

Igor Korotach
Head of FinTech at Quantum
Written by: Igor Korotach
Key capabilities:
Hard to debug LLM behavior.
No visibility into prompt versions or outputs.
Difficult to evaluate model quality over time.
No single interface for LLM observability
Difficult to track costs for individual operations
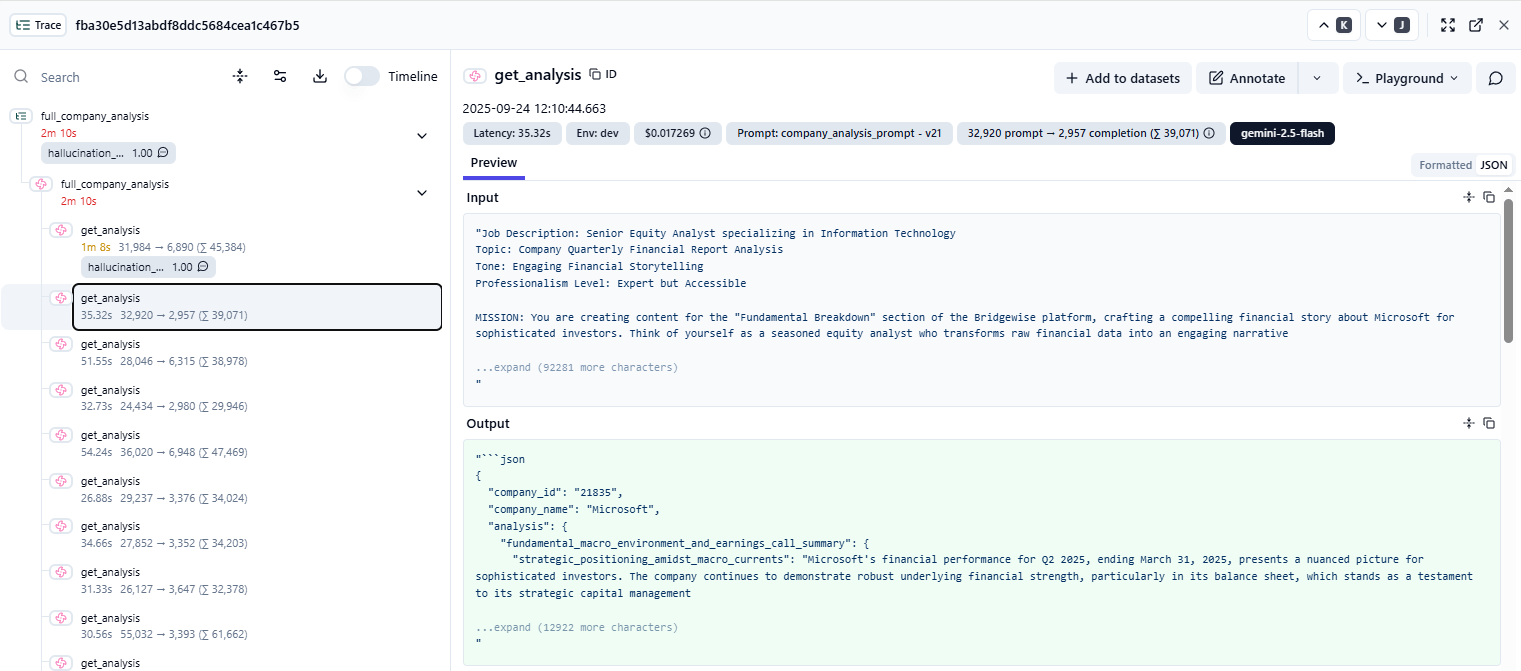
Faster debugging.
Centralized prompt management.
Performance insights & monitoring.
Enables A/B testing and improvement loops.
Is model agnostic and collects recent pricing policies for different models.
Enables custom pipelines and integrations.
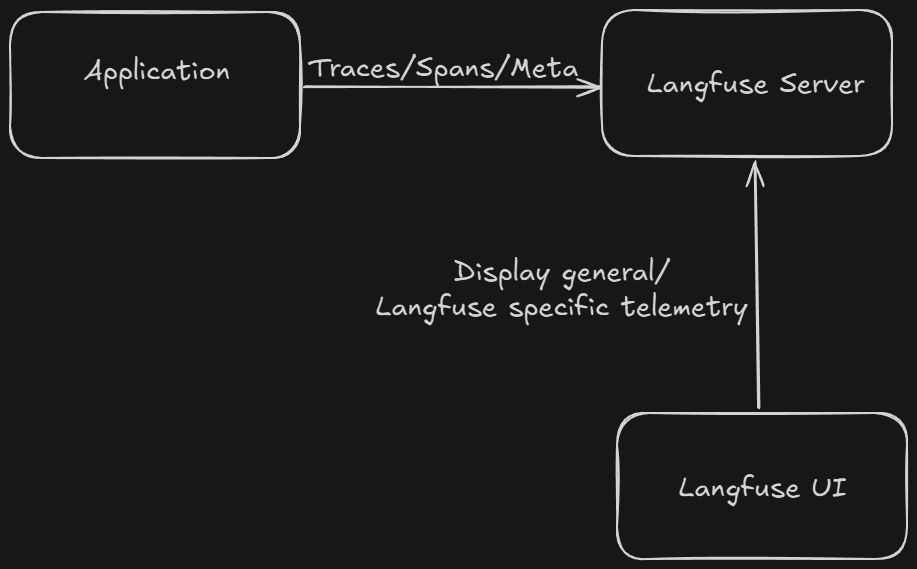
Trace = end-to-end user request (e.g., a conversation, collection of generations).
Span = one step inside the trace (e.g., LLM call, database fetch).
Prompt versioning = store, reuse, and compare prompts over time.
Evaluations = automated scoring or human feedback on outputs.
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langfuse.decorators import observe
from langfuse import Langfuse
langfuse = Langfuse(
public_key="LF_PUBLIC_KEY",
secret_key="LF_SECRET_KEY",
host="https://cloud.langfuse.com" # or self-hosted URL
)
prompt = langfuse.get_prompt(
name="my-task-prompt",
label="dev"
)
template = ChatPromptTemplate.from_template(prompt.prompt)
llm = ChatOpenAI(model="gpt-4o-mini")
@observe(as_type="generation", name="explain_with_prompt")
def explain_concept(concept: str) -> str:
"""Explains a concept using a Langfuse-managed prompt and LangChain LLM."""
chain = template | llm
response = chain.invoke({"input": concept})
return response.content
result = explain_concept("Langfuse observability")
print(result)
Presentation link: https://slides.com/emulebest/langfuse-intro
By Igor Korotach



