QLearning PacMan

Goals
-
Machine Learning
-
Human performance
The Algorithm
QLearning

Basic Idea
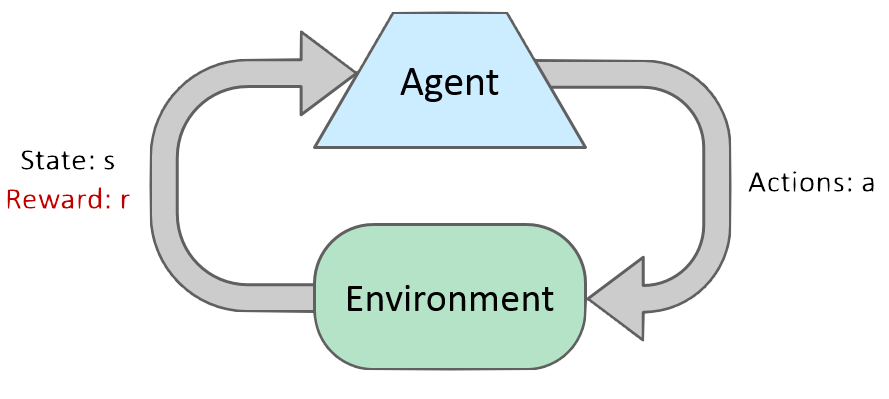
Basic Elements
-
Set of states
-
Set of actions
-
Reward function
-
Set of features represents a state
-
Each feature has a weight
-
Each state has a value
-
Each state plus action has a QValue
Step-by-step
-
Get possible actions
-
Take action with higher QValue
-
Receive feedback (reward and current state)
-
Update Weights
-
Go to first step
Formulas
QValue
Q(s,a) = w1*f1(s,a)+w2*f2(s,a)+...+wn*fn(s,a)
Weights Update
difference = [r + gamma*MaxQ(s',a')] - Q(s,a)
Wi <= Wi + alpha * [difference] * fi(s,a)
alpha - learning rate - 0.1 and 0.001
The Pacman

The Pacman
Rewards
DOT: value = 5
POWER_DOT: value = 10;
EAT_GHOST: value = 800;
DIE: value = -1200;
WALK: value = -2;
Features
-
One divided by the distance to the closest dot or power dot.
-
One divided by the distance to the closest blind ghost.
-
The quantity of ghosts one step away divided by four.
-
Whether the Pacman is going to be eaten or not.
Statistics
Looks like Pacman
Does Not Look like Pacman
Quantity of rounds
-
QLearning Pacman - 4600 round;
-
Random Pacman - 2000 rounds;
-
Human - 4 different humans * 2 rounds each = 8 Rounds
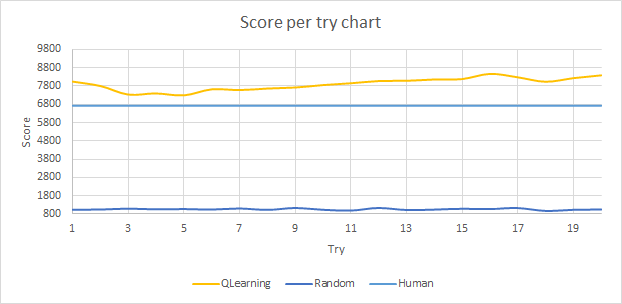
Score per Try
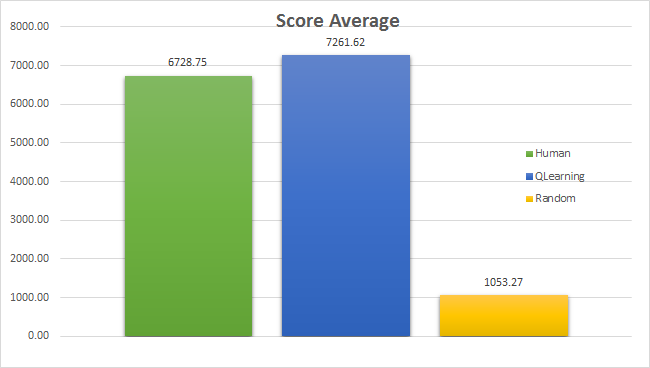
Score AVG
Max Score
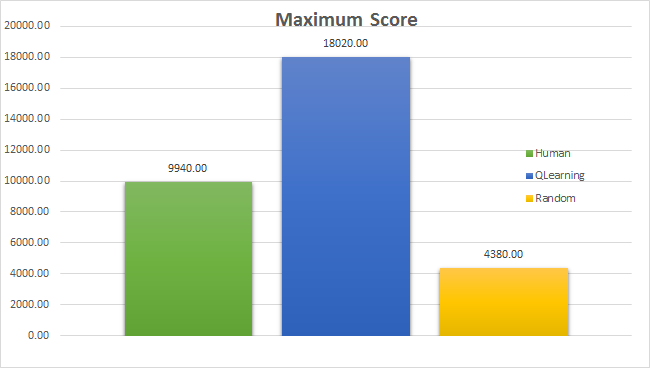
Is the QPacman better than humans?
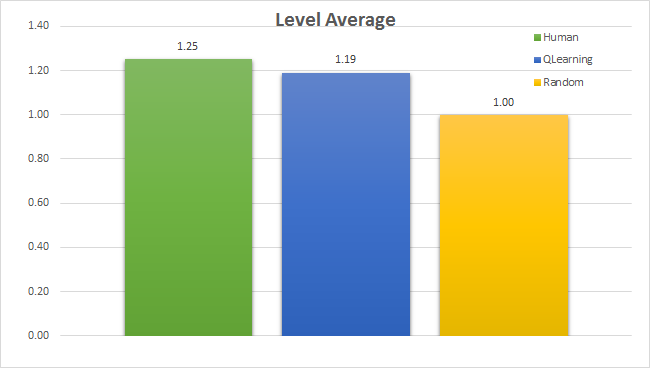
Level AVG
Curiosity
Why did the pacman run from the ghosts before experience a negative reward?
Curiosity
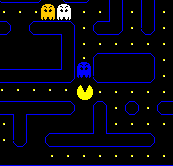
Weights: (10, 15, 0, 0)
State: (0, 0, 1, 1)
QValue = 10*0 + 15*0 + 0 * 1 + 0 * 1 = 0;
Curiosity
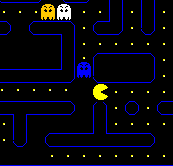
Weights: (10, 15, 0, 0)
State: (1, 0, 0, 0)
QValue = 10*1 + 15*0 + 0 *0 + 0 * 0 = 10;
Curiosity
Curiosity
Special Feature
Sum of distance of ghosts actives divided by the number of ghosts actives
deck
By Eric Moura Guimaraes




