
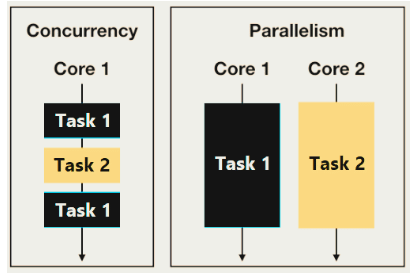
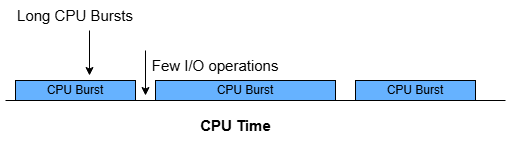
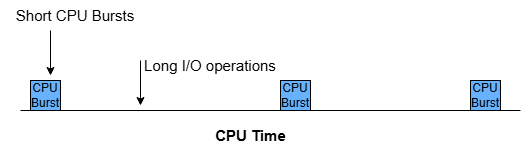
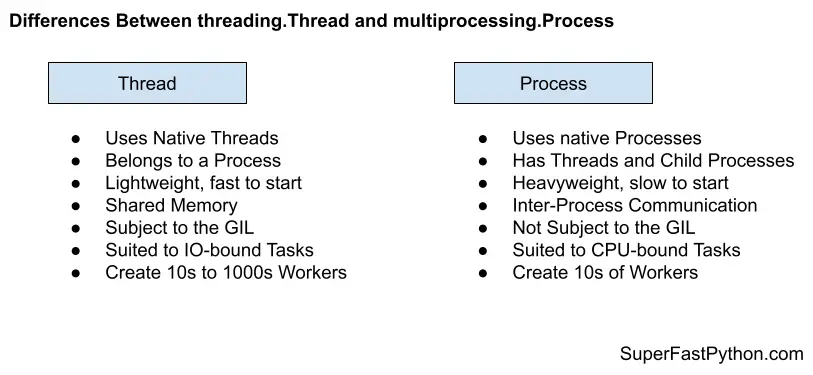

Igor Korotach
Head of FinTech at Quantum
Written by: Igor Korotach
import threading
COUNTER = 0
def increment():
global COUNTER
for _ in range(100000):
COUNTER += 1
# Create multiple threads that increment the shared COUNTER
threads = [threading.Thread(target=increment) for _ in range(5)]
for t in threads:
t.start()
for t in threads:
t.join()
print(f"Expected: 5 * 100000 = 500000, Actual: {COUNTER}")import threading
COUNTER = 0
def increment():
global COUNTER
for _ in range(100000):
# This looks like a single operation, but under the hood it's multiple steps:
# 1) Load COUNTER
# 2) Add 1
# 3) Store COUNTER
# The GIL can switch threads between these steps, causing race conditions.
COUNTER += 1import threading
COUNTER = 0
lock = threading.Lock()
def increment_with_lock():
global COUNTER
for _ in range(100000):
# Only one thread can hold the lock at a time,
# so no other thread can update COUNTER until this block finishes.
# This is called a **critical section**
with lock:
COUNTER += 1
threads = [threading.Thread(target=increment_with_lock) for _ in range(5)]
for t in threads:
t.start()
for t in threads:
t.join()
print(f"Expected: 5 * 100000 = 500000, Actual: {COUNTER}")Any time there is a multi-step operation on the data shared between threads a thread switch can occur which leads to inconsistent data
A C extension can lift the GIL in an explicit operation. Moreover, many C extensions rely on non thread-safe methods of manipulating data, such as 'static' variables
from PIL import Image, ImageFilter
import os
import time
def heavy_image_processing(image_path):
"""Simulate a CPU-heavy image processing task."""
img = Image.open(image_path)
img = img.filter(ImageFilter.GaussianBlur(10))
img.save(f"processed_{os.path.basename(image_path)}")
# List of image files (simulated batch of work)
image_paths = ["image1.jpg", "image2.jpg", "image3.jpg", "image4.jpg"]
start_time = time.time()
for image_path in image_paths:
heavy_image_processing(image_path)
from multiprocessing import Pool
from PIL import Image, ImageFilter
import os
import time
def heavy_image_processing(image_path):
"""Simulate a CPU-heavy image processing task."""
img = Image.open(image_path)
img = img.filter(ImageFilter.GaussianBlur(10))
img.save(f"processed_{os.path.basename(image_path)}")
# List of image files
image_paths = ["image1.jpg", "image2.jpg", "image3.jpg", "image4.jpg"]
if __name__ == "__main__":
start_time = time.time()
# Use multiprocessing to parallelize the workload
with Pool(processes=4) as pool:
pool.map(heavy_image_processing, image_paths)def receive_frame():
"""Simulates receiving a frame from an endpoint."""
# Example: Incoming frame via HTTP/WebSocket/etc.
return get_frame()
def process_frame(frame):
"""Simulates a CPU-intensive frame processing task."""
# Example processing: grayscale, blur, edge detection
pass
def handle_video_stream():
while True:
frame = receive_frame()
if frame is None:
break
processed_frame = process_frame(frame)
send_frame_to_client(processed_frame)import threading
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
frame_queue = Queue()
processed_queue = Queue()
def receive_frames():
"""Receives incoming frames and queues them."""
while True:
frame = receive_frame()
if frame is None:
break
frame_queue.put(frame) # Thread-safe enqueue
def process_frames():
"""Processes frames from the queue using worker threads."""
with ThreadPoolExecutor(max_workers=4) as executor:
while True:
frame = frame_queue.get() # Thread-safe dequeue
if frame is None:
break
executor.submit(lambda f: processed_queue.put(process_frame(f)), frame)
def send_processed_frames():
"""Sends processed frames back to the client."""
while True:
frame = processed_queue.get() # Thread-safe dequeue
if frame is None:
break
send_frame_to_client(frame)
# Start the threads
threading.Thread(target=receive_frames, daemon=True).start()
threading.Thread(target=process_frames, daemon=True).start()
threading.Thread(target=send_processed_frames, daemon=True).start()import threading
from collections import defaultdict
# Shared data structure + Lock
word_counts = defaultdict(int)
lock = threading.Lock()
def count_words_in_file(file_path):
"""Read file and count words in a thread-safe manner."""
with open(file_path, 'r') as file:
for line in file:
for word in line.strip().split():
with lock:
word_counts[word] += 1 # Manual locking
# List of files to process
file_paths = ['file1.txt', 'file2.txt', 'file3.txt']
# Start multiple threads for file processing
threads = [threading.Thread(target=count_words_in_file, args=(path,)) for path in file_paths]
for t in threads:
t.start()
for t in threads:
t.join()from concurrent.futures import ThreadPoolExecutor
from collections import Counter
def count_words_in_file(file_path):
"""Returns a Counter for words in a single file."""
word_counter = Counter()
with open(file_path, 'r') as file:
for line in file:
word_counter.update(line.strip().split())
return word_counter
# List of files to process
file_paths = ['file1.txt', 'file2.txt', 'file3.txt']
# Use ThreadPoolExecutor to efficiently process word counting
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(count_words_in_file, file_paths))
# Merge results without locking
final_word_count = Counter()
for result in results:
final_word_count.update(result)class ConnectionPool {
private:
std::unordered_map<std::string, DatabaseConnection*> pool;
public:
DatabaseConnection* getConnection(const std::string& conn_str) {
if (pool.find(conn_str) == pool.end()) {
pool[conn_str] = new DatabaseConnection(conn_str);
}
return pool[conn_str];
}
};
void workerTask(ConnectionPool& pool, const std::string& conn_str, int id) {
auto conn = pool.getConnection(conn_str);
conn->executeQuery("SELECT * FROM users WHERE id = " + std::to_string(id));
}
int main() {
ConnectionPool pool;
const int numThreads = 5;
std::vector<std::thread> threads;
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(workerTask, pool, "DB_SERVER_1", i);
}
for (auto& t : threads) {
t.join();
}
return 0;
}class ConnectionPool {
private:
std::unordered_map<std::string, DatabaseConnection*> pool;
std::mutex mtx;
public:
DatabaseConnection* getConnection(const std::string& conn_str) {
std::lock_guard<std::mutex> lock(mtx); // Synchronize pool access
if (pool.find(conn_str) == pool.end()) {
pool[conn_str] = new DatabaseConnection(conn_str);
}
return pool[conn_str];
}
};
void workerTask(ConnectionPool& pool, const std::string& conn_str, int id) {
auto conn = pool.getConnection(conn_str);
conn->executeQuery("SELECT * FROM users WHERE id = " + std::to_string(id));
}
int main() {
ConnectionPool pool;
const int numThreads = 5;
std::vector<std::thread> threads;
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(workerTask, pool, "DB_SERVER_1", i);
}
for (auto& t : threads) {
t.join();
}
return 0;
}class ConnectionPool {
private:
std::unordered_map<std::string, std::shared_ptr<DatabaseConnection>> pool; // Stores a shared_ptr
std::mutex mtx;
public:
std::shared_ptr<DatabaseConnection> getConnection(const std::string& conn_str) {
std::lock_guard<std::mutex> lock(mtx); // Synchronize pool access
if (pool.find(conn_str) == pool.end()) {
pool[conn_str] = std::make_shared<DatabaseConnection>(conn_str); // Uses shared_ptr
}
return pool[conn_str];
}
};
void workerTask(ConnectionPool& pool, const std::string& conn_str, int id) {
auto conn = pool.getConnection(conn_str);
conn->executeQuery("SELECT * FROM users WHERE id = " + std::to_string(id));
}
int main() {
ConnectionPool pool;
const int numThreads = 5;
std::vector<std::thread> threads;
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(workerTask, pool, "DB_SERVER_1", i);
}
for (auto& t : threads) {
t.join();
}
return 0;
}std::unordered_map<std::string, int> word_count;
std::mutex map_mutex;
void countWords(const std::vector<std::string>& words) {
for (const auto& word : words) {
std::lock_guard<std::mutex> lock(map_mutex);
word_count[word]++;
}
}
int main() {
const int numThreads = 8;
const int wordsPerThread = 50000;
std::vector<std::string> words = {"apple", "banana", "orange", "apple", "grape"};
std::vector<std::thread> threads;
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(countWords, words);
}
for (auto& t : threads) {
t.join();
}
for (const auto& [word, count] : word_count) {
std::cout << word << ": " << count << "\n";
}
return 0;
}#include <tbb/concurrent_unordered_map.h>
tbb::concurrent_unordered_map<std::string, int> word_count;
void countWords(const std::vector<std::string>& words) {
for (const auto& word : words) {
word_count[word].fetch_add(1, std::memory_order_relaxed); // Atomic increment
}
}
int main() {
const int numThreads = 8;
const int wordsPerThread = 50000;
std::vector<std::string> words = {"apple", "banana", "orange", "apple", "grape"};
std::vector<std::thread> threads;
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(countWords, std::ref(words));
}
for (auto& t : threads) {
t.join();
}
for (const auto& [word, count] : word_count) {
std::cout << word << ": " << count << "\n";
}
return 0;
}Presentation link: https://slides.com/emulebest/practical-concurrency-parallelism
By Igor Korotach



