

Igor Korotach
Head of FinTech at Quantum
Written by: Igor Korotach
Instagram is a free photo and video sharing app available on iPhone and Android. People can upload photos or videos to our service and share them with their followers or with a select group of friends. They can also view, comment and like posts shared by their friends on Instagram.
The 2 billion MAUs made Instagram the 4th largest social network worldwide, with 37.74% of the world’s 5.3 billion internet users accessing the app monthly.
February 2013: Instagram hit 100 million users (MAU)
June 2016: Instagram hit 500 million users (MAU)
June 2018: Instagram hit 1 billion users (MAU)
October 2022: Instagram hit 2 billion users (MAU)
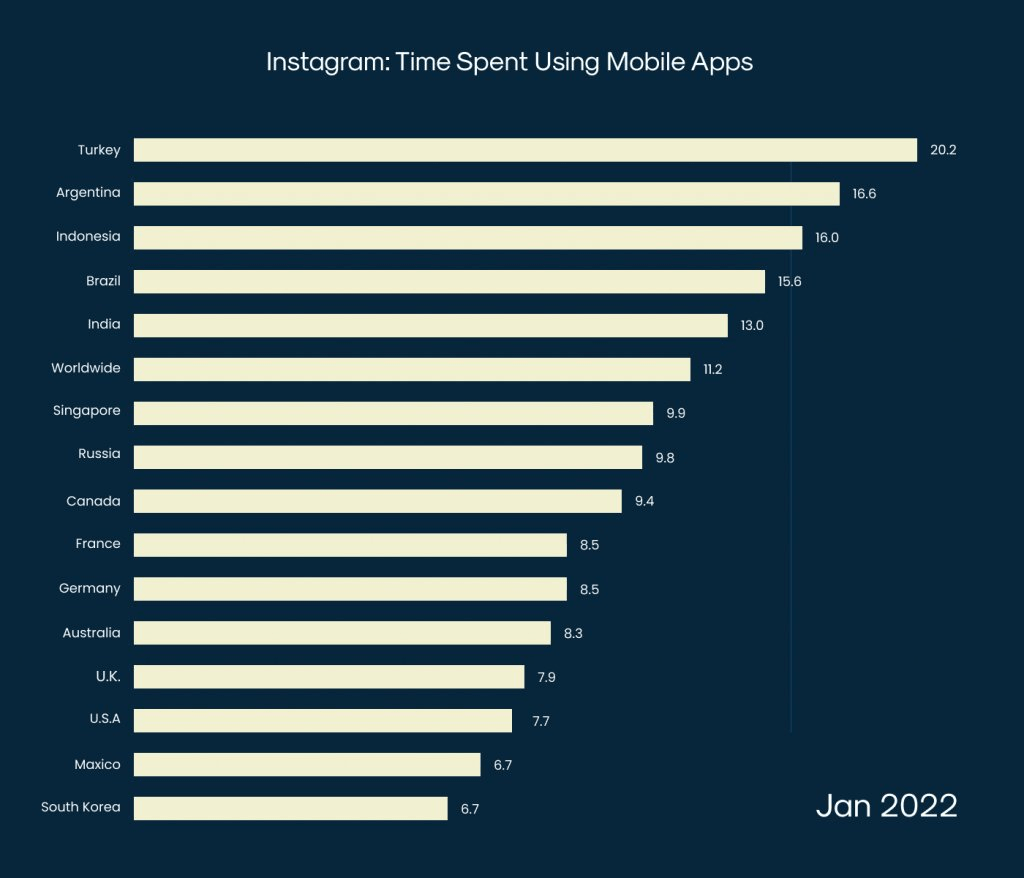
Right now, the country with the largest addressable Instagram ad audience size is in India (229.55 million), followed by the United States (143.35 million) and Brazil (113.5 million).
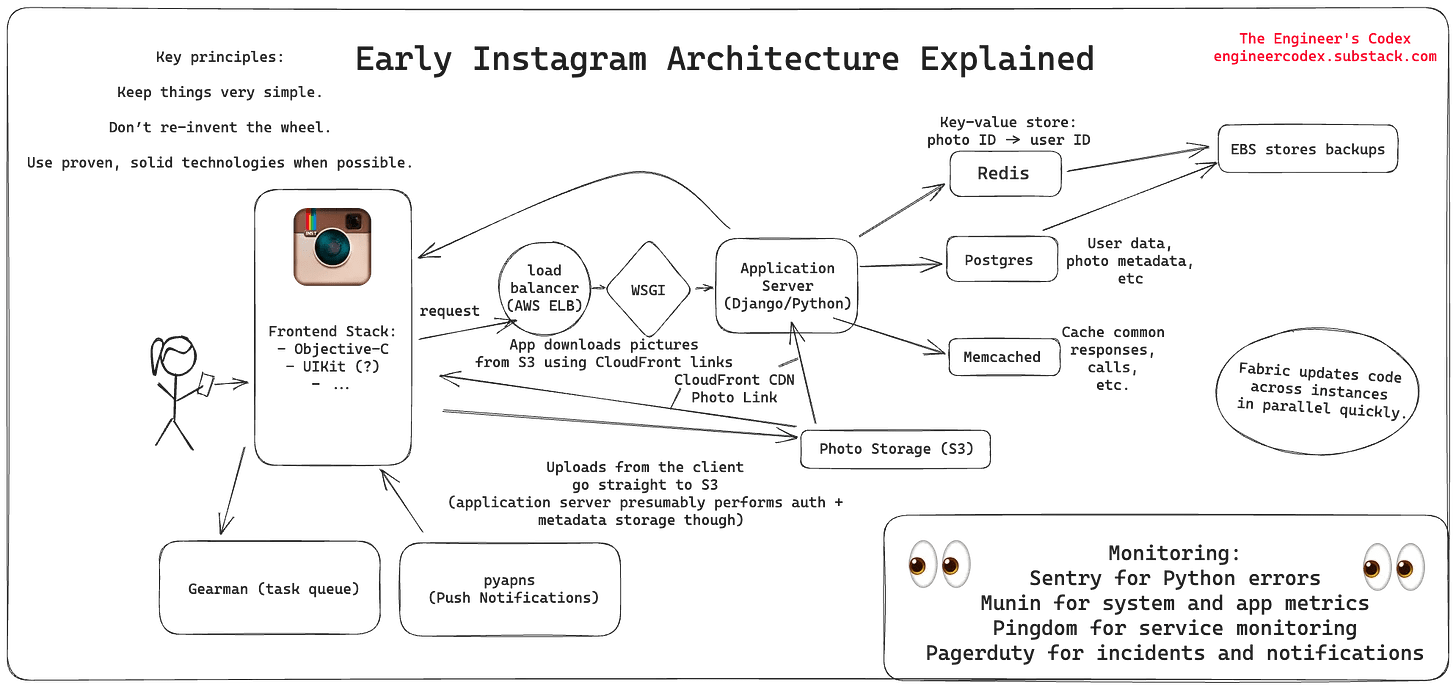
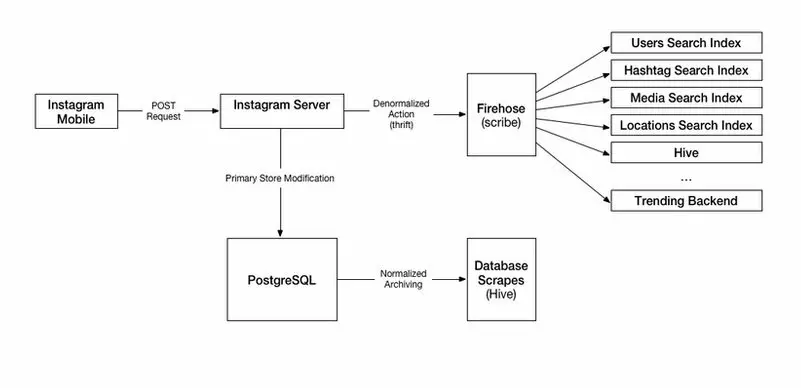
Session: The application server grabs the latest relevant photo IDs from Postgres.
The application server would pull data from PostgreSQL, which stored most of Instagram’s data, such as users and photo metadata.
The connections between Postgres and Django were pooled using Pgbouncer.
Instagram sharded their data because of the volume they were receiving (over 25 photos and 90 likes a second). They used code to map several thousand ‘logical’ shards to a few physical shards.
An interesting challenge that Instagram faced and solved is generating IDs that could be sorted by time. Their resulting sortable-by-time IDs looked like this:
41 bits for time in milliseconds (gives us 41 years of IDs with a custom epoch)
13 bits that represent the logical shard ID
10 bits that represent an auto-incrementing sequence, modulus 1024. This means we can generate 1024 IDs, per shard, per millisecond
Thanks to the sortable-by-time IDs in Postgres, the application server has successfully received the latest relevant photo IDs.
Source: https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c
PostgreSQL is still the primary database of the application, it stores most of the data of the platform such as user data, tags, meta-tags, etc.
The main database cluster of Instagram contains 12 replicas in different zones and involves 12 Quadruple extra large memory instances.
Hive is used for data archiving. It’s a data warehousing software built on top of Apache Hadoop for data query and analytics capabilities. A scheduled batch process runs at regular intervals to archive data from PostgreSQL DB to Hive.
Vmtouch is used to manage in-memory data when moving from one machine to another.
Cassandra is used for analytics data storage.
Redis & Memcached are still used for caching
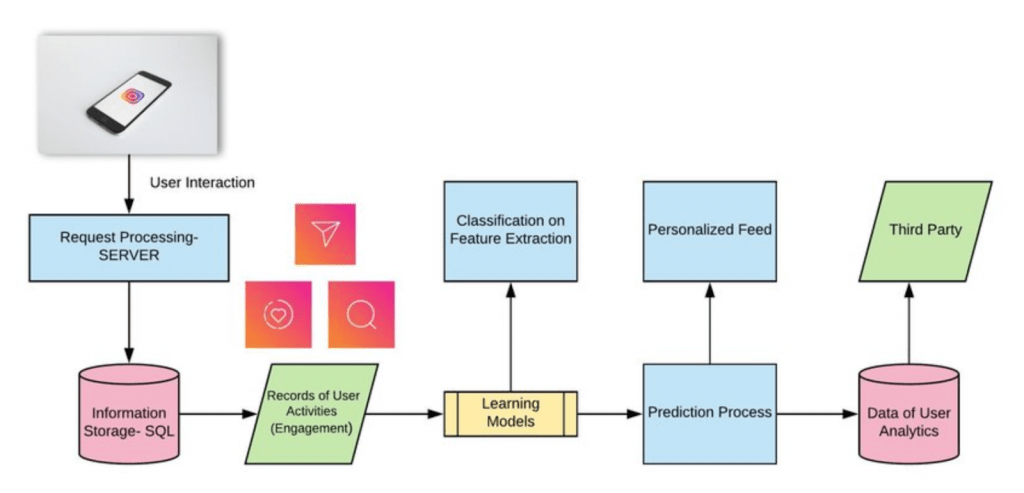
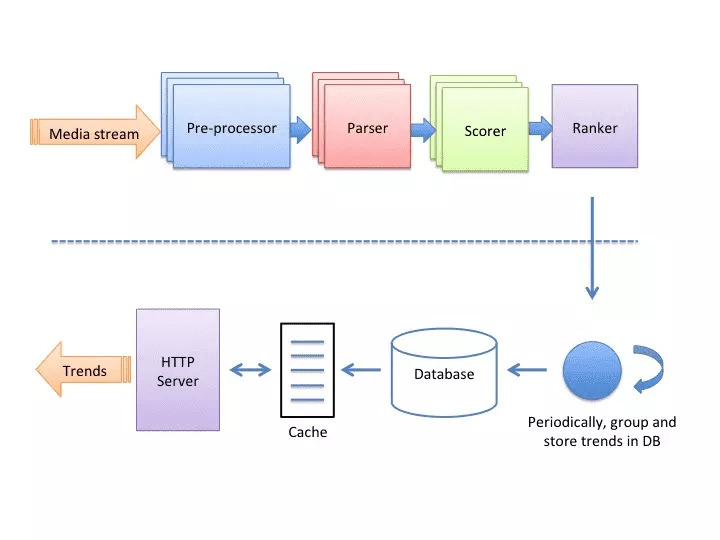
Pre-processor Node
The pre-processor node attaches the necessary data needed to apply filters on the original media that has metadata attached to it.
Parser Node
The parser node extracts all the hashtags attached to an image and applies filters to it.
Scorer Node
The scorer node keeps track of the counters for each hashtag based on time. All the counter data is kept in the cache, also persisted for durability.
Ranker Node
The role of the ranker node is to compute the trending scores of hashtags. The trends are served from a read-through cache that is Memcache and the database is Postgres.
Instagram initially used Elasticsearch for its search feature but later migrated to Unicorn, a social graph-aware search engine built by Facebook in-house.
I will quote the instagram guiding design principles as a basis for their architecture.
Instagram’s Guiding Principles:
https://scaleyourapp.com/facebook-real-time-chat-architecture-scaling-with-over-multi-billion-messages-daily/
https://instagram-engineering.com/
https://engineering.fb.com/tag/instagram/
https://engineering.fb.com/2023/08/15/developer-tools/immortal-objects-for-python-instagram-meta/
https://engineering.fb.com/2023/08/09/ml-applications/scaling-instagram-explore-recommendations-system/
Presentation link: https://slides.com/emulebest/quantum-architecture-course-instagram
By Igor Korotach




