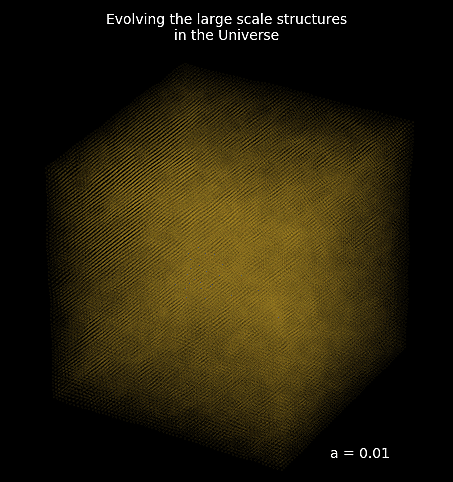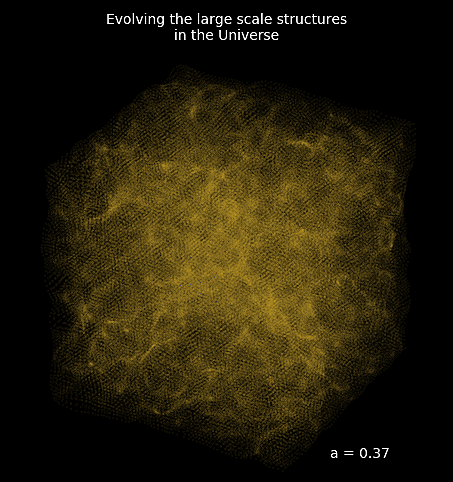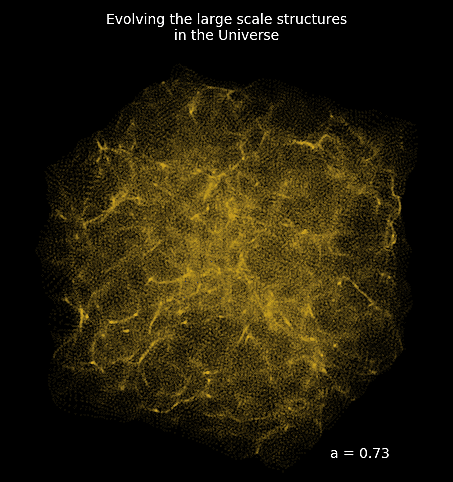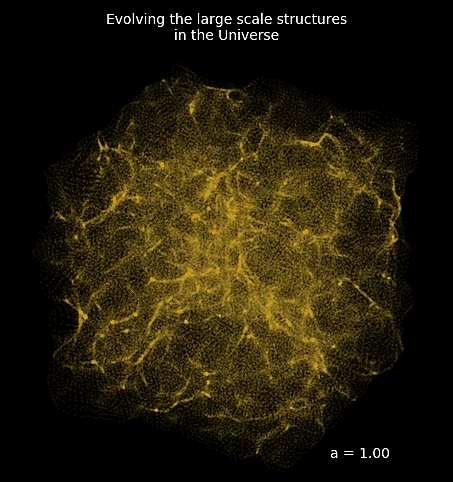
Example: Deep Learning MRI reconstruction

- Implemented end-to-end in JAX
- Involves large neural network (UNet)
- Requires performing a large number of FFTs to model the data acquisition of the MRI instrument
A few other examples in the wild
-
WaveDiff: GPU accelerated Euclid PSF modeling code developed at CosmoStat
- TensorFlow
- TensorFlow
-
JAX-GalSim: GPU accelerated clone of the GalSim galaxy image simulation code
- JAX
- JAX
-
DSPS: GPU accelerated Differentiable Stellar Population Synthesis
- JAX
- JAX
-
pmwd: GPU accelerated particle mesh with derivatives N-body code
- JAX
Where can I get some GPUs?

Depending on your needs
- If you just want to try a few things out:
-
Google Colab: https://colab.research.google.com
- Free access to GPUs and TPUs (within some limits)
- Super easy to use, nothing to install!
- Really great to allow others to reproduce your results/demos
- (Check with your supervisor first if they are ok with you putting your research on Google platforms)
-
Google Colab: https://colab.research.google.com
- If you want a free, secure, robust GPU platform, from getting started to doing serious compute:
-
Jean Zay: http://www.idris.fr/eng/info/gestion/demandes-heures-eng.html
- Supercomputer with thousands of GPUs (state of the art ones!)
- Dynamic Access (AD) has a low barrier to entry
- Once everything is setup, very easy to use
- Highly recommended over buying your own GPU machine!!!
-
Jean Zay: http://www.idris.fr/eng/info/gestion/demandes-heures-eng.html
Takeaways
- I usually expect a speed up of a factor 100x between CPU and GPU code (for my typical applications).
- GPUs can be used to accelerate a wide range of problems, they are not only reserved to HPC and deep learning!
- These days getting started with GPUs is as easy as
import jax.numpy as np -
Ask your doctor if GPU is right for you!
- Happy to chat about your use cases and orient you towards the best solution!
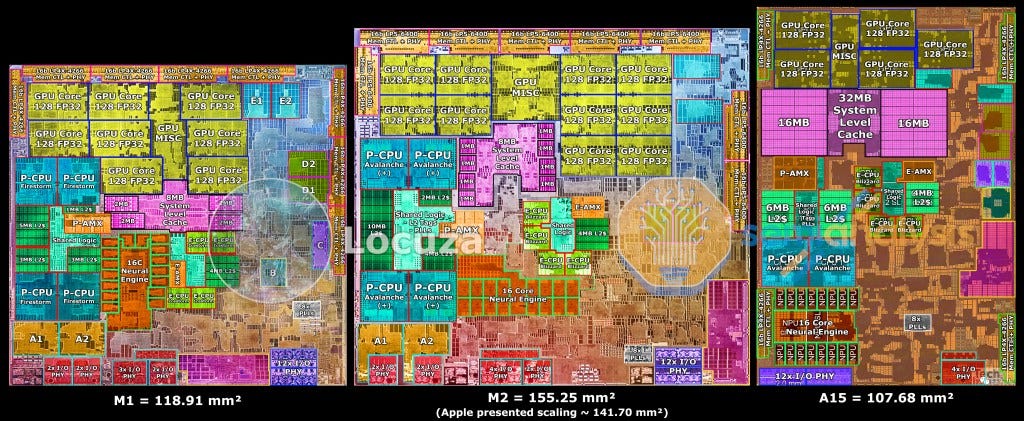
Wait, what about my Mac?

DAp GPU Day
By eiffl




