Text Mining

Generating meaning of textual data
Ujang Fahmi
To be done
- Knowing text mining
- Advantage and Application of text mining
- Tools commonly used in text mining
- Processes in text mining
- Practice
Text Mining?
Text mining, using manual techniques, was used first during the 1980s.
Text mining, also referred to as text data mining, roughly equivalent to text analytics, is the process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as statistical pattern learning.
Text mining is defined as ―the non-trivial extraction of hidden, previously unknown, and potentially useful information from (large amount of) textual data.
Advantage & Application
- Summarizing documents
- Extracting concepts from text
- Indexing text for use in predictive analytics
- Search engines
- Email spam filters
- Product suggestions at check-out
- Fraud detection
- Customer Relationship Management
- Social Media Analysis
Tools for Text Mining






Tools for Text Mining

Processes
- Text Pre-processing
- Text Cleanup
- Tokenisation
- Part of Speech Tagging
- Text Transformation (Attribute Generation)
- Feature Selection (Attribute Selection)
- Evaluate
Cleanup
Text Cleanup means removing any unnecessary or unwanted information. Such as remove ads from web pages, normalize text converted from binary formats.
: bacground-color: red; Annual Meeting PERDAMI 2018 : http://youtu.be/xkd3v18mzPo?a via @YouTube>@BPJSKesehatanRI @anjarisme @BPJSTKinfo @DPR_RI @hincapandjaitan @rs_matacicendo @RoySparringa @PBIDI @RRIPrograma3 @dedeyusuf_1 @NilaMoeloek @taufik_hd2001 @AgusYudhoyono @KPK_RI
annual meeting perdami twothousandandeighteen
Tokenisation
Tokenizing is simply achieved by splitting the text into white spaces.
| Text | Token |
|---|---|
| annual meeting perdami twothousandandeighteen | annual |
| annual meeting perdami twothousandandeighteen | meeting |
| annual meeting perdami twothousandandeighteen | perdami |
| annual meeting perdami twothousandandeighteen | twothousandandeighteen |
POS Tagging
Part-of-Speech (POS) tagging means word class assignment to each token. Its input is given by the tokenized text. Taggers have to cope with unknown words (OOV problem) and ambiguous word-tag mappings.
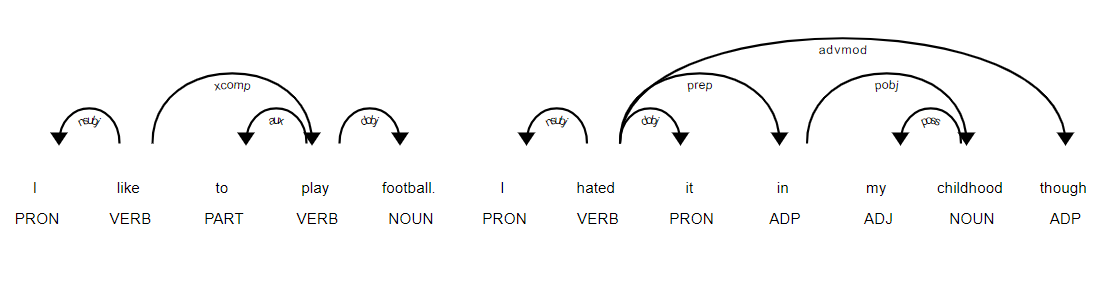
Transformation
A text document is represented by the words it contains and their occurrences. Two main approaches to document representation are:
- Vector Space
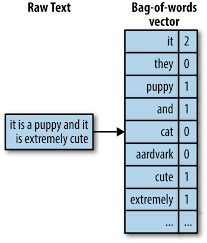
- Bag of words
Feature Selection
Feature selection also is known as variable selection. It is the process of selecting a subset of important features for use in model creation. Redundant features are the one which provides no extra information. Irrelevant features provide no useful or relevant information in any context.
Evaluation
Evaluate the result, after evaluation, the result discard.

- Data and feature
- Method and techniques
- Result
Back to pre-processing and feature selection phase
Practice
Text Mining
By Eppofahmi



