











Igor Korotach
Head of FinTech at Quantum
Written by: Igor Korotach
LangChain is an open-source framework designed to simplify the development of applications powered by large language models (LLMs). It enables LLMs to connect with external data sources and interact with their environment, making it easier to build complex, data-responsive applications like chatbots, question-answering systems, agent systems and content generators.
# 1. Load document
loader = TextLoader("annual_report.txt")
documents = loader.load()
# 2. Split document into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 3. Create embeddings and store in a vector database
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(docs, embeddings)
# 4. Create a retriever
retriever = db.as_retriever()
# 5. Set up the RetrievalQA chain
qa_chain = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
# Ask a question
query = "What were the company's revenues in the last fiscal year?"
response = qa_chain.invoke({"query": query})
print(response["result"])Orchestration and Chaining: Allows developers to chain together various components (LLMs, prompt templates, tools, agents) to create more sophisticated workflows.
External Data Integration: Facilitates connecting LLMs to external data sources (e.g., databases, APIs, web search) to provide up-to-date and contextual information, overcoming the "cutoff date" limitation of LLMs.
Community Packages: offers a wide range of plug'n'play integrations for tools ranging from search engines (e.g. Tavily) to embeddings and vector databases
Universal interface: Langchain supports most of the popular models out of the box through a single interface making them interchangable
Sync & Async interface
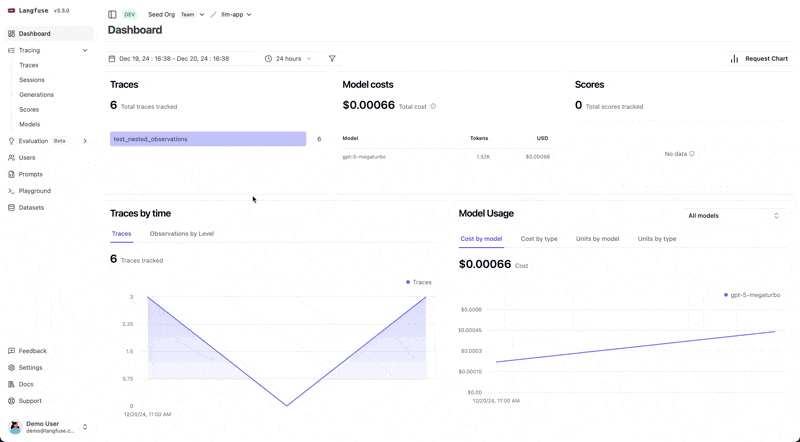
Langfuse is an open-source LLM engineering platform designed to help teams collaboratively debug, analyze, and iterate on their LLM applications. It provides observability, analytics, prompt management and experimentation features for LLM workflows.
# Get current production version of the prompt from Langfuse
langfuse_prompt = langfuse.get_prompt("event-planner")
prompt_template = PromptTemplate.from_template(langfuse_prompt.prompt) # Adapt to LangChain format
llm = OpenAI(temperature=0.7)
chain = LLMChain(llm=llm, prompt=prompt_template)
# Invoke the chain and send traces to Langfuse
example_input = {
"Event Name": "AI Conference 2025",
"Event Description": "A conference showcasing the latest in AI research and applications.",
"Location": "London",
"Date": "October 20-22, 2025"
}
response = chain.invoke(input=example_input, config={"callbacks": [langfuse_callback_handler]})
print(response.content)
# You would then view the trace and prompt details in the Langfuse UIObservability and Debugging: Offers real-time dashboards to monitor token usage, latency, error rates, and costs, enabling quick identification and resolution of issues in LLM interactions.
Prompt Management and Versioning: Facilitates managing and iterating on prompts with version control, allowing teams to store, reuse, and collaboratively edit prompts.
Performance Monitoring and Cost Analysis: Provides in-depth insights into prompt effectiveness and system behavior, including detailed cost tracking.
Automated Evaluation: Supports automated LLM-as-a-judge evaluation methods, integrated with an interactive playground for rapid prototyping and experimentation.
Collaboration: Designed for teams to work together on LLM application development.
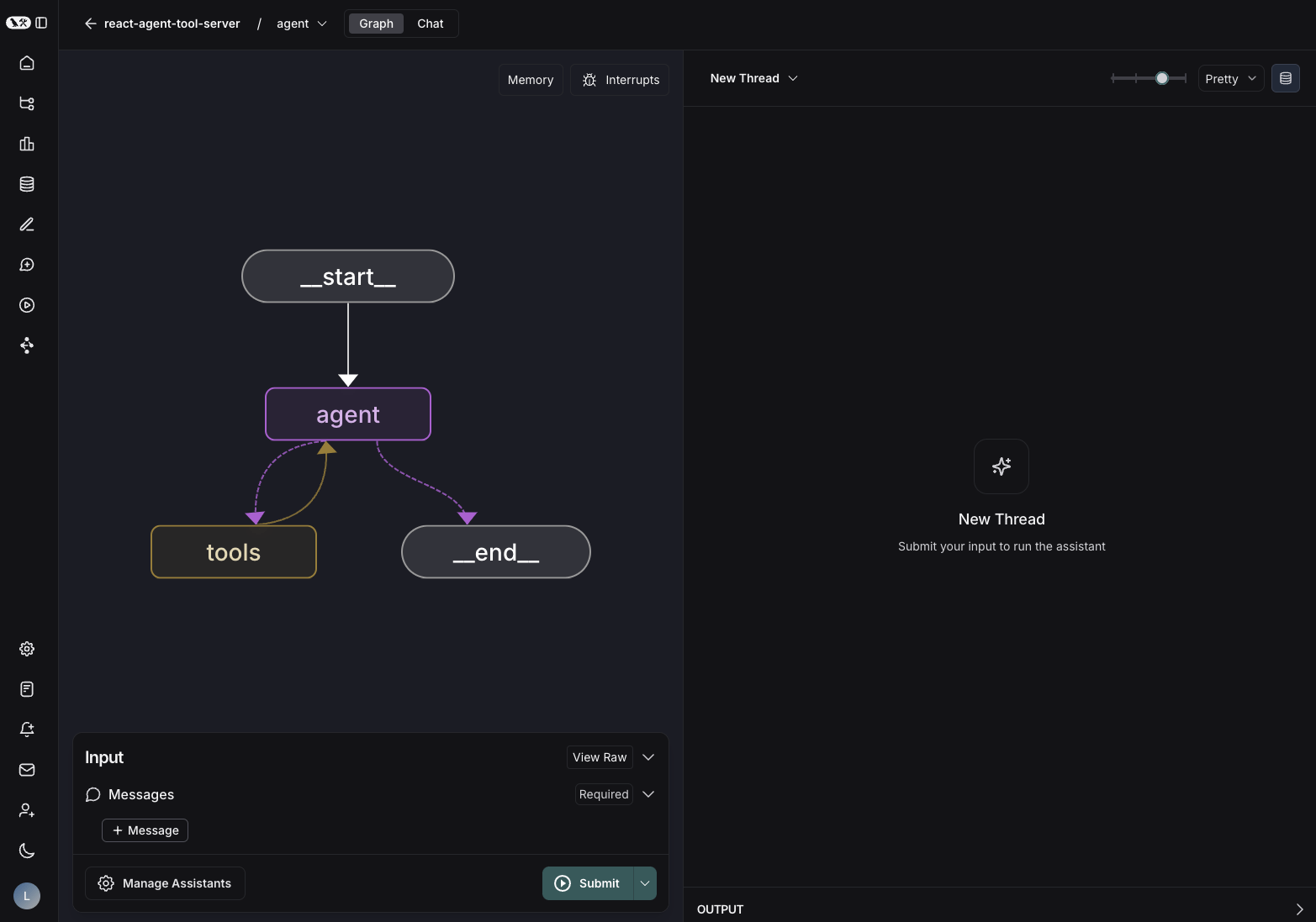
LangGraph is an extension of the LangChain framework specifically designed to build stateful, multi-actor applications with LLMs. While LangChain excels at chaining together linear sequences of LLM calls and tools, LangGraph focuses on orchestrating more complex, cyclical, and dynamic workflows. It models these workflows as directed graphs, where nodes represent individual components (LLMs, tools, custom code) and edges define the transitions between them, allowing for loops, conditional logic, and shared state.
User Input
|
V
[Planner Agent] --(if needs search)--> [Search Tool]
^ |
| V
(if needs refinement) <--- [Critique/Refinement Agent] <-- [Information Extractor Agent]
| |
|--(if sufficient)--------------------|
V
[Answer Synthesis Agent]
|
V
Final Answer to UserComplex Workflow Orchestration: Enables the creation of intricate, multi-step AI workflows with branching logic, loops, and conditional routing, essential for sophisticated agents.
State Management: Provides robust, built-in state management, allowing information and context to be seamlessly passed and updated between different nodes (agents/steps) within a long-running conversation or task. This is critical for agents that "remember" previous interactions.
Multi-Agent Systems: Facilitates the creation of systems where multiple specialized LLM agents can collaborate and communicate to solve a complex problem, mimicking human-like problem-solving (e.g., a "researcher" agent feeding findings to a "writer" agent).
Human-in-the-Loop (HITL): Supports pausing a workflow for human intervention (e.g., review, approval, correction) before resuming execution.
| Alternative | |||
|---|---|---|---|
| Framework | LangChain | LangSmith | LangGraph |
| Haystack | LangFuse | Haystack | |
| Lunary.ai | CrewAI | ||
| Helicone |
Perplexity AI is a conversational answer engine that leverages large language models and real-time web search to provide direct, cited answers to user queries. Its core aim is to offer a more informative and less navigational search experience compared to traditional search engines.
from langchain_core.prompts import ChatPromptTemplate
from langchain_perplexity import ChatPerplexity
chat = ChatPerplexity(temperature=0, pplx_api_key="YOUR_API_KEY", model="sonar")
system = "You are a helpful assistant."
human = "{input}"
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", human)])
chain = prompt | chat
response = chain.invoke({"input": "Why is the Higgs Boson important?"})
response.content
# Structured example
class AnswerFormat(BaseModel):
first_name: str
last_name: str
year_of_birth: int
num_seasons_in_nba: int
chat = ChatPerplexity(temperature=0.7, model="sonar-pro")
structured_chat = chat.with_structured_output(AnswerFormat)
response = structured_chat.invoke(
"Tell me about Michael Jordan. Return your answer "
"as JSON with keys first_name (str), last_name (str), "
"year_of_birth (int), and num_seasons_in_nba (int)."
)
responseDirect Answers with Sources: Synthesizes information from multiple web sources and provides a concise answer along with citations, allowing users to verify the information.
Real-time Information: Incorporates current internet content, making its responses highly relevant and up-to-date. This inherently eliminates the knowledge date cut-off problem for LLMs.
Conversational Interface: Allows for follow-up questions and refined queries in a natural language format.
Focus Mode: Offers "Focus" modes (e.g., Academic, Wolfram|Alpha, YouTube) to tailor searches to specific types of information.
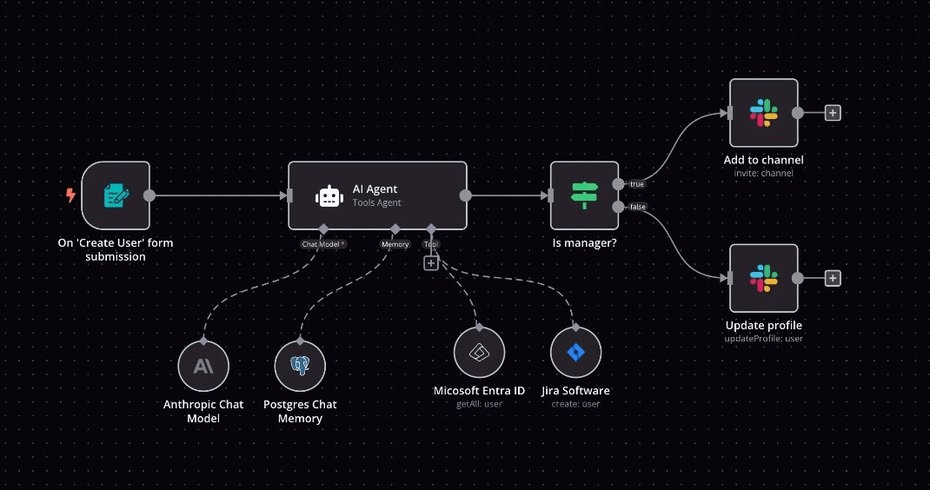
n8n (pronounced "n-eight-n") is a powerful, open-source workflow automation tool. Its core aim is to allow users to automate tasks, integrate different applications and services, and build complex workflows without writing much code (low-code/no-code). In the context of AI, n8n is fantastic for orchestrating LLM calls, connecting them to various data sources, and automating post-processing or actions based on LLM outputs.
Workflow Automation: Enables the creation of sophisticated, multi-step workflows that can trigger actions based on events or schedules.
Extensive Integrations: Offers a vast library of pre-built integrations (nodes) for popular web services, databases, messaging apps, and custom APIs, including those for LLMs (e.g., OpenAI, Hugging Face).
Low-Code/No-Code: Provides a visual, drag-and-drop interface for building workflows, making it accessible to users without deep programming knowledge. For more complex logic, JavaScript can be used within custom code nodes.
Self-Hostable and Cloud Options: Can be self-hosted for greater control and privacy, or used via their cloud service.
Data Transformation: Powerful capabilities for manipulating and transforming data between different steps in a workflow.
Event-Driven: Can react to webhooks, schedules, or database changes, allowing for real-time automation.
LlamaIndex is a data framework for LLM applications. Its core purpose is to help developers ingest, structure, and access private or domain-specific data so that LLMs can accurately answer questions and perform tasks based on that data. It acts as a bridge between your data and LLMs.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.embeddings import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
# 1. Load documents from a directory
documents = SimpleDirectoryReader("my_company_docs/").load_data()
# 2. Create an index from the documents
# Uses OpenAIEmbeddings by default, but can be configured
index = VectorStoreIndex.from_documents(documents)
# 3. Create a query engine
query_engine = index.as_query_engine(llm=OpenAI())
# Query the data
response = query_engine.query("What are the company's sick leave policies?")
print(response)Data Ingestion and Indexing: Simplifies connecting LLMs to various data sources (PDFs, Notion, Google Docs, databases, etc.) and creating searchable "indexes" (like vector stores) from that data.
Querying and Retrieval: Optimizes the process of retrieving relevant information from your custom data to feed into LLMs, making responses more accurate and grounded.
Flexible Data Connectors: Offers a wide range of pre-built data loaders for diverse data types and formats.
Abstracted Complexity: Provides a high-level API to manage the entire data pipeline for LLMs, abstracting away the complexities of chunking, embedding, and retrieval.
The Model Context Protocol (MCP) is an open standard and open-source framework introduced by Anthropic. Its primary aim is to standardize how AI systems (especially LLMs) integrate and share data with external tools, systems, and data sources. It acts as a universal "API for tools," allowing LLMs to discover and use tools in a standardized way.
(Highly conceptual example, actual MCP implementation involves servers, clients, and tool definitions)
Imagine an MCP "Weather Server" exposing a "get_current_weather" tool.
An AI Agent (Client) makes a request in MCP's standardized JSON format:
Agent's MCP Tool Call Request (JSON):
{
"tool_name": "get_current_weather",
"parameters": {
"city": "Paris",
"unit": "celsius"
}
}
The MCP Client (e.g., an LLM application) sends this request to the MCP Weather Server.
The Weather Server executes the underlying code for 'get_current_weather' and returns a response.
MCP Weather Server's Response (JSON):
{
"result": {
"temperature": 25,
"unit": "celsius",
"condition": "Sunny"
},
"status": "success"
}
The AI Agent then receives this structured response and can incorporate it into its answer or next action.Overcoming LLM Limitations: Enables LLMs to access real-time information, perform concrete actions via tools, and overcome context window limits by dynamically fetching external information.
Standardization and Interoperability: Creates a standardized ecosystem where tools developed for one project can be easily shared and used by any compatible MCP client. This fosters collaboration and wider adoption of tools.
Finer-grained Security: Natively integrates robust security mechanisms like connection isolation and granular permissions, giving users more control over AI model actions and data access.
Democratization of Tool Access: Makes it easier for AI agents to discover and utilize a wide range of tools, from web search to internal APIs.
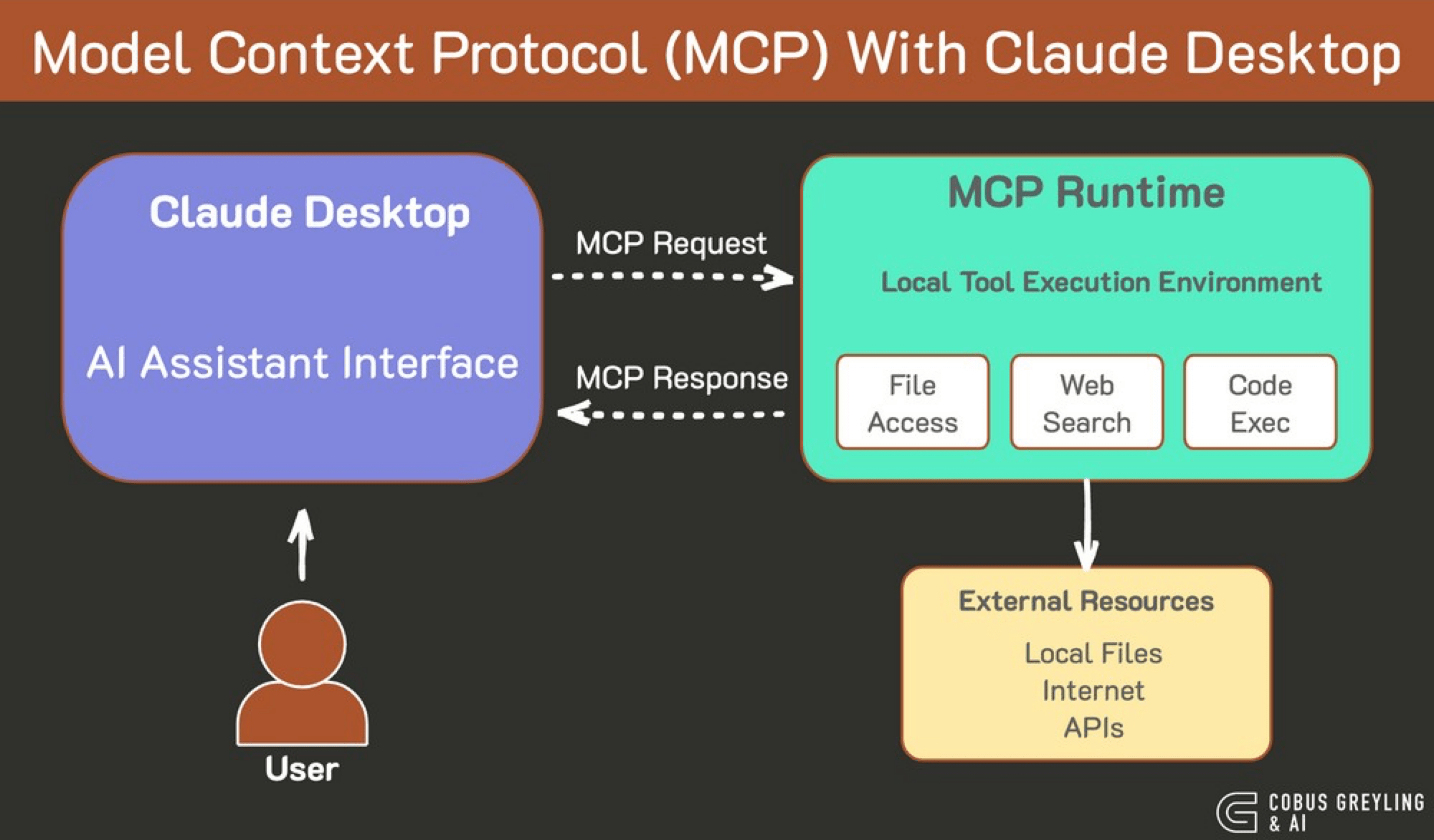
Claude Desktop is a dedicated desktop application (for Windows and macOS) that brings the power of Claude AI directly to your computer. Beyond being a standard chatbot, its key aim is to enable Claude to interact with your local files and applications through the Model Context Protocol (MCP), providing a more integrated and powerful AI assistant experience for a wide range of tasks, including file management, data analysis, and advanced research.
Local File System Interaction: Enables Claude to browse, read, and even manage files directly on your computer (e.g., summarizing PDFs, analyzing CSVs, writing content into documents).
Enhanced Context: Through MCP, Claude can access real-time information from the internet and integrate with various local applications and data sources, providing highly informed responses.
Streamlined Workflows: Reduces the need to switch between applications or copy-paste content, as Claude can directly interact with your desktop environment.
Computer Use (Beta): Newer features allow Claude to perform tasks like moving the cursor, clicking buttons, and typing text, mimicking human-computer interactions for automation.
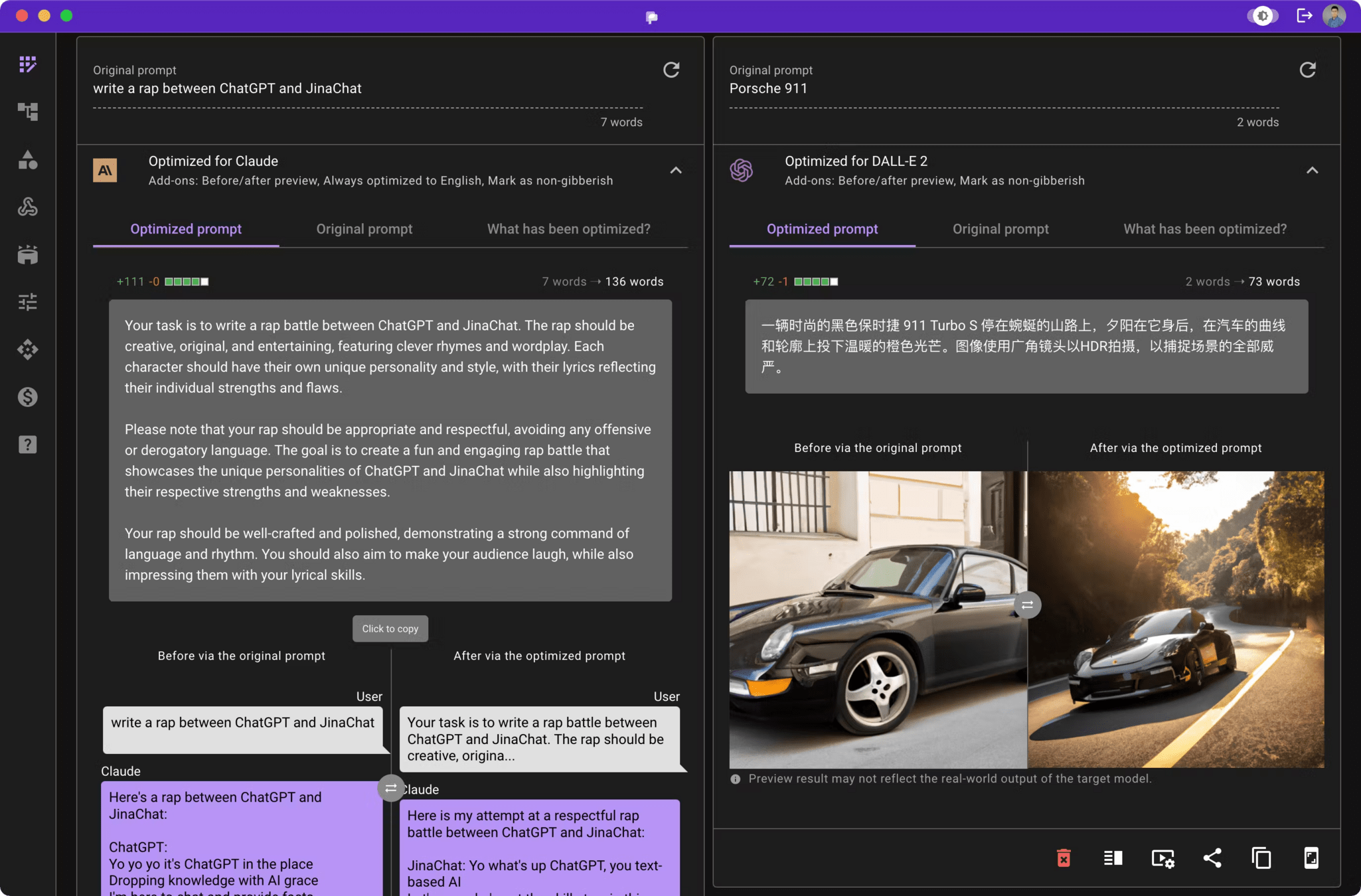
PromptPerfect is a tool specifically designed for prompt optimization. Its aim is to automatically refine and improve prompts given to large language models to elicit better, more accurate, and more consistent outputs. It essentially takes a "raw" prompt and attempts to make it more effective.
Automated Prompt Refinement: Uses AI techniques to automatically rewrite or enhance prompts for optimal performance.
Improved Output Quality: Helps achieve more coherent, relevant, and accurate responses from LLMs.
Time-Saving: Reduces the manual effort and trial-and-error involved in prompt engineering.
Multi-Modal Support: Can optimize prompts for both text-based and image-based generative AI models.
Consistency: Aims to make LLM responses more consistent across different queries.
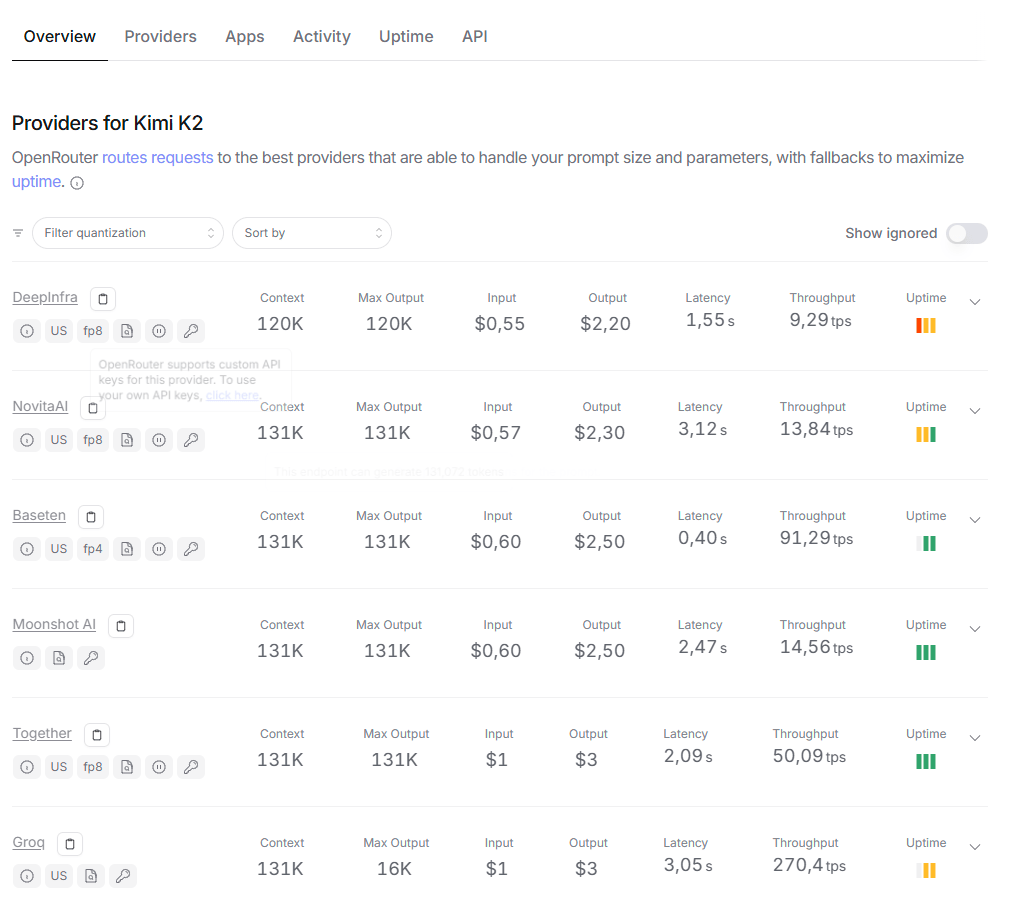
OpenRouter is a unified API gateway and marketplace for Large Language Models (LLMs). Its primary aim is to simplify the process for developers to access, compare, and switch between a vast array of LLMs from different providers (e.g., OpenAI, Anthropic, Mistral, Google, Meta, various open-source models) through a single, standardized API endpoint. It acts as an intermediary layer, abstracting away the complexities of multiple APIs, varying pricing structures, and ensuring model availability.
Unified API Access: Provides a single, OpenAI-compatible API endpoint to interact with hundreds of different LLMs, eliminating the need to manage multiple API keys, client libraries, and integration logic.
Cost & Performance Optimization: Often helps developers find the best price-to-performance ratio by allowing easy comparison of token pricing, latency, and throughput across various models. They can also offer unique pricing or access to models not easily available elsewhere.
Enhanced Reliability & Fallbacks: By routing requests through OpenRouter, developers can implement automatic fallbacks to alternative models or providers if a primary model experiences downtime or rate limits, improving application uptime.
Access to Emerging Models: Provides quick access to newly released and open-source models, often making them available faster than direct integrations with individual providers.
Consolidated Billing & Analytics: Simplifies billing by providing a single invoice for usage across all models. Offers a dashboard for monitoring usage, costs, and performance metrics.
Presentation link: https://slides.com/emulebest/ai-tools
By Igor Korotach



