Pretraining Scientific Foundation Models

François Lanusse
CNRS Researcher @ AIM, CEA Paris-Saclay
from Spatiotemporal Surrogate Models
to Large Multimodal Data Models

The Rise of The Foundation Model Paradigm
-
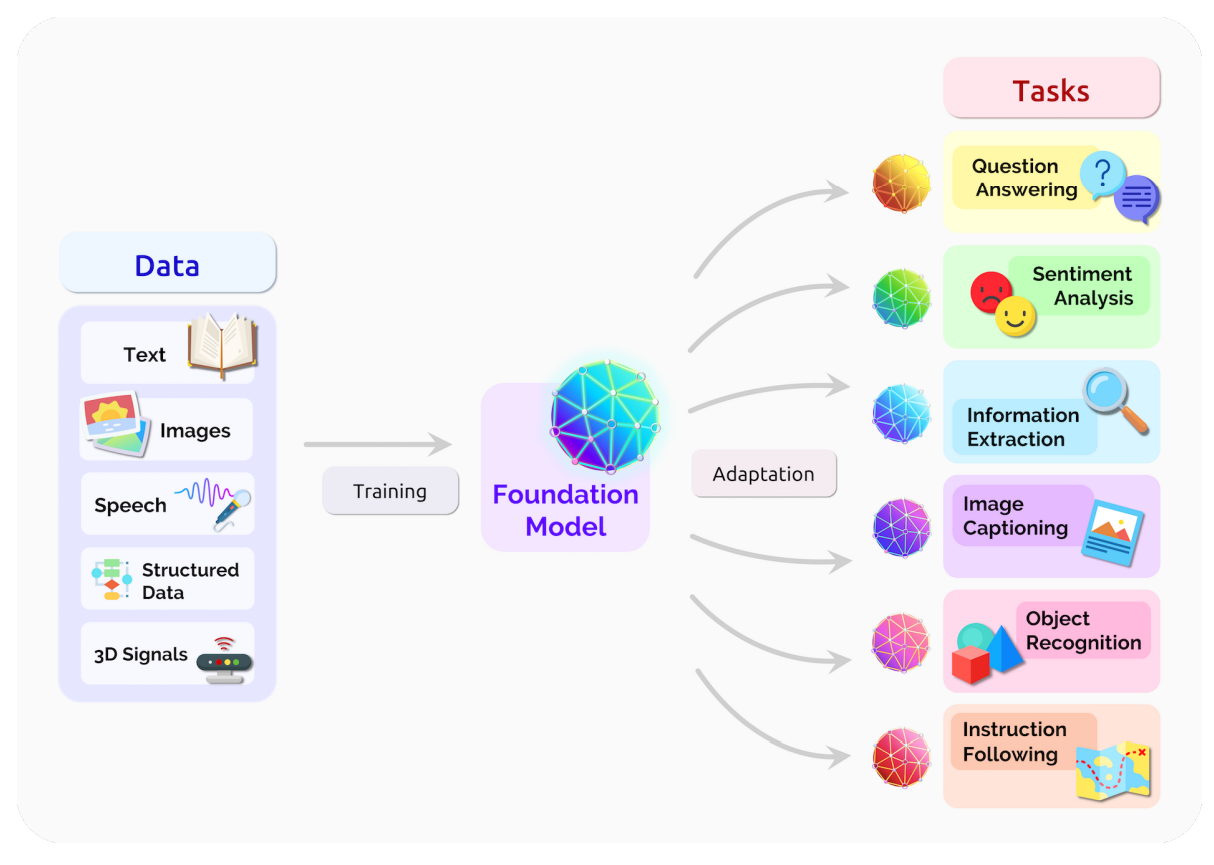
Foundation Model approach
-
Pretrain models on pretext tasks, without supervision, on very large scale datasets.
- Adapt pretrained models to downstream tasks.
-
Pretrain models on pretext tasks, without supervision, on very large scale datasets.
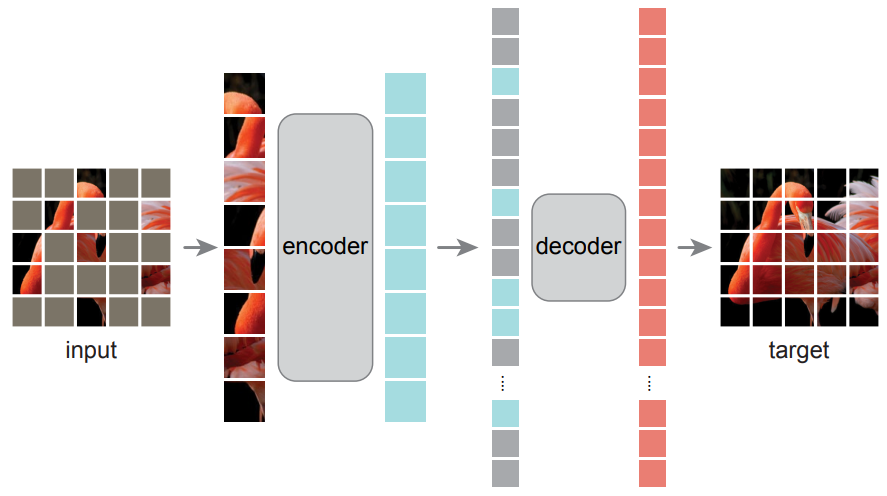
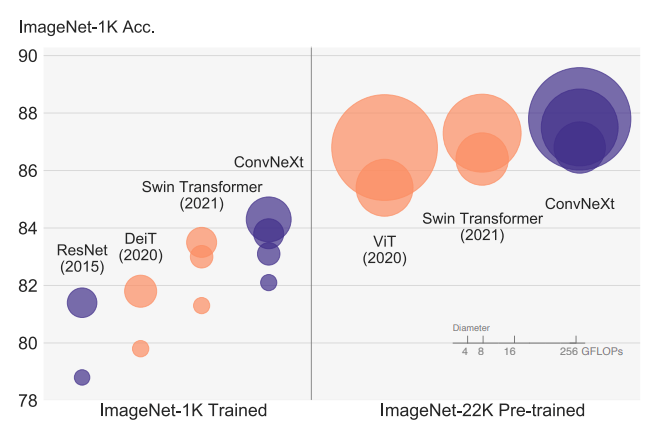
The Advantage of Scale of Data and Compute
Can we translate these innovations into a paradigm shift in machine learning for scientific applications?





Polymathic
Advancing Science through Multi‑Disciplinary AI
Spatiotemporal Surrogate Models
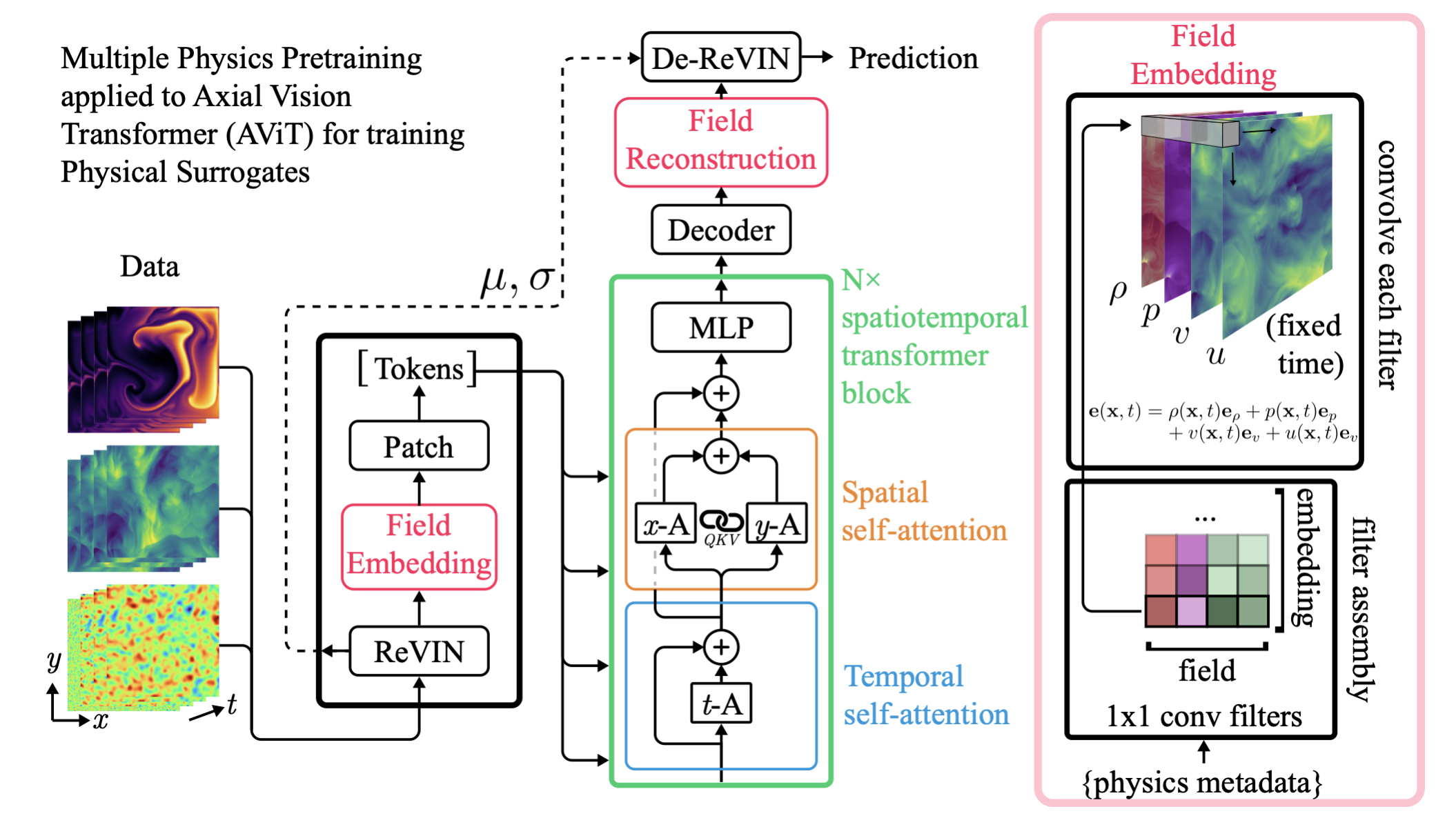
MPP
Multiple Physics Pretraining for
Physical Surrogate Models


Project led by Michael McCabe, Bruno Régaldo, Liam Parker, Ruben Ohana, Miles Cranmer
Accepted at NeurIPS 2024, Best paper award at the NeurIPS 2023 AI4Science Workshop





Compositionality and Pretraining


Physical Systems from PDEBench
Navier-Stokes
Incompressible
Compressible
Shallow Water
Diffusion-Reaction
Takamoto et al. 2022
Can we improve performance of surrogate models by pretraining on large quantities of easily simulatable systems?
MPP: A unified model for diverse physics
Balancing objectives during training


Normalized MSE:

Performance on Pretraining Tasks

Context size: 16 frames

Transfer Experiment on Compressible Navier-Stokes


M = 0.1
M = 1.0
Going further
- Methodology improvements for long roll out predictions.
- Larger and more diverse datasets

PDEBench


The Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning
-
15TB of data: 55B tokens from 3M frames
=> First ImageNet scale dataset for fluids
-
18 subsets spanning problems in astro, bio, aerospace, chemistry, atmospheric science, and more.
- Simple self-documented HDF5 files, with pytorch readers provided.
Presented at NeurIPS 2024 Datasets & Benchmark Track




Challenges of training the next generation of models


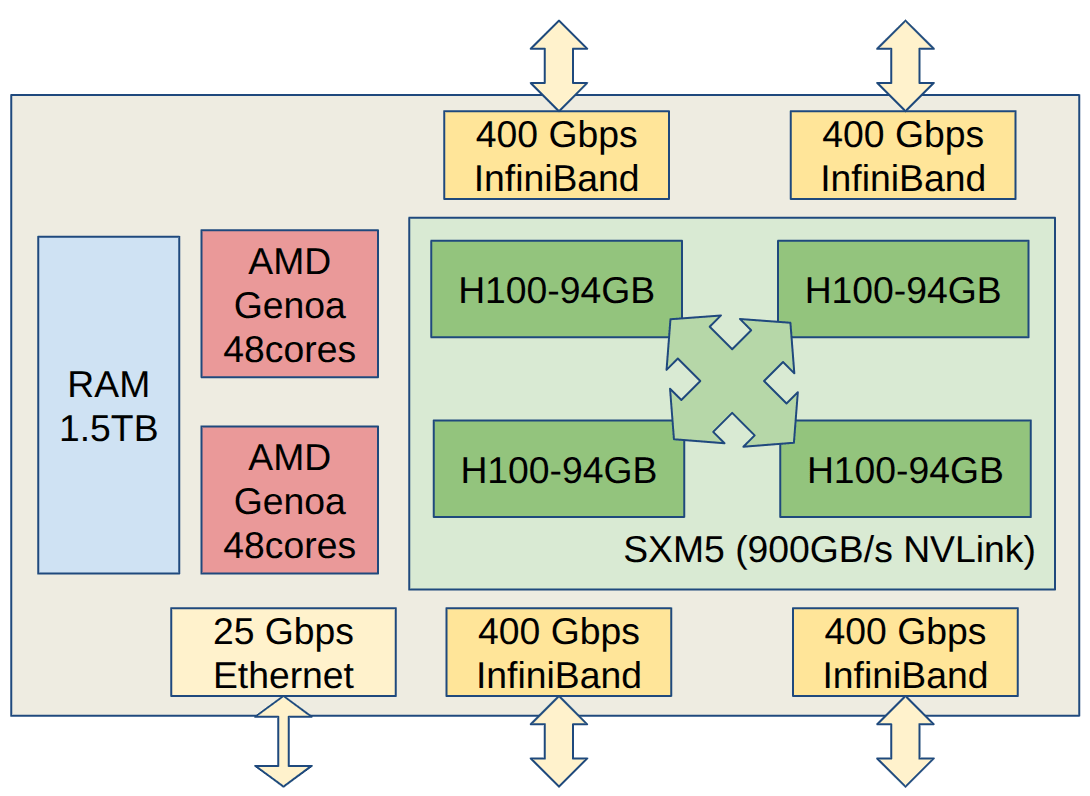
Flatiron Institute's Raphael Cluster
- 24 nodes, 4 H100-94GB GPUs per node
- SXM5 in-node
- 4x 400Gb InfiniBand between nodes
Pain points
-
Contrary to LLMs which act on tokens, our model acts on 2D/3D dense fields.
=> High data throughput requirements-
IBM Storage Scale System 6000
- 250TB SSDs over infiniband
- 250GB/s reads, 150GB/s writes
-
IBM Storage Scale System 6000
- Float32 precision requirements
- Efficient balancing between problems
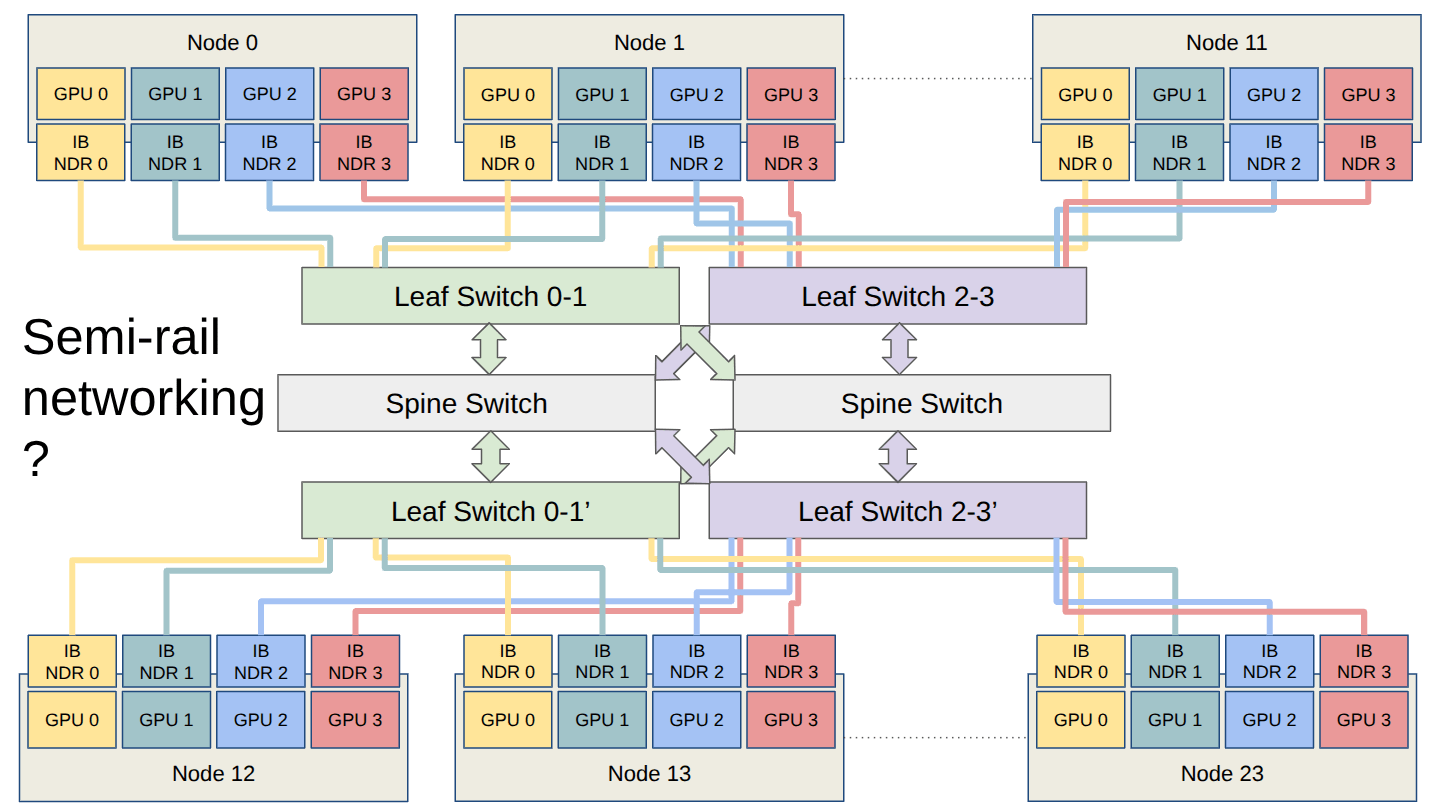
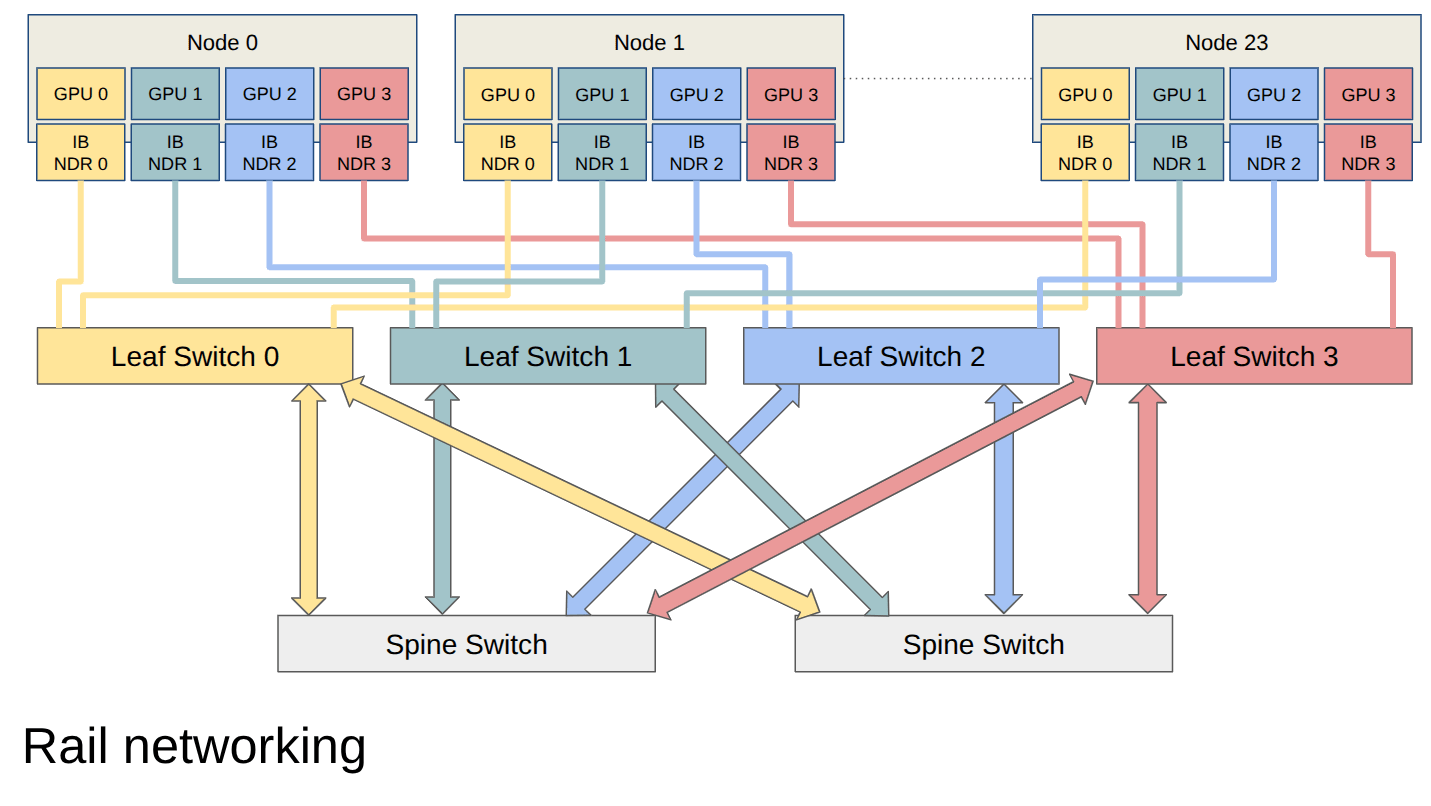
Perfomance optimization
-
NCCL AllReduce algorithm expects a specific topology in the network
- SXM connection (“NVLink”) inside the nodes
- Each GPU has its own InfiniBand interface
-
Rail configuration: all GPUs with the same ordinal are connected to the same leaf switch
- The InfiniBand adapters in our nodes have a single slot for both ports
- “Semi-rail”
-
For better performance, we enabled SHARP (Scalable Hierarchical Aggregation and Reduction Protocol)
- Collective computations offloaded to the switches
Multimodal Scientific Data Models

Why a Dedicated Effort For Scientific Data?
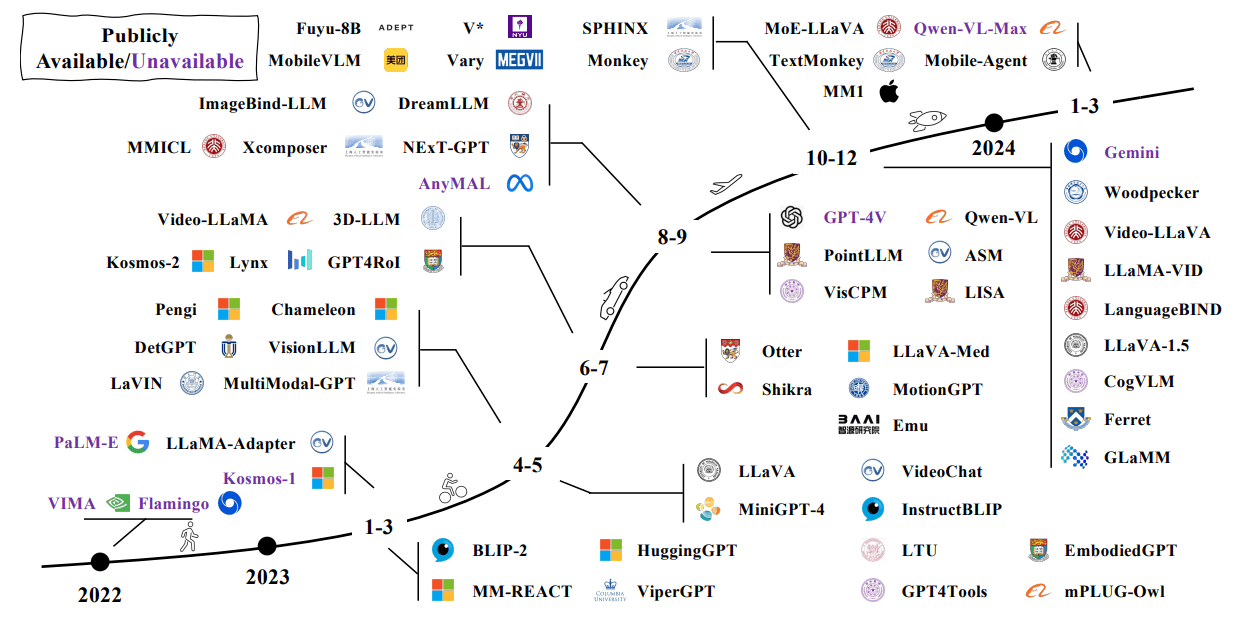




Transposing these methodologies to scientific data and problems brings
unique challenges
-
Scientific Data is Complex and Diverse
- Impacts data collection
- Requires dedicated architectures
- Adoption by Scientists Requires Flexible Models and Quantitative Methods
The Challenges of Scientific Data
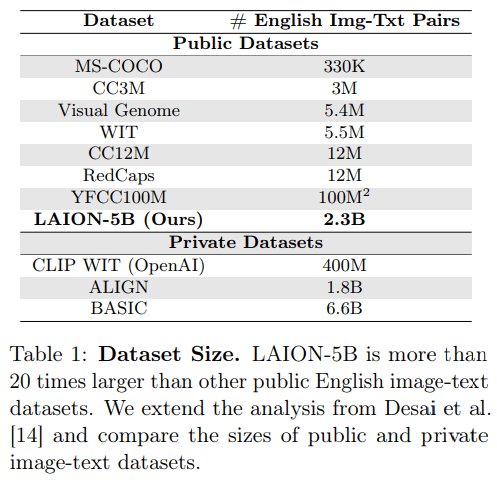
- Success of recent foundation models is driven by large corpora of uniform data (e.g LAION 5B).
- Scientific data comes with many additional challenges:
- Metadata matters
- Wide variety of measurements/observations
- Accessing and formatting data requires very specific expertise

Credit: Melchior et al. 2021


Credit:DESI collaboration/DESI Legacy Imaging Surveys/LBNL/DOE & KPNO/CTIO/NOIRLab/NSF/AURA/unWISE
AION-1
with extensive support from the rest of the team.










Project led by:
Francois
Lanusse
Liam
Parker
Jeff
Shen
Tom
Hehir
Ollie
Liu
Lucas
Meyer
Leopoldo
Sarra
Sebastian Wagner-Carena
Helen
Qu
Micah
Bowles
AstronomIcal Omnimodal Network

Presented at NeurIPS 2024 Datasets & Benchmark Track

The Multimodal Universe: Enabling Large-Scale Machine Learning with 100TBs of Astronomical Scientific Data

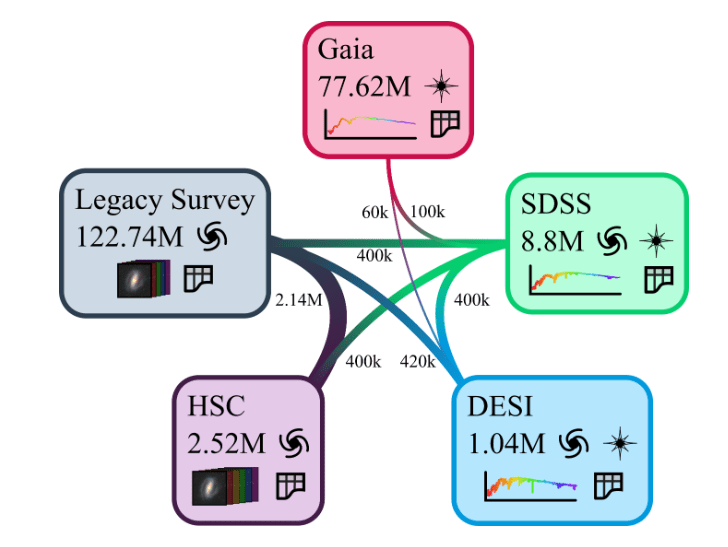
The MultiModal Universe Project
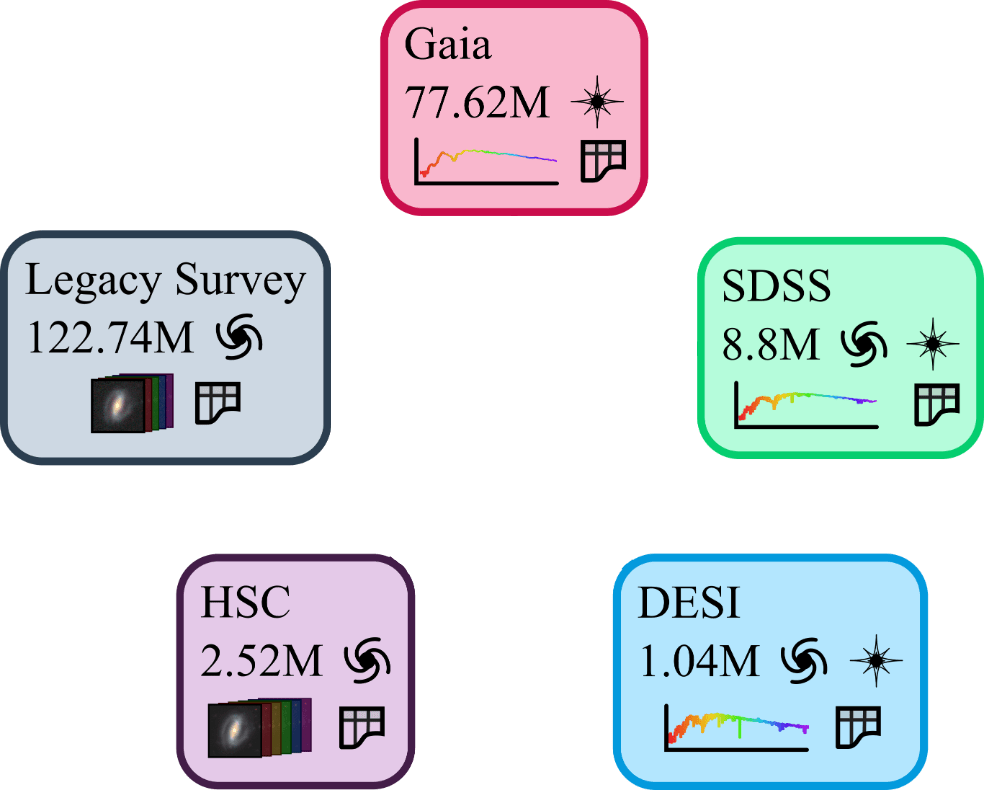
- Goal: Assemble the first large-scale multimodal dataset for machine learning in astrophysics.
-
Strategy:
- Engage with a broad community of AI+Astro experts.
- Target large astronomical surveys, varied types of instruments, many different astrophysics sub-fields.
- Adopt standardized conventions for storing and accessing data and metadata through mainstream tools (e.g. Hugging Face Datasets).



Ground-based imaging from Legacy Survey

Space-based imaging from JWST
AION-1: Diverse data modalities, diverse science cases

(Blanco Telescope and Dark Energy Camera.
Credit: Reidar Hahn/Fermi National Accelerator Laboratory)




(Subaru Telescope and Hyper Suprime Cam. Credit: NAOJ)



(Dark Energy Spectroscopic Instrument)

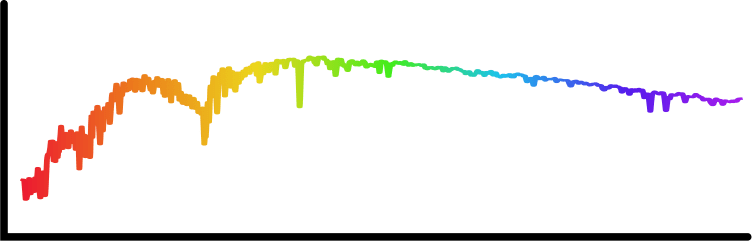

(Sloan Digital Sky Survey. Credit: SDSS)
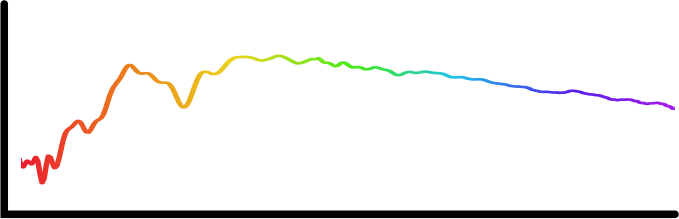
(Gaia Satellite. Credit: ESA/ATG)
- Galaxy formation
- Cosmology
- Stellar physics
- Galaxy archaeology
- ...
Standardizing all modalities through tokenization
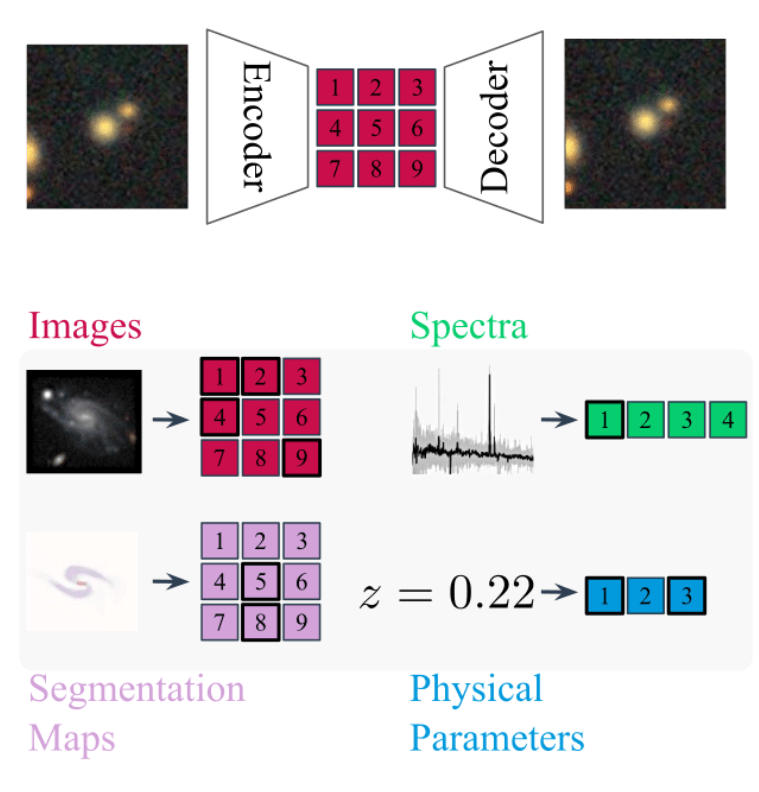
- For each modality class (e.g. image, spectrum) we build dedicated metadata-aware tokenizers
- For Aion-1, we integrate 39 different modalities (different instruments, different measurements, etc.)
\mathcal{L} = \parallel \Sigma^{- \frac{1}{2}} \left( x - d_\theta( \lfloor e_\theta(x) \rfloor_{\text{FSQ}} \right) \parallel_2^2
Field Embedding Strategy Developed for
Multiple Physics Pretraining (McCabe et al. 2023)

DES g
DES r
DES i
DES z
HSC g
HSC r
HSC i
HSC z
HSC y
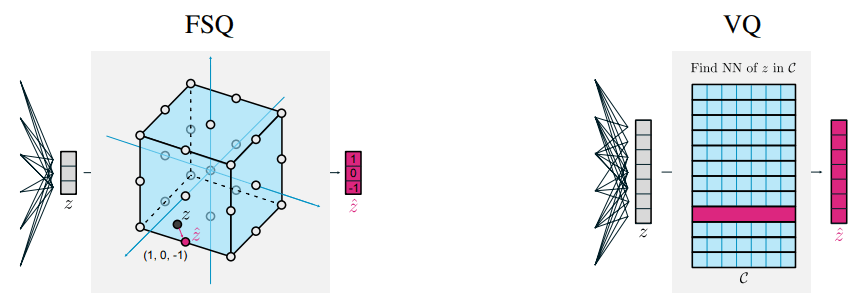

Any-to-Any Modeling with Generative Masked Modeling
- Training is done by pairing observations of the same objects from different instruments.
- Each input token is tagged with a modality embedding that specifies provenance metadata.
- Model is trained by cross-modal generative masked modeling (Mizrahi et al. 2023)
=> Learns the joint and all conditional distributions of provided modalities:
\forall m,n \quad p(x_m | x_n)
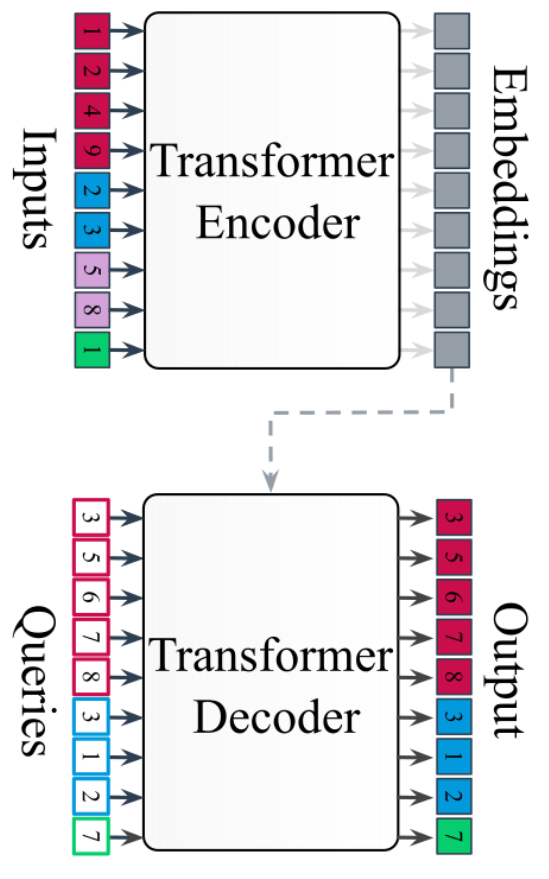
AION-1 family of models
- Models trained as part of the 2024 Jean Zay Grand Challenge, following an extension to a new partition of 1400 H100s
- AION-1 Base: 300 M parameters
- 64 H100s - 1.5 days
- AION-1 Large: 800 M parameters
- 100 H100s - 2.5 days
- AION-1 XLarge: 3B parameters
- 288 H100s - 3.5 days
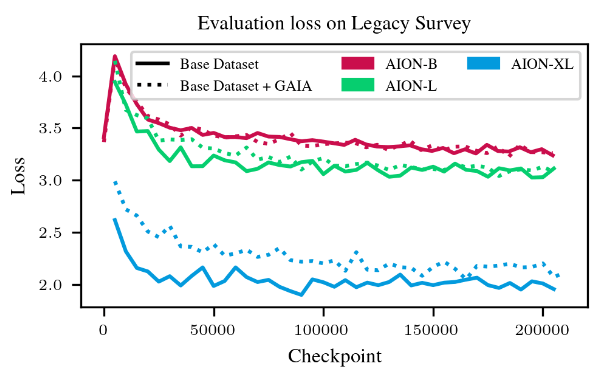


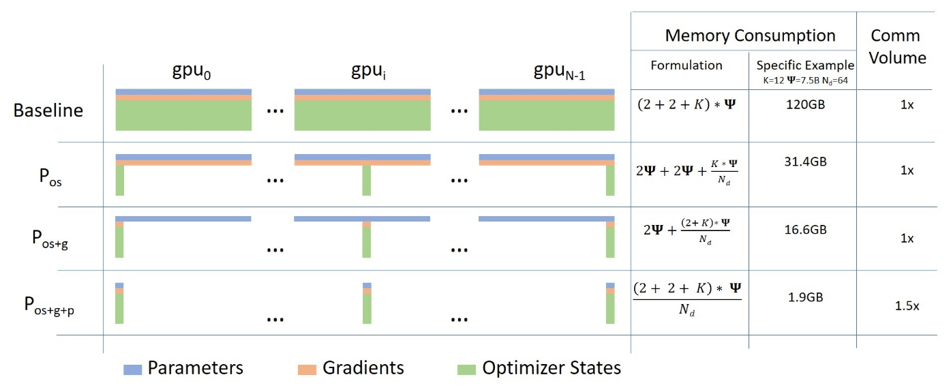
Technical details
(credit)
- Contrary to our surrogate models, we are working here on tokenized data
- Training based on pure torch Fully Sharded Data Parallel (FSDP) ZeRO Stage 2 for main models
- Stage 3 for 13B model

Example of out-of-the-box capabilities

Survey translation
p(\bm{x}_{HSC} | \bm{x}_{DES} )
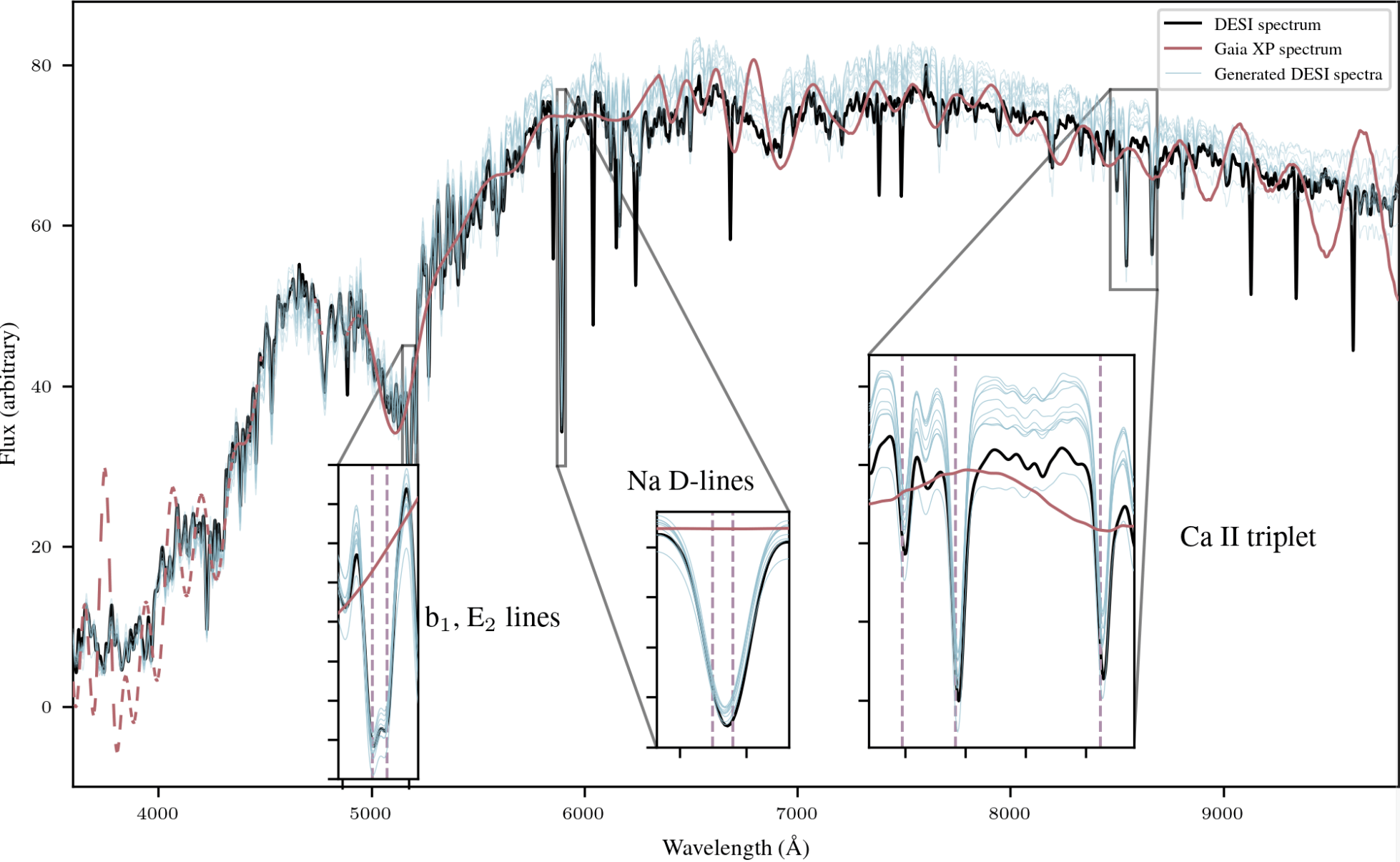
Spectrum super-resolution
p(\bm{x}_{DESI} | \bm{x}_{GAIA} )
Adaptation of AION-1 embeddings

Adaptation at low cost
with simple strategies:
- Mean pooling + linear probing
- Attentive pooling
y = \mathbf{M} \sum_i z_i
y = \operatorname{softmax} \left(\frac{\mathbf{Q} \mathbf{K}^\top(z)}{\sqrt{d}} \right) \mathbf{V}(z)
- Can be used trivially on any input data AION-1 was trained for
- Flexible to varying number/types of inputs
=> Allows for trivial data fusion
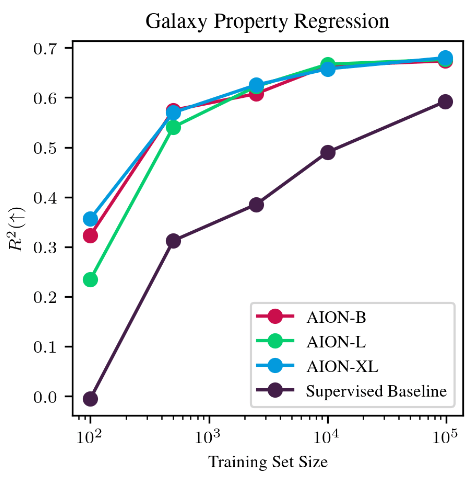
Morphology classification by Linear Probing
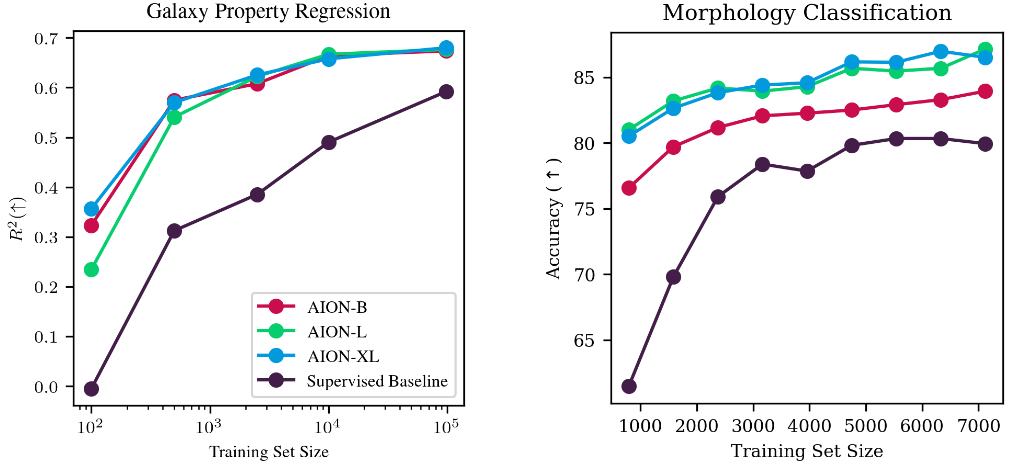


Trained on ->
Eval on ->
Physical parameter estimation and data fusion
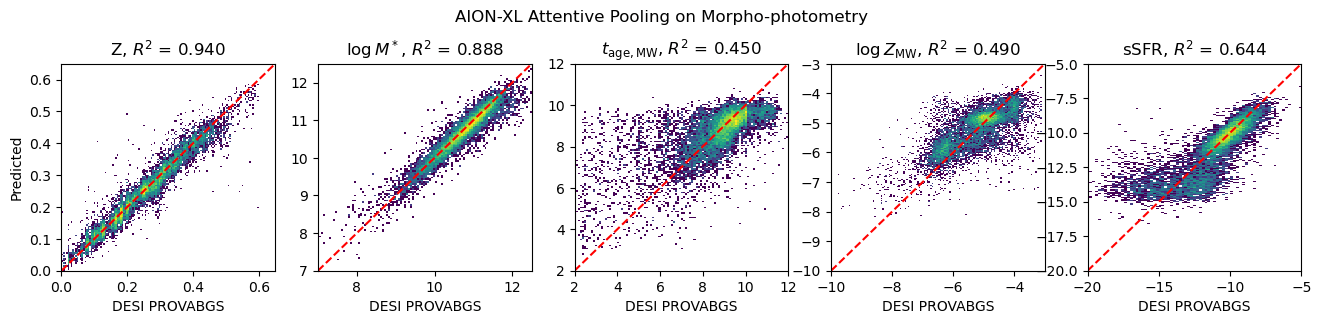
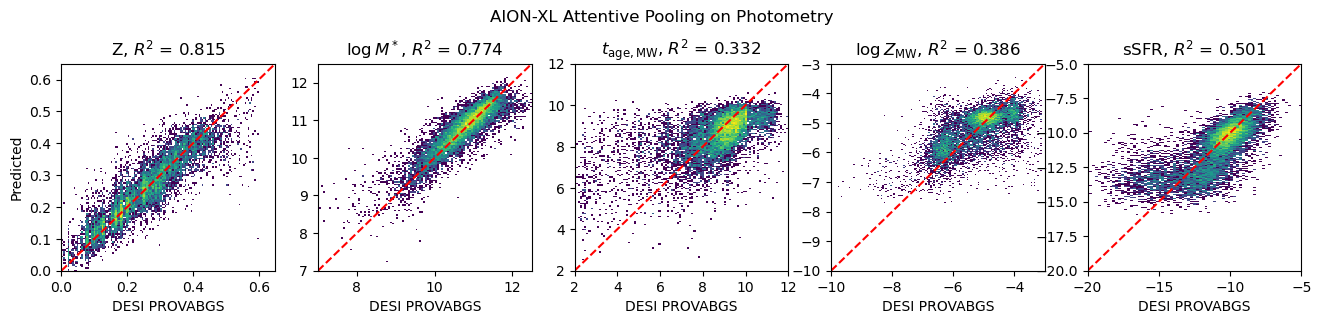
Inputs:
measured fluxes
Inputs:
measured fluxes + image
Semantic segmentation

Segmenting central bar and spiral arms in galaxy images based on Galaxy Zoo 3D
Example-based retrieval from mean pooling embeddings

Why are such Foundation Models useful for Scientists?
-
Never have to retrain my own neural networks from scratch
- Existing pre-trained models would already be near optimal, no matter the task at hand
-
Saves a lot of time and energy
- Practical large scale Deep Learning even in very few example regime
-
Searching for very rare objects in large astronomical surveys becomes possible
-
Searching for very rare objects in large astronomical surveys becomes possible
- If the information is embedded in a space where it becomes linearly accessible, very simple analysis tools are enough for downstream analysis
Polymathic's recipe for developing Multimodal Scientific Models
Takeaways



Engagement with Scientific Communities
Data Curation And Aggregation
Dedicated ML R&D
Follow us online!
Thank you for listening!
Pretraining Scientific Foundation Models
By eiffl




