

Igor Korotach
Head of FinTech at Quantum
Written by: Igor Korotach
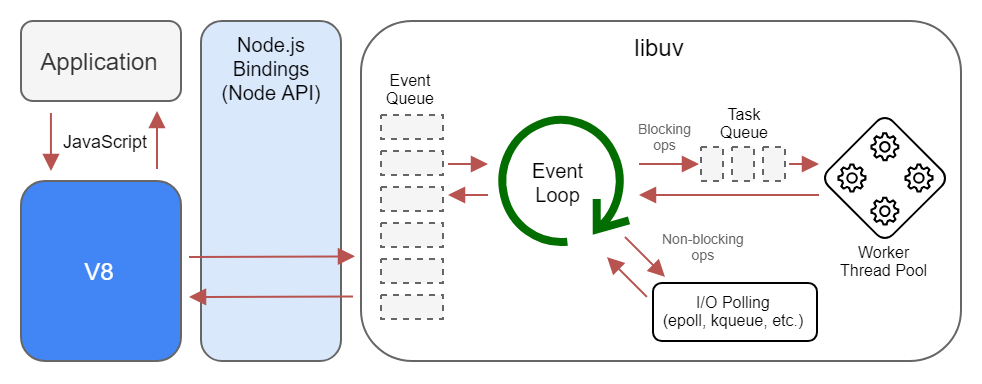
Node.js
Node.js
const { spawn } = require('child_process');
const child = spawn('wc');
process.stdin.pipe(child.stdin)
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`);
});Node.js
var cluster = require('cluster');
var http = require('http');
var numCPUs = 4;
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
http.createServer(function(req, res) {
res.writeHead(200);
res.end('process ' + process.pid + ' says hello!');
}).listen(8000);
}Node.js
const {
Worker,
isMainThread,
parentPort
workerData
} = require("worker_threads");
if (isMainThread) {
const worker = new Worker(__filename, {workerData: "hello"});
worker.on("message", msg => console.log(`Worker message received: ${msg}`));
worker.on("error", err => console.error(error));
worker.on("exit", code => console.log(`Worker exited with code ${code}.`));
}
else {
const data = workerData;
parentPort.postMessage(`You said \"${data}\".`);
}Node.js
const {parentPort, workerData} = require("worker_threads");
const sharp = require("sharp");
const {src, width, height} = workerData;
const [filename, ext] = src.split(".");
console.log(`Resizing ${src} to ${width}px wide`);
const resize = async () => {
await sharp(src)
.resize(width, height, {fit: "cover"})
.toFile(`${src}-${width}.${ext}`);
};
resize();const {Worker} = require("worker_threads");
const src = process.argv[2];
const sizes = [
{width: 1920},
{width: 1280},
{width: 640}
];
for (const size of sizes) {
const worker = new Worker(
__dirname + "/resize-worker.js",
{
workerData: {
src,
...size
}
}
);
}Browser
Browser
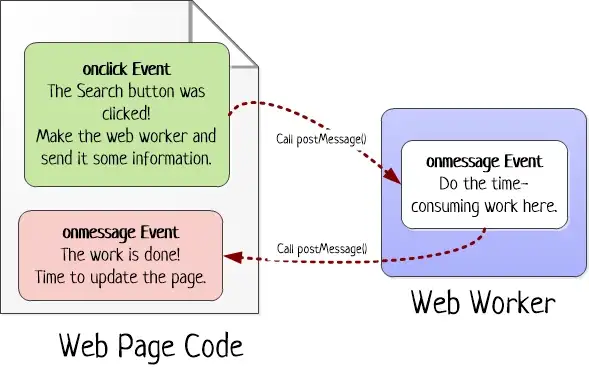
var worker;
function doSearch() {
// Disable the button, so the user can't start more than one search
// at the same time.
searchButton.disabled = true;
// Create the worker.
worker = new Worker("PrimeWorker.js");
// Hook up to the onMessage event, so you can receive messages
// from the worker.
worker.onmessage = receivedWorkerMessage;
// Get the number range, and send it to the web worker.
var fromNumber = document.getElementById("from").value;
var toNumber = document.getElementById("to").value;
worker.postMessage(
{ from: fromNumber,
to: toNumber }
);
// Let the user know that things are on their way.
statusDisplay.innerHTML = "A web worker is on the job ("+
fromNumber + " to " + toNumber + ") ...";
}Node.js
const {
parentPort,
} = require('worker_threads')
parentPort.on('message', (data) => {
const { arr } = data
console.log('modifying sharred array')
arr[0] = 1
arr[1] = 12
arr[2] = 2
parentPort.postMessage({})
})const { Worker } = require('worker_threads')
const sharedArrayBuffer = new SharedArrayBuffer(
Int32Array.BYTES_PER_ELEMENT * 3
);
const arr = new Int32Array(sharedArrayBuffer)
const worker1 = new Worker('./worker.js')
console.log('Original Shared Array')
console.log(arr)
worker1.on('message', (data) => {
console.log(arr)
})
worker1.postMessage({ arr })// Create a SharedArrayBuffer with a size in bytes
const buffer = new SharedArrayBuffer(16);
const uint8 = new Uint8Array(buffer);
uint8[0] = 7;
// 7 + 2 = 9
console.log(Atomics.add(uint8, 0, 2));
// Expected output: 7
console.log(Atomics.load(uint8, 0));
// Expected output: 9
// Create a SharedArrayBuffer with a size in bytes
const buffer = new SharedArrayBuffer(16);
const uint8 = new Uint8Array(buffer);
uint8[0] = 5;
Atomics.compareExchange(uint8, 0, 5, 2); // Returns 5
console.log(Atomics.load(uint8, 0));
// Expected output: 2
Atomics.compareExchange(uint8, 0, 5, 4); // Returns 2
console.log(Atomics.load(uint8, 0));
// Expected output: 2
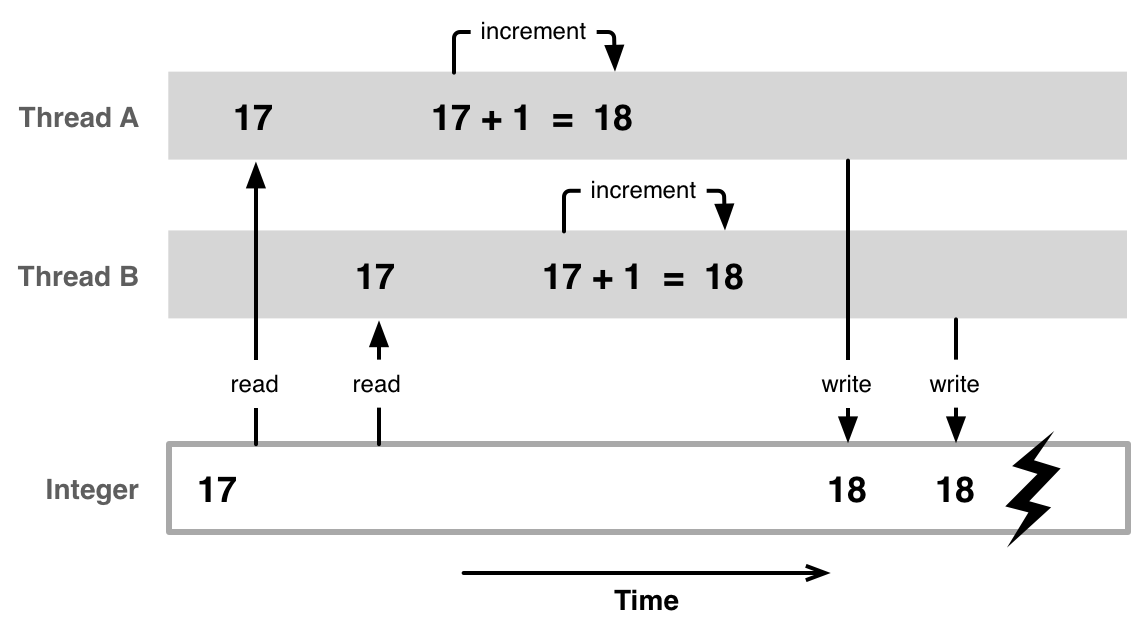
Async context classes are used to associate state and propagate it throughout callbacks and promise chains. They allow storing data throughout the lifetime of a web request or any other asynchronous duration. It is similar to thread-local storage in other languages.
The AsyncLocalStorage and AsyncResource classes are part of the node:async_hooks module:
const app = express();
const log = message => console.log(message);
const emailService = new EmailService(logger);
app.get('/', (request, response) => {
const requestId = uuid();
log(`[${requestId}] Start processing`);
await emailService.notify(
request.body.emails, requestId
);
response.writeHead(200);
});class EmailService {
constructor (log) {
this.log = log;
}
// requestId doesn't belong to
// this function logically
async notify (emails, requestId) {
for (const email of emails) {
this.log(`[${requestId}]
Send email: ${email}`);
sendGrid.send(email);
}
}
}Controller code
Service code
const { AsyncLocalStorage } = require(
'async_hooks'
);
const asyncLocalStorage = new AsyncLocalStorage();
app.get('/', (request, response) => {
const requestId = uuid();
asyncLocalStorage.run(requestId, async () => {
// entering asynchronous context
log('Start processing')
await emailService.notify(request.body.emails);
response.writeHead(200);
});
});const log = message => {
const requestId = asyncLocalStorage.getStore();
if (requestId) {
console.log(`[${requestId}] ${message}`);
}
else {
console.log(message);
}
};Controller code
Logger code
By Igor Korotach




